
📖 학습 주제
- Snowflake
✏️ 주요 메모 사항 소개
Snowflake

Snowflake는 멀티클라우드 데이터 웨어하우스 서비스로, 글로벌 클라우드 (AWS, GCP, Azure) 위에서 모두 동작하고, 데이터 판매를 통한 매출을 가능하게 해주는 Data Sharing/Marketplace와 같은 다양한 기능들을 제공합니다. 또한 ETL과 다양한 데이터 통합 기능도 제공합니다.
Snowflake 특징
- 스토리지와 컴퓨팅 인프라가 별도로 설정되는 가변 비용 모델
- SQL 기반으로 빅데이터 저장, 처리, 분석이 가능
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- Time Travel : 과거 데이터 쿼리 기능으로 트렌드를 분석하기 쉽다
- 웹 콘솔 이외에도 Python API를 통한 관리/제어 가능
- 자체 스토리지 이외에도 클라우드 스토리지를 외부 테이블로 사용 가능
Snowflake 구성
Snowflake의 계정 구성도 : Organization -> 1+ Account -> 1+ Databases
Organizations
- 한 고객이 사용하는 모든 Snowflake 자원들을 통합하는 최상위 레벨 컨테이너
- 하나 혹은 그 이상의 Account들로 구성되며 이 모든 Account들의 접근권한, 사용트래킹, 비용들을 관리하는데 사용됨
Accounts
- 하나의 Account는 자체 사용자, 데이터, 접근권한을 독립적으로 가짐
- 한 Account는 하나 혹은 그 이상의 Database로 구성됨
Databases
- 하나의 Database는 한 Account에 속한 데이터를 다루는 논리적인 컨테이너
- 한 Database는 다수의 스키마와 거기에 속한 테이블과 뷰동으로 구성되어 있음
- 하나의 Database는 PB단위까지 스케일 가능하고 독립적인 컴퓨팅 리소스를 갖게 됨 (컴퓨팅 리소스를 Warehouses라고 부르고 Warehouses와 Databases는 일대일 관계가 아니다)
Snowflake 실습
1. Snowflake 가입
Snowflake는 처음 사용할 시 30일간 400$의 무료 평가판을 이용할 수 있으니 이걸 이용해 보자.
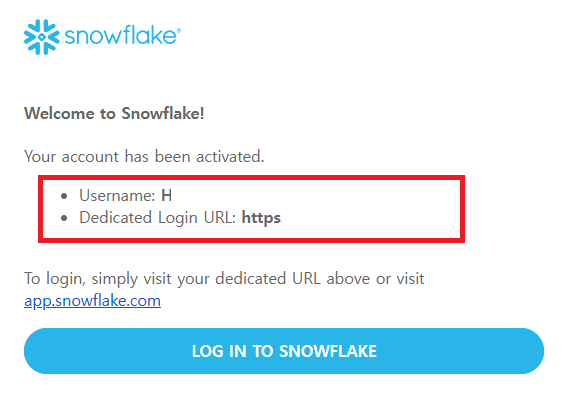
가입을 완료하면 메일로 설정한 Username과 로그인 URL을 확인할 수 있다. 이 정보를 이용해서 Snowflake를 접속해야하므로 별도로 저장하거나 기억해두자.
