
📖 학습 주제
- Spark 데이터 처리
- Spark 데이터 구조
- Spark 프로그램 구조
✏️ 주요 메모 사항 소개
Spark 데이터 처리
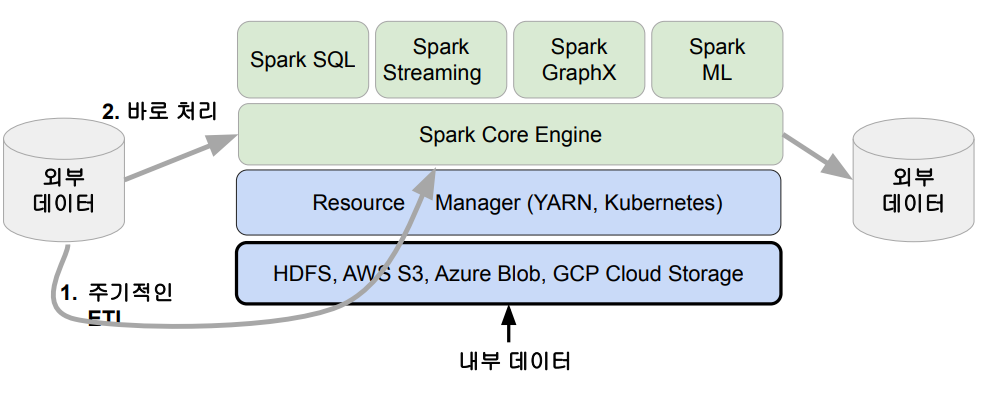
데이터 병렬처리가 가능하려면?
- 데이터가 먼저 분산되어야함
- 하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록 (128MB)
- hdfs-site.xml에 있는 dfs.block.size 프로퍼티가 결정
- Spark에서는 이를 파티션 (Partition)이라 부름. 파티션의 기본크기도 128MB
- spark.sql.files.maxPartitionBytes: HDFS등에 있는 파일을 읽어올 때만 적용됨
- 하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록 (128MB)
- 다음으로 나눠진 데이터를 각각 따로 동시 처리
- 맵리듀스에서 N개의 데이터 블록으로 구성된 파일 처리시 N개의 Map 태스크가 실행
- Spark에서는 파티션 단위로 메모리로 로드되어 Executor가 배정됨
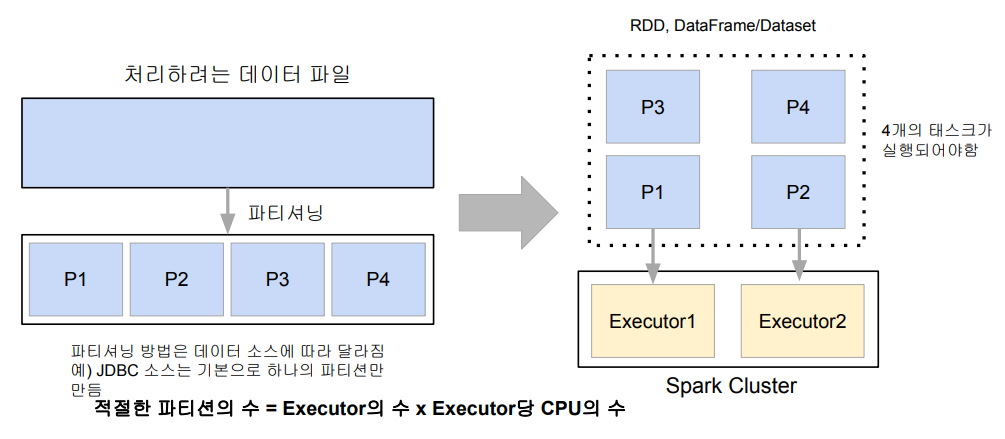
데이터프레임은 작은 파티션들로 구성되고, 데이터프레임은 한번 만들어지면 수정 불가능하다. (Immutable) 따라서, 입력 데이터프레임을 원하는 결과 도출까지 다른 데이터 프레임으로 계속 변환하는 작업이 필요하다.
