Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019.
https://arxiv.org/abs/1810.04805
Introduction
BERT(Bidirectional Encoder Representations from Transformers)란 2019년 Google에서 발표한 '양방향 인코더 표현을 위한 트랜스포머' 모델이다.
2017년 트랜스포머 아키텍처가 등장한 이후, 몇몇 언어 표현 모델들(ELMo - Peters et al.,2018; GPT - Radford et al., 2018)과 다르게 BERT는 왼쪽/오른쪽 context를 모두 조건으로 하여 unlabled text들로부터 pre-training하도록 설계되었다.
BERT는 pre training 과정에서 MLM(masked language model) 방식의 목표를 사용했다. 이는 Cloze task(Taylor, 1953)에서 영향을 받은 것으로, 입력의 일부 토큰을 무작위로 마스킹하고, 주변 문맥만을 기반으로 해당 토큰의 원래 어휘를 유추하도록 학습한다. MLM을 통해 왼쪽과 오른쪽의 문맥을 모두 결합할 수 있어 깊이 있는 bidirectional transformer를 학습할 수 있게 된다.
또한, 다음 누장을 예측하는(next sentence prediction)을 추가하여 pairing단위의 text 또한 사전 학습 한다.
결과적으로 BERT는 GPT 계열 모델과 달리, 양방향 학습의 중요성을 입증하였다. 그리고 광범위한 bidirectional pre-training 이후에는 출력 레이어를 1개만 붙여 fine-tuning하여도 질문 응답, 문장 추론 등 다양한 task에 대해 SOTA급의 모델을 만들 수 있음을 실증하였다.
BERT
Model Architecture
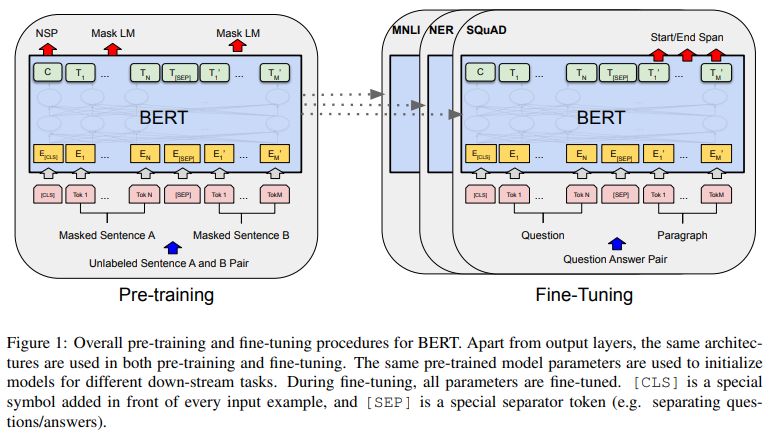
BERT의 모델 아키텍처는 Transformer Encoder를 여러 개 쌓은 형식(multi-layer bidirectional transformer encoder)이다.
아키텍처에서 특별한 부분은 없으며, 연구자들 또한 "based on the original implementation described in Vaswani et al. (2017) and released in the tensor2tensor library" 라고 언급하며 기존에 있던 multi layer transformer의 구조를 거의 그대로 가져다 썼음을 알렸다.
다만 BERT의 주요한 점은 프레임워크를 구성하는 두 단계, pre-training과 fine-tuning이다.
이 중 pre-training은 광범위한 unlabeled text data에 의해 수행되어 파라미터를 학습시키지만, 원하는 task별로 모델을 fine-tuning할 수 있다. 이 과정에서 BERT의 특이한 점은 모든 작업들에서 통일된 아키텍처(unifired architecture)를 사용한다는 점이다.
즉, pre-training model과 downstream model간의 차이가 거의 없다.
연구자들은 주로 BERTBASE(≈110M), BERTLARGE(≈340M) 모델에 대한 결과를 보고하였으며, 비교를 위해 OpenAI의 GPT와 동일한 모델 크기로 설정되었다.
