
📖 학습 주제
- AWS Redshift
- 실습
✏️ 주요 메모 사항 소개
AWS Redshift

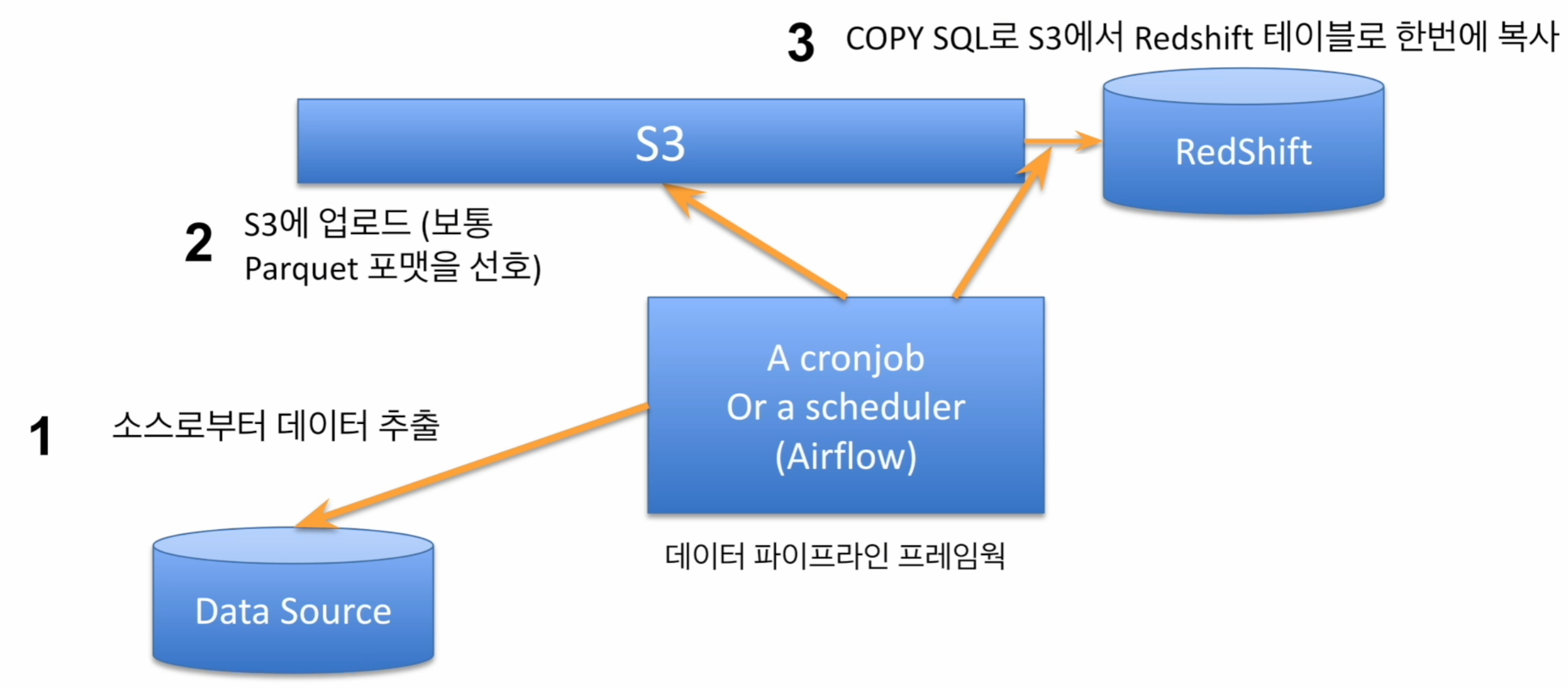
AWS에서 지원하는 데이터 웨어하우스 서비스로, 최소 160GB로 시작해서 점진적으로 용량 증감하여 2PB의 데이터까지 처리 가능하다. AWS Redshift는 다음과 같은 특징이 있다.
- Still OLAP : 응답속도가 빠르지 않기 때문에 프로덕션 데이터베이스로 사용이 불가능하다.
- 컬럼 기반 스토리지 : 레코드 별로 저장하는 것이 아니라 컬럼별로 저장한다. 따라서 컬럼별 압축이 가능하며 컬럼을 추가하거나 삭제하는 것이 아주 빠르다.
- 벌크 업데이트 지원 : 레코드가 들어있는 파일을 S3로 복사 후 COPY 커맨드로 Redshift로 일괄 복사한다.
- 고정 용량/비용 SQL 엔진 : 최근에는 가변 비용 옵션도 제공한다(Redshift Serverless)
- 데이터 공유 기능(Datashare) : 다른 AWS 계정과 특정 데이터 공유 가능.
- 다른 데이터 웨어하우스처럼 primary key uniqueness를 보장하지 않는다.
- Postgresql 8.x와 호환되기 때문에 툴이나 라이브러리로 액세스 가능하다.
Redshift의 스케일링 방식
AWS Redshift는 용량이 부족해질 때마다 새로운 노드를 추가하는 방식으로 스케일링을 수행한다. 만약 dc2.large를 사용하고 있다면,
- Scale Up : 사양을 더 좋은 것(dc2.8xlarge 한대)으로 업그레이드
- Scale Out : dc2.large 한대를 더 추가
이를 Resizing이라 부르며 Auto Scaling 옵션을 설정하면 자동으로 이뤄진다. 이는 Snowflake나 BigQuery의 방식과는 굉장히 다르다. 위의 두개는 특별히 용량이 정해져있지 않고 쿼리를 처리하기 위해 사용한 리소스에 해당하는 비용을 지불하는 형식이다.
즉, Snowflake와 BigQuery가 훨씬 더 스케일하는 데이터베이스 기술이라 볼 수 있지만 비용의 예측이 불가능하다는 단점이 존재한다.
