빅 리더 AI
1.[빅 리더 AI] 스터디 기록 (Dacon 청와대)

여기서 필요한 것은 종속변수인 category와 독립변수인 data이다.test 데이터는 data만 있는 것을 볼 수 있었다.결측치가 data열에 8개 있는 것을 확인했고, 데이터는 충분하기 때문에 결측치가 있는 행을 drop하는 것을 선택했다.형태소 분석에는 Rhin
2.[빅 리더 AI] 크롤러 1일차

크롤링 과정1\. Selenium으로 특정 웹 페이지를 크롤링하라고 명령한다.2\. Selenium은 소스코드에 지정된 Web Driver를 실행하여 웹 페이지에 접속한다.3\. 접속한 웹 페이지를 HTML 형태로 로컬로 가져완다.4\. 수집된 HTML 전체 코드에서
3.[빅 리더 AI] 크롤러 2일차
아래는 riss에서 키워드로 검색하여 옵션에 맞춰서 크롤링하고, 긁어온 데이터를 csv, xls로 저장하는 코드이다.수집하는 것은 제목, 저자, 소속기관, 발표년도, 논문집/자료집, 논문URL이다.페이지를 자동으로 넘기기 위한 부분부터 보겠다.한 페이지에 10건씩 나오
4.[빅 리더 AI] 크롤러 3일차
동작 과정1\. 웹사이트 접속2\. "제주도여행" 검색3\. 검색 결과들에서 제목, 지자체명, 해시태그를 추출4\. 게시물을 클릭하여 들어가 본문 내용 추출 후 뒤로가기5\. 이를 반복하면서 필요 시 페이지 전환이 크롤러를 만들 때 첫 번째 페이지의 정보는 잘 수집했으
5.[빅 리더 AI] 크롤러 4일차
네이버에서 특정 키워드로 검색 후 여러 건의 블로그의 이미지와 텍스트 정보 수집 네이버 블로그에서 작성일자를 주고 필터링하는 부분이 어려운 부분이다. 과정 키워드로 검색 VIEW 클릭 블로그 클릭 옵션 클릭 최신순으로 정렬 클릭 시작날자 클릭 년, 월, 일 클릭 종료
6.[빅 리더 AI] 크롤러 자습
국민 청원 사이트에서 원하는 카테고리의 청원 정보를 읽어온다.읽어오는 정보는 카테고리, 제목, 동의수, 동의달성률, 동의기간, 남은기간, 청원의 취지, 청원의 내용이다.국민 청원 홈페이지의 경우 아마존처럼 스크롤이 필요한 구간도 없고, 이미지를 저장할 것도 없어서 아주
7.[빅 리더 AI] 머신러닝 1~4일차
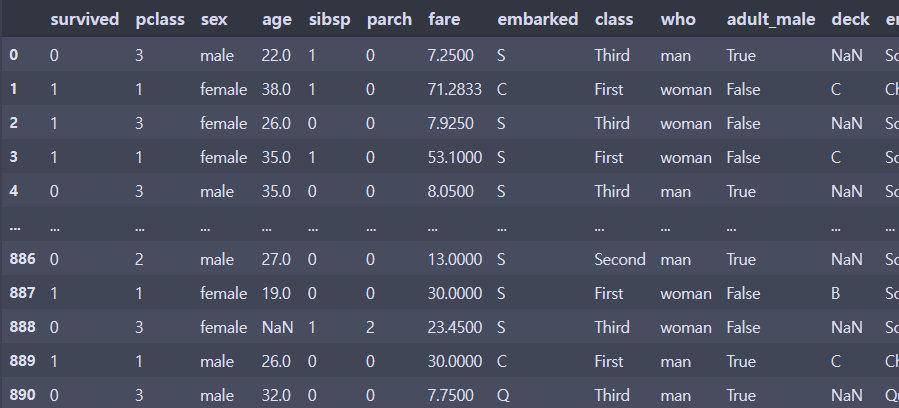
빅데이터 분석 절차1\. 기획 (위험성 분석)2\. 데이터 수집3\. 데이터 전처리4\. 모델 선택5\. 평가 및 적용위험성 분석예측에 실패했을 때의 위험성을 그 분야 전문가와 논의하는 것모델의 정확도보통 95% 이상이면 상용화할만 하다고 판단함데이터 확인결측치 제거