
머신러닝은 인공지능의 안에 속해있는 개념이다
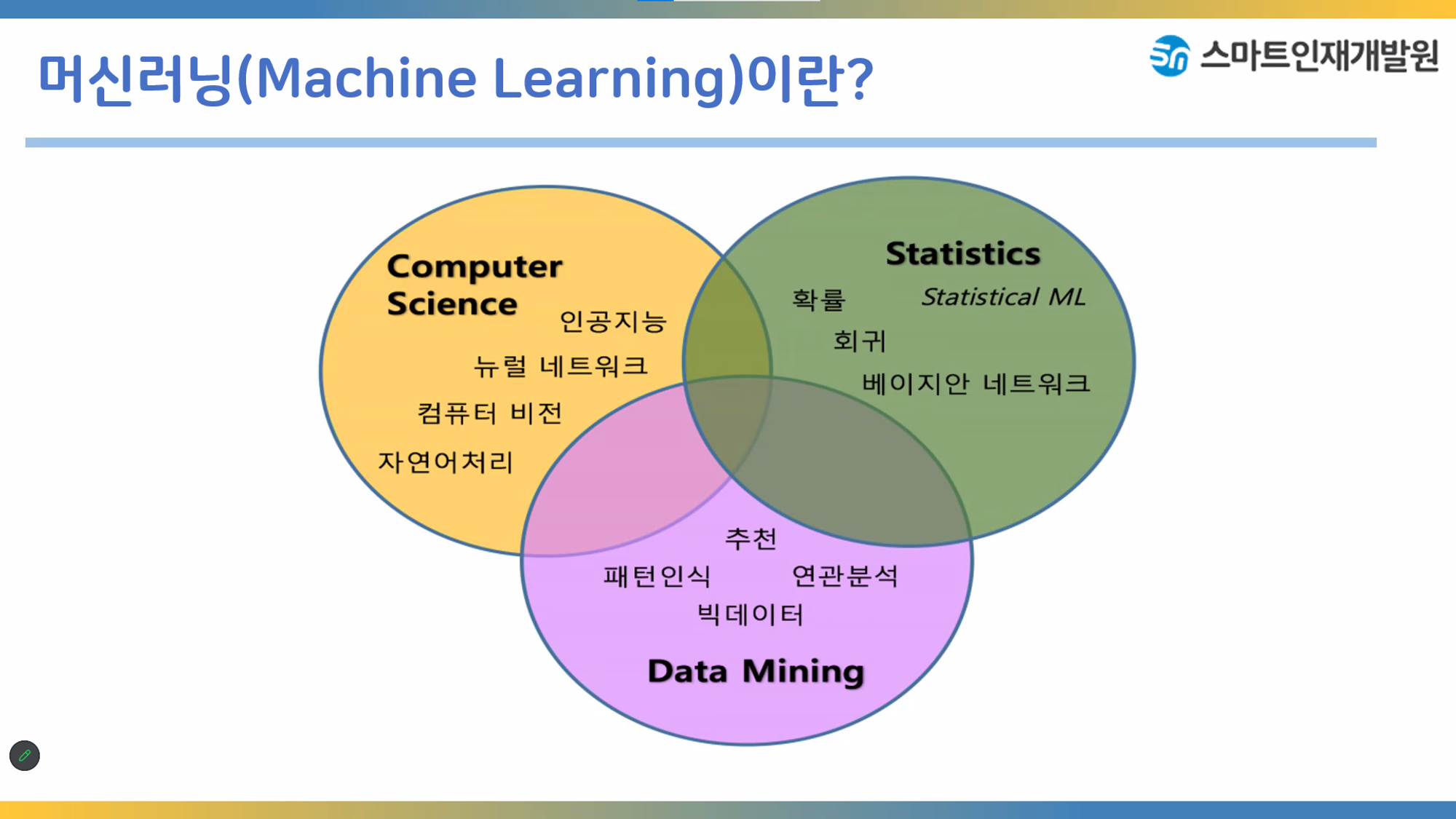
머신러닝은 cs/statistic/data mining의 합집합에 해당하는 개념이다

앨런 매시슨 튜링은 인공지능의 아버지이다.
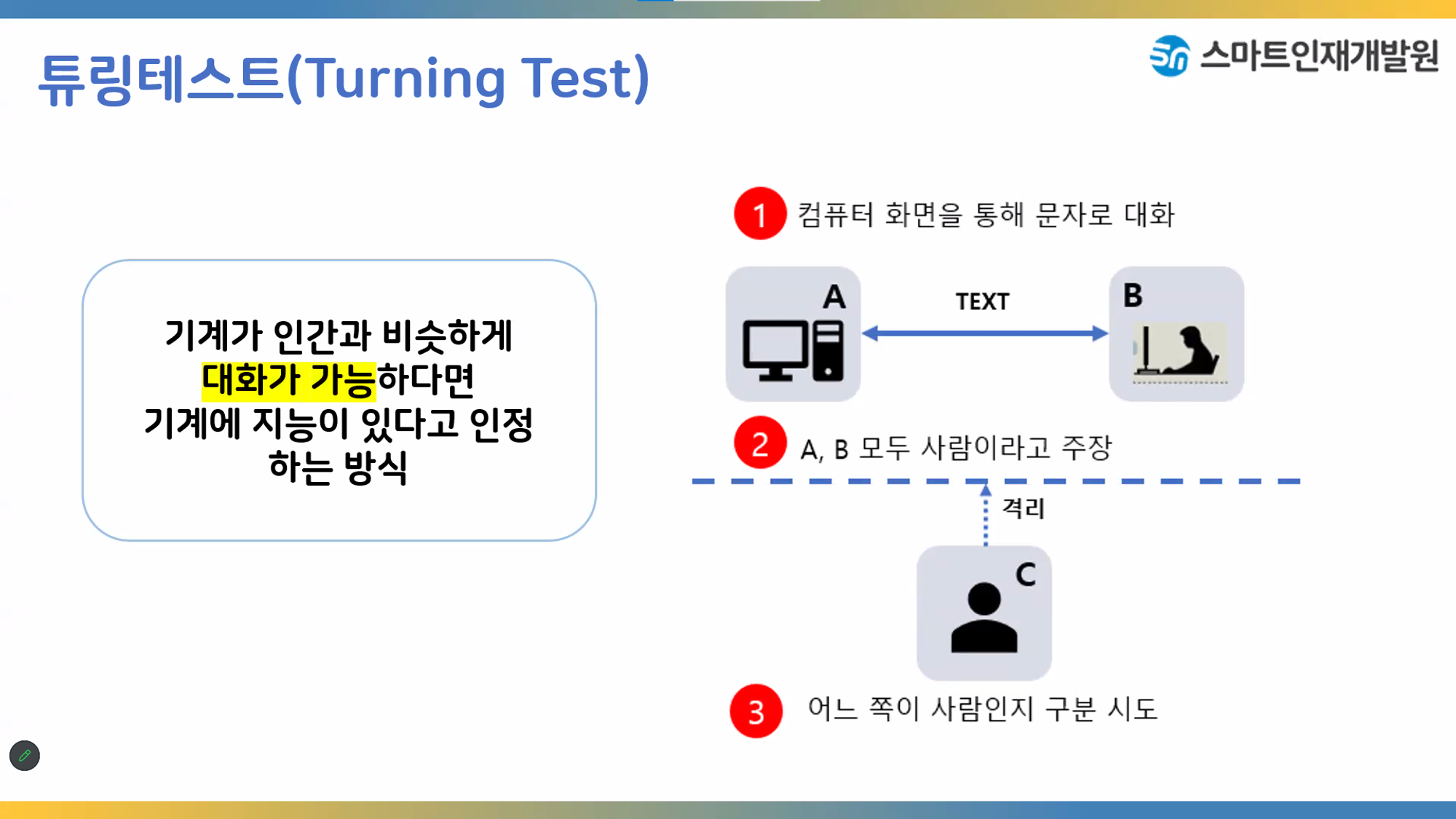
튜링테스트는 기계는 생각할수 있는가 없는가하는 의문에서 시작된 테스트이다.
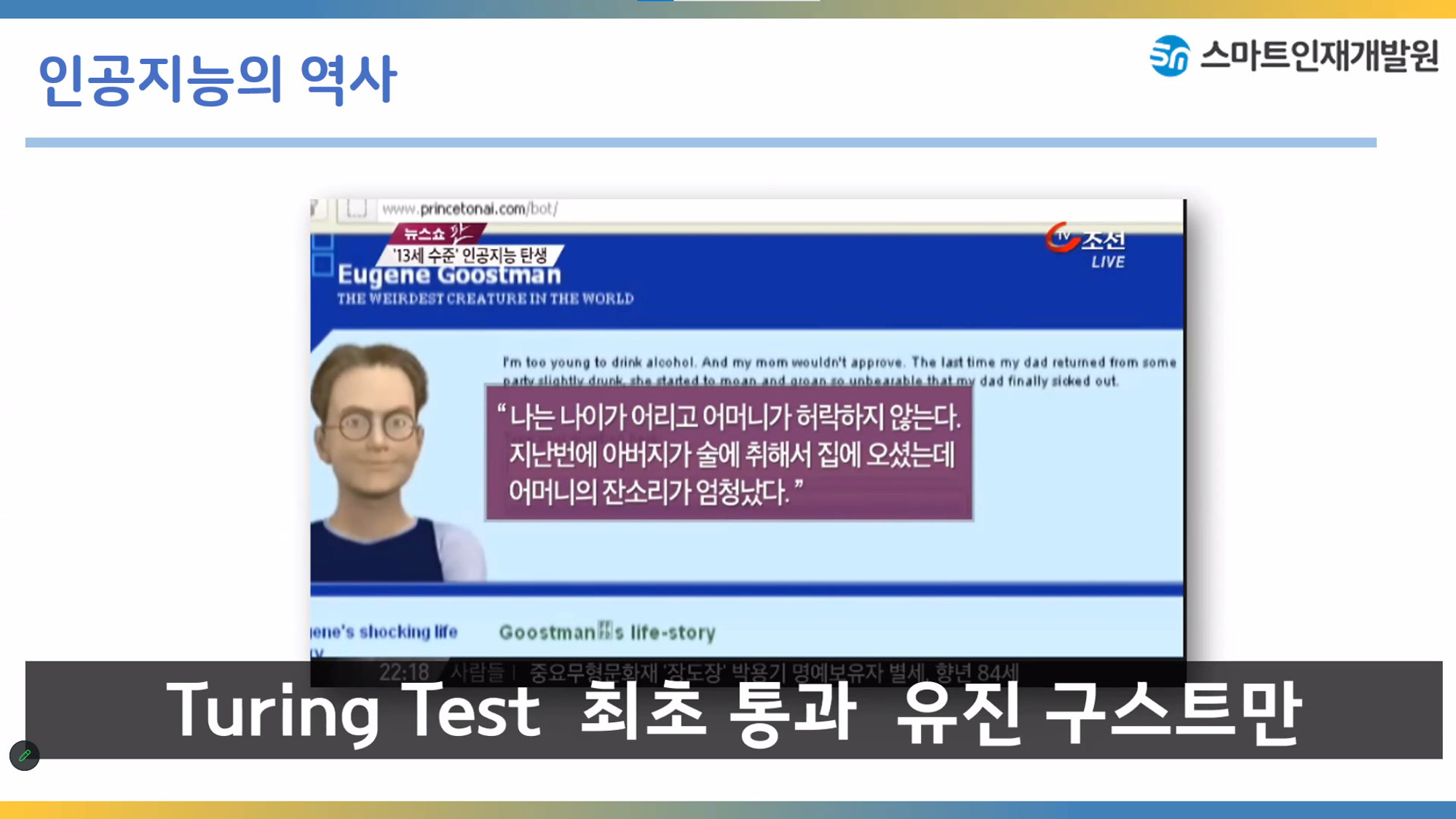
러시아에서 개발한 인공지능이지만 완벽하지않아서 미국에서는 인정하지않았다
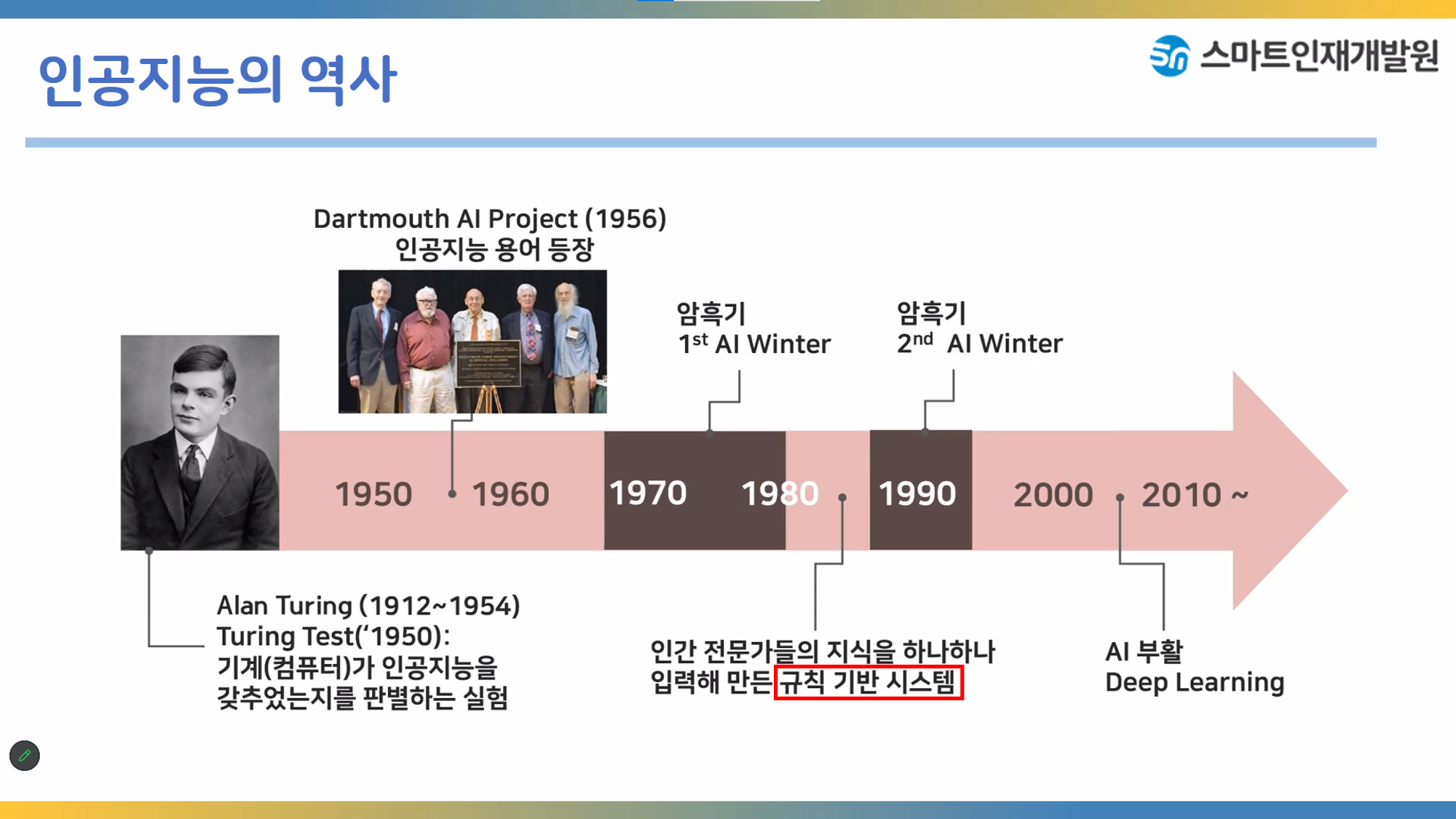
여러 암흑기를 거쳐 2000년대 이후에 딥러닝에의해 인공지능이 다시 부활되었다

정해진 답변만 할 수 있는 챗봇이기때문에 인공지능이라보기 어렵다

현재의 인공지능은 약한인공지능이라할 수 있다

가장 인기있는 인공지능 이루다였으나 사회적물의를 일으킬만한 발언을 함으로서 이루다의 서비스는 중단되었다

데이터를 예쁘게 가공하는 작업이다
레이블 인코딩
단순 수치 값으로 mapping하는 작업
숫자 값의 크고 작음에 대한 특성으로 인해 예측성능이 떨어지는 경우가 발생할 수 있음
원핫인코딩
단어를 표현하는 가장 기본적인 표현방법