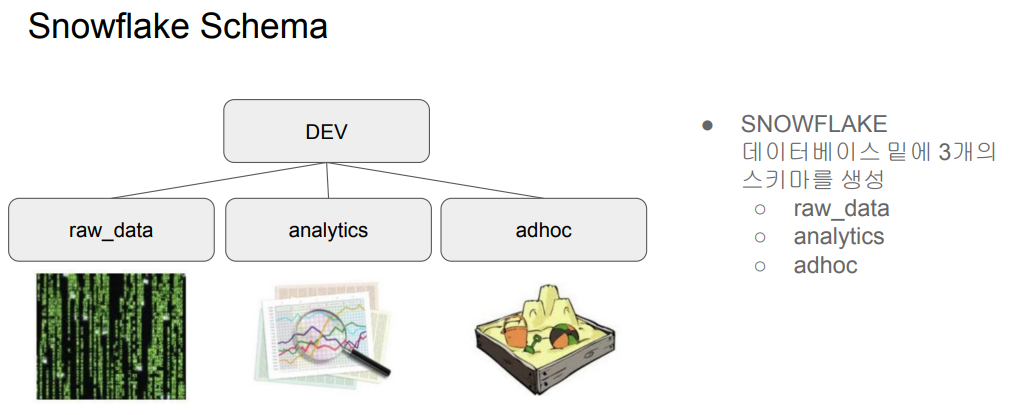
전 실습에서 Redshift에서 테이블을 생성한 것과 마찬가지로 똑같은 구조를 Snowflake를 이용해서 구현해보도록 하자.
2. IAM 사용자 추가
Snowflake는 외부 프로그램이기 때문에 AWS S3 버킷에 접근하기 위해 사용자를 만들어 S3에 접근할 수 있도록 정책을 할당하고 액세스 키를 발급받아야 한다.
