Hollmann, Noah, Samuel Müller, and Frank Hutter. "Large language models for automated data science: Introducing caafe for context-aware automated feature engineering." Advances in Neural Information Processing Systems 36 (2024).
https://arxiv.org/abs/2305.03403
https://github.com/cafeautomatedfeatures/CAFE
Ⅰ. Abstract
이 연구에서는 AutoML 분야에서 LLM의 강점을 활용하여 자동화된 피처 엔지니어링을 구현하는 접근방법을 제시합니다. CAAFE 모델은 시스템이 도메인 지식을 통합함으로써 Context-aware한 피처 엔지니어링이 가능해집니다.
CAAFE는 새로운 피처를 생성하는 Python 코드를 제공하며, 해당 코드의 유용성에 대한 설명도 제시합니다. 비록 방법론적으로는 단순하나, 14개의 Dataset중 11개에서 성능을 향상시켯으며 평균 ROC AUC 성능을 0.798에서 0.822로 증가시켰습니다.
또한, 각 피처에 대한 텍스트 설명을 제공함으로써 해석 가능성을 제공하고, AutoML 범위를 Semantic AudoML로 확장할 수 있는 context-aware의 중요성을 강조합니다. 또한, CAAFE는 데이터 사이언스 분야에서 더 광범위한 반-자동화(semi-automated)를 가능하게 합니다.
Ⅱ. Introduction
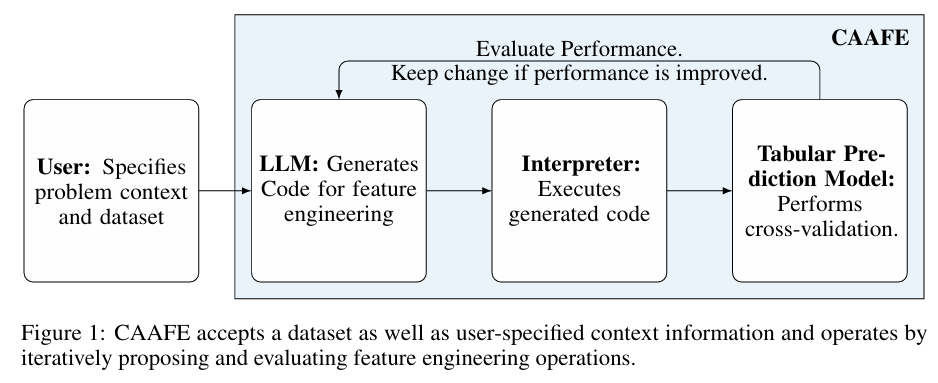 Reprinted Figure.1
Reprinted Figure.1
AutoML(Hutter et. al., 2019)은 머신러닝 관련 작업을 최적화하는데 매우 효율적이나, 데이터 엔지니어링이나 도메인 지식 통합에 있어서는 여전히 인간 실무자에게 크게 의존중입니다. "State of Data Science"(Anaconda, 2020)에 의하면 모델의 선택, 학습, 평가 등에 대해서는 23%의 작은 비중을 가지고있지만, 데이터 엔지니어링과 정제와 같은 가장 시간소모적인 작업에 대해서는 AutoML에서 거의 지원되지 않고있습니다. 이에 대해 LLM은 AutoML의 범위를 확장하여 자동화된 데이터 사이언스로 진화시킬 잠재력을 가지고 있습니다.
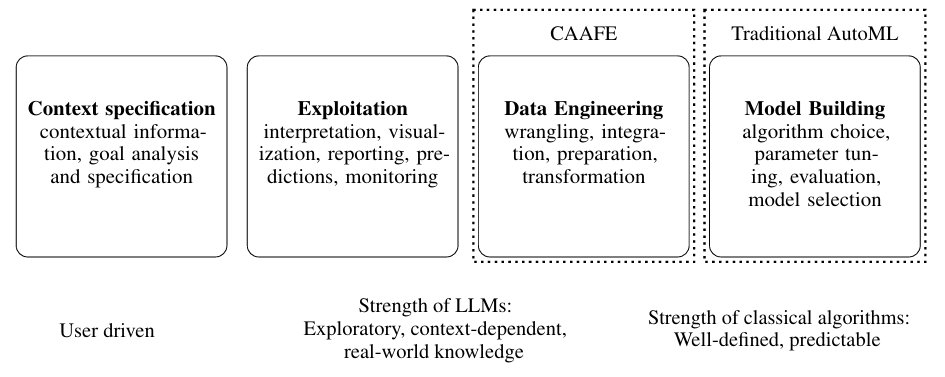 Reprinted Figure.2
Reprinted Figure.2
이 연구에서는 전통적인 머신러닝 분류기의 확장성과 강건성을 LLM에 내제된 방대한 도메인 지식과 결합하는 접근법을 제시합니다. LLM과 알고리즘 간의 간극을 메우기 위해 코드를 인터페이스로써 사용합니다. 즉, LLM은 입력 데이터셋을 수정하는 코드를 작성하고, 수정된 데이터셋은 클래식 알고리즘에 의해 처리됩니다.
CAAFE(Context-Aware Automated Feature Engineering) 는 성능을 향상시키는 의미적으로도 유의미한 피처를 반복적으로 생성합니다. 이는 알고리즘의 피드백을 통해 개선됩니다. 이러한 과정은 1) 데이터에서 학습된 모델로 전환되는 시간을 단축, 2) ML모델 생성 비용 절감, 3) 기존 AutoML과 수작업으로는 평가하지 못했던 풍부한 솔루션 공간을 탐색. 4) 솔루션의 강선성과 재현 가능성 향상
따라서 CAAFE는 데이터 과학 작업을 더욱 광범위하게 자동화시켜주는 LLM의 가능성을 보여주고, 보다 강건하며 context에 민감한 AutoML 도구를 개발하는 가능성을 제공합니다.
Ⅲ. Background
feature engineering이란 raw 데이터에서 적합한 피처를 구성하여 예측 성능을 높이는 것을 의미합니다. 즉, 주어진 데이터셋 D에 대해 함수 X->X'을 찾아 알고리즘 A의 성능을 최대화하는 것 입니다. 주로, 수치 변환, 범주형 인코딩, 클러스터링, 그룹 집계, PCA와 같은 차원 축소 기법을 포함합니다.
자동화된 특성 엔지니어링은 아래와 같은 주요 선행 연구들이 존재합니다.
DFS(Kanter & Veeramachaneni, 2015) : 여러 테이블을 통합하여 가능한 변환을 열거, 모델 성능에 기반하여 특징을 선별합니다.
Cognito(Khurana et al.,2016) : 트리 형태로 탐색하여 수작업으로 설계된 방식을 사용합니다.
AutoFeat(Horn et al.,2019) : 빔 서치(Beam Search)를 사용하여 특징을 반복적으로 샘플링합니다.
LFE(Nargesian et al., 2017) : 머신러닝 모델을 사용하여 유용한 변환을 추천합니다.
강화학습 기반(Khurana et al.,2018)(Zhang et al.,2019)
그러나 이러한 방법들은 의미적 정보(Semantic Information)을 활용하는데 한계가 있습니다.
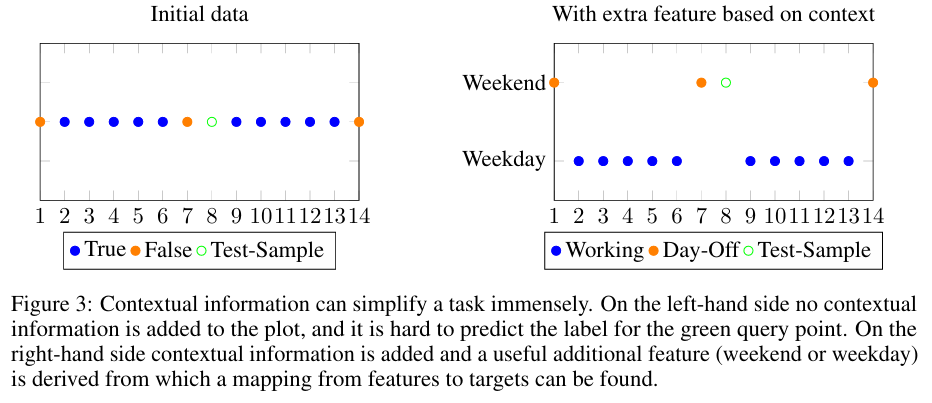 Reprinted Figure.3
Reprinted Figure.3
Figure.3은 문맥 정보의 유용성을 보여줍니다. 왼쪽은 문맥적인 정보가 존재하지 않아 초록색 포인트를 예측하기 어렵지만, 오른쪽은 주말과 평일에 대한 문맥의 정보가 제공되어 예측이 훨씬 용이해집니다.
Ⅳ. Method
CAAFE는 LLM을 활용하여 도메인 지식을 피처 엔지니어링에 사용하는 접근법으로, 자동화와 해석 가능성, 성능을 유지할 수 있는 가능성을 제시합니다.
CAAFE는 여러 번의 반복을 통해서 특성 변환과 평가를 수행합니다. LLM은 코드를 생성하고, D_train과 D_valid에 대해 변환된 데이터셋 D'_train과 D'_valid을 생성합니다.
이때 D'_train을 사용해 머신러닝 분류기를 학습시켜 D'_valid에서 성능 P'을 평가합니다.
P'이 기존 D_trian과 D_valid로부터 얻은 성능 P를 초과하면 해당 특성은 유지되며, D_train과 D_valid 또한 D'_train과 D'_valid로 업데이트도비니다. 만약 성능 개선이 없을 경우, 특성이 폐기됩니다.
 Reprinted Figure.4
Reprinted Figure.4
Figure.4는 Tic-Tac-Toe EndGame의 데이터셋에서 실험한 결과입니다. 2번의 반복으로 ROC AUC 점수를 0.888에서 1.0으로 개선하였습니다.
 Reprinted Figure.5
Reprinted Figure.5
프롬프트는 A. 사용자가 생성한 데이터셋에 대한 설명, B. 피처 이름, C. 데이터 타입, D. 결측치, E. 데이터셋의 10개의 임의의 row를 포함합니다. 또한, 코드와 설명의 형식에 대한 템플릿을 제공하고, CoT를 포함하여 중간 단계의 추론 과정을 안내합니다.
또한, 코드 블록 실행이 오류가 난다면, 이에 대한 에러 리커버리를 수행합니다.
Ⅴ. Experiment Setup
Downstream-Classifiers
평가를 위해 Logistic Regression, RandomForest, TabPFN을 사용하였으며, 피처의 성능을 평가하는 모델로써 TabPFN을 사용하였습니다. 결측치는 평균치로 대체하고, one-hot/oridinal encoding을 수행하엿습니다.
Automated Feature Engineering Methods
또한, DFS(Kanter & Veeramachaneni, 2015)나 AutoFeat(Horn et al., 2019)와 같은 문맥에 의존하지 않는 피처 엔지니어링 라이브러리를 평가했습니다. 평가 시 DFS, AutoFeat을 단독으로 사용하거나, CAAFE와 결합하여 사용하였습니다.
Evaluating LLMs on Tabular Data
LLM의 훈련 데이터는 웹에서 비롯되기에, 훈련 데이터셋이 포함될 가능성이 있습니다. GPT-4와 GPT-3.5는 2021.09에 학습 컷오프를 가지므로, 대부분의 학습 데이터가 그 이전에 생성되었음을 알 수 있다. 즉, 이에따른 편향성이 존재할 수 있습니다.
따라서 평가를 두 범주의 데이터셋에서 수행하였습니다. 하나는 2019년 9월 이전에 공개되어 LLM의 훈련 데이터에 포함되었을 수 있는 데이터와, 다른 하나는 2019년 9월 이후에 Kaggle에서 공개되어 접근하기 위한 절차가 필요한 데이터셋입니다.
Evaluation Protocol
각 데이터셋에 5번의 반복 평가를 수행하고, 각 반복마다 다른 SEED와 train-test split을 사용합니다. 데이터셋은 학습 데이터와 테스트 데이터를 각각 50%씩 나누며 모두 동일한 분할을 사용합니다.
Ⅵ. Result
CAAFE에 대한 실험은 3가지를 주로 이룹니다.
1. CAAFE가 최신 분류기의 성능을 개선할 수 있음을 증명한다.
2. CAAFE가 다른 AutoFE 방법과 어떻게 상호작용하는지 증명한다.
3. CAAFE가 생성한 특성의 예시를 제시한다.
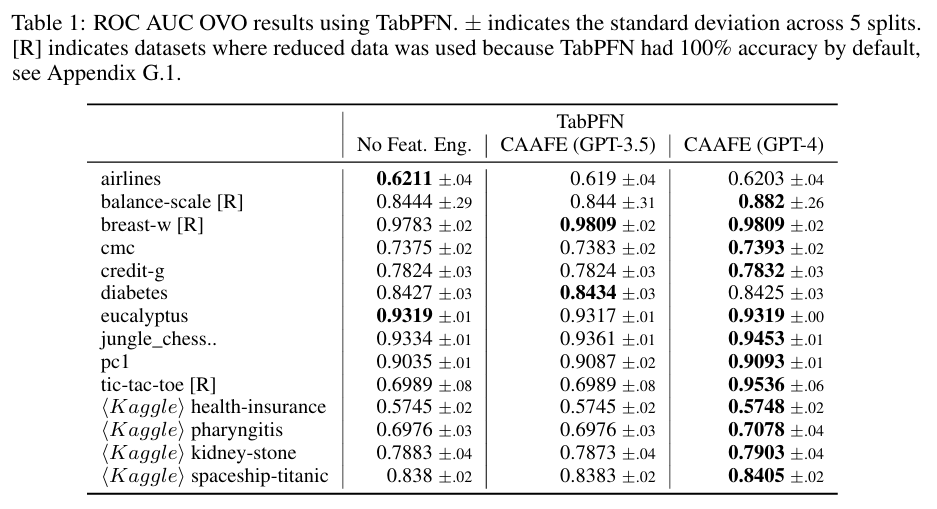 Reprinted Table.1
Reprinted Table.1
TabPFN으로 얻은 ROC AUC 결과를 요약하였으며, 일부 데이터셋은 TabPFN이 완벽한 성능을 보였기에 데이터셋 크기를 축소하여 실험을 진행하였습니다.
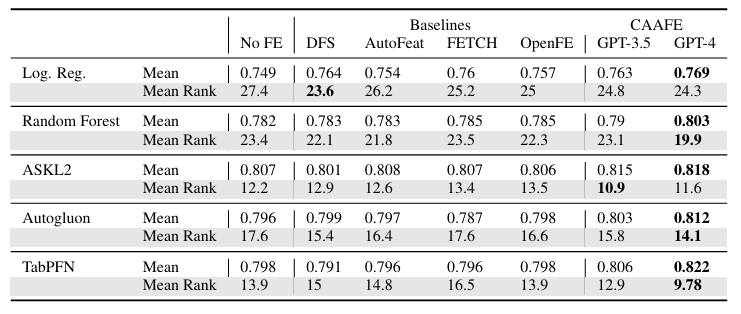
Reprinted Table.2
CAAFE는 TabPFN의 성능을 상당히 개선할 수 있었습니다. 특히, GPT-4와 결합하게 되면 평균 ROC AUC 성능을 0.798에서 0.822로 개선시킬 수 있으며 이는 14개의 데이터셋 중 11개의 데이터셋에서 성능이 향상된 결과입니다.
GPT3.5와 GPT4.0을 비교하면 뚜렷하게 GPT4.0이 더 높은 성능을 보였으며, 심지어 GPT3.5는 14개 중 6개의 데이터셋에서만 성능 향상이 있었습니다.
성능 개선이 얼마나 크게 되는지는 문제가 특성 엔지니어링에 적합한지와 데이터셋 설명의 품질에 있었습니다.
각 데이터셋에 대해서는 약 4분 43초가 소요되었습니다. 시간의 90%는 LLM의 코드 생성에 사용되며, 나머지 10%는 평가에 사용됩니다. 또한, 생성 단계에서 52개의 잘못된 특징(7.4%)가 발생하였지만, 시스템이 이를 복구했습니다.
 Reprinted Table.3
Reprinted Table.3
CAAFE는 주로 1) 특성을 결합하거나, 2)수치형 특성을 범주(구간)화하여 서열 데이터를 생성하거나, 3) 문자열을 변환하거나, 4) 불필요한 특성을 제거하거나, 5) 잘못 생성된 코드의 오류를 복구하는 방법으로 피처 엔지니어링을 수행합니다.
