이 논문은 재식별에서 많이 사용하는 triplet loss를 처음 도입한 논문이라 읽게 되었다.
얼굴인식 분야에서 triplet loss를 처음 도입한 논문이다.
I. Introduction
이 논문에서는 아래의 시스템을 통합하기 위한 시스템을 제안한다.
- Face verification (얼굴 식별) - Is this same person?
- Face Recognition (얼굴 인식) - Who is this person?
- Face Clustering (얼굴 클러스터링) - Who are similar persons?
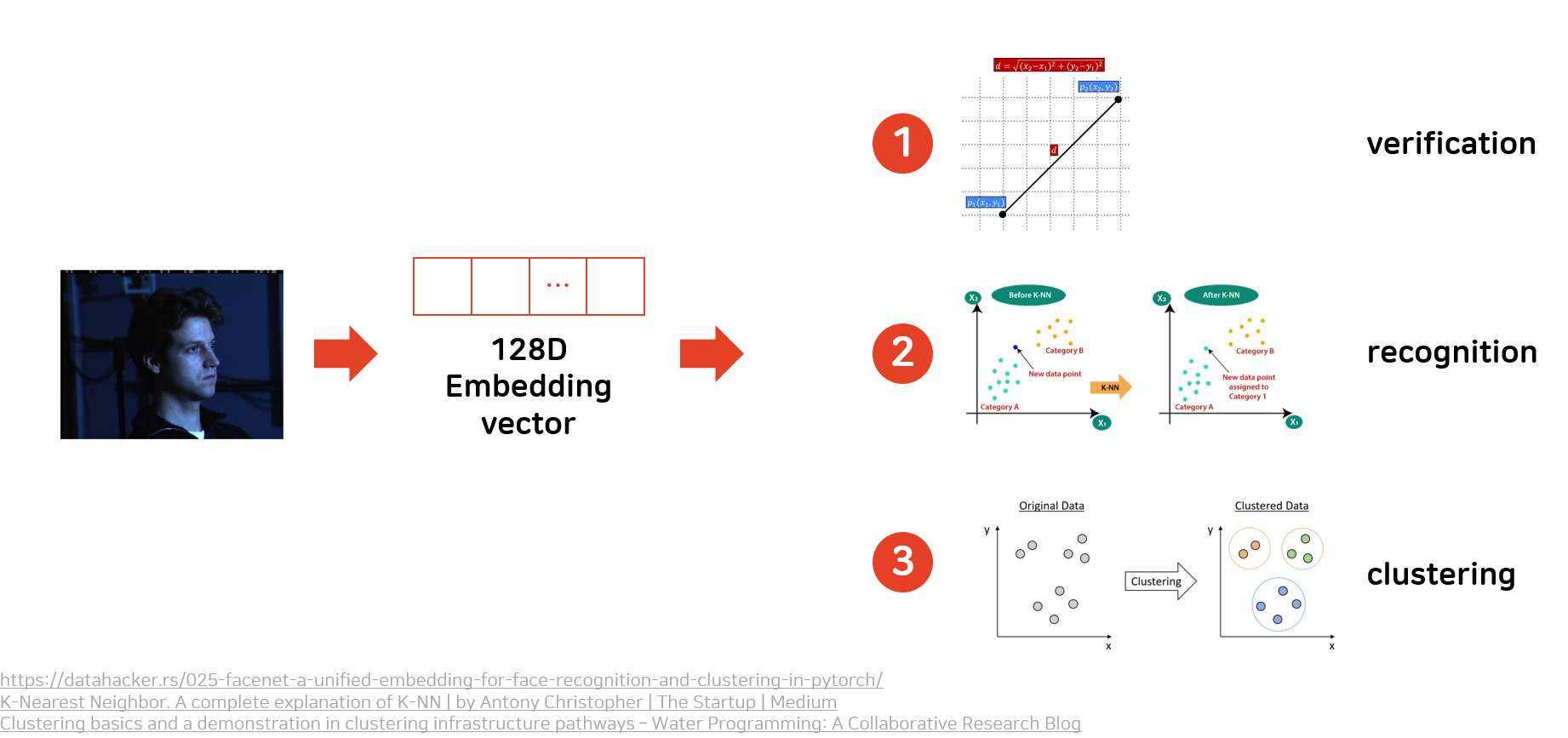
FaceNet 이전의 모델들과 다른 점은 CNN -> BottleNeck Layer -> PCA 같은 복잡한 과정을 거치지 않고, 모델이 128D embedding vector를 추출해내게 된다.
Embedding vector를 얻으면,
- 두 vector 사이의 거리에 threshold를 걸어 verification에 이용할 수 있고
- k-NN classification을 사용하면 recognition을 할 수 있고
- k-means나 agglomerative clustering을 사용하면 외형이 비슷한 사람끼리 묶을 수 있다
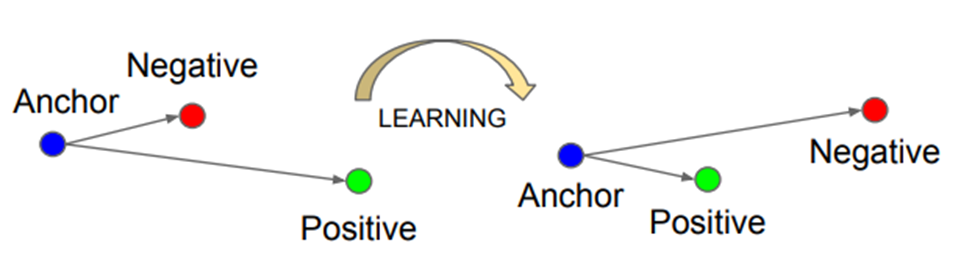
학습에는 Triplet Loss를 도입하여 임베딩 공간에서
같은 사람의 이미지는 가깝게, 다른 사람의 이미지는 멀게 학습한다.
II. Proposed Method
1. Triplet loss
1) Basic idea
Anchor-Positive 거리보다 Anchor-Negative의 거리는 멀어야한다.
'멀다'의 기준은 margin 로 정한다.
→ 같은 사람의 이미지끼리는 임베딩 공간에서 가깝게 위치해야하고, 다른 사람의 이미지끼리는 멀리 위치해야한다.
2) Equation
좌변을 우변으로 이항하면,
이 식을 최소화하는 문제가 된다.
배치 사이즈를 1이라고 가정하고, 식을 좀 더 쉽게 써보면
2-1)
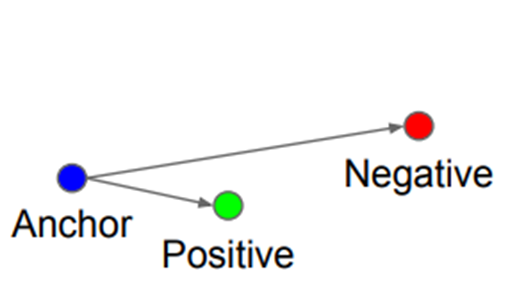
이 경우에는 이미 Anchor-Positive 거리 + 보다 Anchor-Negative 거리가 멀기 때문에 으로 더 이상 학습할 필요가 없는 상태이다.
2-2)
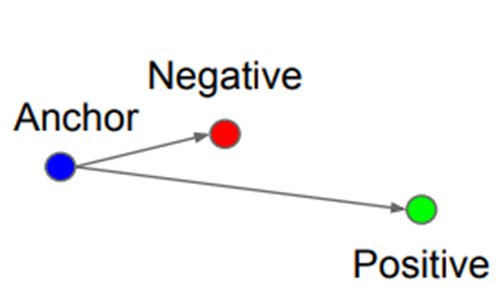
반대로 Negative가 더 가까이 있는 경우는 이기 때문에 학습을 진행해야하는 상태이다.
3) Triplet Selection
Triplet은 어떻게 선택할까?
기본적으로 Triplet loss equation을 위배하는 쌍을 찾는 것이 빠른 수렴에 도움이 된다.
- Anchor-Positive 거리가 먼 경우 (Hard Positive)
- Anchor-Negative 거리가 가까운 경우 (Hard Negative)
이를 수식으로 나타내면 다음과 같다.
- (Hard Positive)
- (Hard Negative)
하지만 전체 데이터 셋에 대해 argmax/min을 구하는 것은 비효율적이고,
노이즈 이미지나 잘못된 라벨에 의해 학습이 불안정해 진다.
논문에서는 두 가지 방법을 소개한다.
1. Online Triplet Selection
모델의 최근 체크포인트를 사용하여 전체(or 일부) 데이터 셋에 대해 임베딩을 구하고 임베딩으로부터 hard triplet을 선택.
2. Offline Triplet Selection
매 배치마다 배치안의 데이터에서 현재 모델로 부터 임베딩을 구하고 hard triplet을 선택
논문에서는 online triplet을 다루고 있다.
논문에서의 Online Triplet Selection:
- 각 미니배치 당 한 명에 대해 약 40장의 이미지 사용
- 각 미니배치에 negative face도 랜덤하게 샘플
- 배치 사이즈는 약 1800
- Hard positive를 선택하는 것 대신 모든 anchor-positive를 선택
- Hardest negative를 사용하면 local minima에 빠질 가능성이 있어 Semi-Hard Negative를 선택
4) Semi-Hard Negative
Anchor-positive 거리보다는 멀리 있지만
여전히 margin 만큼은 더 멀지 있지 못하는 경우를 선택한다
2. Deep Convolution Network
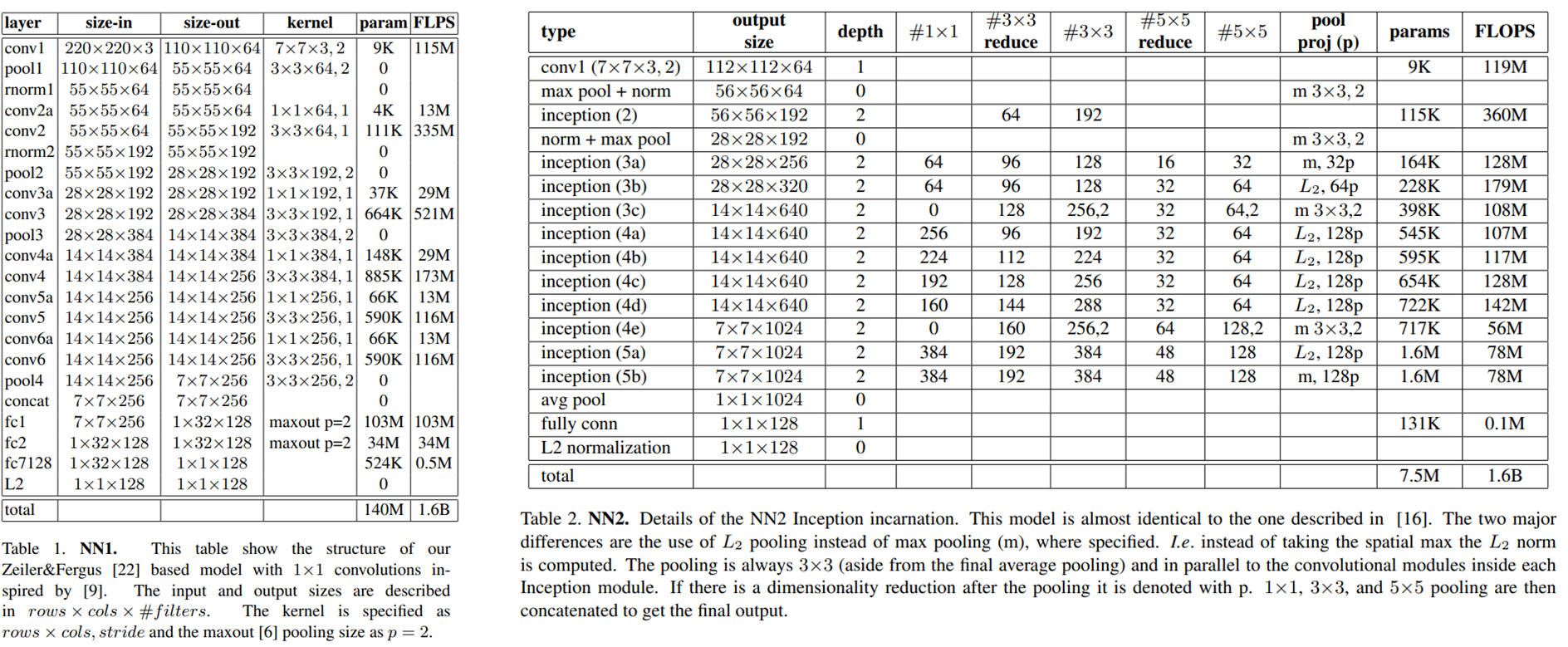
FaceNet은 CNN기반 네트워크이다.
ZFNet 기반 모델과 GoogleNet 스타일의 Inception 기반 모델을 소개하고 있고,
이 두 네트워크의 차이는 파라미터 수와 FLOPS에 있다.
이 외에도 모바일 기기에서 사용할 수 있을 정도로 작은 네트워크도 설계했다고 한다.

III. Results and Discussion
1) Embedding Dimensionality
- 임베딩은 128 차원일 때 가장 좋은 성능을 보였고,
- 더 큰 차원의 경우에는 유사한 성능을 보였지만, 같은 정확도를 얻기 위해 더 많은 학습이 필요
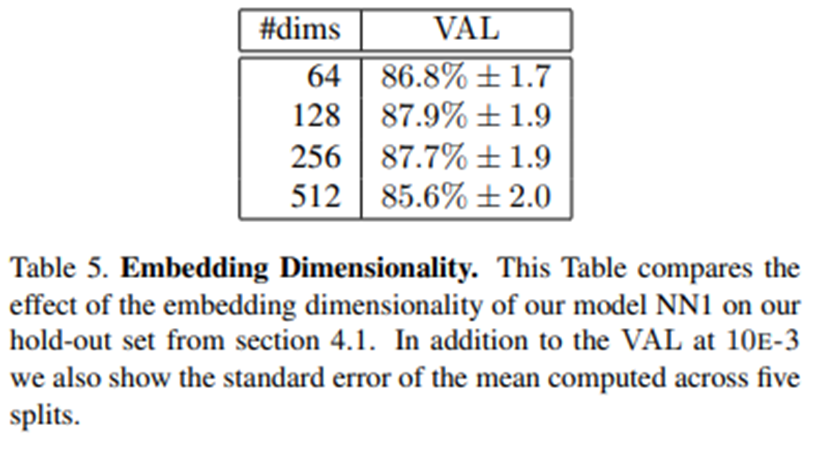
2) Performance
dataset은 LFW (Labeled Face in the Wild), Youtube Faces DB에서 실험,
DeepFace, DeepId2+와 비교.
-
LFW:
- 중앙 크롭만 했을때: 98.87% ± 0.15
- Face Alignment 시: 99.63% ± 0.09
→ 얼굴 방향을 정렬했을 때 더 높은 성능을 보임
→ DeepFace 보다 오류가 7배 감소, DeepId2+ 보다 30% 감소
-
Youtube Faces DB:
- 95.12% ± 0.39
→ DeepFace: 91.4%, DeepId2+: 93.2% 보다 개선
- 95.12% ± 0.39
3) 정리
FaceNet은 CNN bottle neck layer를 사용하여 임베딩을 추출하고
PCA/SVM 등의 후처리를 필요로 하지 않고, 128차원의 임베딩을 추출하여
end-to-end로 Triplet loss를 사용하여 임베딩을 직접 학습한다.