Redshift 레코드 분배 & 최적화
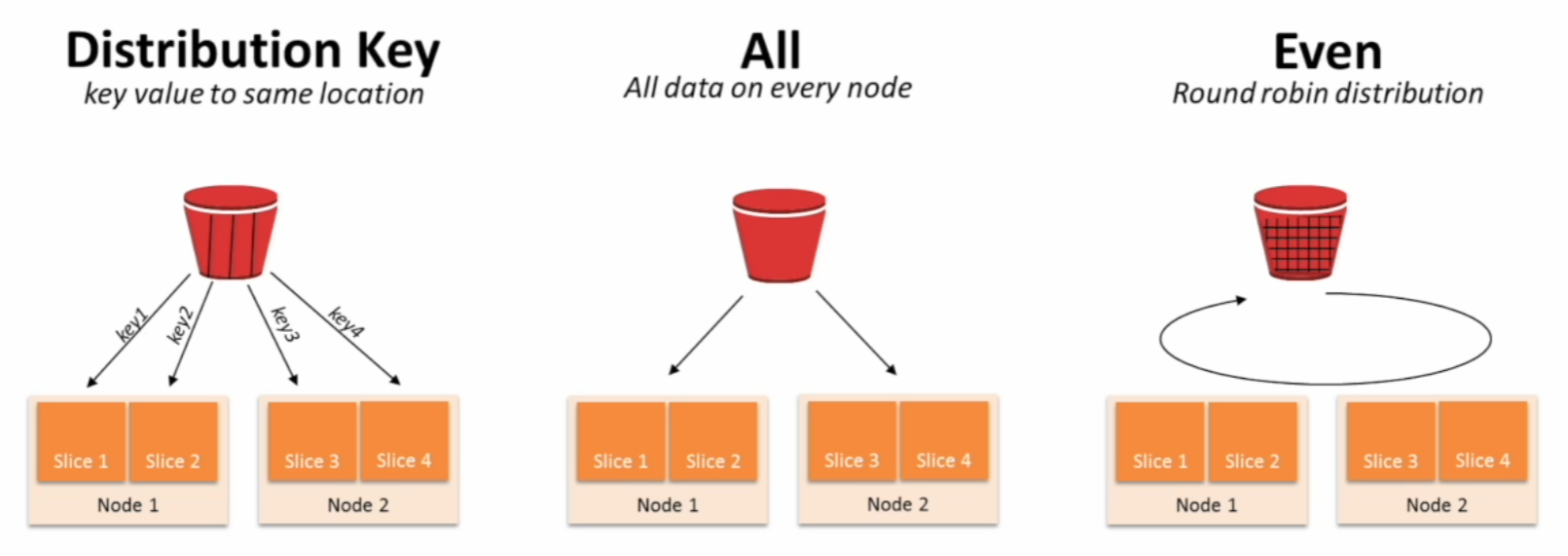
만약 Redshift가 두 대 이상의 노드로 구성되면 그 시점부터 테이블 최적화가 중요하다. 한 테이블의 레코드들을 어떻게 다수의 노드에 분산 저장 하는 지와, 또 한 노드 내에서 순서를 정해주어야 한다. 3가지의 속성을 어떻게 설정하느냐에 따라서 어떤 방식으로 저장되는지가 결정된다.
- Diststyle : 레코드 분배가 어떻게 이뤄지는지를 결정 (
all,even(default),key) - Distkey : 레코드가 어떤 컬럼을 기준으로 배포되는지 나타냄 (diststyle이
key인 경우) - Sortkey : 레코드가 한 노드내에서 어떤 컬럼을 기준으로 정렬되는지 나타냄 (보통 타임스탬프 필드가 된다.)
- Diststyle이 key인 경우 컬럼 선택이 잘못될 경우 레코드 분포에 Skew가 발생하여 분산처리의 효율성이 사라진다. BigQuery나 Snowflake는 이런 속성을 시스템이 알아서 선택하기 때문에 개발자가 지정할 필요가 없다.
다음의 코드는 'my_table의 레코드들을 column1의 값을 기준으로 분배되고 같은 노드(슬라이스) 안에서는 column3의 값을 기준으로 sorting이 된다.
CREATE TABLE my_table(
column1 INT,
column2 VARCHAR(50),
column3 TIMESTAMP,
column4 DECIMAL(18,2)
) DISTSTYLE KEY DISTKEY(column1) SORTKEY(column3) ;Redshift의 벌크 업데이트 방식 - COPY SQL
실습1 - Redshift 클러스터 생성해보기

구성은 기본적으로 설정되어 있는 것을 쓰도록 하자. 구성 저장을 누르고 잠시 기다리면 설치가 완료된다.

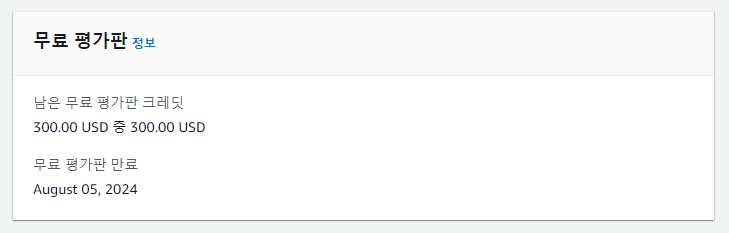
처음 Redshift를 생성하면 무료 평가판으로 3개월 간 300$의 크레딧을 사용할 수 있다. 꼭 확인해서 추가적인 과금에 조심하도록 하자.