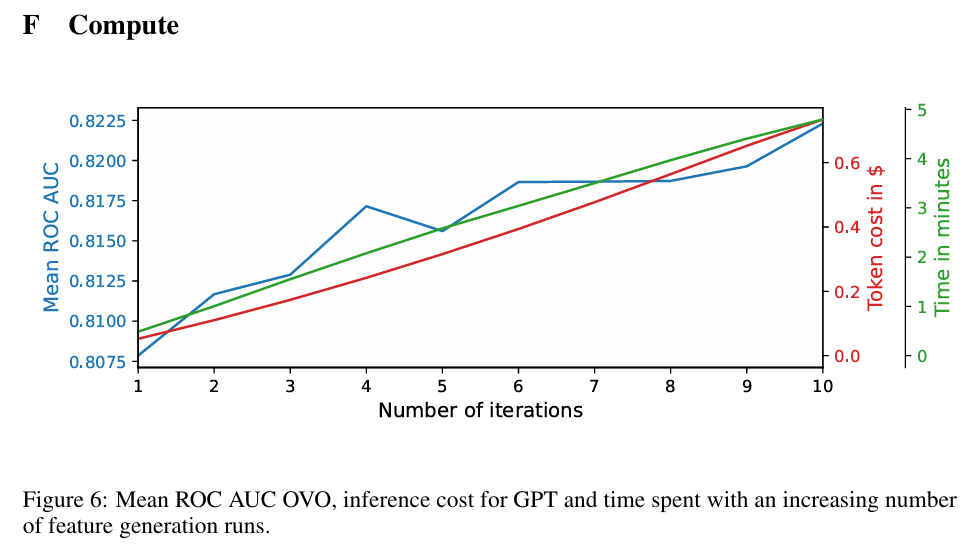 Reprinted Figure.6
Reprinted Figure.6
Figure.6을 통해 특성을 생성하는 반복 횟수에 따라 유의미하게 성능이 올라가지만, Token에 대한 비용과 소요 시간이 함께 증가하는 것을 알 수 있습니다.
Incorporating Classical AutoFE Methods
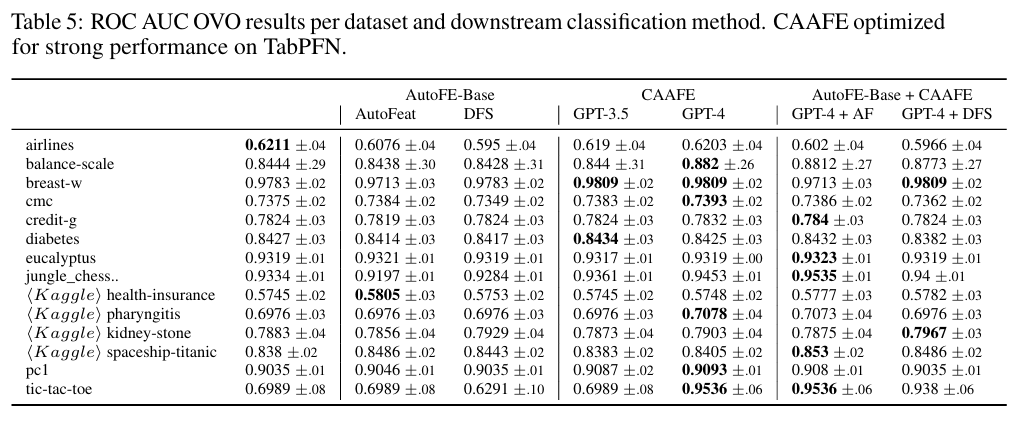 Reprinted Table.5
Reprinted Table.5
또 다른 접근법으로는 전통적인 AutoFE 기법과 CAAFE를 연동할 수도 있습니다. CAAFE를 먼저 실행한 후, AutoFE를 추가적으로 사용하여 더 많은 특징을 생성할 수 있습니다. 특히 Logistic Regression, Random Forest와 같은 성능이 낮은 분류기에서 AutoFE + CAAFE는 큰 성능 향상을 가져왔습니다. 반면에 TabPFN의 경우 뚜렷한 성능 향상이 없었는데 이는 큰 복잡성이나 데이터로부터 필요한 정보를 직접 얻는 TabPFN의 특성에 기인하는 것으로 보여집니다.
Ⅵ. Conclusion
CAAFE는 LLM을 활용하여 피처 엔지니어링을 자동화하고, 기존 AutoFE/AutoML을 보완 및 발전시키는 효과적인 접근법을 제안하였습니다. 또한, 데이터셋에 대한 설명이 더 정확하고 세부적이라면, CAAFE의 성능이 크게 향상될 수 있습니다.
하지만, 피처가 많다면 프롬프트의 길이가 길어지며, 현재 추가 특징의 테스트 절차가 통계적 절차에 기반하지 않으므로 개선의 여지가 있습니다. 또한, LLM의 hallucination이나 사회/윤리적 문제 등이 안좋은 영향을 미칠 수 있습니다.
앞으로 프롬프트 튜닝과 파인 튜닝을 통한 성능 향상, 인간 전문가와 AutoML간의 상호작용 연구, CAAFE의 높은 설명력을 이용한 전문개의 추가적 개선 등이 가능할 것으로 보여집니다.
