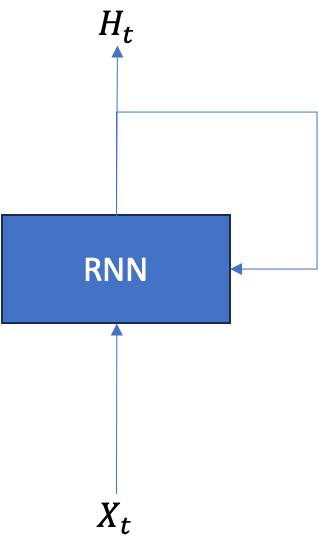
1. 순환 신경망(Recurrent Neural Network)
순환 신경망은 순서가 있는 시계열 데이터를 다루기 위해 사용하는 인공 신경망이다. 문장 역시 단어의 시퀸스이므로 자연어 처리에도 순환 신경망을 사용할 수 있다.
순환 신경망이라는 이름이 붙은 이유는 네트워크 내에 순환하는 경로가 있다는 것이다. 순환 신경망의 출력값은 다시 다음 시점의 순환 신경망의 입력으로 전달되며 순환하는 경로를 만든다. 정보가 계속해서 순환되기 때문에 과거의 정보를 기억하면서 최신 정보를 갱신할 수 있다.
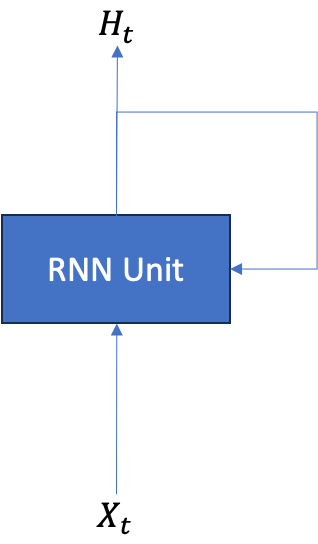
순환 신경망의 순환 과정을 전개해서 나타내면 아래 그림과 같다. 왼쪽에서 오른쪽으로 은닉 상태()가 전파되는 것은 시간 순서에 따라 이전 시점의 은닉 상태가 내부적인 연산을 거쳐 다음 시점의 입력으로 전달되는 것이다. 따라서 그림에 나타나는 다수의 RNN 계층은 시점만 다를 뿐 똑같은 가중치를 공유하는 같은 계층이다.
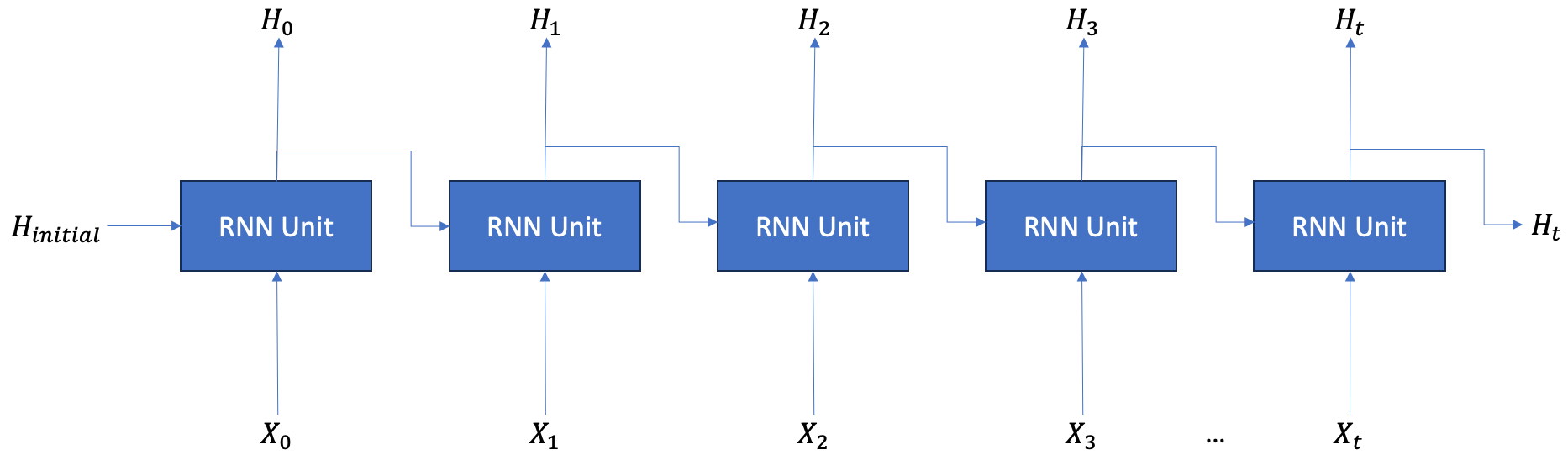
2. 순환 신경망 유닛의 순전파
순환 신경망은 시퀸스 길이만큼의 유닛을 가진다. 순환 신경망 유닛이 순전파 과정에서 이전 시점의 은닉층()과 현재 시점의 입력()을 이용해 다음 시점의 은닉 상태()을 생성하는 과정은 다음 수식과 같다.
