LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." nature 521.7553 (2015): 436.
https://www.nature.com/articles/nature14539
Introduce
딥러닝(Deep Learning)이란 여러개의 Layer로 구성되는 머신러닝 모델입니다. 딥러닝 모델의 특성으로는 데이터의 추상화가 가능하며, 데이터 간의 숨겨진 특성을 추론하는 것이 가능하다는 점이 있습니다.
이러한 특성때문에 딥러닝은 이미지 인식, 음성 인식, 객체 탐지 등 최신 기술 분야와 약물 탐지, 유전학과 같은 다른 영역에도 큰 영향을 주었습니다.
딥러닝의 가장 큰 특징은 바로 역전파(Backpropagation) 알고리즘입니다. 후술하겠지만 간단히 말하자면, Gradient Descent 기반의 알고리즘으로 output으로부터 각 단계의 레이어의 파라미터를 순차적으로(output layer부터 가까운 순으로) 업데이트하는 방식입니다.
"The key aspect of deep learning is that
these layers of features are not designed by human engineers: they
are learned from data using a general-purpose learning procedure."
전통적인 머신러닝 모델들은 엔지니어가 수동적으로 특징이나 파라미터를 설계했어야했지만, 딥러닝은 데이터들로부터 자동적으로 학습을 진행합니다. 모든 형태의 데이터에 대한 일반화된 학습 절차가 딥러닝의 가장 큰 장점이라고 볼 수 있겠습니다.
딥러닝, 특히 합성곱신경망(Deep Neural Network)은 이미지, 비디오, 음성 등을 처리하는 분야의 페러다임을 바꾼 주요한 기술입니다. 이제 딥러닝 모델의 종류와 특성들을 하나씩 알아보도록 하겠습니다.
Supervised Learning
딥러닝을 알기 전에, 알아야할 것은 감독 학습(Supervised Learning)입니다. 감독 학습은 가장 흔한 머신러닝의 한 형태라고 볼 수 있겠습니다. 일반적인 감독 학습의 절차는 다음과 같습니다.
1. 대량의 데이터를 수집한다.
2. 오차(error)를 계산한다.
3. 내부 파라미터를 조정한다.
가중치를 수정하기 위해서는 gradient vector를 계산해야합니다. gradient vector를 계산하면, 가중치는 graidnet의 반대 방향으로 움직입니다.
Gradient descent를 수행하기 위한 다차원 데이터 공간은 많은 산을 가진 평원(hilly landscape)과 같습니다. 이 곳에서 negative gradient는 가파른 경사(steepest descent)를 내려가는 것을 의미하고, 점점 더 error가 작아지며 결국 최저점에 도달할 것입니다.
하지만, 실제로 gradient descent보다 더욱 많이 쓰이는 것은 SGD(Stochastic Gradient Descent)입니다. SGD란 계산된 데이터 셋의 평균 기울기를 계산하여 가중치를 조정하는 것을 의미합니다. 이러한 과정을 전체 데이터를 여러 개로 나누어 반복적으로 수행합니다.
훈련이 끝나면 테스트 데이터라는, 모델이 본 적 없는 데이터 집합에 대해 평가가 이루어집니다.
일반적인 선형 분류기(Linear classifier), 혹은 얕은 분류기(shallow classifier)들은 분류 문제에 대해 선택-불변성 딜레마(selectivity-invariance Dilemma)를 겪습니다. 모델의 입력이 무관한 변화(ex. 물체의 위치, 방향, 조명 등)에는 민감하지 않게 반응하면서도, 미세한 변형(ex. 흰 늑대와 사모예드의 차이)에는 민감하게 반응하여야하는데 이는 서로 상충되는 요구사항이기 때문입니다.
하지만 딥러닝 모델은 이러한 딜레마를 겪지 않습니다. 여러 레이어가 쌓인 구조는 선택성과 불변성을 모두 높일 수 있기 때문입니다.