특성을 세부적으로 나줘서 생각할 수 있음
필요한 공간이 계속 늘어나 저장공간 측면에서는 비효율적인 방법
결정트리(Decision Tree)
주요 매개변수(Hyperparameter)
scikit-learn의 경우
DecisionTreeClassifier(max_depth, max_leaf_nodes, min_sample_leaf)
- 트리의 최대깊이 : max_depth
(값이 클수록 모델의 복잡도가 올라간다.) - 리프 노드의 최대 개수 : max_leaf_nodes
- 리프 노드를 구성하는 최소 샘플의 개수 : min_samples_leaf
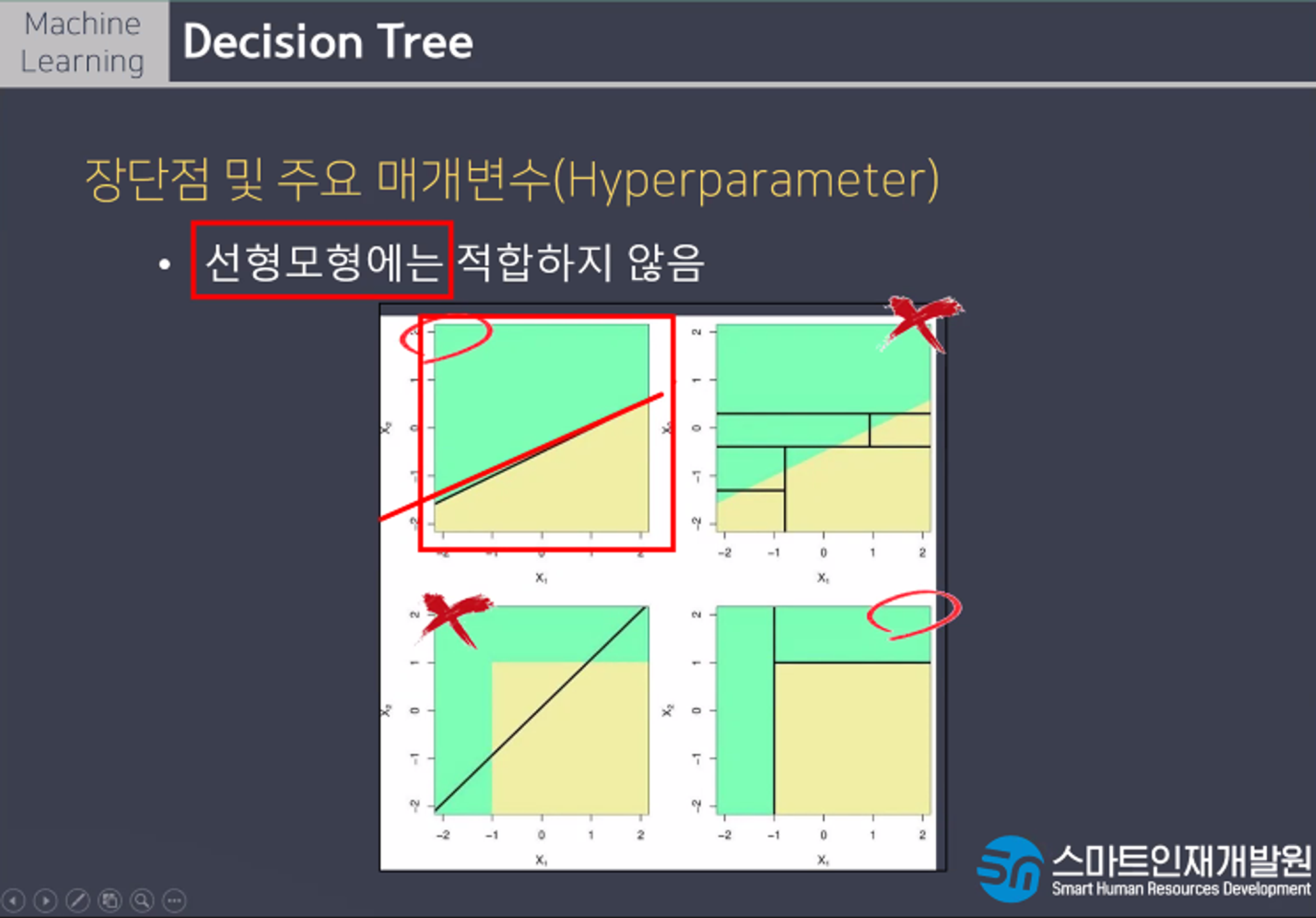
장단점 및 주요 매개변수
만들어진 모델을 쉽게 시각화 할 수 있어 이해하기쉽고 각 특성이 개별 처리되기 때문에 데이터 스케일에 영향을 받지않아 특성의 정규화나 표준화가 필요없다. 트리 구성시 각 특성의 중요도를 계산하기 때문에 특성선택에 활용될 수 있다.
단점으로는 훈련데이터 범위 밖의 포인트는 예측할 수 없고, 가지치기를 사용함에도 불구하고 과대적합되는 경항이 있어 일반화 성능이 좋지않다. 또한 선형모형에는 적합하지않다.
머신러닝 실전연습
