📖 학습 주제
- Spark Streaming
✏️ 주요 메모 사항 소개
Spark Streaming

실시간 데이터 스트림 처리를 위한 Spark API로, Kafka, Kinesis, Flume과 같은 다양한 소스에서 발생하는 데이터를 처리 가능하다. Join, Map, Reduce, Window와 같은 고급 함수도 사용가능 하다.
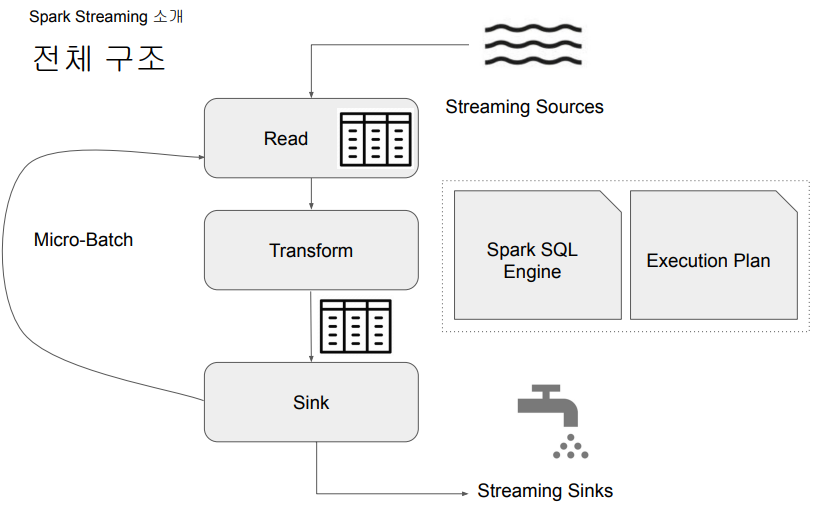
동작 방식
- 데이터를 마이크로 배치로 처리
- 계속해서 위의 과정을 반복(루프)
- 이렇게 읽은 데이터를 앞서 읽은 데이터에 머지
- 배치마다 데이터 위치 관리 (시작과 끝)
- Fault Tolerance와 데이터 재처리 관리 (실패 시)
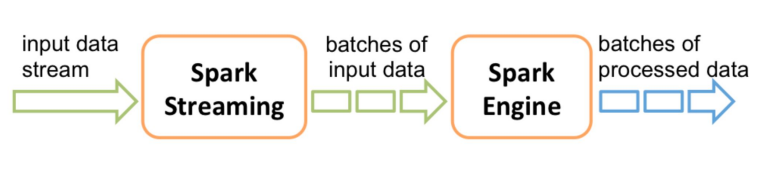
- Spark Streaming은 실시간 입력 데이터 스트림을 배치로 나눈 다음, Spark Engine에서 처리하여 최종 결과 스트림을 일괄적으로 생성
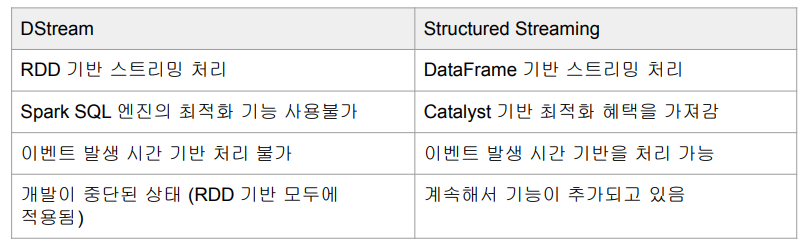
- DStream과 Structured Streaming 두 종류가 존재
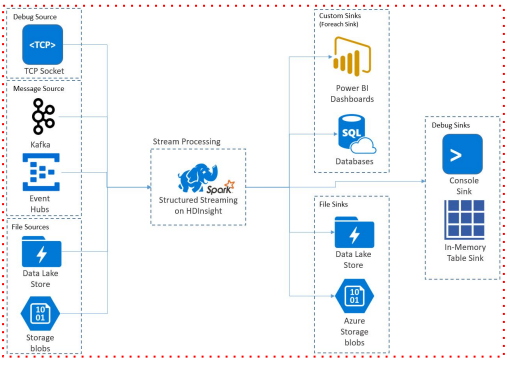
Source & Sink
소스와 싱크는 외부 시스템(소스)에서 스트리밍 데이터를 수집하고 처리된 데이터를 외부 시스템(싱크)으로 출력하는 것을 용이하게 하는 구성 요소를 말함.
- Source
- Kafka, Amazon Kinesis, Apache Flume, TCP/IP 소켓, HDFS, File 등을 Spark Structured Streaming에서 처리할 수 있도록 해줌
- 결국 Spark DataFrame으로 변환
- Spark DataFrame과 비교하면 readStream을 사용하는 점이 다름
- Kafka, Amazon Kinesis, Apache Flume, TCP/IP 소켓, HDFS, File 등을 Spark Structured Streaming에서 처리할 수 있도록 해줌
lines_df = spark.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", "9999") \
.load()
- Sink
- Sink는 Spark Structured Streaming에서 처리된 데이터를 외부 시스템이나 스토리지로 출력 가능하게 해줌
- Sink는 변환되거나 집계된 데이터가 어떻게 쓰이거나 소비되는지를 정의
- Source와 마찬가지로, Sink는 Kafka, HDFS, Amazon S3, Apache Cassandra, JDBC 데이터베이스 등과 같은 다양한 대상에 대해 사용 가능
- OutputMode: 현재 Micro Batch의 결과가 Sink에 어떻게 쓰일지 결정
- Append
- Update: UPSERT 같은 느낌
- Complete: FULL REFRESH 같은 느낌
word_count_query = counts_df.writeStream \
.format("console") \
.outputMode("complete") \
.option("checkpointLocation", "chk-point-dir") \
.start()