Backpropagation
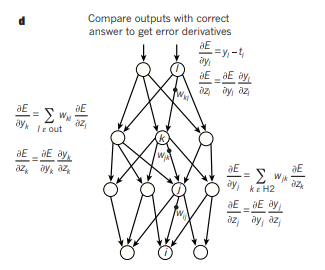 Figure.1 | Multilayer neural networks and backpropagation(d)
Figure.1 | Multilayer neural networks and backpropagation(d)
1970 ~ 1980년대 독립된 연구자들로부터, multilayer 구조에서 SGD가 적용 가능하다는 것이 증명되었습니다. 이는 역전파(Backpropagation)로 알려진 알고리즘인데, 미적분의 연쇄 법칙을 응용한 방식입니다. 역전파의 핵심은 output 노드의 출력의 기울기로부터 objective function들의 기울기를 역으로 계산할 수 있다는 점입니다. 즉, 최상단 출력 노드로부터 최하단 입력 노드까지 반복적으로 계산합니다. 이러한 역전파 알고리즘은 각 노드들의 파라미터들을 매우 간단하고 효율적으로 계산할 수 있게 해줍니다.
1990년대 말에는 역전파 알고리즘이 연구자들에게 외면받았습니다. 바로 지역 최저점(local minima) 때문인데요. 사실 이는 규모가 큰 신경망에서는 별 문제가 되지 않는 것으로 드러났습니다. 여러 연구 결과가 초기 상태에 관계 없이 시스템이 대부분 비슷한 성능에 도달함을 보였기 대문입니다.
Deep feedforward network(=DNN)는 2006년 다시 CIFAR 연구자 그룹의 Pre-trained model 연구에 의해 부상하기 시작했습니다. 또한, GPU의 등장으로 DNN의 학습은 10배에서 20배까지 빨라졌습니다. 이후 소규모 어휘 인식 작업으로 시작하여, 대규모 어휘 인식, 컴퓨터 비전 등 여러 분야의 벤치마크에서 기록적인 성과를 달성했습니다.
특히, DNN의 한 종류인 ConvNet은 기존의 알고리즘에 비해 학습이 훨씬 쉬웠고, 일반화 성능이 뛰어나며 실용적인 성과 또한 낼 수 있었습니다.
CNN(Convolutional neural network)
ConvNet은 DNN의 한 종류로, 기본적으로 다차원 배열 형태의 데이터를 처리하기 위해 디자인된 신경망 모델입니다. 특히 사물 인식, 이미지 분류, 등의 분야에서 좋은 성능을 냅니다.
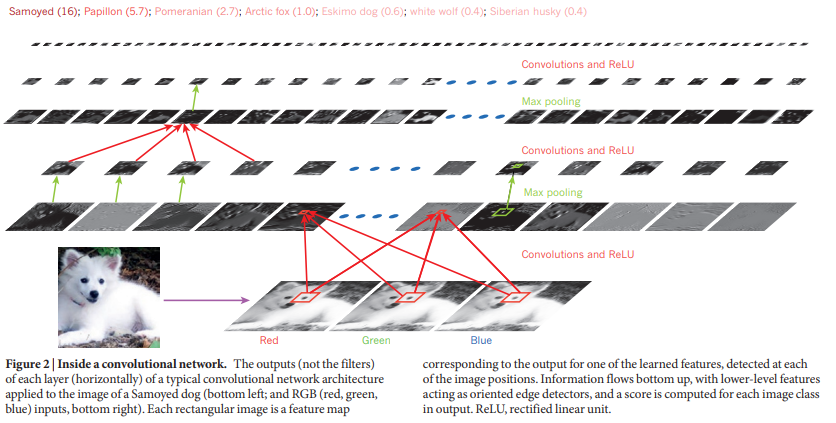 Figure.2 | Inside a convolutional network
Figure.2 | Inside a convolutional network
일반적인 ConvNet의 아키텍처는 여러 단계로 구성됩니다. 초기 몇 단계는 합성곱 레이어(Convolutional Layer)와 풀링 레이어(Pooling Layer)로 구성됩니다. 합성곱 레이어는 이전 층의 피쳐들의 지역적 결함을 감지하는 한 편, 풀링 레이어는 의미상 유사한 피쳐를 하나로 병합하는 역할을 합니다.
합성곱 레이어는 피쳐 맵(feature maps)로 구성되는데 각 유닛은 필터 뱅크(filter bank)라고 하는 가중치 집합을 통해 가중합을 계산하여 활성화 함수로 전달합니다. 피쳐 맵 내의 모든 유닛은 동일한 필터 뱅크를 공유하는데, 이는 지역 모티프를 배열의 다른 부분에서도 감지하기 위함입니다. 이러한 방식으로 지역적 결합을 감지하는 것이 합성곱 레이어의 역할입니다.