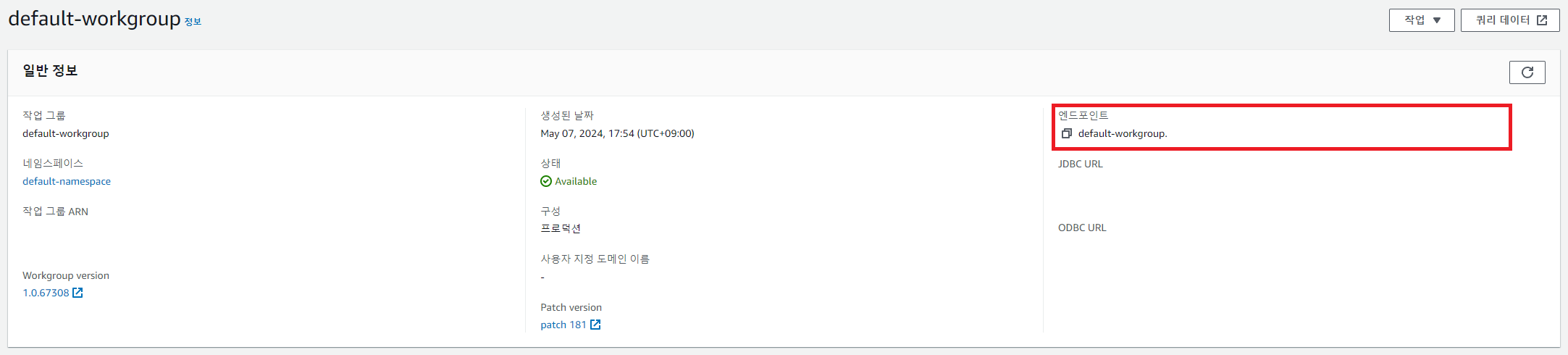
Redshift를 사용하기 위해 먼저 우리가 생성한 클러스터의 엔드포인트를 확인해 보자. 이 엔드포인트는 나중에 외부에서 연결할 때 필요하므로 복사해 두자.

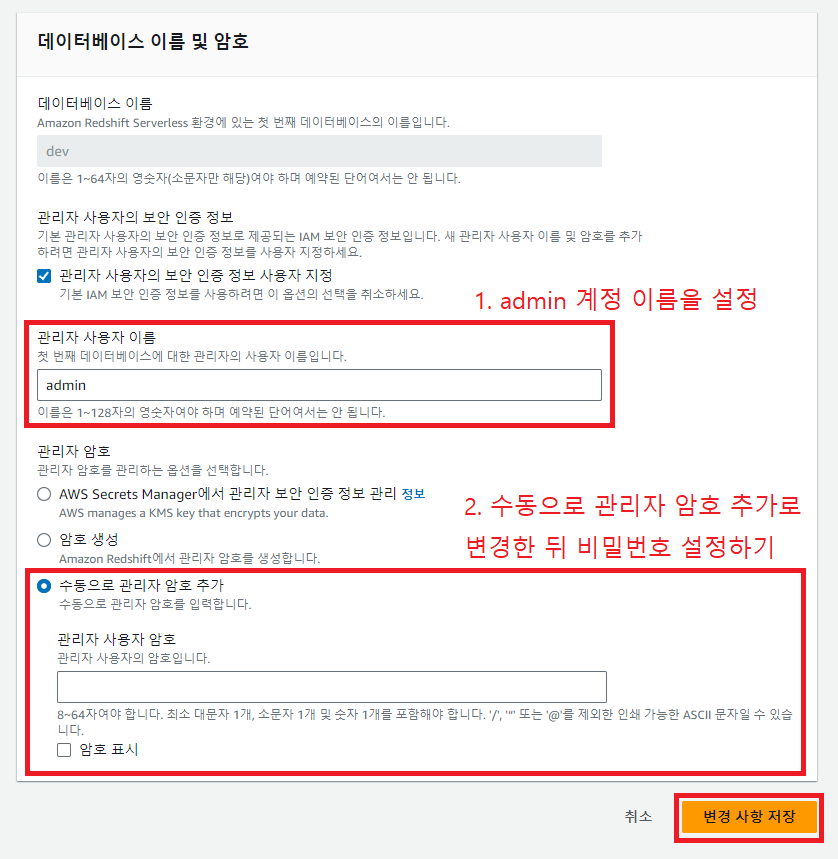
다음으로는 액세스할 수 있는 계정 설정을 해야한다. 두가지 방법이 있는데 이 실습에서는 1번으로 진행해보자.
- admin 세팅을 해서 admin으로 연결
- IAM 기능을 이용해서 별도의 계정으로 연결
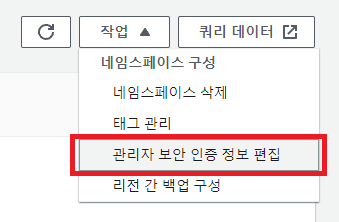
다시 대시보드로 돌아가서 네임스페이스로 이동한다.

오른쪽의 작업을 누르고 '관리자 보안 인증 정보 편집'을 누른다.