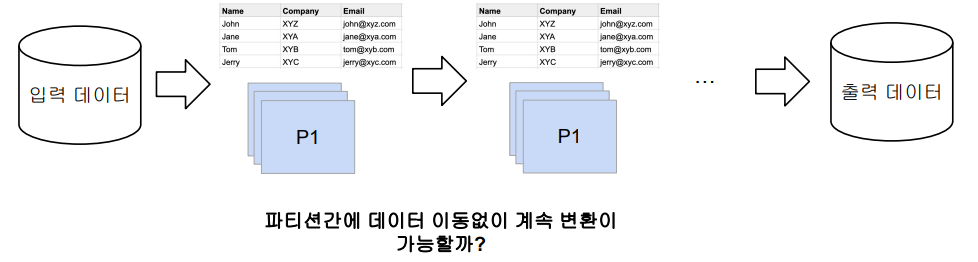
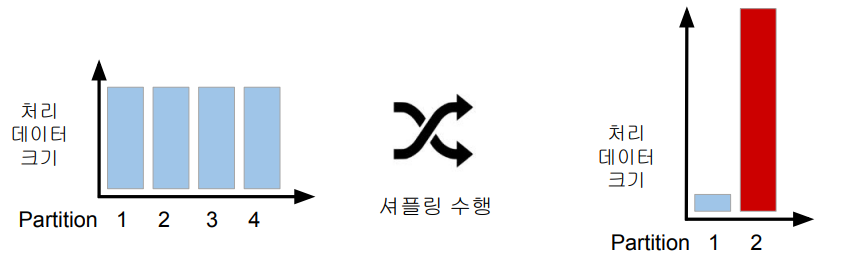
만약 파티션간에 데이터 이동이 필요한 경우 셔플링이 발생한다. 셔플링은 다음 두가지 경우에 발생한다.
- 명시적 파티션을 새롭게 하는 경우 (예: 파티션 수를 줄이기)
- 시스템에 의해 이뤄지는 셔플링 (예: 그룹핑 등의 aggregation이나 sorting)
이런 경우에 셔플링이 발생하고, 네트워크를 타고 데이터가 이동하게 된다. 만들어지는 파티션의 개수는 spark.sql.shuffle.partitions 프로퍼티의 값이 결정하게 된다. (기본/최대 200) 또한 오퍼레이션에 따라 파티션 수가 결정되기도 한다. (random, hashing partition, range partition 등)
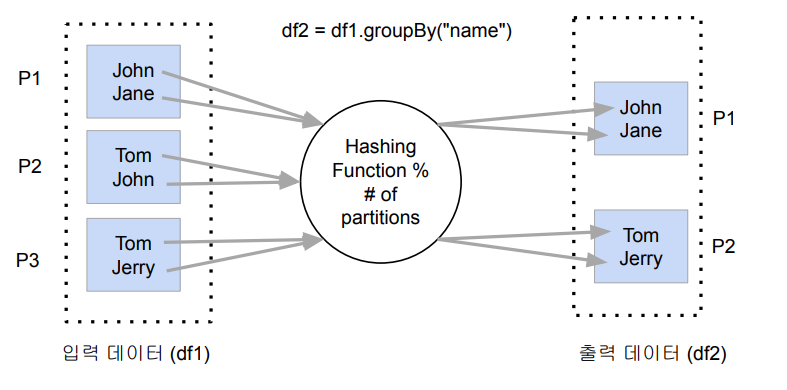
Data partitioning은 데이터 처리에 병렬성을 주지만 Datat Skewness라는 단점도 존재한다. 이는 데이터가 균등하게 분포하지 않는 경우, 주로 데이터 셔플링 후에 발생한다. 따라서 셔플링을 최소화하는 것이 중요하고 파티션 최적화를 하는 것이 중요하다.
