Nie, Shen, et al. "Large Language Diffusion Models." arXiv preprint arXiv:2502.09992 (2025).
https://arxiv.org/abs/2502.09992
Abstract
기존의 대규모 언어 모델(LLM)은 대부분 자기회귀 모델 (AutoRegressive Models, ARMs) 을 기반으로 구축됩니다.
하지만 이 논문에서는 마스킹 확산 모델(Masked Diffusion Model, MDM)을 활용한 LLM인 LLaDA(Large Language Diffusion with mAsking)를 제안합니다.
실험 결과, LLaDA는 전통적인 ARM 기반의 LLM 대비 적은 토큰의 학습만으로 타 모델과 유사하거나 더 높은 성능을 보였습니다.
또한, Gpt-4o와 같은 기존 모델이 어려움을 겪는 문장 역순 예측(Reversal Reasoning) 문제에서 매우 뛰어난 성능을 보였습니다.
결과적으로 LLaDA는 AR 없이도 LLM을 학습시켜 유의미한 성과를 거둘 수 있음을 보이며, ARMs의 필수성을 재검토하게 만들어주었습니다.
논문은 중국 인민대학교와 Ant group 연구자들에 의해 수행되었으며, 2025년 2월 arxiv에 preprint로 업로드되었습니다.
Ⅰ. Introduction

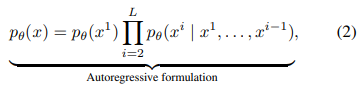
Eq.1은 LLM의 모델 학습에 사용되는 공식입니다. 두 공식 모두 모델의 훈련 데이터의 분포를 학습하도록 유도하는데, 생김새만 다르지 동일한 문제를 풀고 있습니다.
좌측의 식은 최대 우도 측정(MLE)이라는 방식입니다. 주어진 데이터 분포 P_data을 이용해 모델의 분포 P_theta와 실제 데이터 분포 P_data가 최대한 비슷해지도록 학습하여 Theta를 최적화합니다.
우측의 식은 Kullback-Leibler Divergence(KL-Divergence)를 이용한 것으로, MLE와 동일하게 p_theta와 p_data간의 차이를 최소화하는 것을 목적으로 동작합니다. 두 분포의 차이는 KL-divergence로 계산되며 이를 최소화하는 방향으로 theta를 최적화합니다.
이러한 식은 LLM의 핵심적인 성질을 결정하는 요소이지만, 해당 논문에서는 LLM이 반드시 자기회귀방식(Eq.2)가 필요한 것은 아니며, LLM에서 확산 모델이 유효하게 작용할 수 있다고 주장합니다.
또한, LLaDA는 기존의 ARM 기반 LLM이 가지고 있던 문제점인 1) 연산 비용이 높은 생성 방식(토큰의 연속적 생성)과 2) 좌->우 방향성의 제약을 해결할 수 있습니다.
Ⅱ. Approach
1. Probablisitic Formulation
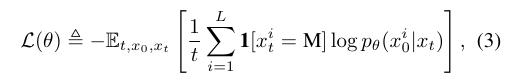
Eq.3은 LLaDA의 핵심 아이디어인 마스킹 예측 모델의 Loss 함수입니다. 뭔가 복잡해보이지만, 결과적으로 Cross Entropy Loss를 계산해서 학습하는 내용입니다.
수식을 자세히 살펴보면 는 에서의 기댓값을 의미합니다. 는 원본 텍스트, 는 Forward Process를 거쳐 마스킹된 결과물, t는 마스킹 비율입니다. 이때 t는 [0,1] 범위의 uniform distribution을 가집니다.
의 경우 특정한 토큰 가 마스킹된 경우에만 손실을 계산하도록 해줍니다. Loss는 에서 계산되는데, 이는 토큰 의 시점에서 원래 토큰인 을 예측할 확률을 의미합니다.
이를 통해 Cross Entropy Loss를 계산하고, 로 나누어 마스킹된 비율에 따라 Loss값을 조정해줍니다.
따라서 Eq.3은 마스킹된 토큰들만 학습에 기여하게 하고, 마스킹 비율에 따라 Loss값을 조정해 정규화해주어 모델이 마스킹된 토큰을 복원하는 것을 학습시키도록 돕습니다.