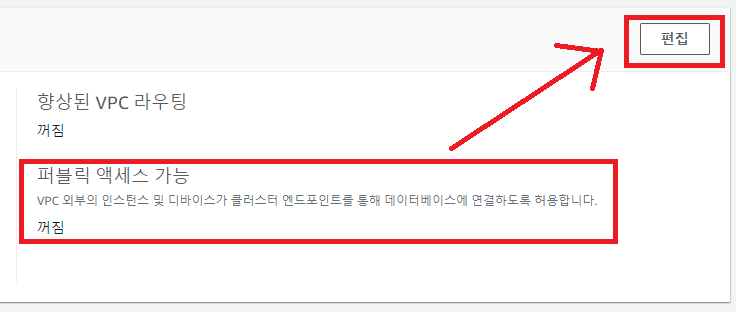
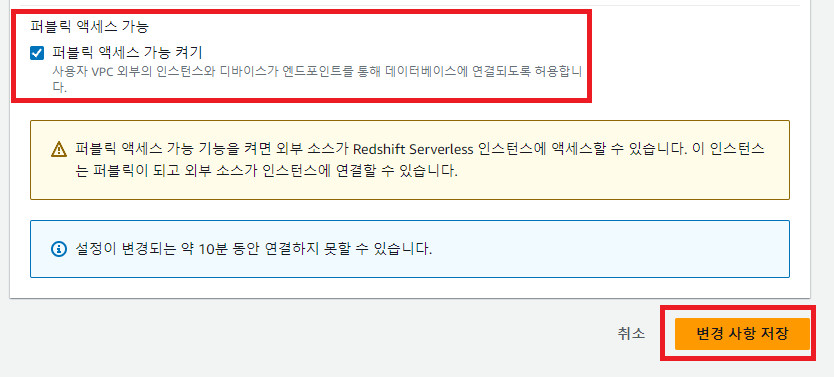
외부에서 접근을 허용하기 위해 퍼블릭 액세스를 허용하게 설정을 바꿔야 한다.

네트워크와 보안 탭에서 편집해주자.
VPC security group에서 인바운드 규칙도 추가적으로 설정해주어야 한다.


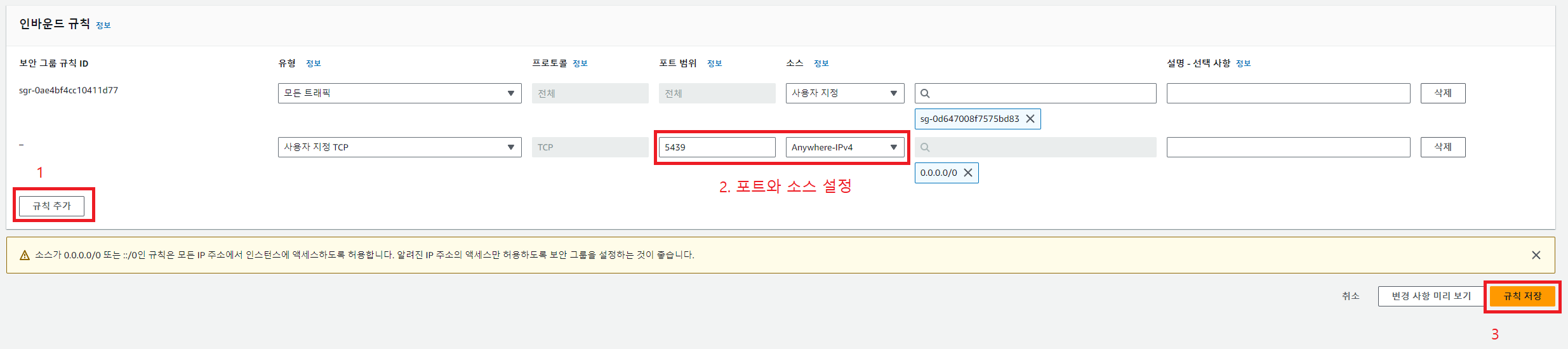
구글 COLAB을 이용해서 redshift에 연결 후 실습을 진행하기 위해 방금 까지 우리가 확인했던 정보를 기억해두자.
- Redshift 엔드포인트 (endpoint)
- admin 계정 (username)
- admin 비밀번호 (password)
이 정보를 이용해서 구글 COLAB에서 연결하면 된다

- 혹시 'Connection' object has no attribute 'rollback' 이런 오류가 발생했다면 그건 ipython-sql과 SQLAlchemy 버전에서 호환이 안되는 문제가 발생한 것일 수 있다.
다음과 같이 버전을 수정해보자.

!pip install ipython-sql==0.4.1
!pip install SQLAlchemy==1.4.49실습2 - Redshift 초기 설정
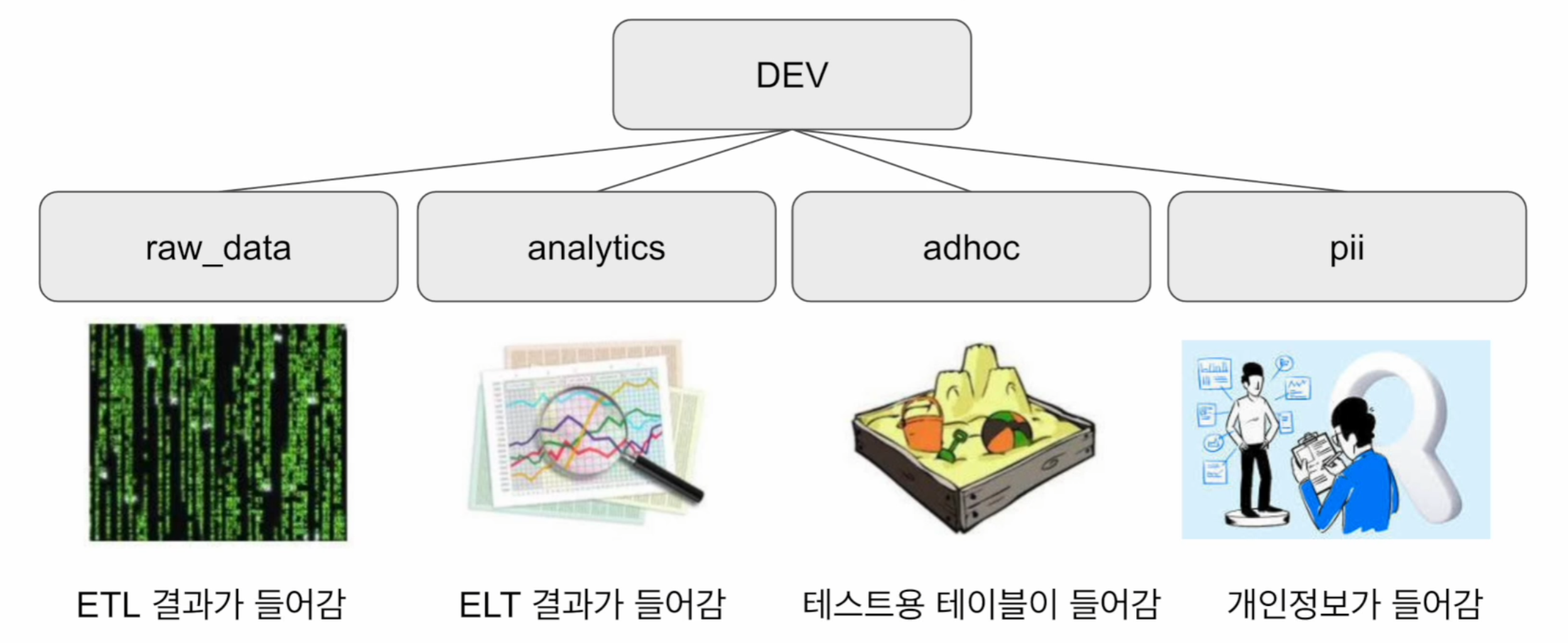
- Schema 생성하기
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;
CREATE SCHEMA pii;
select * from pg_namespace;
- User 추가하기
CREATE USER sasngwon PASSWORD 'password(대소문자1개, 특수문자1개 포함)';
select * from pg_user;
- Group 추가하기
CREATE GROUP analytics_users;
