
📖 학습 주제
- 데이터 파이프라인
- Airflow
✏️ 주요 메모 사항 소개
데이터 파이프라인
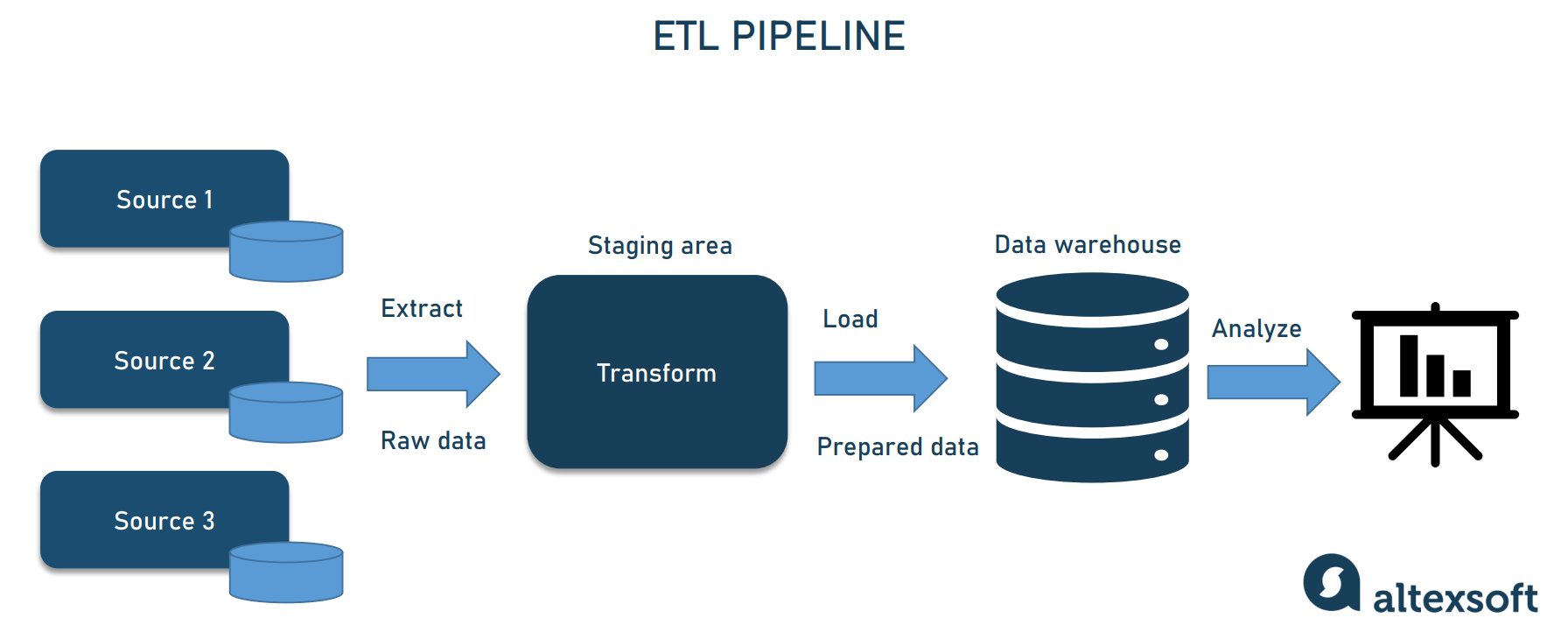
데이터를 소스로부터 목적지로 복사하는 작업으로 보통 코딩(Python, Scala) 혹은 SQL을 통해 이뤄짐, 대부분의 경우 목적지는 데이터 웨어하우스가 된다.