AWS IAM 서비스에서 사용자 탭에 들어가 사용자 생성을 해주자.
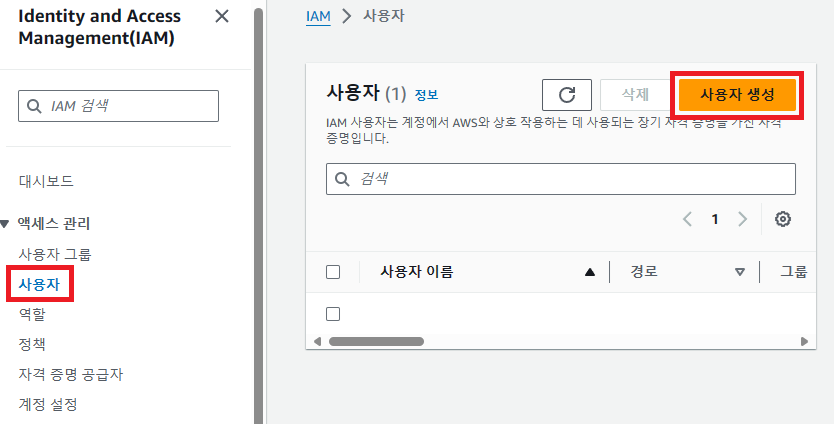
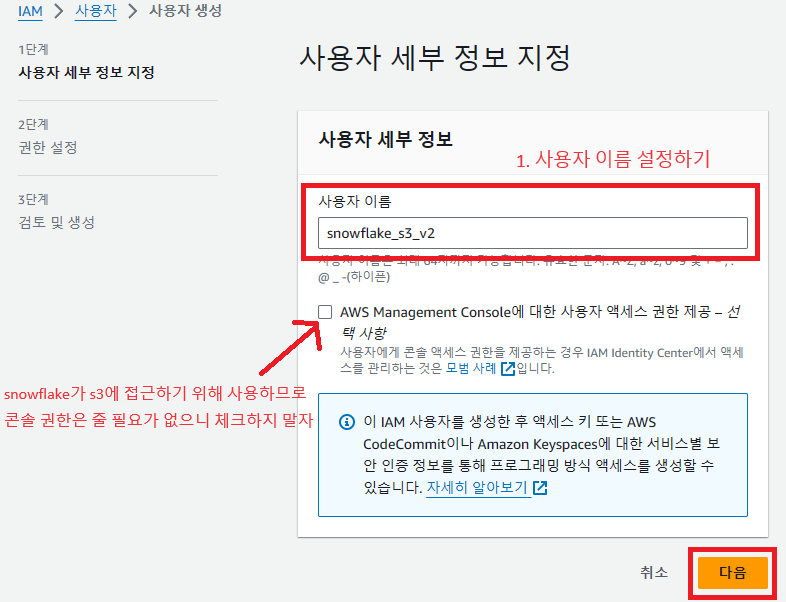
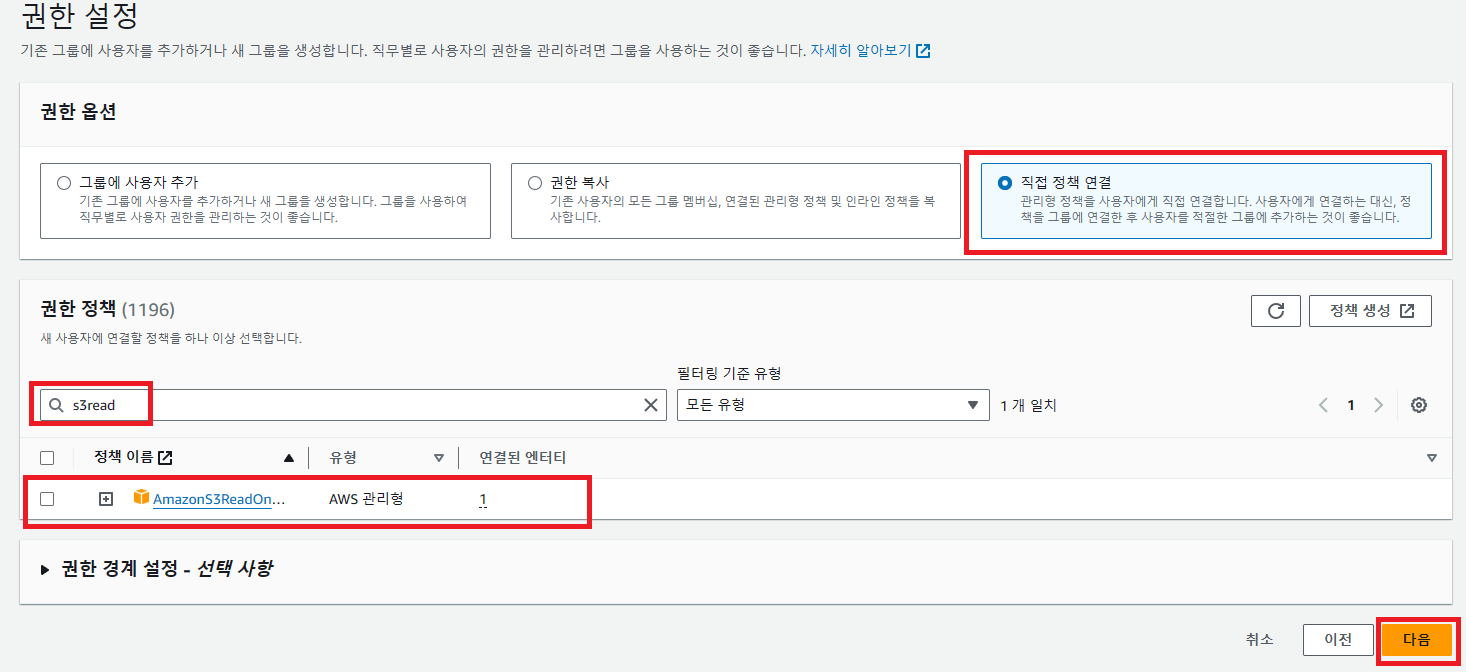
생성한 사용자가 S3에 접근하고 데이터를 읽어올 수 있어야 하기 때문에 'AmazonS3ReadOnlyAccess' 정책을 연결해주고 검토 후 사용자를 생성해주자.