순환 신경망 유닛의 순전파에 해당하는 계산 그래프는 다음과 같다.
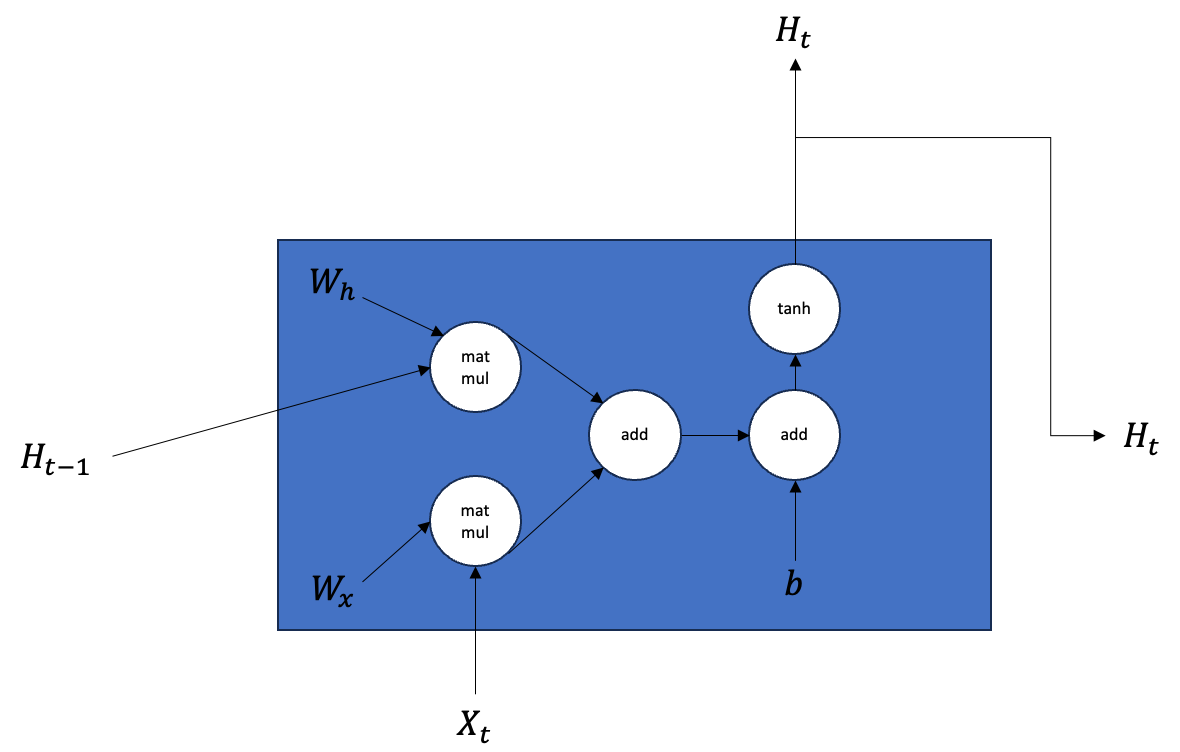
계산 그래프를 통해 확인할 수 있는 사실은 유닛의 출력인 는 똑같은 은닉 상태가 복사돼 두 개로 분기된다는 점이다. 하나는 다음 레이어의 입력으로 사용되고 나머지 하나는 다음 시점에 해당하는 유닛의 입력으로 사용된다.
앞서 언급한 순전파 과정을 참고하여 순환 신경망 유닛을 numpy를 통해 구현하면 다음과 같다.
class RNNUnit:
def __init__(self, Wx, Wh, b):
# B: batch size, I: inpuy dimension, H: hidden dimension
# Wx : [I, H]
# Wh : [H, H]
# b : [1, H]
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
# x : [B, I]
# h_prev : [B, H]
Wx, Wh, b = self.params
# t: [B, H]
t = np.matmul(h_prev, Wh) + np.matmul(x, Wx) + b
# h_next: [B, H]
h_next = np.tanh(t)
# backward 계산에 필요한 값을 cache로 저장
self.cache = (x, h_prev, h_next)
return h_next
3. 순환 신경망 유닛의 역전파
역전파 과정은 순전파의 반대 순서로 진행된다. 순환 신경망의 활성화 함수로 함수가 사용되기 때문에 의 미분을 알아야 한다. 의 미분은 다음과 같다. 자세한 미분 과정은 다음 글을 참고하면 된다.
앞서 작성한 순환 신경망 유닛의 순전파에 대응하는 역전파 과정을 코드로 구현하면 다음과 같다.