Input/Output Representations
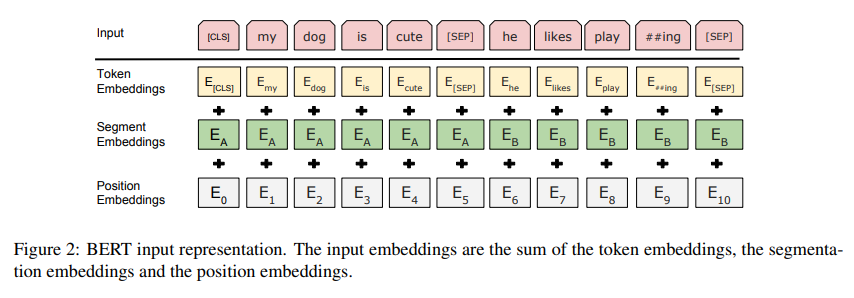
BERT의 입/출력 표현 방식은 single sentence와 pair of sentence이다. 이들은 모두 하나의 시퀀스 안에서 명확하게 표현된다.
여기서 sentence란 "연속된 텍스트(span of contiguous text)"이며, sequence란 토큰들의 시퀀스이다. 임베딩으로는 WordPiece Embedding(Wu et al.m 2016)을 사용했으며, 어휘 크기는 30,000 토큰이다.
Figure 2에서 볼 수 있듯이, input sequence의 첫 번째 토큰은 항상 특수한 분류 토큰 [CLS]이다. 이 CLS 토큰은 시퀀스의 전체를 대표하는 종합적 표현(aggregate sequence representation)으로 사용된다.
문장의 pair를 입력으로 넣는 경우, 두 문장을 하나의 시퀀스로 합쳐 넣는다. 이 때, 두 문장을 구분하는 방법은 1) 두 문장 사이에 구분 토큰 [SEP]을 삽입한다. 2) 각 토큰에 이 토큰이 문장 A에 속하는지, B에 속하는지를 나타내는 임베딩(learned embedding)에 추가한다.
Figure 1을 살펴보면, 입력 임베딩은 E로, CLS의 input representation는 C로, i번째 입력 토큰의 input representation는 Ti로 출력한다.
Figure 2에서 보듯이, 각 토큰의 input representation은 toekn embedding(토큰에 대한 임베딩), segment embedding(문장이 A/B 어느 쪽에 속하는지 알려주는 벡터), position embedding(토큰의 위치)을 더하여 구성한다.
Pre-training
Introducing 단계에서 설명하였듯이, BERT는 기존의 전통적 모델과는 다르게, left-to-right 혹은 right-to-left로 학습하지 않는다.
BERT는 두 가지의 unsupervised learning을 통해 pre-training을 하는데, 이는 Figure 1의 왼쪽에 해당하는 단계이다.
#task1 Masked LM (MLM)
직관적으로, deep bidirectional model은 left-to-right 혹은 right-to-left로 학습하는 shallow concatenation보다 강력하다.
하지만, conditional LM은 자기 참조 문제로 인해 이러한 양방향 학습이 불가능하다. 양방향 조건을 허용한다면, 각 단어가 간접적으로 자기 자신을 볼 수 있기 때문에 목표 단어를 너무 쉽게 예측할 수 있기 때문이다.
따라서 BERT는 깊이 있는 양방향 학습을 위해 토큰들 중에 일부를 무작위로 마스킹한 뒤, 가린 토큰을 예측하도록 모델을 학습시킨다(MLM).
구체적으로, masking된 토큰에 해당하는 fianl hidden vector를 어휘 전체에 대한 softmax로 보내어 일반적인 Language model과 동일하게 예측을 수행한다.
- 모든 실험에서 WordPiece 토큰 중 15%를 무작위로 가렸다.
- 입력 전체를 복원하는 것이 아닌, 마스킹된 단어만 예측한다.
- 학습 시 사용하는 [MASK]토큰이 fine-tuning 시에는 나타나지 않는다. 이에 따라 pre-traning과 fine-tuning 간의 mismatch가 일어난다.