머신러닝의 과정은 1.Problem Identification(문제정의), 2.Data Collect(데이터 수집), 3.Data Preprocessing(데이터 전처리), 4.EDA(탐색적 데이터 분석), 5.Model선택, Hyper Parameter조정, 6.Training(학습), 7.Evaluation(평가)로 총 7단계로 이루어진다
1단계 문제정의는 비즈니스 목적을 정의하는 단계이다.모델을 어떻게 사용해 이익을 얻을까 생각하고 현재 솔루션의 구성을 파악한다.
'타이타닉 데이터를 사용해서 생존자와 사망자 예측해보기'라는 문제정의를 하고
kaggle 사이트로부터 train, test 데이터 다운로드하는 데이터 수집이라는 2단계 과정을 거친다
import pandas as pd
train = pd.read_csv('./titanic/train.csv')
test = pd.read_csv('./titanic/test.csv')
train.shape, test.shape이 코드를 입력하면
((891, 12), (418, 11))이러한 결과값이 나온다
train에는 891개의 행과 12개의 열이 나오고 test에는 418개의 행과 11개의 열이 나온다는것을 알 수 있다
다음은 3단계인 데이터 전처리과정이다
데이터 전처리에는 결측치처리와 이상치처리가 있다.
# 결측치 : Age, Cabin, Embarked
train.info()를 하면
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB이라는 결괏값이 나온다
test를 확인하려면
# 결측치 : Age, Cabin, Fare
# 타입 변경 : Name, Sex, Ticket, Cabin, Embarked
test.info()를 입력하고
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.1+ KB이라는 결괏값을 확인한다.
# 정답 컬럼 분리
y_train = train['Survived']다음으로는 PassengerId를 삭제한다
Survived를 예측하는데 도움이되지않기때문이다
# train = train.drop('PassengerId', axis = 1)
# inplace = True : 변경된 결과 저장
train.drop('PassengerId', axis = 1, inplace = True)
test.drop('PassengerId', axis = 1, inplace = True)Embarked 결측치 채우는 과정이다
Embarked는 탑승한 항구이다.
train에 2개의 결측치가 존재한다.