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
# h_next = np.tanh(t)
# dh_next / dt [B, H]
dt = dh_next * (1- h_next**2)
# t = np.matmul(h_prev, Wh) + np.matmul(x, Wx) + b
# dt / db (b는 브로드캐스팅 되었음) [1, H]
db = np.sum(dt, axis=0)
# dt / dWh [H, H]
dWh = np.matmul(h_prev.T, dt)
# dt / dh_prev [H, H]
dh_prev = np.matmul(dt, Wh.T)
# dt / dWx [I, H]
dWx = np.matmul(x.T, dt)
# dt / dx [B, I]
dx = np.matmul(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
4. 순환 신경망 구현
전체 순환 신경망은 순환 신경망 유닛 개가 순서에 따라 연결된 형태이다. 이때 는 시퀸스의 길이를 의미한다. 전체 순환 신경망은 시퀸스()를 입력받고 시퀸스의 각 시점의 데이터에 해당하는 은닉 상태()를 출력하는 네트워크로 표현할 수 있다.
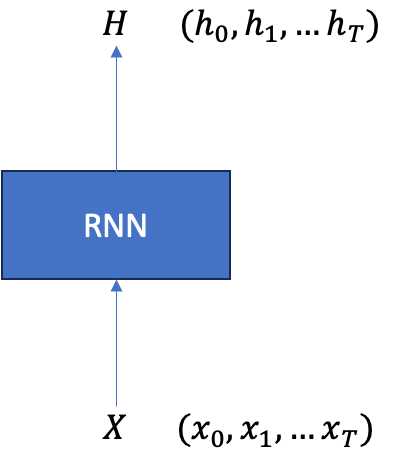
앞서 언급한 것들을 참고해서 RNN을 코드로 구현해보자. 순전파 과정을 구현할 때 중요한 점은 가중치 가 전체 유닛에서 공유된다는 점과 이전 유닛의 출력이 다음 유닛의 입력으로 사용된다는 점이다.
class RNN:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layer = None
self.h, self.dh = None, None
# stateful을 True로 설정하면 은닉 상태를 유지한다는 의미임
self.stateful = stateful
# 초기 은닉상태 설정
def set_state(self, h):
self.h = h
# 은닉상테 초기화
def reset_state(self):
self.h = None
# 순전파
def forward(self, xs):
Wx, Wh, b = self.params
B, T, I = xs.shape # [batch, time, input_dim]
I, H = Wx.shape # [input_dim, hidden_dim]
self.layers = []
# 시간 순서에 따른 은닉 상태를 저장할 텐서
hs = np.empty((B, T, H), dtype='f')
# 만약 은닉 상태가 초기화 되지 않았거나 은닉 상태를 유지하지 않는다고 설정했다면
if not self.stateful or self.h is None:
# 은닉 상태 초기화
self.h = np.zeros((B, H), dtype='f')
for t in range(T):
# RNN 유닛 생성할 때 같은 가중치를 공유함
layer = RNNUnit(*self.params)
# 시간에 따른 순전파. 계산된 은닉 상태가 다음 유닛의 입력으로 사용됨
self.h = layer.forward(xs[:, t, :], self.h)
# 시간에 따라 은닉 상태 저장
hs[:, t, :] = self.h
self.layers.append(layer)
return hs역전파를 구현할 때 주의할 점은 앞서 언급한 것과 같이 순환 신경망 유닛의 출력이 2개로 분기된다는 점이다. 순전파 과정에서 출력이 분기했다는 것은 동일한 출력이 다른 계산을 위해 여러번 사용됐다는 의미이므로 역전파 과정에서는 분기된 그래디언트가 합산되어야 한다. 또한 각 시점마다 그래디언트가 계산되고 똑같은 가중치가 전체 시점에서 공유하기 때문에 순환 신경망의 가중치에 대한 최종적인 그래디언트는 각 시점의 가중치에 대한 그래디언트를 모두 더한 것이 된다. 따라서 해당 사항을 주의하여 역전파를 구현하면 다음과 같다.
def backward(self, dhs):
# dhs는 위쪽 레이어에서 전파된 그래디언트
# dhs : [B, T, H]
# dh는 다음 시점의 유닛에서 전파된 그래디언트
# dh : [B, H]
# dxs는 아래쪽 레이어로 전파될 그래디언트
# dxs : [B, T, I]
Wx, Wh, b = self.params
B, T, H = dhs.shape
I, H = Wx.shape
# 아래쪽 레이어로 전파될 그래디언트를 담을 텐서
dxs = np.empty((B, T, I), dtype="f")
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
# 순전파 과정에서 RNN 유닛의 출력인 h는 두 개로 분기되어 각각 위쪽 레이어와 다음 시점의 유닛으로 전파되기 때문에
# h에 대한 그래디언트를 구하기 위해서는 위쪽에서 전파된 그래디언트와 다음 시점에서 전파된 그래디언트를 더해줘야함
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
# 똑같은 가중치를 공유하기 때문에 각 시점의 그래디언트를 모두 더해줘여함
for i, grad in enumerate(layer.grads):
grads[i] += grad
# 가중치에 대한 그래디언트 갱신
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs