
📖 학습 주제
- MySQL 테이블 복사하기
- Backfill 실행해보기
✏️ 주요 메모 사항 소개
MySQL 테이블 복사하기
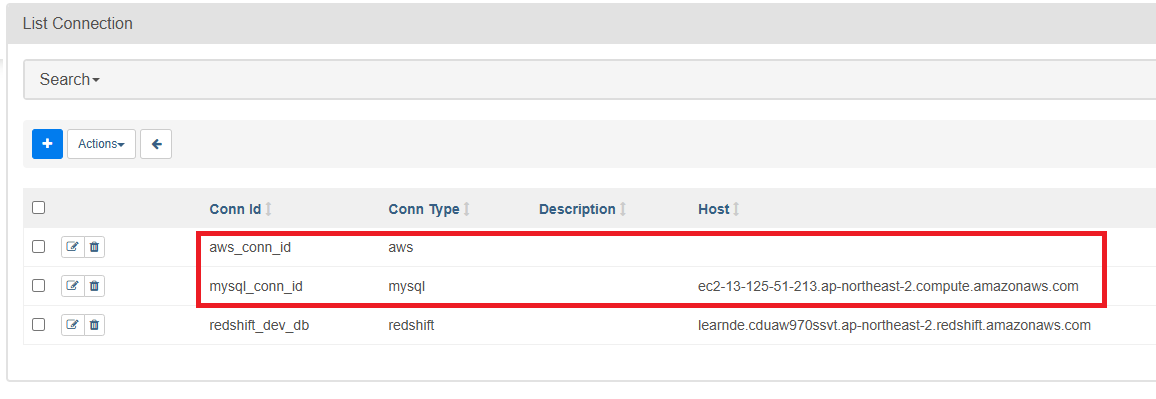
프로덕션 데이터베이스(MySQL)에서 데이터 웨어하우스(Redshift)로 테이블을 복사하는 방법을 알아보자.
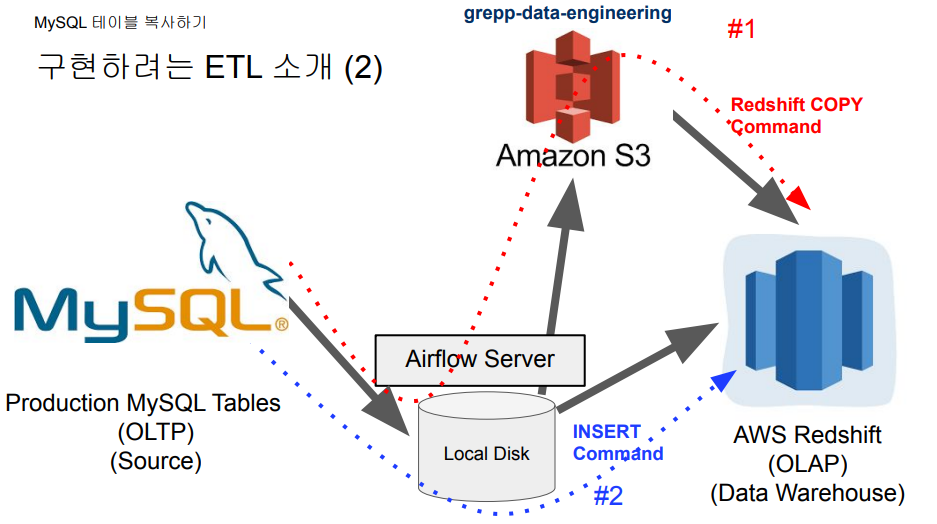
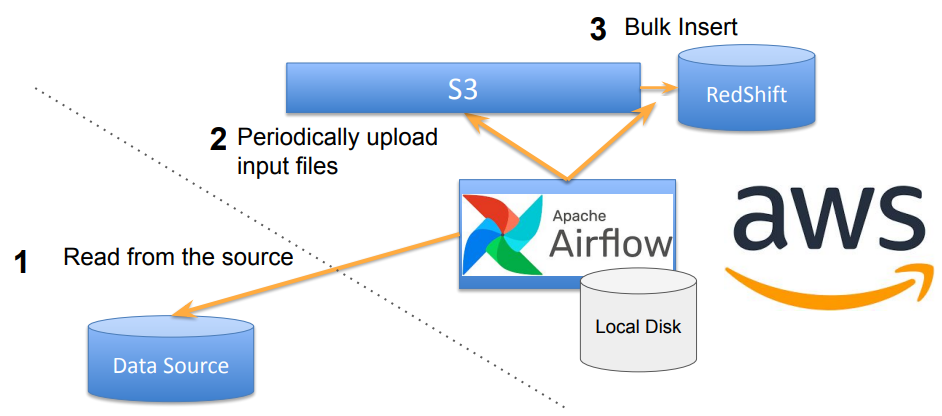
레코드가 적은 경우 #2 방식으로 INSERT INTO 명령어로 적재하면 되고, 레코드가 많은 경우 #1 방식같이 S3에 파일을 올린 뒤 Redshift로 COPY 명령어를 이용하여 벌크 업데이트 하는 방식을 선택하면 된다.