# value_counts() : 값의 갯수 세어주는 함수
train['Embarked'].value_counts()이라는 코드를 입력하면
S 644
C 168
Q 77
Name: Embarked, dtype: int64이라는 결괏갑이 나온다
# 최빈값으로 결측치 채우기
train['Embarked'] = train['Embarked'].fillna('S')Fare(요금)결측치를 채우려면 먼저 통계치를 확인해야한다
# 통계치 확인하기
test['Fare'].describe()count 417.000000
mean 35.627188
std 55.907576
min 0.000000
25% 7.895800
50% 14.454200
75% 31.500000
max 512.329200
Name: Fare, dtype: float64test['Fare'].fillna(14.45, inplace = True)test.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 418 non-null int64
1 Name 418 non-null object
2 Sex 418 non-null object
3 Age 332 non-null float64
4 SibSp 418 non-null int64
5 Parch 418 non-null int64
6 Ticket 418 non-null object
7 Fare 418 non-null float64
8 Cabin 91 non-null object
9 Embarked 418 non-null object
dtypes: float64(2), int64(3), object(5)
memory usage: 32.8+ KBAge 결측치를 채워보자
단순 통계치가 아니라 다른 컬럼간의 상관관계를 이용해서 채워보자
train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Name 891 non-null object
3 Sex 891 non-null object
4 Age 714 non-null float64
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Ticket 891 non-null object
8 Fare 891 non-null float64
9 Cabin 204 non-null object
10 Embarked 891 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 76.7+ KB# Pclass, Sex를 기준으로 Age 결측치를 채워보자
# Age에 결측치가 존재한다 =>Pclass와 Sex를 확인하고 해당하는 값으로 결측치 채움
# Age에 결측치가 존재하지 않는다 => 그 값을 그대로 사용한다
age_table = train[['Pclass','Sex','Age']].groupby(by=['Pclass','Sex']).median()train.iloc[19]Survived 1
Pclass 3
Name Masselmani, Mrs. Fatima
Sex female
Age NaN
SibSp 0
Parch 0
Ticket 2649
Fare 7.225
Cabin NaN
Embarked C
Name: 19, dtype: object# apply
# 행이나 열 단위로 복잡한 작업(커스텀 함수)을 할 때 사용
# 결측치채우는 함수 만들기
import numpy as np
def fill_age(data): # data는 하나의 행 데이터(한 사람의 데이터)
if np.isnan(data['Age']): # 결측치면 True, 아니면 False
# 결측치라면 Pclass와 Sex를 확인하고 해당 값으로 age_table에서 검색
# 나온값으로 결측치 채우기
return age_table.loc[data['Pclass'],data['Sex']][0]
else:
# 값이 있기때문에 그대로 사용
return data['Age']#fill_age() # 함수를 사용하겠다
#fil_age # 함수를 가져오겠다# apply는 한 행(axis = 1)씩 데이터를 가져와서 fill_age 함수에 집어넣음
train['Age'] = train.apply(fill_age, axis = 1)
test['Age'] = test.apply(fill_age, axis = 1)train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Name 891 non-null object
3 Sex 891 non-null object
4 Age 891 non-null float64
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Ticket 891 non-null object
8 Fare 891 non-null float64
9 Cabin 204 non-null object
10 Embarked 891 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 76.7+ KB유방암 데이터 실습
문제정의
- 유방암 환자의 데이터를 사용해서 유방암의 정도를 예측하기
2. 데이터 수집
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()cancer.keys()dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])# malignant : 암
# benign : 암이 아니다
cancer['target_names']array(['malignant', 'benign'], dtype='<U9')cancer['feature_names']array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')데이터 전처리
import pandas as pd
# 문제데이터
X = pd.DataFrame(cancer['data'], columns = cancer['feature_names'])
X.head()# 정답데이터
y = pd.DataFrame(cancer['target'],columns = ['cancer'])
y.head()탐색적 데이터 분석
- 생략
데이터 스케일링
- 데이터 전처리를 마무리하고 실행
- 원래 가지고있던 데이터의 의미가 변형되기 때문에 모든 전처리를 마무리 한 후에 사용
from sklearn.preprocessing import RobustScaler, StandardScaler, MinMaxScaler
rbs = RobustScaler()# 1. 스케일링 모델 불러오기
rbs = RobustScaler()
# 2. 가지고 있는 데이터로 스케일링 모델에 학습 > 어떤값이 어떻게 변하는지 파악
rbs.fit(X)
# 3. 파악된 규칙을 통해서 값을 변형
X_rbs = rbs.transform(X)sds = StandardScaler()
선형회귀함수
-
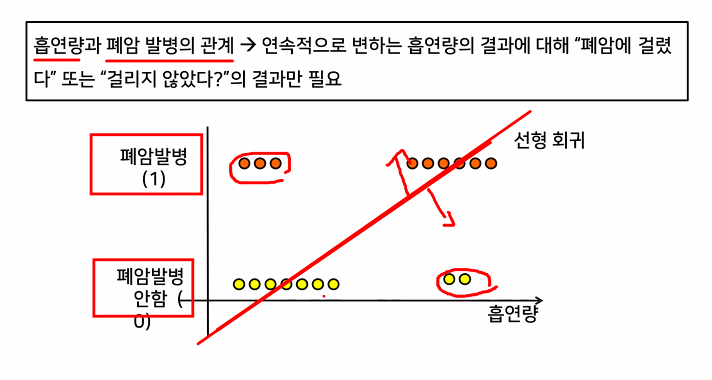
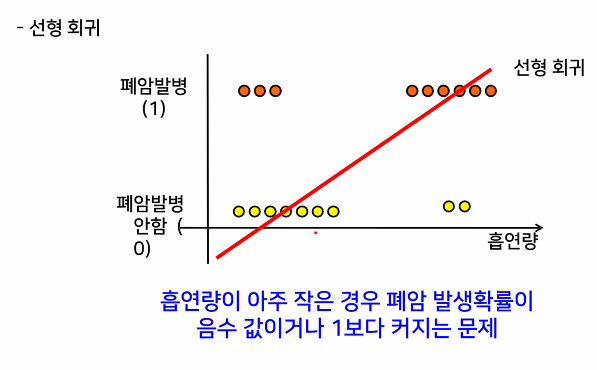
가지고있는 데이터를 잘 표현할 수 있는 선형함수 찾기
- 모든 데이터를 설명할 수 있는 직선은 없다!
-
데이터를 최대한 잘 설명하는 선형함수 찾기
- 오차(실제값과 예측값의 차이들의 합)가 최소가 되는 직선 찾기 > 예측함수로 사용
-
선형함수의 갯수가 무한대이다
-
무한개의 선형함수를 계산하지말고 계산할 선형함수의 갯수를 줄여보자(2가지 방법이 존재)
- 선형함수의 갯수가 무한대이다
- 무한개의 선형함수를 계산하지말고 계산할 선형함수의 갯수 를 줄여보자(2가지 방법이 존재)
- 수학 공식을 이용한 해석적 방법
º 한번에 계산할 공식이 존재
단 : 공식이 완벽하지 않다 > 값이 잘못됐을때 고칠수 없음
장 : 매우 빠르다
모델 : LinearRegression, Lasso, Ridge - 경사하강법
º 점진적으로 정답을 찾아간다
단 : 속도가 느리다
장 : 값이 잘못됐을때 고칠 수 있음
모델 : SGDRegressor
- 수학 공식을 이용한 해석적 방법
★ 결론
1. 가지고있는 데이터를 최대한 잘 설명할 직선 찾기
2. 오차를 계산해서 오차가 가장 작은 직선 찾기
3. 무한개의 직선을 계산하지 않고 특정 갯수의 직선만 계산

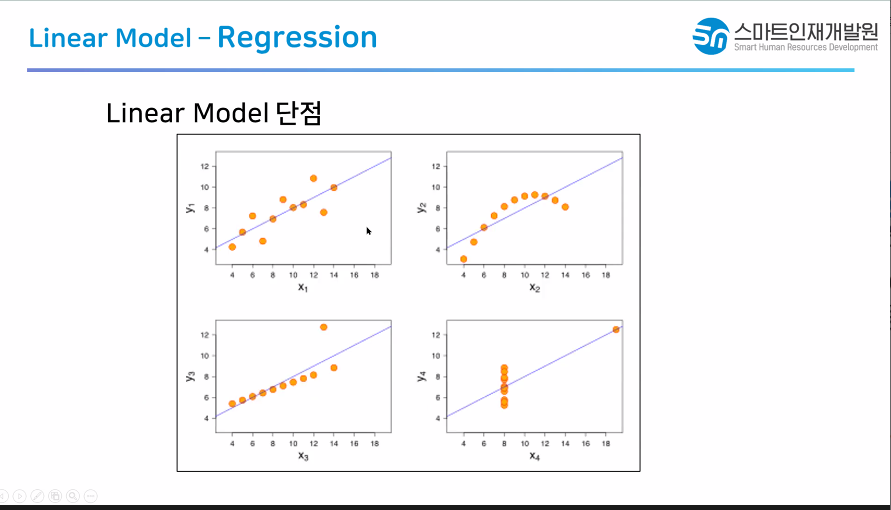
선형모델 장점
1.예측 속도가 빠르다
선형 함수를 찾고 가중치와 절편이 결정되 어있는 상태
새로운 데이터가 들어오면 그 함수에 집 어넣기만하면 됨
2. 예측 속도가 빠르기때문에 나타나는 현상임
3. y = w1x1 + w2x2 + w3x3 +.....+wpxp + b

선형 모델은 데이터의 분포가 다른 데이터의 분포일때 잘 안어울림


바꿀 수 있는 모델을 추가한 모델?
Linear Regression : 수학 공식을 이용한 모델
- 결과가 나오면 수정 불가능
lasso모델과 Ridge모델
Linear Regression + 모델 정규화
모델 정규화란?
w와 b에 직접적인 수정을 가하는것.
특정 계수들은 0이됨
0보다 작은것도 0취급
0이 된것들은 사용X

릿지와 라쏘는 둘 다 회귀(Regression) 분석에서 사용되는 방법이에요.
릿지(Ridge):
릿지 회귀는 어떤 것을 예측할 때 사용되는 특별한 수학적 방법 중 하나이다.
릿지는 데이터의 패턴을 찾을 때 도움이 되는데, 가끔 큰 숫자들이 예측에 영향을 많이 미칠 때 사용된다.
마치 강한 다리(릿지)를 사용해서 예측을 할 때, 중요하지 않은 숫자들도 도와줄 수 있다
라쏘(Lasso):
라쏘 회귀도 데이터 예측에 사용되는 방법 중 하나이다..
라쏘는 릿지와 비슷하지만, 어떤 숫자들은 완전히 무시되도록 도와준다.
라쏘는 마치 마법사처럼 중요하지 않은 것들을 예측에 사용하지 않도록 해서 모델을 더 간단하게 만들어 준다.
간단하게 말하면, 릿지와 라쏘는 데이터를 예측할 때 도움을 주는 두 가지 다른 방법이다. 릿지는 큰 숫자들을 다루는 데 좋고, 라쏘는 중요하지 않은 것들을 무시하는 데 도움이 된다.