CREATE GROUP pii_users;
CREATE GROUP analytics_authors;
ALTER GROUP analytics_authors ADD USER sangwon;
ALTER GROUP analytics_users ADD USER sangwon;
ALTER GROUP pii_users ADD USER sangwon;
select * from pg_group;
- Role 추가하기
CREATE ROLE staff;
CREATE ROLE manager;
CREATE ROLE external;
GRANT ROLE staff TO sangwon; -- sangwon 대신에 다른 역할(Role)을 지정 가능
GRANT ROLE staff TO ROLE manager;
SELECT * FROM SVV_ROLES;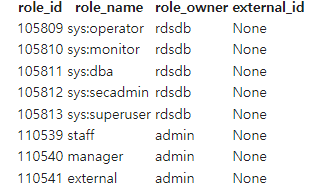
실습3 - Redshift COPY로 레코드 적재하기
COPY 명령을 사용해 raw_data 스키마 및 3개의 테이블에 레코드를 적재해보자.
- 각 테이블을 CREATE TABLE 명령으로 raw_data 스키마 밑에 생성
- 이때 각 테이블의 입력이 되는 CSV 파일을 먼저 S3로 복사해야함. (S3 버킷부터 미리 생성하기)
- S3에서 해당 테이블로 복사를 하려면 Redshift가 S3 접근권한을 가져야함
따라서 먼저 Redshift가 S3를 접근할 수 있는 역할을 만들고 (IAM 웹콘솔)
이 역할을 Redshift 클러스터에 지정해야 함 (Redshift 웹 콘솔)
최종적으로 다음과 같은 테이블을 만들면 된다.

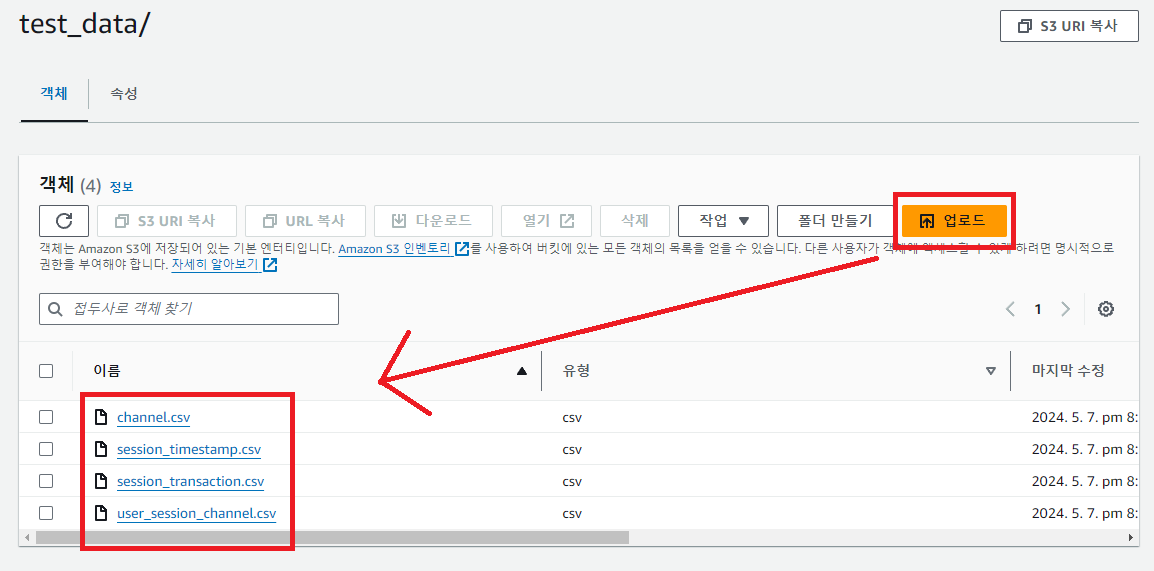
1. CSV 파일을 S3 bucket에 업로드

AWS S3에 들어가서 버킷 만들기를 누른 뒤 버킷이름을 설정하고 나머지는 기본으로 버킷을 만들어보자.