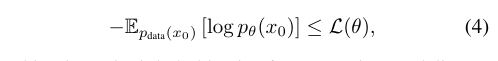
Eq.4를 통해 가 항상 NLL보다 크거나 같다는 것을 알 수 있습니다. 따라서 학습이 진행됨에 따라 가 작아지고, NLL도 작아지므로 LLaDA의 학습 방식이 수학적으로 타당하다는 점을 입증해줍니다.
LLaDA의 Forward Porcess는 $x_0$에 대해 확률 t에 따라 토큰을 마스킹 하는 과정입니다. 즉, 각 토큰 $x^i_0$가 마스킹될 확률은 t이고, 마스킹되지 않을 확률은 1-t입니다.
중요한 점은, 각 토큰이 마스킹될 확률이 모두 상호독립적이고, t는 랜덤한 값이라는 점입니다.
이러한 점이 고정된 마스킹 비율을 선택하는 BERT와 LLaDA의 차이를 만들어줍니다.
역방향은 일반적인 Diffusion Model처럼 마스킹된 상태의 문장을 원래 문장으로 복원하는 것을 학습합니다. t=1(Fully Masked)에서 t=0(Unmasked)상태까지 진행됩니다.
2. Pre-training, SFT, Sampling
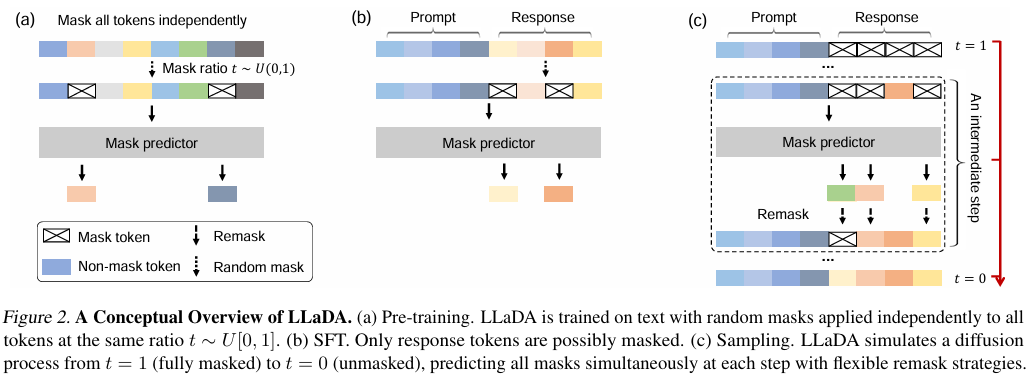 Reprinted Figure.2
Reprinted Figure.2
(a). pre-training
사전 학습은 다음과 같이 이루어졌습니다.
| 구분 | 항목 | 내용 |
|---|---|---|
| 모델 구조 | 모델 크기 | 1B (10억 개), 8B (80억 개) |
| Attention 방식 | Multi-head Attention (기존 GQA 미사용) | |
| Feed Forward Network (FFN) | Attention Layer 증가로 인해 FFN 차원 감소 | |
| 토크나이저 | 기존 LLaMA와 다른 새로운 토크나이저 적용 | |
| 데이터 및 학습 설정 | 총 학습 토큰 수 | 2.3조 (Trillion) 개 |
| 학습 데이터 | 일반 텍스트 + 고품질 코드 + 수학 + 다국어 데이터 | |
| 데이터 필터링 | 규칙 기반 + LLM 기반 방식 적용 | |
| 최대 입력 길이 | 4096 tokens | |
| 총 GPU 시간 | 13만 GPU 시간 (H800 기준) | |
| 데이터 샘플링 방식 | 랜덤 마스킹 및 랜덤 길이 샘플링 (1~4096 tokens, 1% 적용) | |
| 학습 스케줄 | 학습률 스케줄러 | Warmup-Stable-Decay 방식 |
| 초기 Warmup | 2000 iterations 동안 4 × 10⁻⁴까지 증가 | |
| 학습률 감소 | 1.2조 개 토큰 학습 후 1 × 10⁻⁴로 감소, 마지막 0.3조 토큰 학습 시 1 × 10⁻⁵까지 선형 감소 | |
| 옵티마이저 | AdamW (Weight decay: 0.1) | |
| 글로벌 배치 사이즈 | 1280 | |
| GPU당 로컬 배치 사이즈 | 4 |
(b) Supervised Fine-Tuning(SFT)
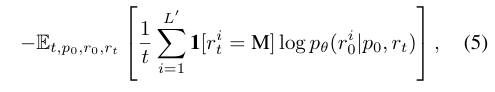
LLaDA가 instruction을 더 잘따를 수 있도록 지도 학습을 기반으로 미세 조정(SFT)를 수행해줍니다. 학습에 대한 input으로는 프롬프트 p와 응답 r로 구성된 paired data를 450M을 넣어주었고, 기존 LLM과 동일한 SFT 방식(Chu et al., 2024; Yang et al., 2024)을 사용했습니다.