1. Connection 추가 (MySQL)
자신의 Mysql Host명과 ID, PW로 Airflow 웹 UI에서 Connection을 만들어주자.

2. AWS S3 접근 설정
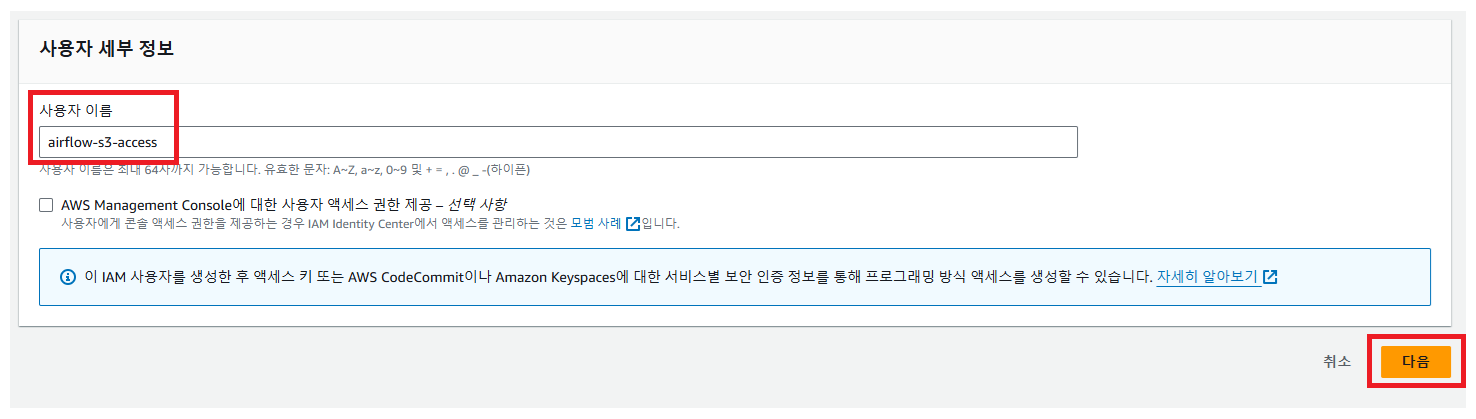
Access Key ID와 Secret Access Key를 사용하여 접근하기 위해 AWS IAM으로 별도의 사용자를 만들고, 그 사용자에게 S3 bucket을 읽고 쓸 수 있는 권한을 제공한다. 그 후 그 사용자의 Access Key ID와 Secret Access Key를 사용해서 S3에 접근하도록 설정.
- AWS 콘솔에서 IAM으로 이동 후 사용자를 추가
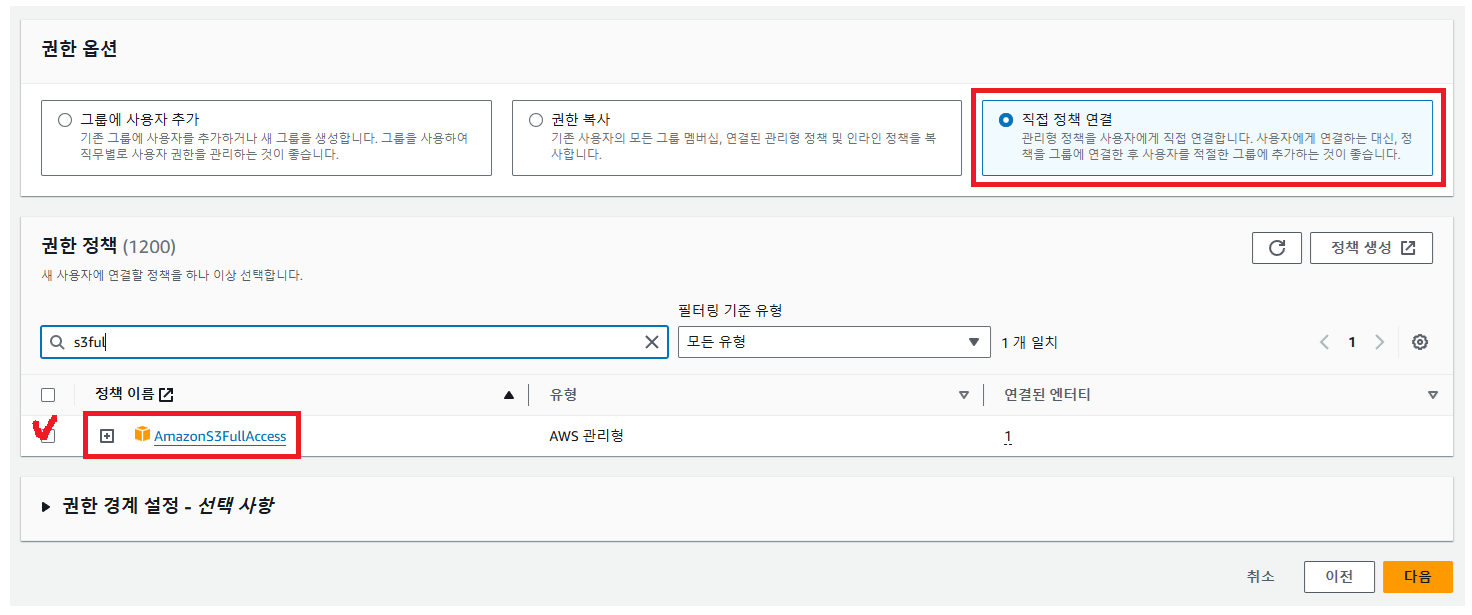
- 자신이 만든 사용자로 가서 보안 자격 증명 탭에서 액세스 키를 발급

이 액세스키를 가지고 aws에 연결할 것이기 때문에 두 가지 키를 별도로 저장해두자.
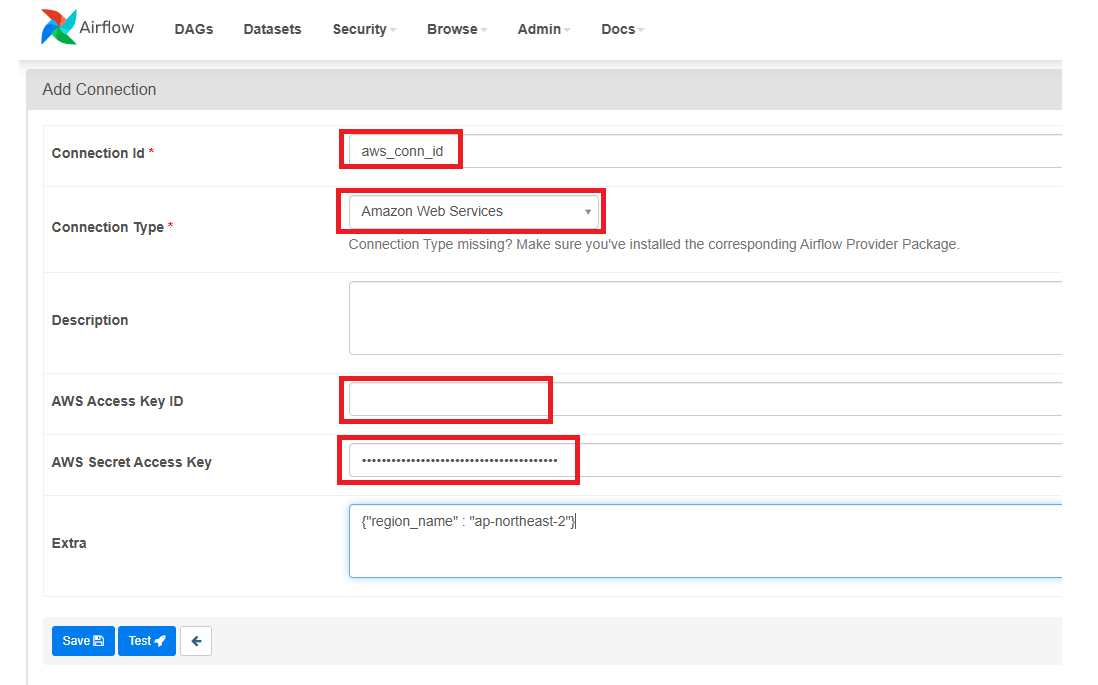
3. Connection 추가 (AWS)
4. DAG 작성
우리가 만들 DAG는 의 TASK는 총 두개로 SqlToS3Operator, S3ToRedshiftOperator를 만들어 보자
SqlToS3Operator- MySQL SQL 결과 -> S3
- (s3://grepp-data-engineering/{본인ID}-nps)
- s3://s3_bucket/s3_key
S3ToRedshiftOperator- S3 -> Redshift 테이블
- (s3://grepp-data-engineering/{본인ID}-nps) -> Redshift (본인스키마.nps)
- COPY command is used
DAG 코드 - Full Refresh
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
import json
dag = DAG(
dag_id = 'MySQL_to_Redshift',
start_date = datetime(2022,8,24), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 9 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
schema = "jwa4610"
table = "nps"
s3_bucket = "grepp-data-engineering"
s3_key = schema + "-" + table
mysql_to_s3_nps = SqlToS3Operator(
task_id = 'mysql_to_s3_nps',
query = "SELECT * FROM prod.nps",
s3_bucket = s3_bucket,
s3_key = s3_key,
sql_conn_id = "mysql_conn_id",
aws_conn_id = "aws_conn_id",
verify = False,
replace = True,
pd_kwargs={"index": False, "header": False},
dag = dag
)
s3_to_redshift_nps = S3ToRedshiftOperator(
task_id = 's3_to_redshift_nps',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = schema,
table = table,
copy_options=['csv'],
method = 'REPLACE',
redshift_conn_id = "redshift_dev_db",
aws_conn_id = "aws_conn_id",
dag = dag
)
mysql_to_s3_nps >> s3_to_redshift_npsDAG 코드 - Incremental Update
Incremental Update 방식으로 진행하려면 MySQL / PostgreSQL 테이블이라면 다음을 만족해야한다.