일반적인 풀링 유닛은 하나의 피쳐 맵에서 지역 패치의 최대값을 계산합니다(Max Pooling). 인접한 풀링 유닛이 행/열을 이동하며 이동된 패치에서 입력을 받아 표현의 차원을 줄입니다. 두세 단계의 합성곱/풀링이 쌓인 후 더 많은 Fully connection이 이어집니다. ConvNet에서의 역전파는 이전과 동일하게 매우 간단합니다.
합성곱 신경망은 1990년대 초 음성 인식, 문서 읽기 등을 위한 신경망 모델에서 시작되었습니다. 자연 이미지에서 손, 얼굴과 같은 객체를 탐지하는 기술과 얼굴 인식을 위해 실험되기도 하였습니다. 2000년 초반부터 ConvNet은 이미지 내의 객체와 영역 탐지, 분할, 인식에서 큰 성공을 거두었습니다. 최근 ConvNet의 주요 사례 중 하나는 얼굴 인식입니다.
특히, 이미지는 픽셀 단위로 라벨링될 수 있기에 로보틱스 및 자율 주행 자동차같은 기술에 응용될 수 있습니다. 2012년 ImageNet 대회에서 합성곱 신경망이 경쟁 방법의 오류율의 거의 절반을 달성하며 컴퓨터 비전 분야의 혁명을 일으켰고, 이제 거의 모든 인식/탐지 작업에서 지배적인 접근 방식으로 자리잡았습니다.
Language Processing
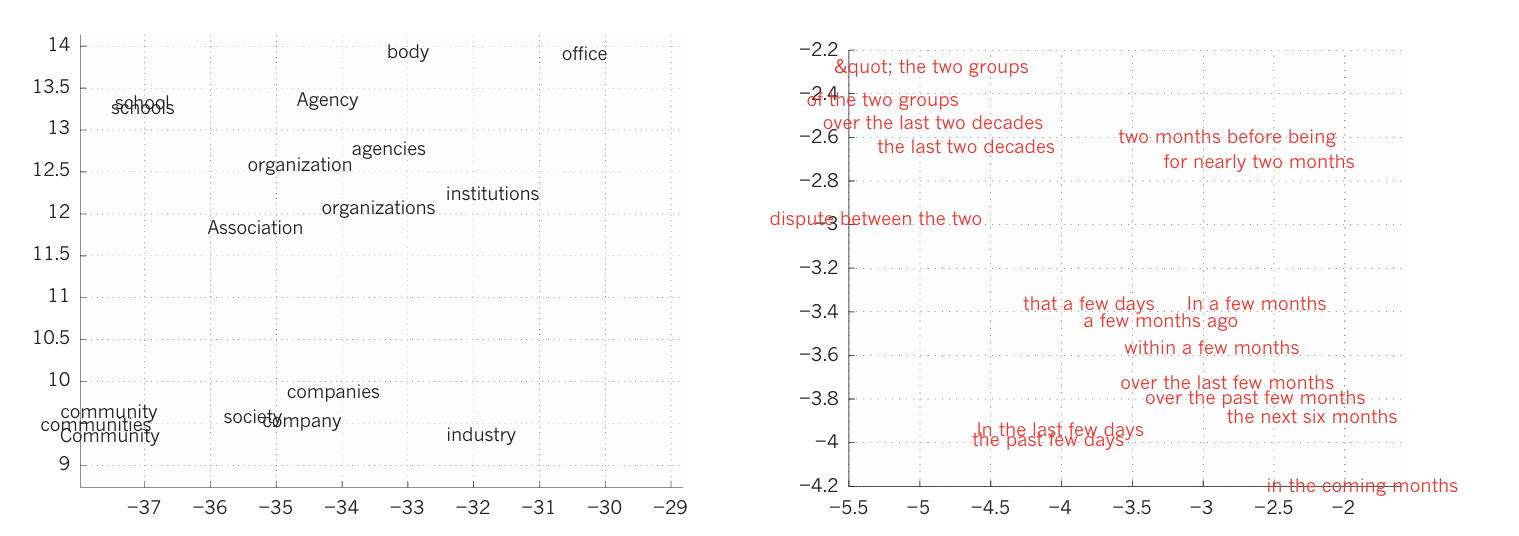 Figure.4 | Visualizing the learned word vectors
Figure.4 | Visualizing the learned word vectors
문맥(context)에서 각 단어는 one-of-N 벡터로 표현됩니다. 이는 해당 단어 하나만 1로 표현되고, 나머지는 0인 벡터입니다. 첫 번째 계층에서는 word vector를 생성하고, 다른 계층들은 입력한 단어 벡터를 다음 단어를 예측하기 위한 출력 단어 벡터로 변환하는 것을 학습합니다. 이를 통해 단어 벡터는 다음 단어가 나올 확률을 예측할 수 있습니다.