학습의 경우 우선 입력 p는 그대로 둔 상태에서 응답 r을 독립적으로 마스킹합니다. 모델은 p와 마스킹된 응답 를 받아 원래의 응답 를 복원하도록 학습해줍니다. Loss 함수도 Eq.5처럼 계산됩니다.
(c) Inference
LLaDA는 새로운 텍스트를 sampling하는 것과 텍스트의 확률을 평가 하는 것이 가능합니다.
텍스트 생성은 먼저 프롬프트 p가 주어집니다. p를 기반으로 응답 r을 완전히 마스킹된 상태에서 각 step마다 일부 토큰을 복원하면서 샘플링으르 진행합니다. 이 때, 2가지 Random Remasking을 사용합니다. 하나는 Low-Confidence Remasking으로 확률이 낮은 토큰을 다시 마스킹한 뒤에 예측하는 것입니다.

Reprinted Figure.4 [Appendix A.2]
다른 하나는 Semi-Autoregressive Remasking으로 sequence를 블록 단위로 나누어 좌->우로 생성하는 것입니다.
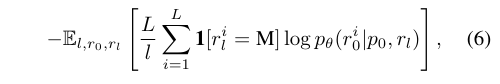
확률 평가는 기본적으로는 식 Eq.5와 같은 형태인 Eq.6을 사용합니다. l의 경우 [1,L]에서 uniform sampling을 해주고, 은 로부터 중복없이 l개의 토큰을 샘플링하여 얻습니다. 또한, 추가적인 지도 학습 없이 모델을 안내하는 기법인 Classifier-free guidance(Nie et al., 2024)을 사용합니다.
Ⅲ. Experiments
1. Scalability of LLaDA on Language Tasks
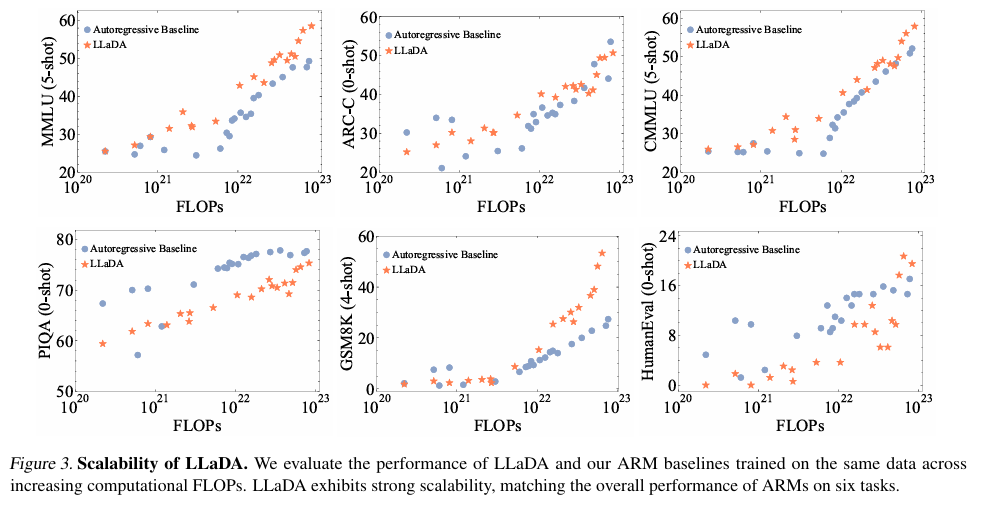
Reprinted figure.3
연구자들은 LLaDA와 ARM 기반 모델들의 계산 비용을 FLOPs를 통해 비교하였습니다. 비교하는 모델은 동일하게 1B 스케일에서 이루어졌습니다.
Fig.3을 보면 LLaDa는 ARM과 비교해도 상당히 괜찮은 성능을 보이며, scalability 또한 인상적으로 보입니다.
다만 outlier의 영향이 실험 결과에 끼칠 왜곡을 고려하여, 정량적인 스케일링 곡선(quantitative scaling curve)을 맞추지 않아주었습니다.
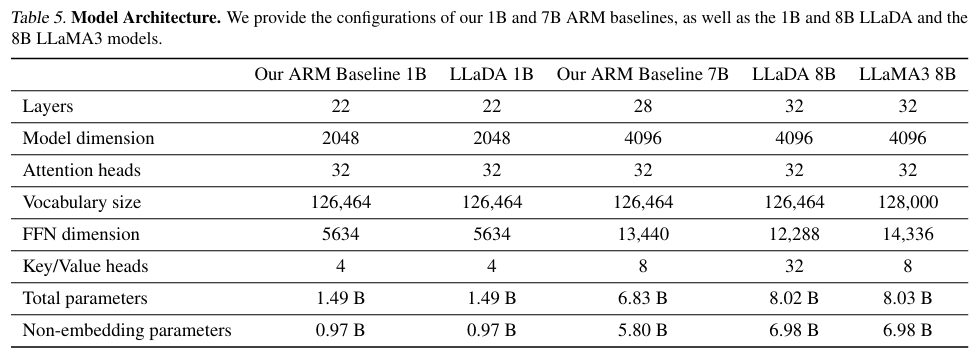
Reprinted Table.5 [Appendix B.2]
더 큰 스케일에서는 LLaDA와 ARM 모델이 리소스 제한으로 인해 약간 다른 크기로 훈련되었습니다. 해당 내용이 부록 B.2에 자세히 수록되어있습니다.
2. Benchmark Results
성능 비교는 LLaDA 8B와 비슷한 크기의 기존 LLM 모델들(Touvron et al., 2023; Dubey et al., 2024; Chu et al., 2024; Yang et al., 2024; Bi et al., 2024; Jiang et al., 2023))과 수행되었습니다.
작업과 평가 프로토콜이 기존 연구들과 일치하며, 15개의 자주 사용되는 벤치마크를 포함합니다.
특히, LLaMA3 8B와 LLaMA2 7B는 보다 직접적인 비교를 위해 연구자들의 실험 환경에서 다시 벤치마크를 테스트 했습니다.
괄호안의 숫자는 shot의 개수를 의미합니다.
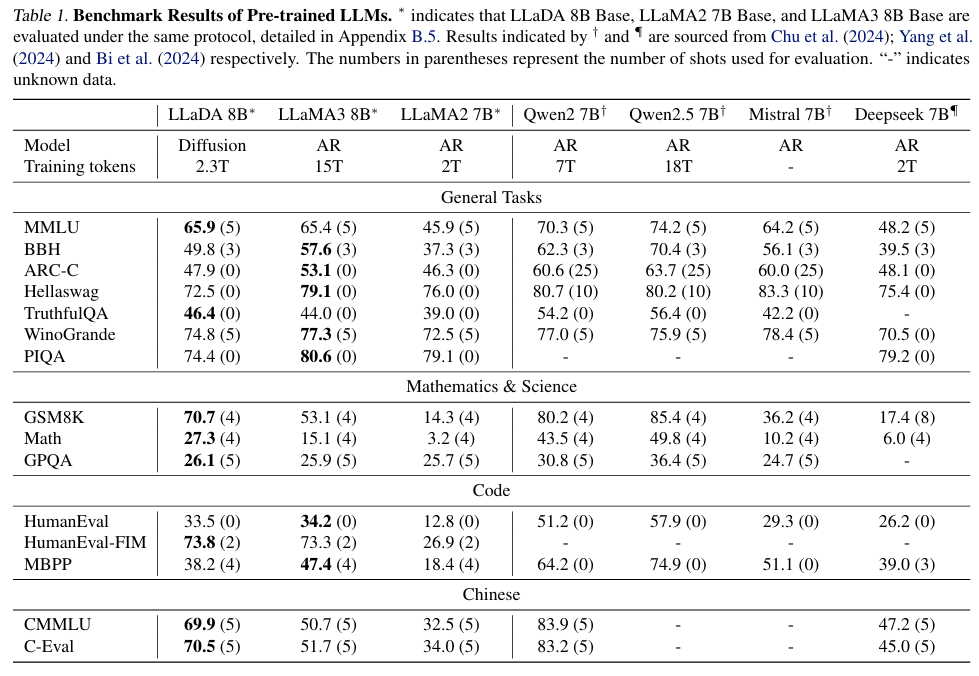
Reprinted Table.1
Table.1에서 LLaDA 8B는 LLaMA 8B와 전반적으로 비슷한 성능을 보이며, LLaMA2 7B를 능가하는 성능을 보입니다.
LLaDA는 주로 수학 & 과학, 중국어 문제에서 장점을 보였으며 일부 작업에서 나타나는 약한 성능은 데이터 품질, 분포, LLM 데이터셋의 폐쇄적인 문제 등에 기인하는 것으로 연구자들은 추측하였습니다.
중요한 점은 이러한 결과가 2.3T의 토큰을 학습한 결과라는 점입니다.
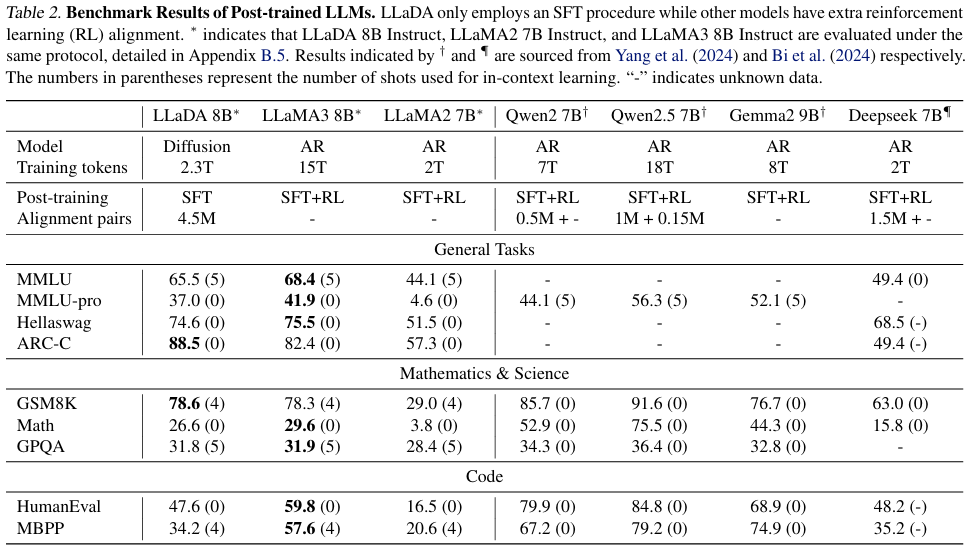
Reprinted Table.2
또한, Table 2에서 LLaDA 8B가 지침 수행 능력을 비교합니다.
AR 기반 모델들은 Post-training에 SFT와 RL을 사용하는 반면, LLaDA는 SFT만을 사용하였습니다.
SFT는 LLaDA의 ARC-C, Hellaswag, GSM8K, GPQA, HummanEval에서 벤치마크 점수를 크게 향상시켰습니다. MMLU, Math, MBPP 등의 데이터셋에서 약간의 성능 하락이 있었으나 이는 SFT 데이터셋의 품질이 해당 데이터셋에 최적화되어있지 않음에 기인한다고 연구자들은 추측합니다.
즉, LLaDA는 RL 없이 SFT만을 사용하여 타 모델들과 비교할만한 지침 수행 능력을 보였습니다.
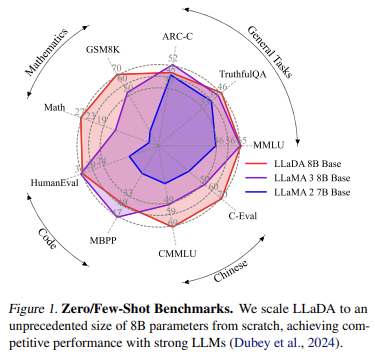 Reprinted Figure.1
Reprinted Figure.1
Zero/Few-shot에 대한 벤치마크입니다. LLaDA 8B는 비슷한 파라미터 크기를 가진 LLaMA3 8B, LLaMA2 7B에 비해 일정한 성능을 보입니다. 몇몇 벤치마크는 성능이 떨어지지만, 강력한 LLM인 LLaMA3와 비교할 만한 성과를 거두었다는 점이 눈에 띕니다.