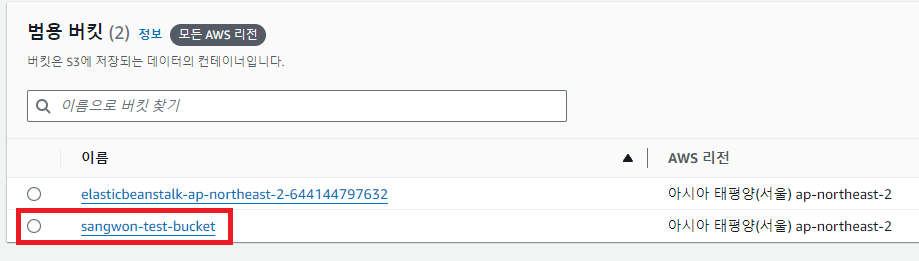
이후 버킷안에 우리가 준비한 csv 파일들을 업로드하면 된다.
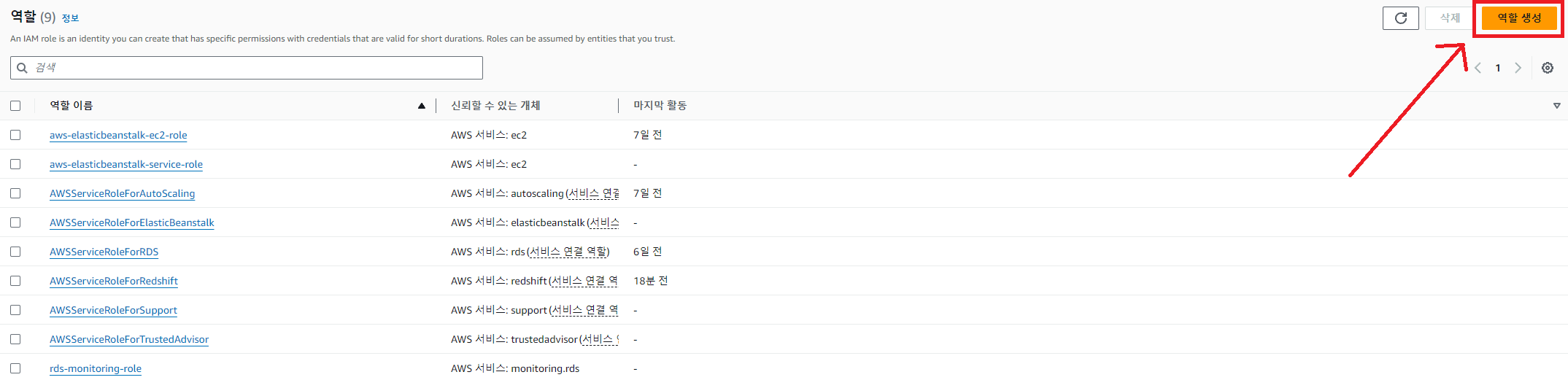
2. Redshift에 S3 접근 권한을 설정
AWS IAM을 이용해 이에 해당하는 역할(Role)을 만들고 이를 Redshift에 부여하면 된다.
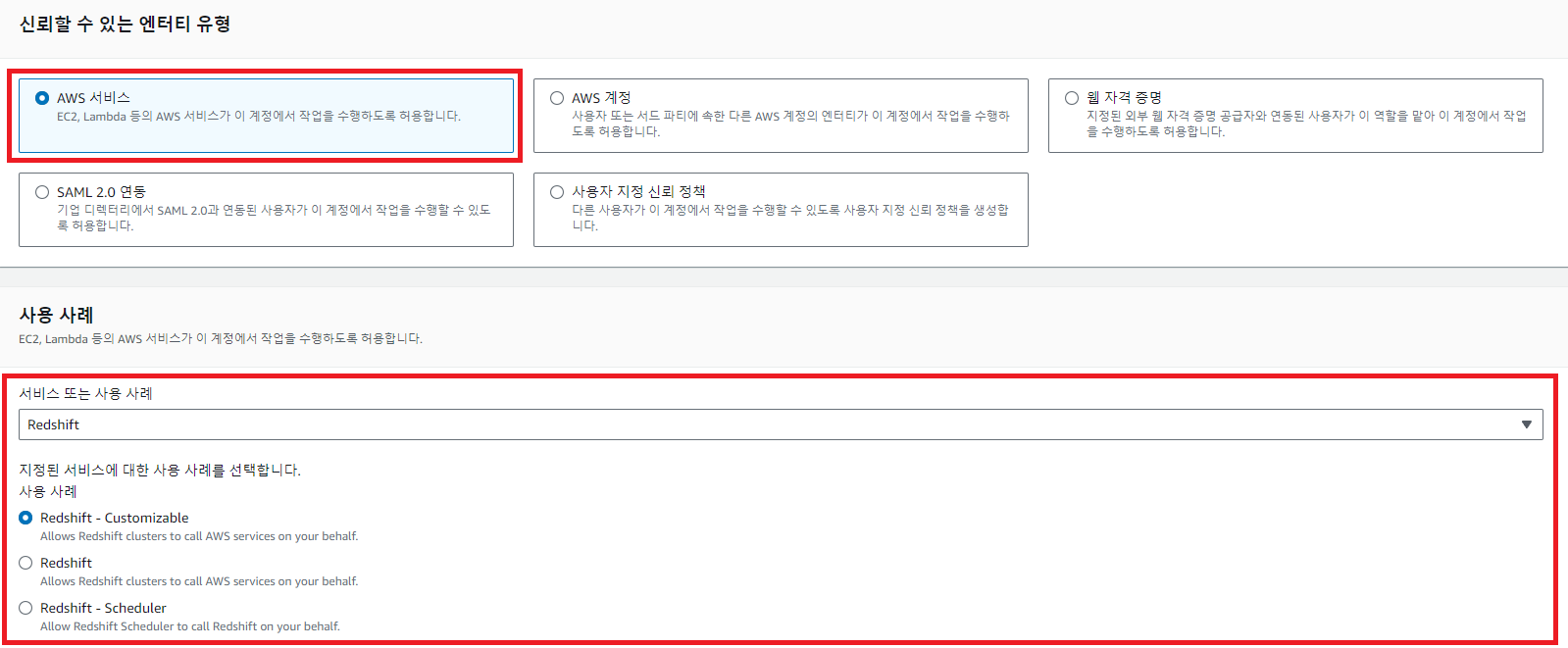