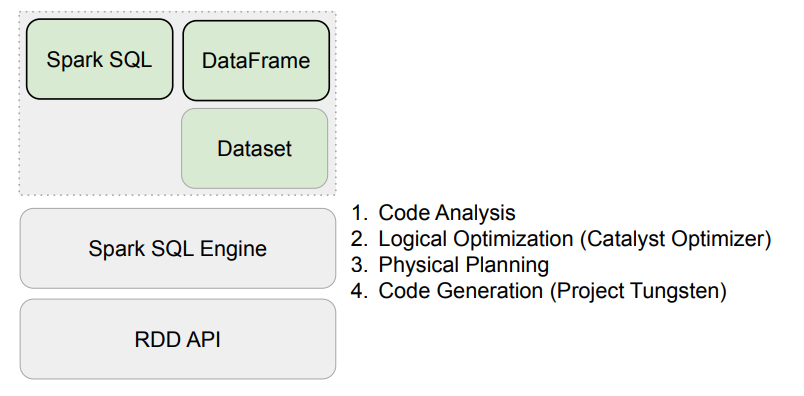
Spark 데이터 구조
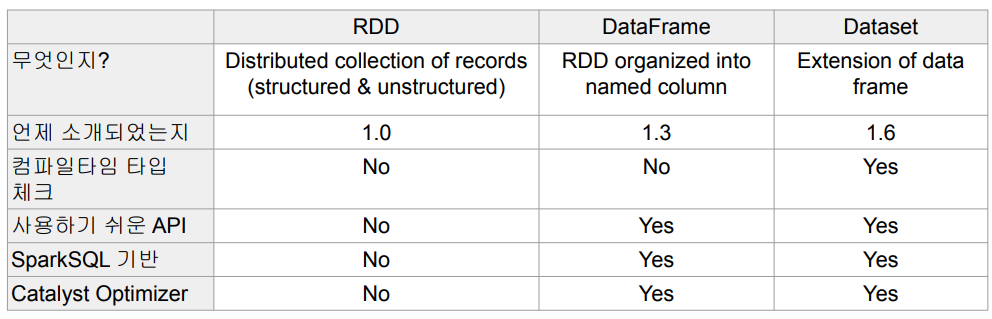
- RDD (Resilient Distributed Dataset)
- 변경이 불가능한 분산 저장된 데이터
- RDD는 다수의 파티션으로 구성
- 로우레벨의 함수형 변환 지원 (map, filter, flatMap 등등)
- 로우레벨 데이터로 클러스터내의 서버에 분산된 데이터를 지칭
- 레코드별로 존재하지만 스키마가 존재하지 않음
- 구조화된 데이터나 비구조화된 데이터 모두 지원
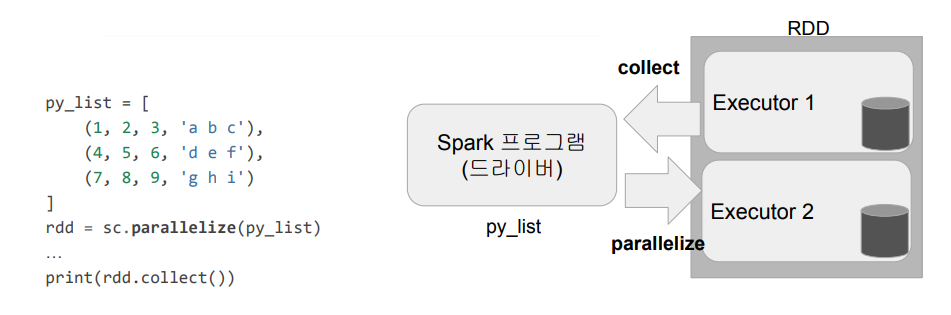
- 일반 파이썬 데이터는 parallelize 함수로 RDD로 변환
- 반대는 collect로 파이썬 데이터로 변환가능
- 변경이 불가능한 분산 저장된 데이터
- DataFrame(DataSet)
- 변경이 불가한 분산 저장된 데이터
- RDD와는 다르게 관계형 데이터베이스 테이블처럼 컬럼으로 나눠 저장
- 판다스의 데이터 프레임 혹은 관계형 데이터베이스의 테이블과 거의 흡사
- 다양한 데이터소스 지원: HDFS, Hive, 외부 데이터베이스, RDD 등등
- Dataset은 타입 정보가 존재하며 컴파일 언어에서 사용가능
- 컴파일 언어: Scala/Java에서 사용가능
- PySpark에서는 DataFrame을 사용
Spark 프로그램 구조
Spark Session
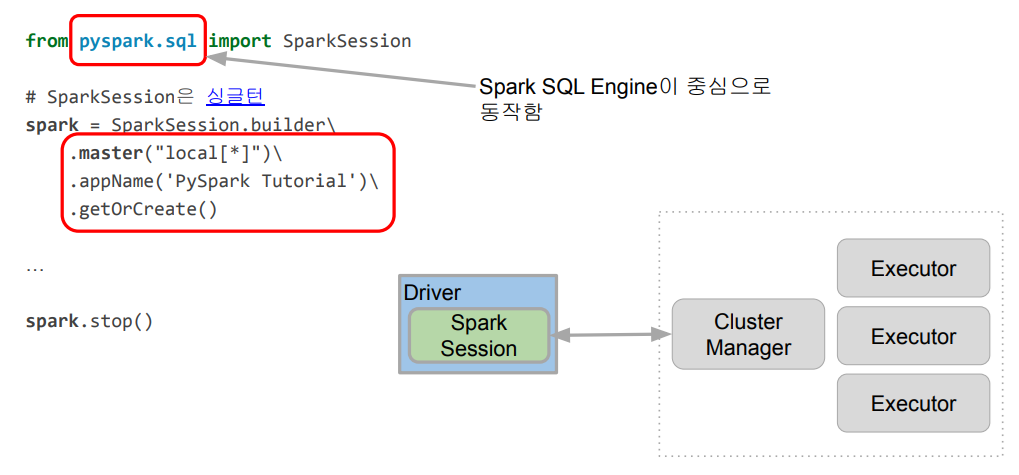
Spark 프로그램의 시작은 Spark Session을 만드는 것이다. 프로그램마다 하나를 만들어 Spark Cluster와 통신을 하게 된다. (Singleton) 이 Spark Session을 통해 Spark가 제공해주는 다양한 기능을 사용할 수 있다.