3. Reversal Reasoning and Analyses
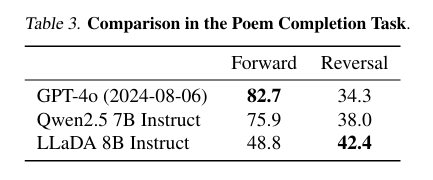
Reprinted Table.3
모델의 반전 추론 능력을 정량적으로 측정하였습니다. 496개의 유명한 중국어 시(poem) 문장 쌍으로 이루어져있습니다. 모델은 시에서 주어진 문장을 바탕으로 후속 문장을 만들거나(Forward), 이전 문장(Reversal)을 만듭니다.
이는 추가적인 fine-tuning 없이 진행됩니다.
LLaDA는 이 실험에서 정방향, 역방향 생성에 대해 동일한 능력을 보입니다. 정방향 생성에서는 ARM 기반의 모델이 매우 강력하다는 것을 보여주는데, 이는 LLaDA에 비해 훨씬 큰 데이터셋과 컴퓨팅 자원을 소모한 혜택을 받았다고 연구자들은 주장합니다.
대신, LLaDA는 역방향 생성에서 타 ARM 기반 모델들의 성능을 능가합니다.
4. Case Studies
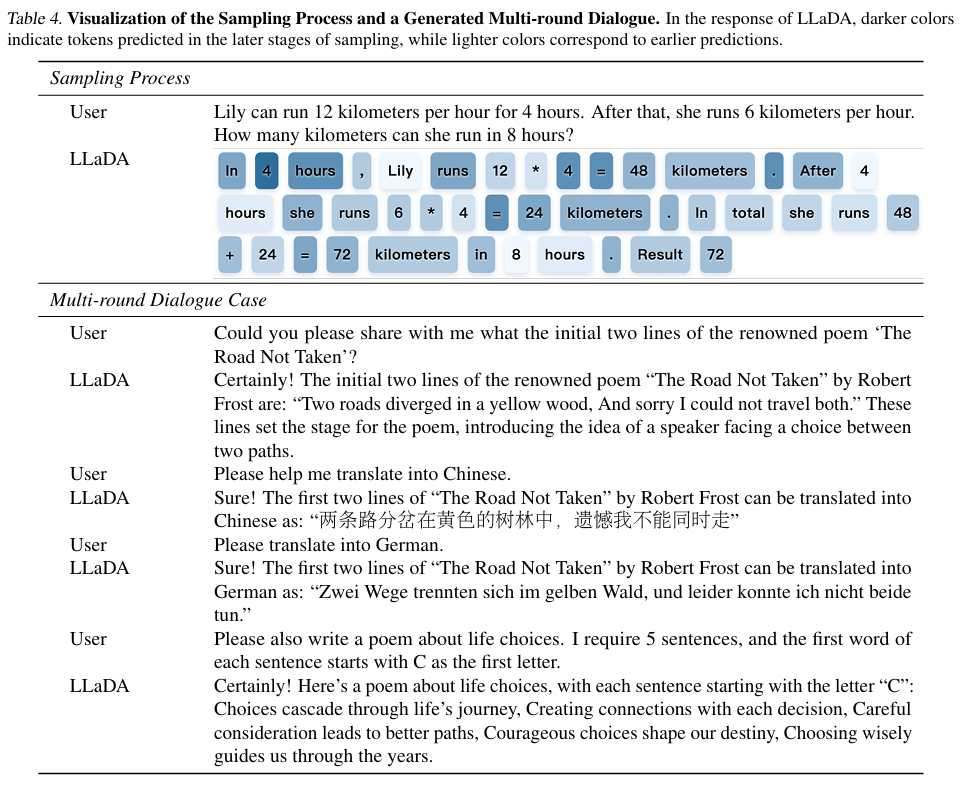
Reprinted table.4
table 4는 LLaDA 8B instruct가 생성한 샘플들입니다.
1. 이는 LLaDA가 auto-regression을 사용하지 않은 방식으로도 일관되고 유창한 텍스트를 생성할 수 있음을 보여줍니다.
2. 또한, 다국어 대화에서도 context를 유지하며 대화가 가능하다는 것을 알 수 있습니다.
Ⅳ. Related Work
Diffusion Models in Vision vs. Language
확산 모델(Sohl-Dickstein et al., 2015; Ho et al., 2020; Song et al., 2020)은 시각적 도메인에서 우수한 성능을 보여왔다. 하지만 대규모 언어 모델(LLM)에 대한 적용은 아직 충분히 연구되지 않았으며, 검증도 제한적이다.