- created (timestamp) : Optional
- modified (timestamp)
- deleted (boolean) : 레코드를 삭제하지 않고 deleted를 True로 설정
S3ToRedshiftOperator로 구현하는 경우
- query 파라미터로 아래를 지정
SELECT * FROM A WHERE DATE(modified) = DATE(execution_date)
- method 파라미터로
UPSERT를 지정 upsert_keys파라미터로 Primary Key를 지정- 앞서 nps 테이블이라면 "id" 필드를 지정
전체 코드
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
import json
dag = DAG(
dag_id = 'MySQL_to_Redshift_v2',
start_date = datetime(2023,1,1), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 9 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
schema = "jwa4610"
table = "nps"
s3_bucket = "grepp-data-engineering"
s3_key = schema + "-" + table # s3_key = schema + "/" + table
sql = "SELECT * FROM prod.nps WHERE DATE(created_at) = DATE('{{ execution_date }}')"
print(sql)
mysql_to_s3_nps = SqlToS3Operator(
task_id = 'mysql_to_s3_nps',
query = sql,
s3_bucket = s3_bucket,
s3_key = s3_key,
sql_conn_id = "mysql_conn_id",
aws_conn_id = "aws_conn_id",
verify = False,
replace = True,
pd_kwargs={"index": False, "header": False},
dag = dag
)
s3_to_redshift_nps = S3ToRedshiftOperator(
task_id = 's3_to_redshift_nps',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = schema,
table = table,
copy_options=['csv'],
redshift_conn_id = "redshift_dev_db",
aws_conn_id = "aws_conn_id",
method = "UPSERT",
upsert_keys = ["id"],
dag = dag
)
mysql_to_s3_nps >> s3_to_redshift_nps
Backfill 실행해보기
상황을 먼저 가정해보자. Dailly Incremental DAG에서 2018년 7월달 데이터를 다 다시 읽어와야 하는 경우 만약 Airflow에서 추천하는 방식으로 Incremental Update르 구현했다면 Backfill이 쉬워진다.
주의점
- 모든 DAG가 backfill을 필요로 하지 않는다. Full Refresh방식을 이용한다면 backfill은 의미가 없다.
- 여기서 backfill은 일별 혹은 시간별로 업데이트를 하는 경우를 의미한다.
- 마지막 업데이트 시간 기준 backfill을 하는 경우라면 이런 경우(Data Warehouse 테이블에 기록된 시간 기준)에도 execution_date을 이용한 backfill은 필요하지 않다.
- 데이터의 크기가 굉장히 커지면 backfill 기능을 구현해 두는 것이 필수이다.
- airflow가 큰 도움이 되지만, 데이터 소스의 도움 없이는 불가능하다.
CLI 환경에서 Backfill
명령어 : airflow dags backfill dag_id -s 2018- 07- 01 -e 2018- 08- 01
- 다음이 준비되어 있어야한다.
- catchUp이 True로 설정되어 있어야 함
- execution_date을 사용해서 Incremental Update가 구현되어 있어야 함
- start_date 부터 시작하지만 end_date은 포함하지 않음
- 실행순서는 날짜/시간순은 아니고 랜덤. 만일 날짜순으로 하고 싶다면
- DAG default_args의 depends_on_past를 True로 설정하면 된다.