- DataFrame, SQL, Streaming, ML API 모두 이 객체로 통신
- config 메소드를 이용해 다양한 환경설정이 가능
- 단 RDD와 관련된 작업을 할때는 Spark Session밑의 sparkContext 객체를 사용
Session 환경설정
Spark Session을 만들 때 다양한 환경변수 설정이 가능하다. 몇가지 환경변수의 예를 알아보자
- executor별 메모리 : spark.executor.memory (기본 1g)
- executor별 CPU 수 : spark.executor.cores (기본 1)
- driver 메모리 : spark.driver.memory (기본 1g)
- Shuffle후 Partition의 수 : spark.sql.shuffle.partitions (기본/최대 200)
사용하는 Resource Manager에 따라 환경변수가 많이 달라진다. 이 환경변수를 설정하는 방법은 크게 4가지가 있다. 1,2 번은 보통 Spark Cluster 어드민이 관리하고, 4번으로 갈 수록 충돌 시 우선순위가 높다.
- 환경변수
- $SPARK_HOME/conf/spark_defaults.conf
- spark-submit 명령의 커맨드라인 파라미터
- SparkSession 만들 때 지정 (SparkConf)
- SparkSession 생성시 일일히 지정하는 방법
from pyspark.sql import SparkSession
# SparkSession은 싱글턴
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.config("spark.some.config.option1", "some-value") \
.config("spark.some.config.option2", "some-value") \
.getOrCreate()- SparkConf 객체에 환경 설정하고 SparkSession에 지정
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "PySpark Tutorial")
conf.set("spark.master", "local[*]")
# SparkSession은 싱글턴
spark = SparkSession.builder\
.config(conf=conf) \
.getOrCreate()전체적인 FLOW
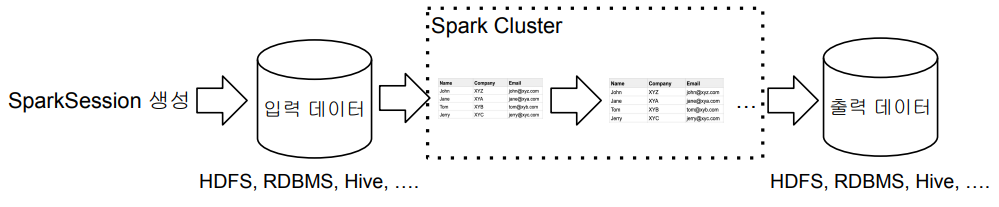
- Spark 세션(SparkSession)을 만들기
- 입력 데이터 로딩
- 데이터 조작 작업 (판다스와 아주 흡사)
- DataFrame API나 Spark SQL을 사용
- 원하는 결과가 나올때까지 새로운 DataFrame을 생성
- 최종 결과 저장
- spark.read(DataFrameReader)를 사용하여 데이터프레임으로 로드
- spark.write(DataFrameWriter)을 사용하여 데이터프레임을 저장
추가로 Spark Session이 지원하는 데이터 소스는 다음과 같은 것들이 있다.
- HDFS 파일
- CSV, JSON, Parquet, ORC, Text, Avro
- Hive 테이블
- JDBC 관계형 데이터베이스
- 클라우드 기반 데이터 시스템
- 스트리밍 시스템