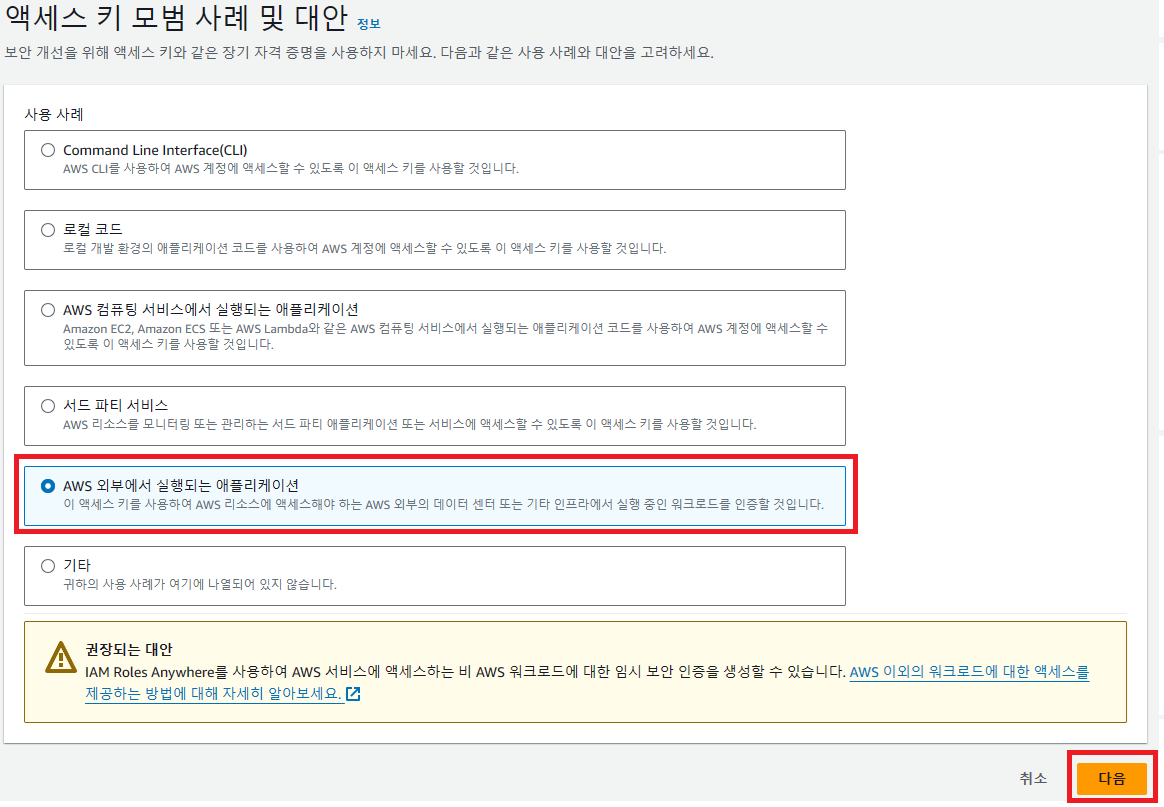
이제 이 사용자에 대한 액세스 키를 발급받아야 한다. 우리는 외부 프로그램에서 사용할 것이기 때문에 'AWS 외부에서 실행되는 애플리케이션' 을 선택해주자.

description은 자유롭게 적어주고 액세스 키를 생성하면 다음과 같은 화면이 나오는데, 이 액세스 키와 비밀 액세스키는 이 창을 넘어가면 다시 찾아볼 수 없기 때문에 미리 복사해서 안전한 곳에 저장해두자.
절대 이 키가 외부에 알려지지 않도록 조심하자!
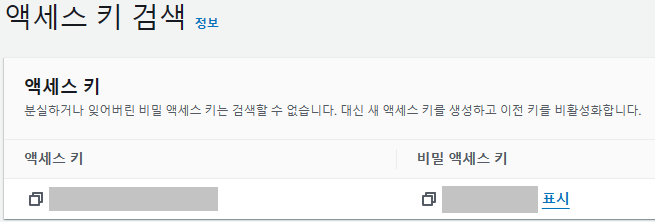
이제 이 키를 이용해서 S3 버킷으로 접근해 데이터를 가져와 테이블을 생성해보자.