데이터 파이프라인의 종류
-
Raw Data ETL Jobs- 외부와 내부 데이터 소스에서 데이터를 읽어다가 (많은 경우 API 이용)
- 적당한 데이터 포맷 변환 후 (데이터의 크기가 커질 경우 Spark와 같은 툴이 필요해짐)
- 데이터 웨어하우스 로드
-
Summary / Report Jobs- DW(혹은 DL)로부터 데이터를 읽어 다시 DW에 쓰는 ETL
- Raw Data를 읽어서 일종의 리포트 형태나 써머리 형태의 테이블을 다시 만드는 용도
- 특수한 형태로는 AB 테스트 결과를 분석하는 데이터 파이프라인도 존재
-
Production Data Jobs- DW로부터 데이터를 읽어 다른 Storage(많은 경우 프로덕션 환경)로 쓰는 ETL
(써머리 정보가 프로덕션 환경에서 성능이유로 필요한 경우, 혹은 머신러닝 모델에서 필요한 피쳐들을 미리 계산해두는 경우)
- DW로부터 데이터를 읽어 다른 Storage(많은 경우 프로덕션 환경)로 쓰는 ETL
데이터 파이프라인 구축 시 고려할 점
-
데이터가 작을 경우 가능하다면 매번 통채로 복사해서 테이블을 만들기 (Full Refresh)
-
Incremental Update만이 가능하다면, 대상 데이터 소스가 갖춰야할 몇 가지 조건이 있다.
- 데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요하다.
- created
- modified
- deleted
- 데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야 한다.
- 데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요하다.
-
멱등성(Idempotency)을 보장하는 것이 중요
- 멱등성이란 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야 한다 (중복 데이터 X)
- 중요한 포인트는 critical point들이 모두 one atomic action으로 실행이 되어야 한다는 점이다 (SQL Transaction이 꼭 필요)
-
실패한 데이터 파이프라인을 재실행하는 것이 쉬워야 하고, 과거 데이터를 다시 채우는 과정(Backfill)도 쉬워야 한다.
-
데이터 파이프라인의 입력과 출력을 명확히 하고 문서화해야 한다.
- 비지니스 오너 명시 : 누가 이 데이터를 요청했는지를 기록으로 남기기
- 이게 나중에 데이터 카탈로그로 들어가서 데이터 디스커버리에 사용 가능함 (데이터 리니지가 중요)
-
데이터 파이프라인 사고시 마다 사고 리포트(post-mortem) 작성
- 목적은 동일한 혹은 아주 비슷한 사고가 또 발생하는 것을 막기 위함
- 사고 원인(root-cause)을 이해하고 이를 방지하기 위한 액션 아이템들의 실행이 중요해짐
- 기술 부채의 정도를 이야기해주는 바로미터
-
중요 데이터 파이프라인의 입력과 출력을 체크하기
- 아주 간단하게 입력 레코드 수와 출력 레코드의 수가 몇개인지 체크하는 것부터 시작
- 써머리 테이블을 만들고, Primary Key가 존재한다면 Uniqueness가 보장되는지 체크
- 중복 레코드 체크
... - 일련의 데이터 대상 유닛 테스트를 시행한다고 생각
실습1 : 간단한 ETL 데이터 파이프라인 만들어보기
1. redshift 연결하고 사용할 테이블 만들기
%sql postgresql://ID:PW@learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev
DROP TABLE IF EXISTS jwa4610.name_gender;
CREATE TABLE jwa4610.name_gender (
name varchar(32) primary key,
gender varchar(8)