Direct Application Approaches
Continuousization of Text : 일부 연구에서는 텍스트 데이터를 연속적인 표현으로 변환한 후 확산 모델을 적용하는 방식을 제안하였다 (Li et al., 2022; Gong et al., 2022; Han et al., 2022; Strudel et al., 2022; Chen et al., 2022; Dieleman et al., 2022; Richemond et al., 2022; Wu et al., 2023; Mahabadi et al., 2024; Ye et al., 2023b).
이산 분포 모델링(Modeling Discrete Distributions) : 다른 연구들은 이산 분포의 연속적인 파라미터를 모델링하는 접근 방식을 시도하였다 (Lou & Ermon, 2023; Graves et al., 2023; Lin et al., 2023; Xue et al., 2024).
확장성 문제(Scalability Challenge) : 확장성은 주요 과제로 남아 있으며, 10억 개의 파라미터를 가진 모델이 유사한 성능을 내기 위해 AR 모델보다 64배 더 많은 연산량을 요구할 수도 있다 (Gulrajani & Hashimoto, 2024).
Discrete Diffusion Approaches
이산 확산(Discrete Diffusion) : 일부 연구들은 연속적인 확산 과정 대신 새로운 정방향 및 역방향 동역학을 갖춘 이산 확산을 활용하였다 (Austin et al., 2021a).다양한 변형 기법들이 등장하였다 (Hoogeboom et al., 2021; He et al., 2022; Campbell et al., 2022; Meng et al., 2022; Reid et al., 2022; Sun et al., 2022; Kitouni et al., 2023; Zheng et al., 2023; Chen et al., 2023; Ye et al., 2023a; Gat et al., 2024; Zheng et al., 2024; Sahoo et al., 2024; Shi et al., 2024).
마스킹 확산(Masked Diffusion) : Lou et al. (2023)은 마스킹 확산이 GPT-2 규모에서 AR 모델과 유사하거나 더 낮은 perplexity를 달성할 수 있음을 입증하였다.
이론적 기반 : Ou et al. (2024)은 본 연구의 모델 설계, 학습 및 추론을 위한 핵심 이론적 결과를 제시하였다
Applications and Extensions
언어 태스크 적용 : Nie et al. (2024)는 MDM을 활용하여 GPT-2 수준의 질의응답(QA) 태스크를 수행하는 연구를 진행하였다.
ARM과의 결합 : Gong et al. (2024)는 MDM을 이용하여 ARM을 미세 조정하는 연구를 수행하였으나, 일부 메트릭에서만 향상을 확인할 수 있었다.
Related Lines of Work
이미지 생성(Image Generation) : 이미지 생성 분야에서도 MDM을 적용하는 연구가 진행되고 있으며, 본 연구와 유사한 방향성을 가진다 (Chang et al., 2022; 2023).
기타 도메인(Other Domains) : MDM은 단백질 생성과 같은 분야에서도 가능성을 보이고 있다 (Wang et al., 2024b; c).
지속 시간 단축(Acceleration via Distillation) : 최근 연구들은 증류(distillation) 기법을 활용하여 MDM의 샘플링 속도를 향상시키는 가능성을 탐색하고 있다 (Kou et al., 2024; Xu et al., 2025).
Ⅴ. Result and Discussion
연구자들은 기존의 지배적인 방식이던 AR 기반의 LLM을 벗어나 Diffusion model을 기반으로한 LLM인 LLaDA를 제시합니다.
LLaDA는 양방향 모델링이 가능하고, 강건성이 좋으며 이에 따라 Scalability, In-context-learning, instruct등의 작업에서 타 LLM과 비슷한 성과를 달성했습니다.
하지만 아직 Diffusion model의 잠재력이 완전히 탐구된 것은 아닙니다. LLaDa를 위한 특별한 attention 매커니즘이 적용되지도 않았고, position embedding을 설계하지도 않았습니다. 또한, 아키텍처의 최적화도 적용되지 않았습니다.
추론의 측면에서도 guiance 매커니즘은 초기 단계이며, RL과의 정렬을 아직 수행하지 않았습니다.
결과적으로 LLaDA는 diffusion 기반의 LLM이 실행 가능하고, 좋은 대안이 됨을 입증하는 동시에 ARM 기반 LLM에 도전하였습니다.