마지막 부분을 완화하기 위해 masking할 토큰을 항상 [MASK]로 대체하지 않는다. training data 생성기가 토큰들 중 15%의 무작위 위치를 선정하고, 선택된 i번째 토큰을 1) [MASK]토큰으로 대체한다(80%), 2) 임의의 랜덤 토큰으로 변경한다(10%), 3) 원래 토큰을 그대로 유지한다(10%)로 대체한다.
이렇게 얻은 hidden vector Ti를 이용해 원래의 토큰을 CEL(Cross Entropy Loss)를 사용해 예측한다.
#task2 Next Sentence Prediction (NSP)
NSP 작업은 두 문장(pair sentence)간의 이해를 필요로 하는데, 이는 언어 모델링 만으로는 학습하기 어려운 단계이다.
이를 위해 연구자들은 corpus에서 쉽게 생성할 수 있는 이진 분류 형태의 NSP 과제를 pre-training 단계에 추가하였다.
구체적으로, pre-training 예제에서 문장 A와 B를 선택했을 때 다음의 두 라벨 중 하나를 예측한다.
- isNext label : B가 실제로 A 다음에 나오는 경우(50%)
- NotNext label : B가 corpus에서 무작위로 선택된 문장인 경우
Figure 1에서 볼 수 있듯이, [CLS]토큰의 hidden vector(C)를 NSP 예측에 사용한다.
재미있는 점은 NSP에서 [CLS]벡터 C는 fine-tuning 이전에는 의미 있는 표현이 아니라는 점이다. 이는 NSP에 맞추어 훈련된 상태이기 때문에, [CLS]가 다른 task에 최적화되어있지 않다는 의미이다.
Pre-training Data
연구자들은 두 가지의 데이터를 사용하였다.
- BookCorpus(800M words)(Zhu et al., 2015)
- Wikipedia(2,500M words)
wikipedia는 본문의 text만을 추출하였으며, 문장이 섞인 corpus가 아닌 document-level의 corpus를 사용하는 것이 중요하다.
Fine-tuning BERT
BERT의 Fine-tuning 과정은 상당히 간단하다.
기존의 모델들은 일반적으로 두 텍스트를 각각 인코딩하여 bidirectional corss-attention을 적용하는데(Parikh et al., 2016, Seo at al.,2017) BERT는 self-attention 만으로 두 단계를 통합하기 때문이다.
조금 풀어서 설명하자면 BERT는 두 문장 간의 교차 어텐션을 구하는 것이 아니라, 두 문장을 [SEP] 토큰을 기준으로 이어 붙여 Transformer Encoder에 한 번에 넣는다. 따라서 Transformer의 특성 상, self-attention을 통해 모든 토큰이 서로를 참조할 수 있어서 자연스럽게 두 문장 간의 attention도 교환이 되는 것이다.
각 task별로 downstream model을 만들려면
입력(input)은 다음과 같이 넣어준다.
- 1) 패러프레이징(Paraphrasing) → 문장 쌍(sentence pairs)
- 2) 함의 판별(Entailment) → 가설(Hypothesis)-전제(Premise) 쌍
- 3) 질문 응답(QA) → 질문(Question)-지문(Passage) 쌍
- 4) 텍스트 분류/시퀀스 태깅 → 문장-∅(빈 입력) 쌍
출력은 다음과 같은 형태일 것이다.
- 1) 토큰 수준 작업(token-level tasks, 예: 시퀀스 태깅, 질문 응답) → 각 토큰의 표현을 출력층에 전달
- 2) 분류 작업(classification tasks, 예: 함의 판별, 감성 분석) → [CLS] 토큰의 표현을 출력층에 전달
※ pre-training에 비해 fine-tuning은 상대적으로 매우 저렴하다.