);2. psycopg2를 이용하여 파이썬 코드에서 redshift 연결
import psycopg2
# Redshift connection 함수
# 본인 ID/PW 사용!
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "ID"
redshift_pass = "PW"
port = 5439
dbname = "dev"
conn = psycopg2.connect("dbname={dbname} user={user} host={host} password={password} port={port}".format(
dbname=dbname,
user=redshift_user,
password=redshift_pass,
host=host,
port=port
))
conn.set_session(autocommit=True)
return conn.cursor()3. ETL 함수 생성 (extract, transform, load)
import requests
def extract(url):
f = requests.get(url)
return (f.text)
def transform(text):
lines = text.strip().split("\n")
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
return records
def load(records):
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = "INSERT INTO jwa4610.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)
4. ETL 실행
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)5. 결과 확인
%%sql
-- 총 레코드 개수
SELECT COUNT(1)
FROM jwa4610.name_gender;
-- 레코드 확인
SELECT *
FROM jwa4610.name_gender
LIMIT 10;
-- 성별 별 레코드 개수
SELECT gender, COUNT(1) count
FROM jwa4610.name_gender
GROUP BY gender;
Airflow

Apache Airflow는 워크플로우와 데이터 파이프라인을 자동화하고 모니터링하기 위한 오픈 소스 플랫폼입니다.
DAG(Directed Acyclic Graph)를 사용하여 작업 간의 의존성을 정의하고 스케줄링할 수 있습니다. 이를 통해 복잡한 데이터 처리 작업을 효율적으로 관리하고 오류를 쉽게 추적할 수 있습니다.
Airflow 구성
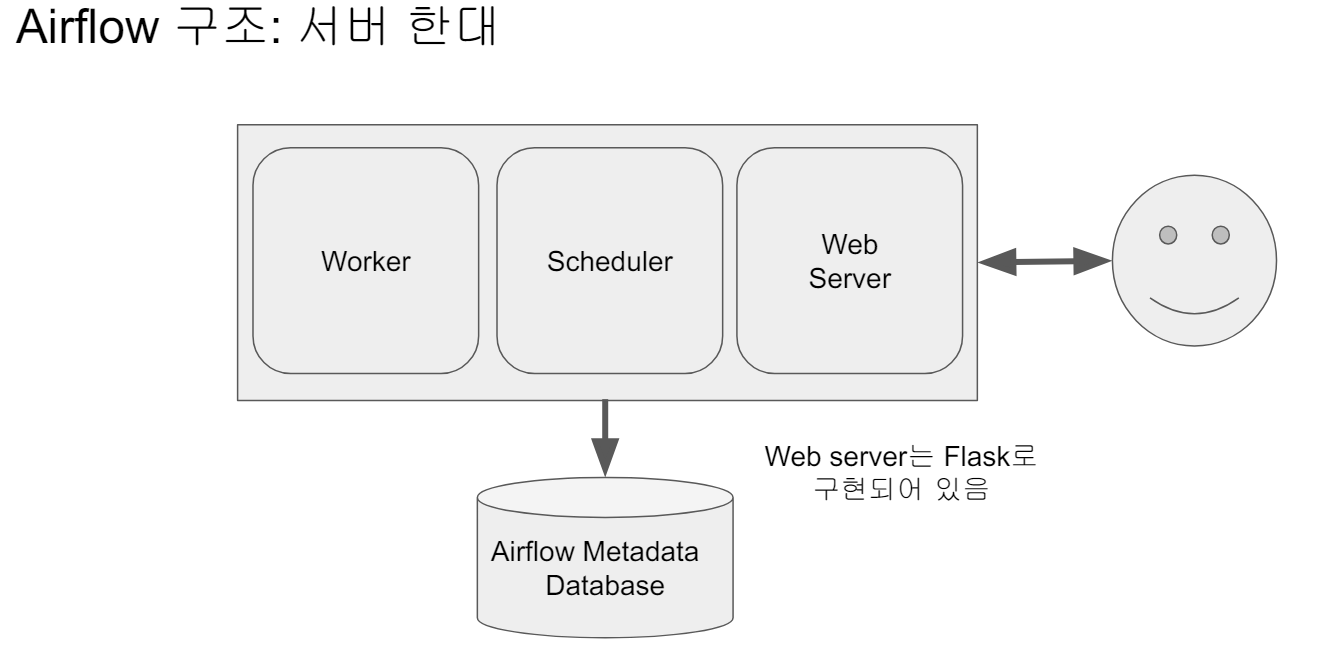
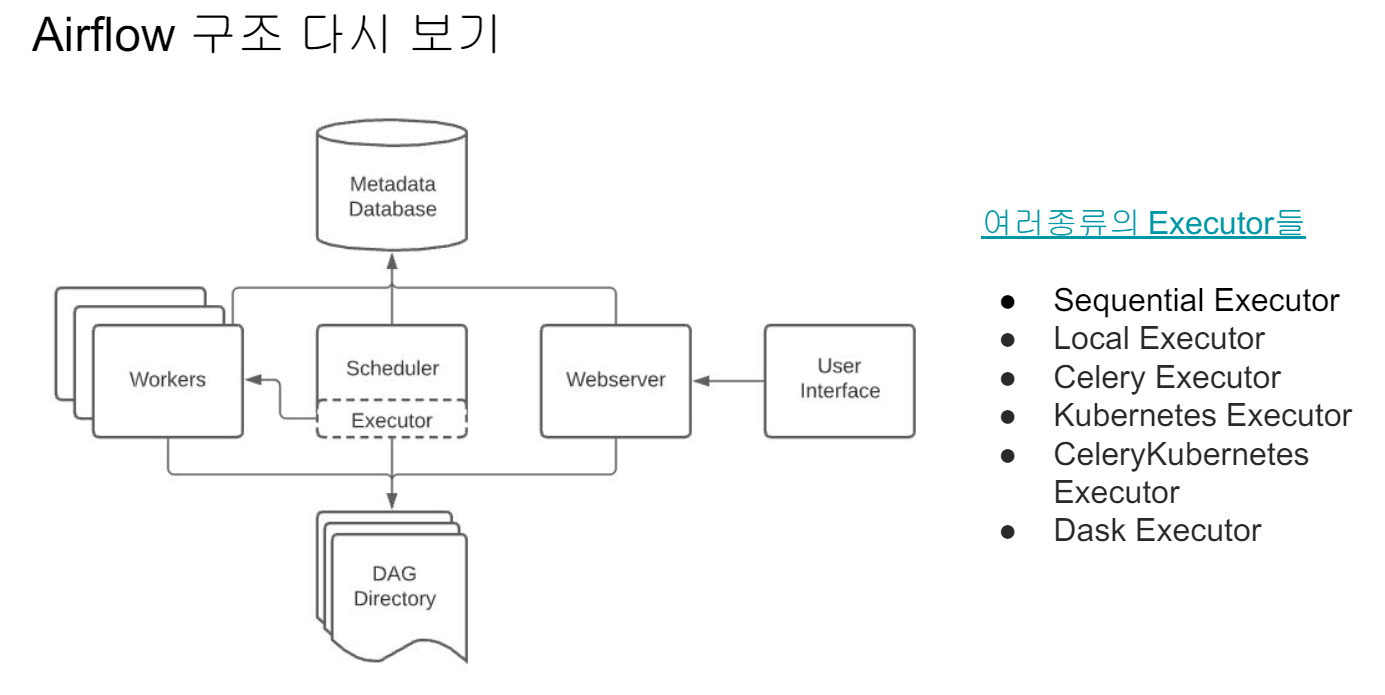
Airflow는 총 5개의 컴포넌트로 구성되어 있다.