3. 테이블 생성
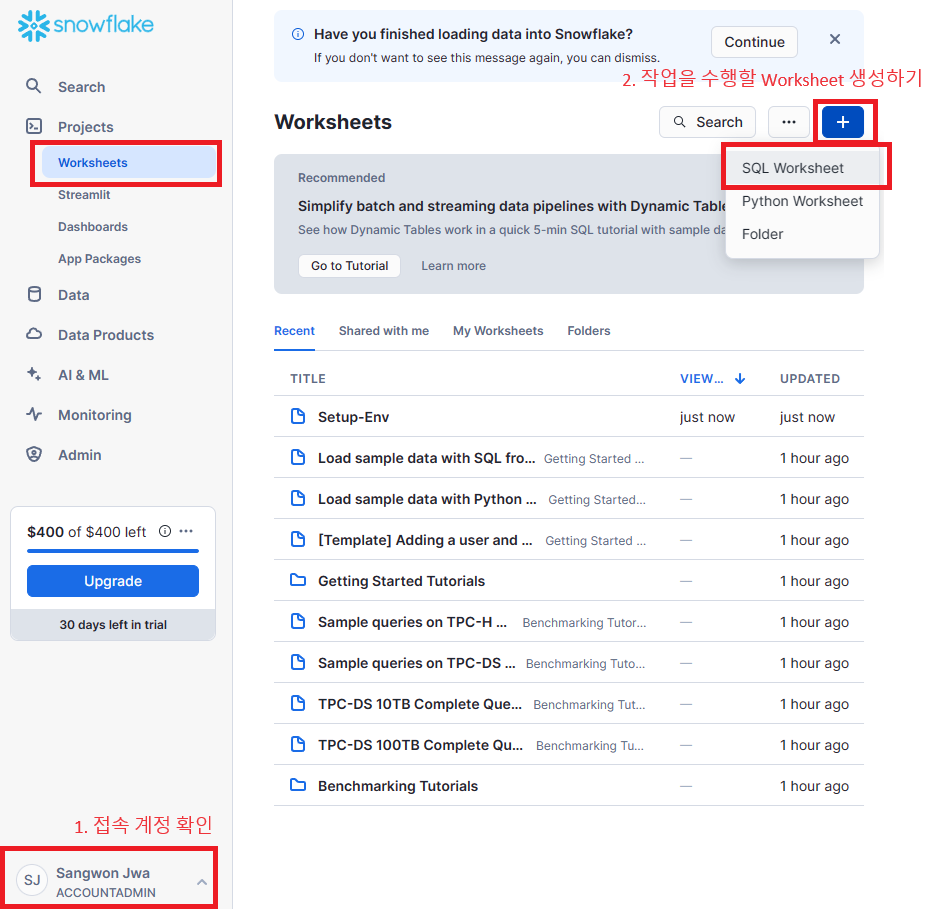
Snowflake는 자체적으로 웹 에디터를 제공하므로 간단하게 SQL문을 실행하고 결과를 출력할 수 있다. 먼저 우리가 SQL문을 실행시키고 작업을 할 Worksheet를 만들자.
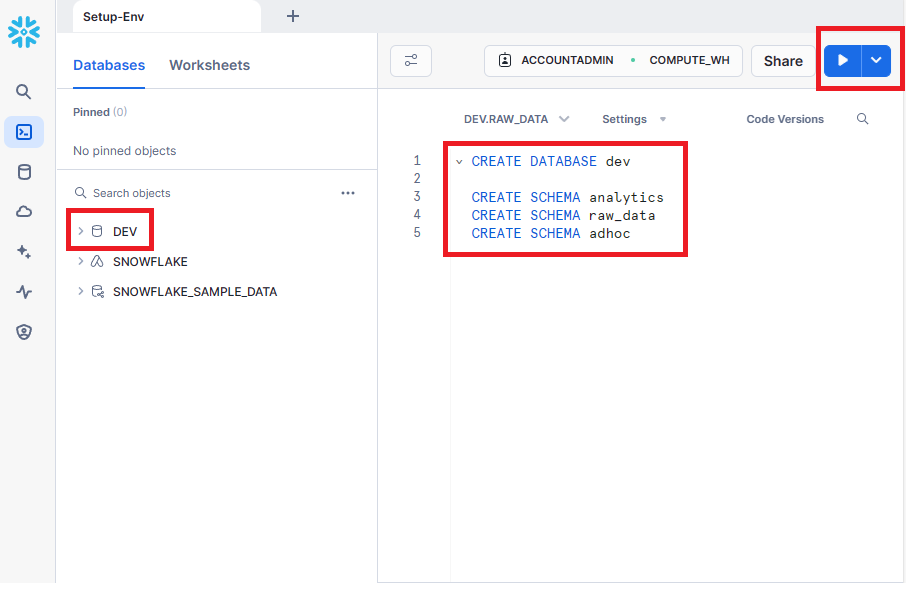
생성한 Worksheet으로 이동하면 SQL을 실행시킬 수 있는 텍스트 에디터를 볼 수 있다. 먼저 dev라는 데이터베이스를 만들고 우리가 만드려는 3가지 스키마를 생성해주자. 완료 시 옆에 DEV 데이터베이스가 생성된 것을 확인할 수 있다.
이후 SQL문을 이용해서 테이블을 우리가 사용할 CSV파일에 맞게 필드를 설정해서 만들어주고, 전에 생성한 S3 버킷에서 COPY 명령어를 이용해 데이터를 가져와 주자.
CREATE OR REPLACE TABLE dev.raw_data.session_transaction (
sessionid varchar(32) primary key,
refunded boolean,
amount int
);
CREATE TABLE dev.raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
);
CREATE TABLE dev.raw_data.session_timestamp (
sessionid varchar(32) primary key,
ts timestamp
);
COPY INTO dev.raw_data.session_timestamp
FROM '본인 s3 버킷안의 파일 url'
credentials=(AWS_KEY_ID='액세스 키' AWS_SECRET_KEY='비밀 키')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');
COPY INTO dev.raw_data.user_session_channel
FROM '본인 s3 버킷안의 파일 url'
credentials=(AWS_KEY_ID='액세스 키' AWS_SECRET_KEY='비밀 키')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');
COPY INTO dev.raw_data.session_transaction
FROM '본인 s3 버킷안의 파일 url'
credentials=(AWS_KEY_ID='액세스 키' AWS_SECRET_KEY='비밀 키')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');4. 실행
다음 테이블을 새롭게 만들고 SELECT 명령어로 테이블을 살펴보면 잘 출력되는 것을 볼 수 있다.
CREATE TABLE dev.analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM dev.raw_data.session_timestamp A
JOIN dev.raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;
SELECT * FROM dev.analytics.mau_summary LIMIT 10;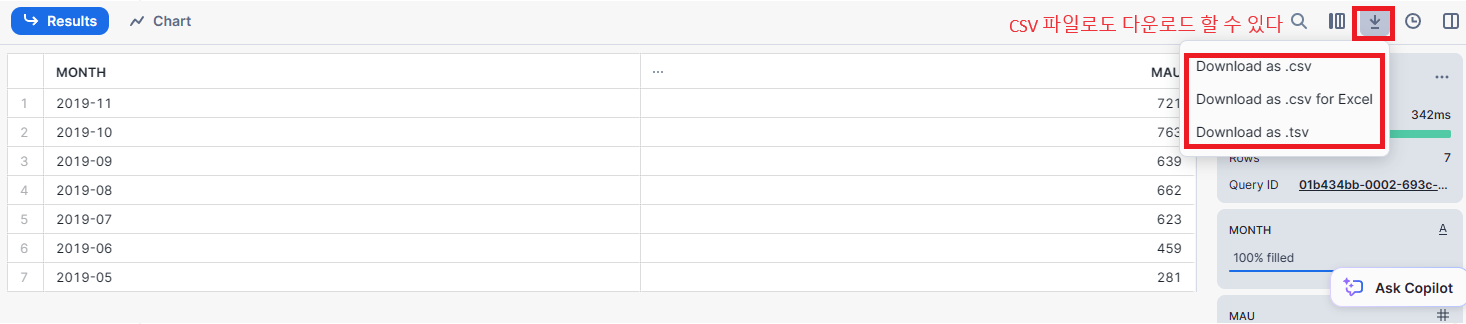
5. 권한 설정하기
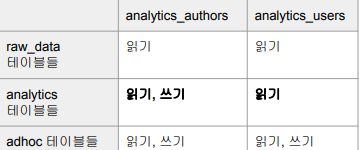
Snowflake는 Redshift와 달리 Group기능을 제공하지 않기 때문에 Role을 이용해야 한다.
-- 3개의 ROLE을 생성한다
CREATE ROLE analytics_users;
CREATE ROLE analytics_authors;
CREATE ROLE pii_users;
-- 사용자 생성
CREATE USER sangwon PASSWORD='sangwonpassword';
-- 사용자에게 analytics_users 권한 지정
GRANT ROLE analytics_users TO USER sangwon;생성한 Role에 아무런 권한을 설정하지 않았기 때문에 어떤 테이블에서 어떤 작업을 할 수 있는지 지정해주자
-- analytics_users 설정
GRANT USAGE on schema dev.raw_data to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.raw_data to ROLE analytics_users;
GRANT USAGE on schema dev.analytics to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.analytics to ROLE analytics_users;
GRANT ALL on schema dev.adhoc to ROLE analytics_users;
GRANT ALL on all tables in schema dev.adhoc to ROLE analytics_users;
-- analytics_authors 설정
GRANT ROLE analytics_users TO ROLE analytics_authors;
GRANT ALL on schema dev.analytics to ROLE analytics_authors;
GRANT ALL on all tables in schema dev.analytics to ROLE analytics_authors;권한 설정에 있어서 선택할 수 있는 옵션은 두 가지 정도가 있다.
- 컬럼 레벨 보안 (Column Level Security)
- 테이블내의 특정 컬럼들을 특정 사용자나 특정 역할에만 접근 가능하게 설정
- 보통 개인정보 등에 해당하는 컬럼을 권한이 없는 사용자들에게 감추는 목적으로 사용
- 레코드 레벨 보안 (Row Level Security)
- 테이블내의 특정 레코드들을 특정 사용자나 특정 역할에만 접근 가능하게 설정
- 특정 사용자/그룹의 특정 테이블 대상 SELECT, UPDATE, DELETE 작업에 추가 조건을 다는 형태로 동작
이렇게 있지만 사실 가장 좋은 방법은 보안이 필요한 컬럼이나 레코드들을 별도 테이블로 구성하는 것이다. 더 나아간다면 이러한 정보를 데이터 시스템으로 로딩하지 않는 것이 가장 바람직하다.
Data Governance

Data Governance란 필요한 데이터가 적재적소에 올바르게 사용됨을 보장하기 위한 데이터 관리 프로세스를 말한다. 품질 보장과 데이터 관련 법규 준수를 주 목적으로 삼는다. 세부적으로 다음과 같은 것들을 이룩하기 위함이 Data Governance의 존재 의의이다.
- 데이터 기반 결정에서 일관성
- 예: KPI등의 지표 정의와 계산에 있어 일관성
- 데이터를 이용한 가치 만들기
- Citizen data scientist가 더 효율적으로 일할 수 있게 도와주기
- Data silos 없애기
- 데이터 관련 법규 준수
- 개인 정보 보호 -> 적절한 권한 설정과 보안 프로세스가 필수적