선형회귀모델
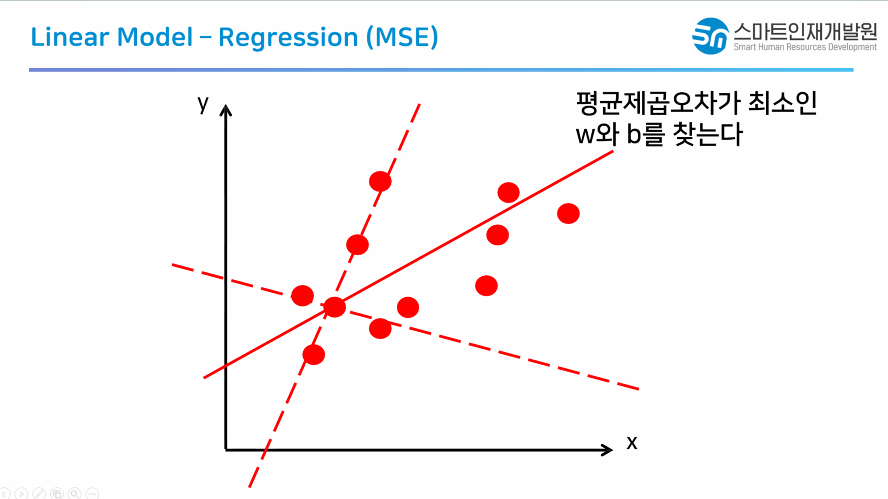
가지고있는 데이터를 최대한 잘 설명하는 선 찾기
가지고있는 데이터를 완벽하게 설명할 순 없다.
오차(MSE-평균제곱오차)가 최소인 직선을 찾자!
*MSE = 회귀 평가 지표
직선의 갯수는 무한대이다.
모든 직선을 계산하지않고, 특성 직선(직선의 갯수가 유한개)을 계산한다.
1) 수학 공식을 이용
- 장점 : 한번에 계산한다 > 속도가 빠르다
- 단 : 공식이 존재한다 > 잘못된 결과나와도 수정이 불가능하다.
- LinearRegression 모델
2) 경사하강법
- 장 : 점진적으로 최적의 직선을 찾아간다 > 잘못된 결과도 수정 가능
- 단 : 여러번 계산 한다 > 속도가 느리다
- SGDRegressor 모델
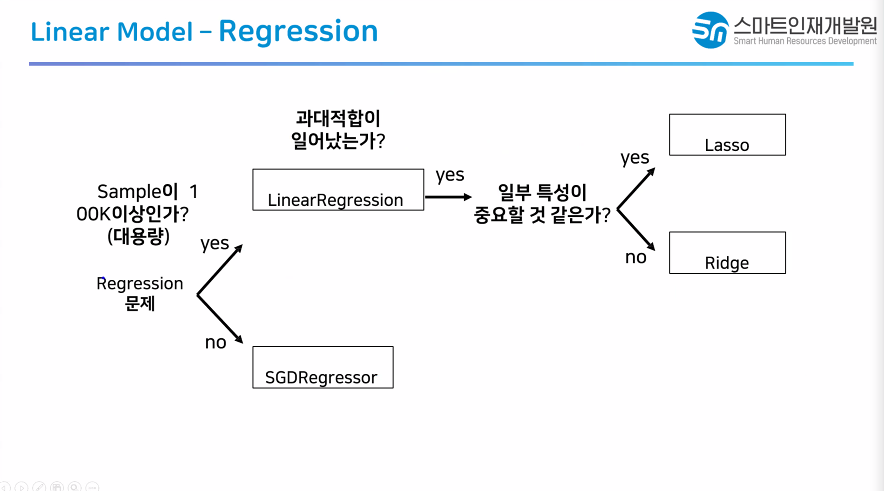
LinearRegression 발전시키기
- LinearRegression + 규제 : 모델 2가지
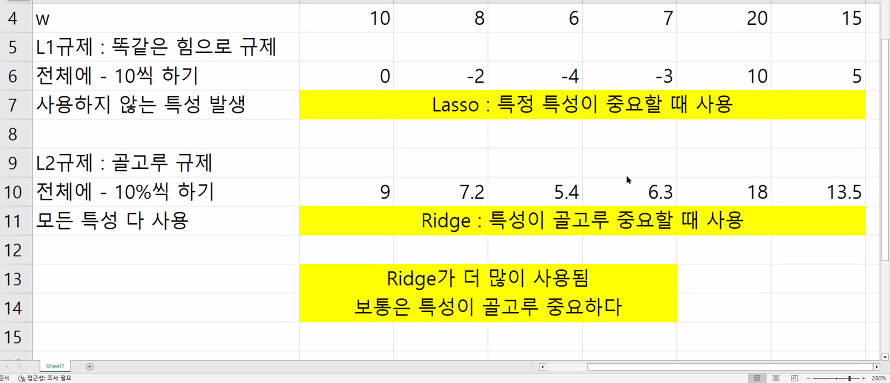
- Lasso : 모든 w에 똑같은 힘으로 규제를 가한다 0보다 가중치가 작아지면 사용하지않는다 특성선택(중요한 특성 찾기) 특정한 데이터가 중요할 떄 사용
- Ridge : 모든 w에 똑같은 비율로 규제를 가한다. 모든 가중치는 0이하로 되지않는다. 모든 가중치를 사용한다. 데이터가 고루 중요할 때 사용 릿지라는 모델이 보통 사용된다는 뜻 보통은 데이터가 골고루 중요하다

MSE 값만보고 모델을 판단하기 애매함
값의 범위를 확인해야지 MSE에대한 정확한 판단이가능하당!!!!!!