Experiment
GLUE
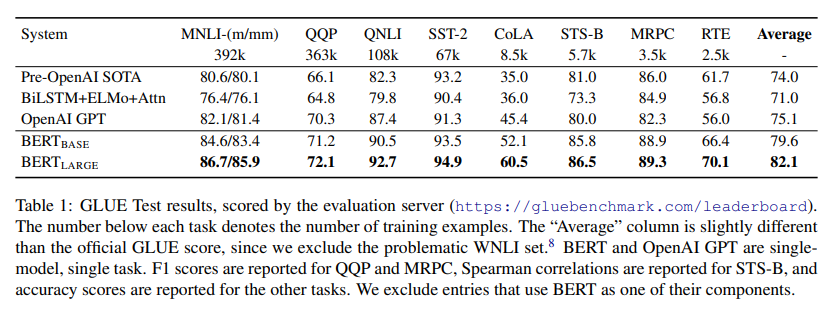
GLUE(General Language Understanding Evaluation, Wang et al., 2018a)는 다양한 NLU 작업들로 구성되어있는 벤치마크 데이터셋이다.
BERTBASE와 BERTLARGE가 모두 기존 작업에 대해 SOTA를 크게 앞서는 것을 알 수 있다. 그리고 공식 GLUE 리더보드에서 BERTLARGE의 점수는 80.5로 동일 시점의 GPT의 점수 72.8을 크게 앞섰다.
이외에도 BERTLARGE가 대부분 BERTBASE보다 성능이 앞서고, 특히 학습 데이터가 적은 task들에서 큰 폭으로 우세하였다.
SQuAD
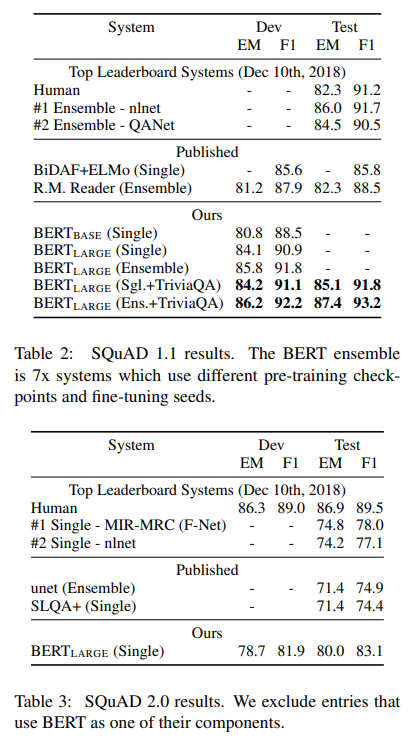
SQuAD v1.1(Stanford Question Answering Dataset, Rajpurkar et al., 2016)은 위키백과에서 발췌한 문단과 질문이 주어졌을 때, 문단 속에서 정답이 되는 텍스트 구간(span)을 맞추는 과제이다.
데이터는 약 10만 개의 크라우드소싱 질문/답변 쌍으로 구성되어있다. 질문(Question)과 지문(Passage)을 하나의 토큰 시퀀스로 묶은 후, 질문은 세그먼트 A 임베딩에, 지문은 세그먼트 B 임베딩 사용하였다.
연구자들은 소량의 추가 학습 데이터를 위해 TriviaQA(Joshi et al., 2017)로 먼저 미세 조정 후 SQuAD에 fine-tuning하였으며, 단일 BERT 모델이 당시 최고 앙상블 시스템보다도 F1 score가 높음을 보였다.
또한, TriviaQA 데이터셋 없이도 F1 score가 우수함을 보였다.
SQuAD 2.0은 SQuAD 1.1에 "정답이 없는(no-answer)" 케이스를 추가한 확장 버전이다. 이는 보다 실제 상황에 가까운 시나리오를 구성하는데, 답이 없는 질문의 경우 시작과 종료 위치를 모두 [CLS]토큰으로 처리하고, 시작·종료 위치 확률 공간에 [CLS]토큰의 위치를 포함하였다.