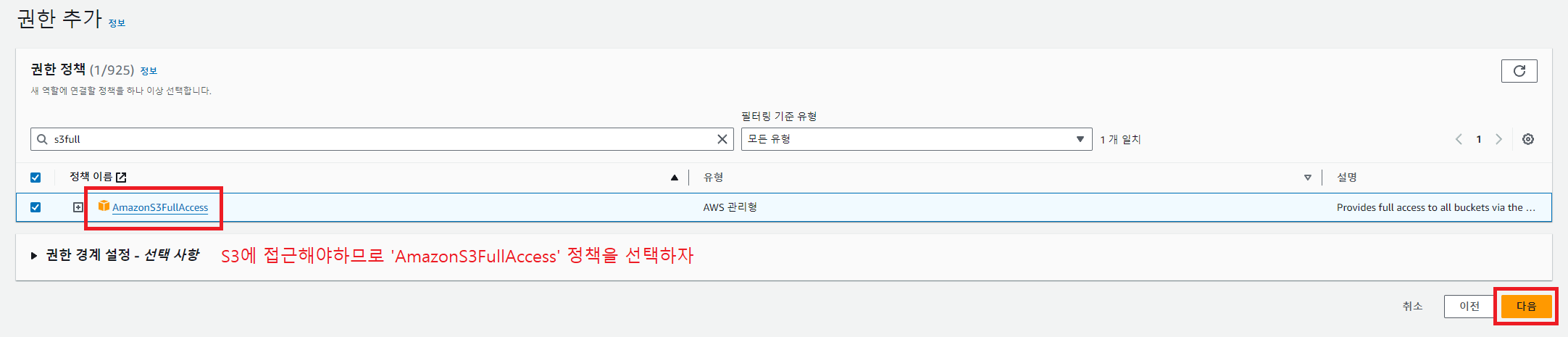
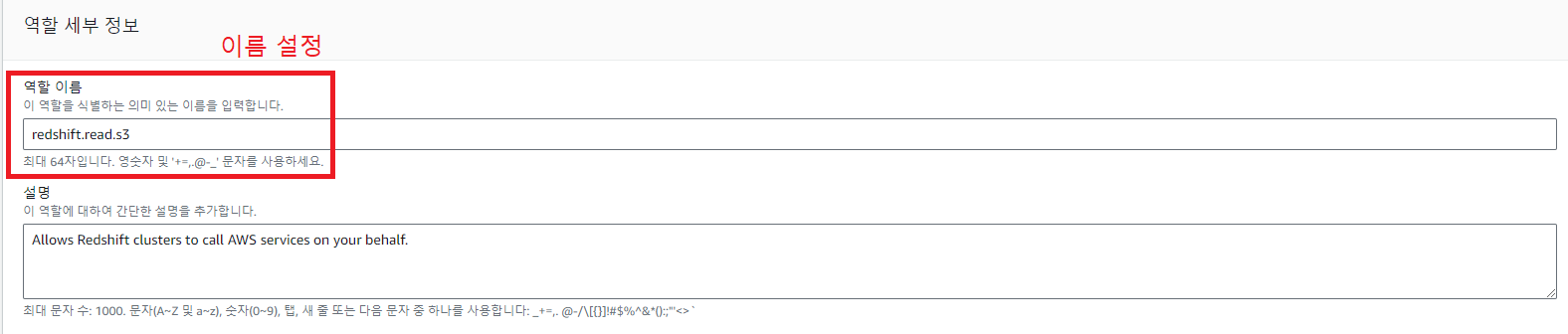
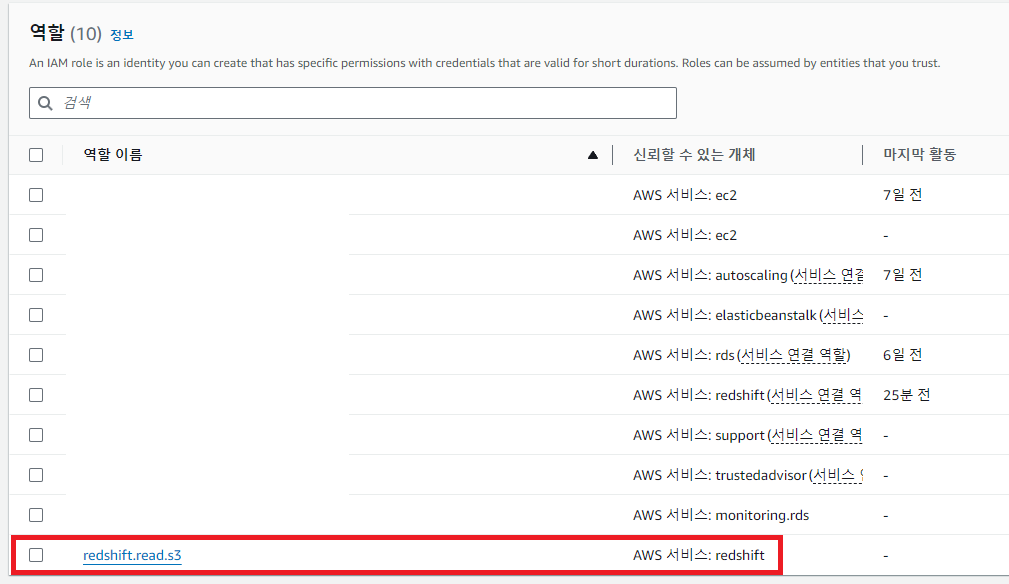
3. Redshift 클러스터에 권한 적용
우리가 만든 Redshift의 namespace로 이동한 뒤 '보안 및 암호화' 탭에서 방금 만든 IAM role을 추가해주자.