단어 벡터는 데이터에서 명시적으로 표기되지 않은 의미적 특징들을 학습 과정에서 자동적으로 발견하여 학습합니다. 예를 들어, N-gram 모델은 각 단어를 원자 단위로 취급하여 단어 시퀀스 간의 일반화를 할 수는 없지만, 신경망 기반의 언어 모델은 단어를 실수값 벡터로 연관시키기 때문에 의미적 유사도가 높은 단어들이 벡터 공간 내에 놓이게됩니다.
과거 신경망 모델이 도입되기 이전까지의 언어 모델은 통계적 추론을 기반으로 동작했습니다. 예를 들어 N-gram을 기반으로 짧은 단어 시퀀스의 빈도를 계산하는 방법입니다. 이러한 경우 경우의 수는 어휘 크기(V)의 N제곱에 비례하기에 문맥의 길이가 길어질 수록 매우 큰 훈련 데이터가 필요합니다. 하지만, 신경망의 경우 큰 활동 벡터(activity vector)와 가중치 행렬(weight matrix), 스칼라를 활용하여 직관적 추론을 수행합니다. 따라서 신경망 언어 모델의 도입은 언어 처리에서 일반화 및 효율성을 크게 개선한 혁신적인 전환점이였습니다.
RNN(Recurrent Neural Network)
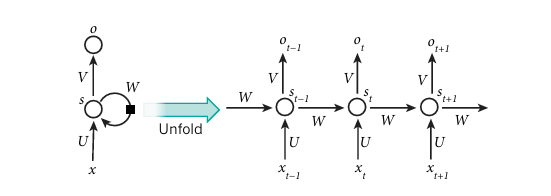 figure.5 | A recurrent neural network and the unfolding in time of the
figure.5 | A recurrent neural network and the unfolding in time of the
computation involved in its forward computation
RNN은 순차적인 입력을 처리하는데 사용되는 신경망 구조입니다. 특히 음성, 언어, 시계열 데이터를 다룰 때 유리합니다. RNN은 입력 시퀀스를 한 번에 하나씩 처리하며, 과거의 모든 입력 요소를 암묵적으로 포함하는 상태 벡터를 유지합니다. 하지만, RNN을 훈련하는 과정에서 흔히 발생하는 발생하는 문제는 기울기 소실입니다. 역전파 과정을 많이 거칠 수록 기울기가 발산하거나, 소실하는 문제가 발생하게되는데, 이를 해결하기 위해 새로운 아키텍처와 훈련 방법이 도입되었습니다. 예를 들어, LSTM(Long Short-Term Memory) 네트워크는 입력을 장기적으로 기억할 수 있는 메모리 셀을 활용해 이러한 문제를 완화합니다.
RNN과 LSTM은 텍스트 예측 뿐 아니라, 문장 번역에도 사용할 수 있습니다. 예를 들어, 영어 문장을 프랑스어로 번역한다면 영어 문장은 인코더 네트워크로 처리되어 의미 벡터로 변환되고, 이 벡터는 디코더 네트워크에 전달되어 프랑스어 번역이 생성됩니다. 이외에도, 이미지의 의미를 텍스트로 번역하거나, 질문에 대한 답변을 생성하는데도 사용된다.
Conclusion
본 논문에서 제시하는 딥러닝의 미래는 비전 분야의 ConvNet과 RNN의 결합과 강화 학습을 사용하는 end-to-end 학습 시스템입니다. 딥러닝과 강화학습을 결합한 시스템이 여러 수동 비전 시스템을 능가하며, 좋은 결과를 보여주고 있기 때문입니다.
또한, 자연어 처리는 몇 년간 딥러닝이 큰 영향을 미칠 것으로 보고있습니다. RNN을 사용하는 시스템이 특정 부분을 선택적으로 주목하는 전략을 학습하며 훨씬 더 발전할 것으로 보고있습니다.