SWAG
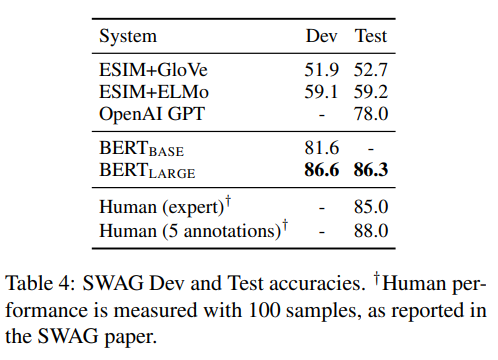
SWAG(Situations With Adversarial Generations, Zellers et al., 2018)은 113k개의 문장쌍 완성(sentence-pair completion) 문제로 구성되어, 주어진 문장(premise) 다음에 올 가장 자연스러운 문장을 4개 선택지 중 맞추는 과제를 수행한다.
BERTLARGE는 해당 벤치마크에서 이전 최고 모델 대비 5.1 높은 F1-score를 기록하였다.
Ablation Study
Effect of Pre-training Tasks
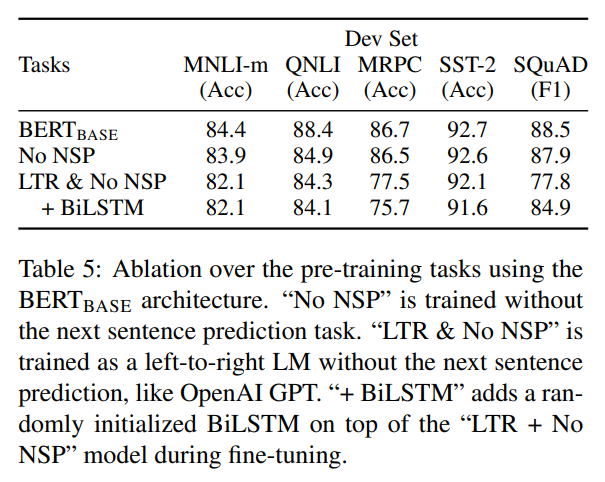
No NSP: 양방향 모델을 사용하되, MLM만 학습하고 NSP 과제는 제외
LTR & No NSP: 왼쪽 문맥만(LTR, Left-To-Right)을 보는 표준 언어 모델로 학습. MLM 대신 LTR LM 사용, NSP도 제외
NSP를 제거한 결과, QNLI, MNLI, SQuAD 1.1에서 확실한 성능 저하를 보였다.
LTR & No NSP에서도 모든 작업에서 MLM 모델보다 성능이 낮고, MRPC·SQuAD에서 성능이 크게 하락하였다.(직관적으로도 SQuAD와 같은 토큰 단위의 예측에서는 오른쪽 context를 보지 못하기 떄문에 불리할 것이다.)
이를 개선하기 위해 연구자들은 LTR & No NSP 위에 무작위 초기화 BiLSTM을 쌓아보았으나, 여전히 사전학습된 양방향 모델보다 훨씬 낮았으며 GLUE 작업에서는 오히려 성능이 하락하였다.
ELMo 방식(좌→우 + 우→좌 별도 학습 후 연결)도 가능하지만, 모델 크기가 2배가 되어 비효율적이고, 모든 층에서 좌/우 문맥을 동시에 활용하지 못하므로 근본적으로 덜 강력하다.
Effect of Model Size
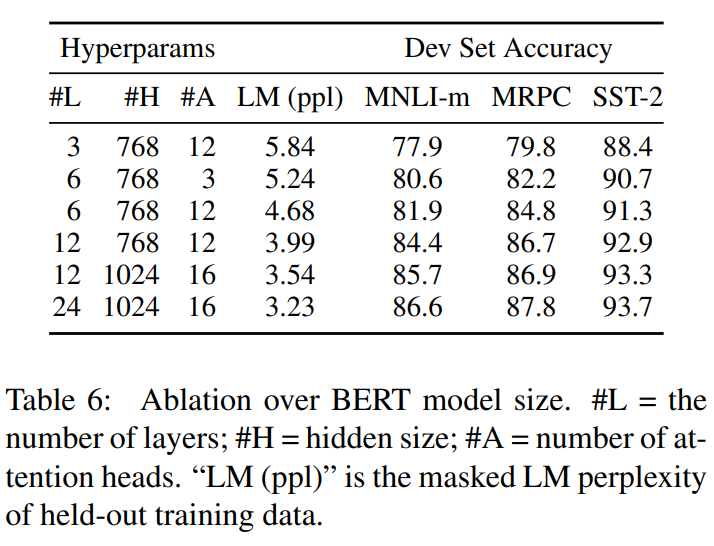
전반적으로 다음의 사항들을 관찰할 수 있다.