-
웹 서버 (Web Server)
- 웹 UI는 스케줄러와 DAG의 실행 상황을 시각화
-
스케줄러 (Scheduler)
- DAG들을 워커들에게 배정하는 역할을 수행
-
워커 (Worker)
- 실제로 DAG를 실행하는 역할
-
메타 데이터 데이터베이스
- Sqlite가 기본으로 설치
-
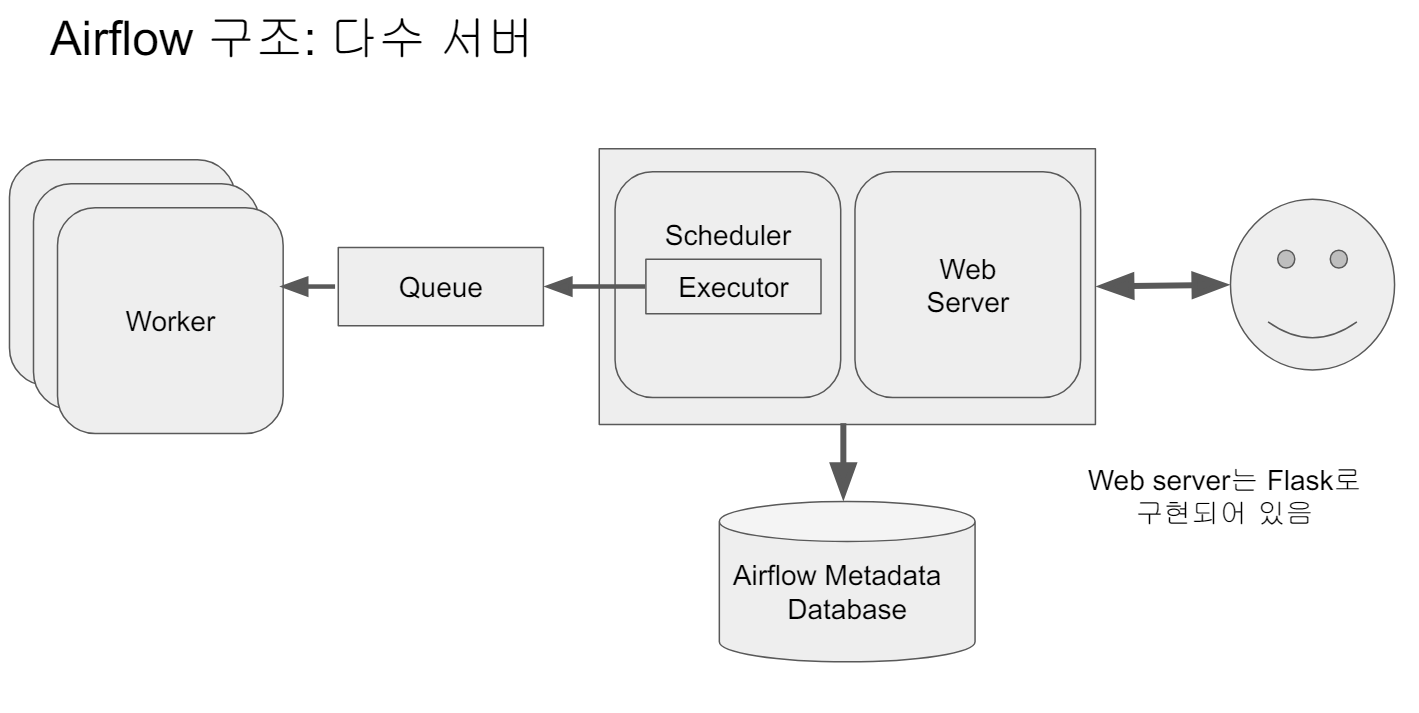
큐
- 다수서버 구성인 경우 사용, 이 경우 Executor가 달라짐
- 스케줄러와 각 DAG의 실행결과는 별도 DB에 저장된다, 기본으로는 SQLite지만, 실제 프로덕션에서는 MySQL이나 Postgres를 사용해야함
- Airflow는 스케일 업(더 좋은 사양의 서버로 변경), 스케일 아웃(서버 추가) 방법으로 스케일링 작업을 진행한다.
Airflow 장단점
[장점]
- 데이터 파이프라인을 세밀하게 제어 가능
- 다양한 데이터 소스와 데이터 웨어하우스를 지원
- 백필(Backfill)이 쉽다
[단점]
- 배우기가 쉽지 않음
- 상대적으로 개발환경을 구성하기가 쉽지 않음
- 직접 운영이 쉽지 않음. 클라우드 버전 사용이 선호
- GCP - "Cloud Composer"
- AWS - "Managed Workflows for Apache Airflow"
- Azure - "Data Factory Managed Airflow"