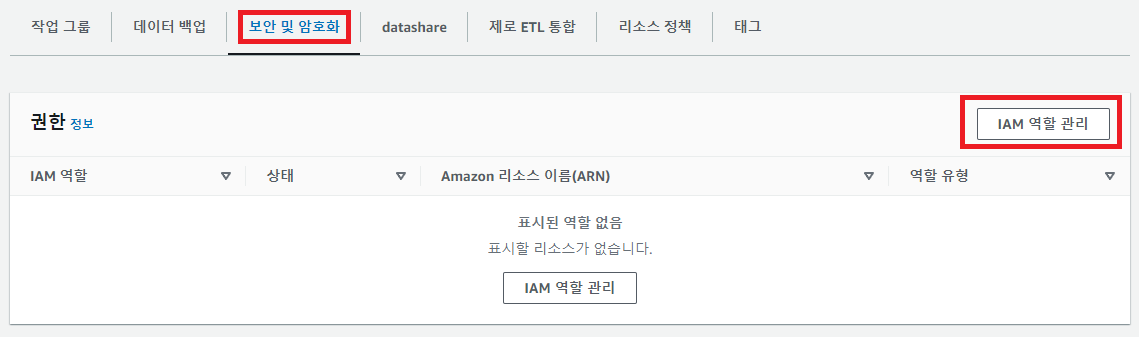
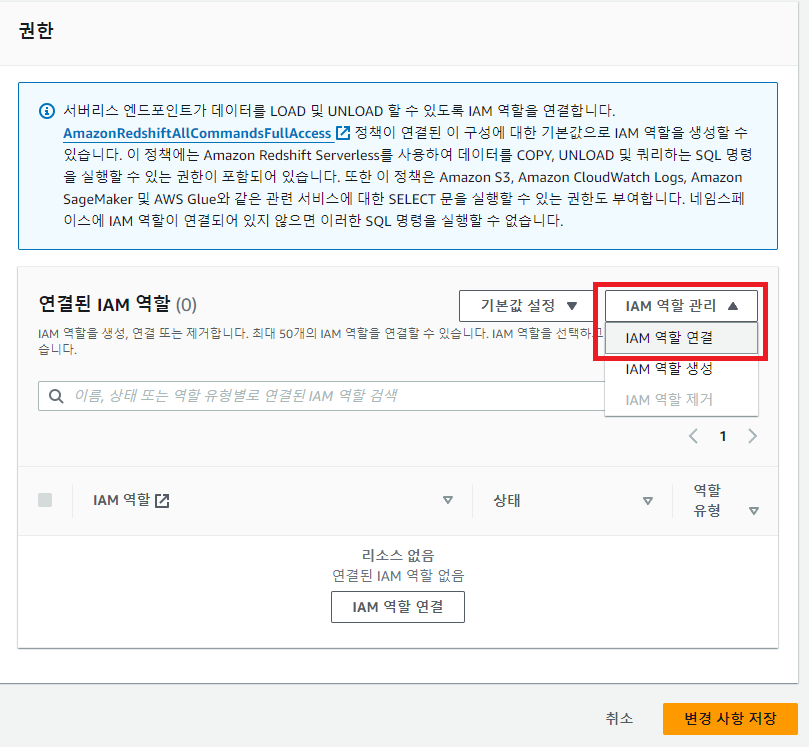
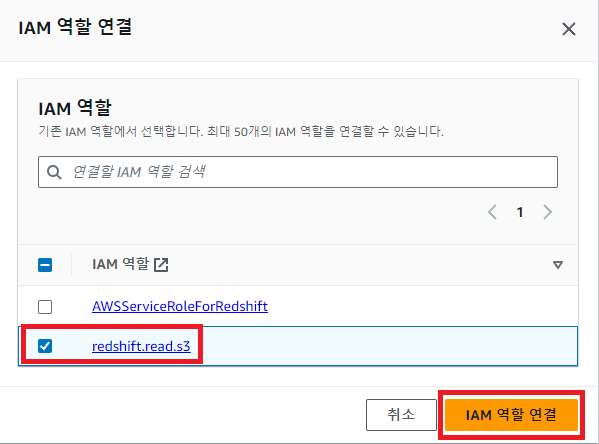

4. CSV 파일들을 테이블로 복사 (벌크 업데이트)
COPY 명령을 사용해서 앞서 업로드한 CSV파일을 테이블로 복사해보자.
- 테이블 생성하기
CREATE TABLE raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
);- COPY 명령어를 사용해서 S3 버킷안의 CSV 파일을 테이블로 복사하기
COPY raw_data.user_session_channel
FROM '(S3 버킷에 업로드한 파일의 URI)'
credentials 'aws_iam_role=(아까 만든 역할의 ARN)'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes;- 확인
SELECT * FROM raw_data.user_session_channel LIMIT 10;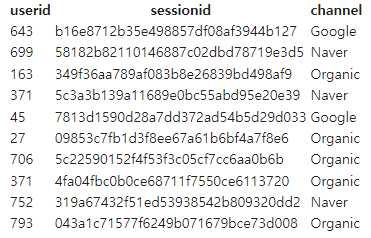
💦 공부하며 어려웠던 내용
강의가 꼼꼼하고 따라 하기 쉽게 구성이 되어있어서 실습하는데 어려움은 없었다. 그래도 AWS의 과금 압박은 무섭다... 시간당 0.25$ 라고 하니까 문제될 건 없겠지만 그래도 꼼꼼하게 체크하는 습관을 들여야 겠다.