- 모델이 커질수록 모든 데이터셋에서 정확도가 일관되게 상승
- 이미 기존 연구 대비 큰 모델에서 시작했음에도 불구하고, 모델의 크기를 더 키워도 이득이 있다.
- 사전학습이 충분하면 아주 작은 다운스트림 데이터에서도 큰 모델이 이득이 된다는 것을 처음으로 명확히 입증하였다.
Feature-based Approach with BERT
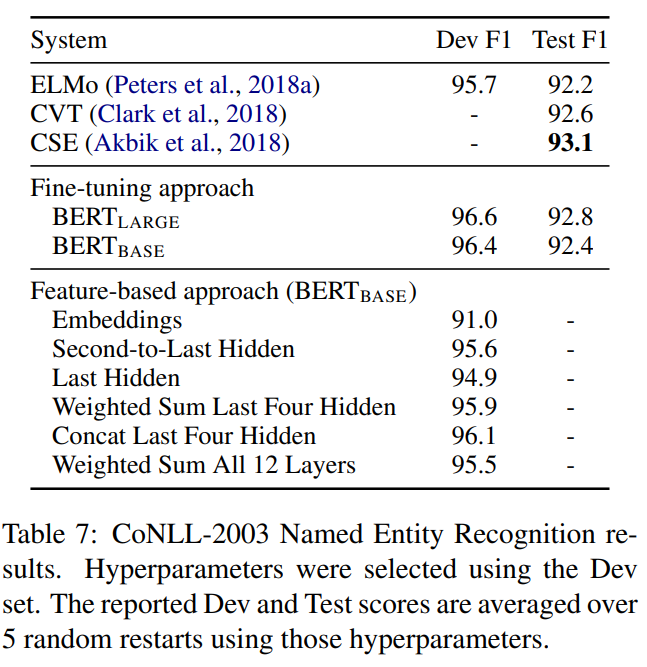
현재까지는 모두 fine-tuning 기반의 접근이였으나, Feature-based로 접근하면 사전학습된 모델의 가중치는 고정하고, 중간 계층 출력을 특성(features)으로 추출해 별도 아키텍처에서 사용할 수 있다.
이는 특정 task에 특화된 모델을 만들 때 유용하며, 큰 cost를 소모해 만든 임베딩 위에 가벼운 모델을 얹어 사용하므로 비용-효율적이다.
CoNLL-2003 Named Entity Recognition(NER) task로 실험한 결과, Feature-based 접근에서도 BERT는 매우 강력하며 Top 4 계층의 은닉 상태를 연결(Concat)한 것이 Fine-tuning 대비 단 0.3 F1 낮음을 보였다.
이를 통해 BERT는 Fine-tuning뿐 아니라 Feature-based 방식에서도 효과적임이 확인되었다.
Conclusion
해당 연구가 진행되던 시기에 NLP 분야에서는 언어 모델 기반 전이 학습(transfer learning)이 큰 도약을 이끌었다.
특히, 라벨이 없는 방대한 텍스트로 사전 학습을 진행하면, 데이터가 적은 과제도 깊은 신경망의 이점을 누릴 수 있다는 것이 입증된 바가 있다.
BERT의 가장 큰 기여는 이를 '양방향(Bidirectional)' 아키텍처로 확장하였다는 점이다.
이 덕분에 하나의 사전학습 모델만으로도 질문 응답, 문장 추론, 감정 분석 등 다양한 NLP 작업을 높은 성능으로 처리할 수 있게 되었다.
즉, BERT는 방대한 사전학습으로 얻은 양방향 언어 표현을 통해, 비용 효율적으로 다양한 NLP 과제를 해결할 수 있는 새로운 표준 아키텍처를 만들었다는 점에서 의의가 있다.