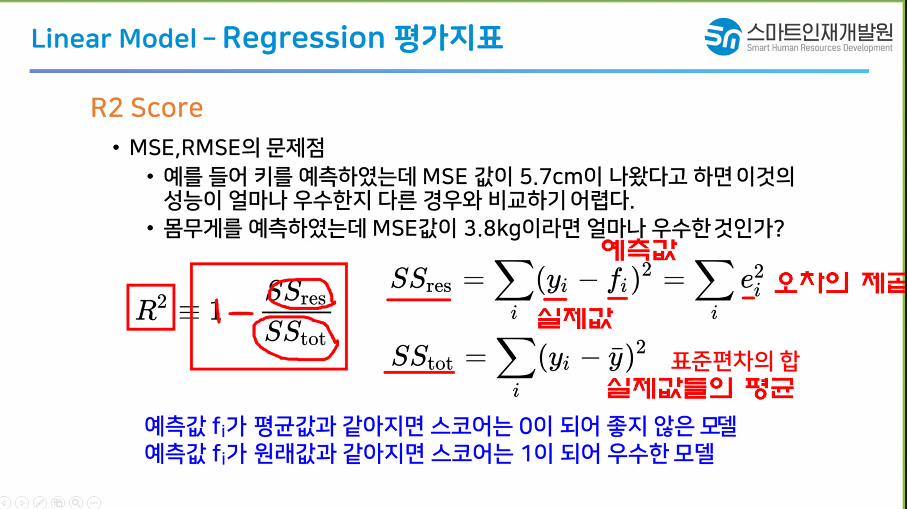
회귀평가지표
- R2 Score
: MSE는 데이터의 범위를 봐야 제대로된 판단이 가능하다
: R2 Score는 데이터의 범위를 안봐도 모델 성능 판단이 가능하게 만들자
-> 0~1까지 값치 출력되게 하자
-> 정확도처럼 해석

0에 가까울수록 좋고 1에 가까울수록 안좋다고 생각하면된다
선형 회귀 모델
- 가지고있는 데이터를 최대한 잘 설명하는 선 찾기
> 가지고있는 데이터를 완벽하게 설명할 순 없다.
> 오차(MSE - 평균제곱오차)가 최소인 직선을 찾자.
* MSE = 회귀 평가 지표
> 직선의 갯수는 무한대이다
> 모든 직선을 계산하지 않고, 특정 직선을 계산(직선의 갯수가 유한개)
1) 수학 공식을 이용
- 장 : 한번에 계산한다 > 속도가 빠르다
- 단 : 공식이 존재한다 > 잘못된 결과도 수정이 불가
- LinearRegression 모델
2) 경사하강법
- 장 : 점진적으로 최적의 직선을 찾아간다
> 잘못된 결과도 수정 가능
- 단 : 여러번 계산을 한다 > 속도가 느리다
- SGDRegressor 모델
LinearRegression 발전시키기
- LinearRegression + 규제 : 모델 2가지
- Lasso : 모든 w에 똑같은 힘으로 규제를 가한다
0보다 가중치가 작아지면 사용하지 않는다
특성 선택(중요한 특성 찾기)
특정한 데이터가 중요할때 사용
- Ridge : 모든 w에 똑같은 비율로 규제를 가한다
모든 가중치는 0이하로 되지 않는다.
모든 가중치를 사용한다.
데이터가 고루 중요할 때 사용
MSE
1. 오차 10000
데이터 값 : 1000
2. 오차 100000
데이터 값 : 10000000
MSE 값만보고 모델을 판단하기 애매함
- 값의 범위를 확인해야지 MSE에 대한 정확한 판단
회귀평가지표
- R2 Score
: MSE는 데이터의 범위를 봐야 제대로된 판단이 가능
: R2 Score는 데이터의 범위를 안봐도 모델 성능 판단이 가능하게 만들자
> 0 ~ 1까지 값이 출력되게 하자
> 정확도처럼 해석
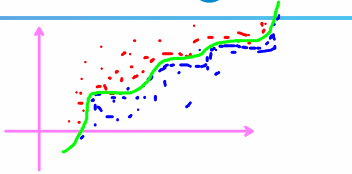
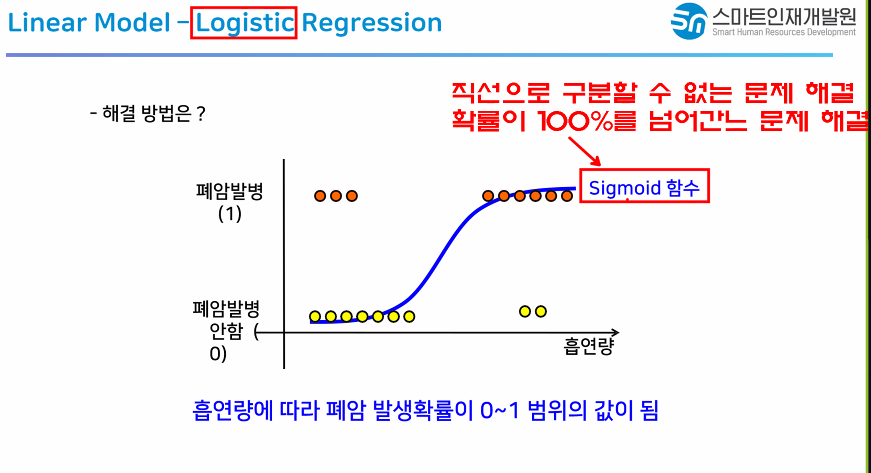
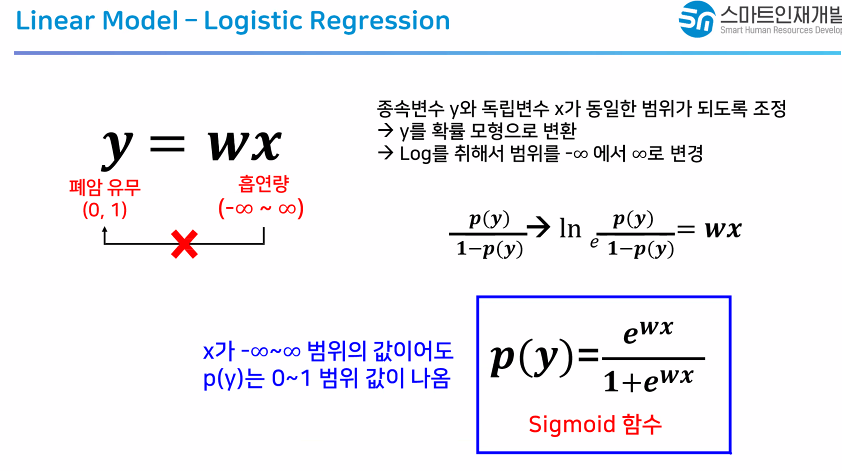
- Logistic Regression
(Regression 단어가 붙지만 분류용 모델) - Linear Support Vector Machine


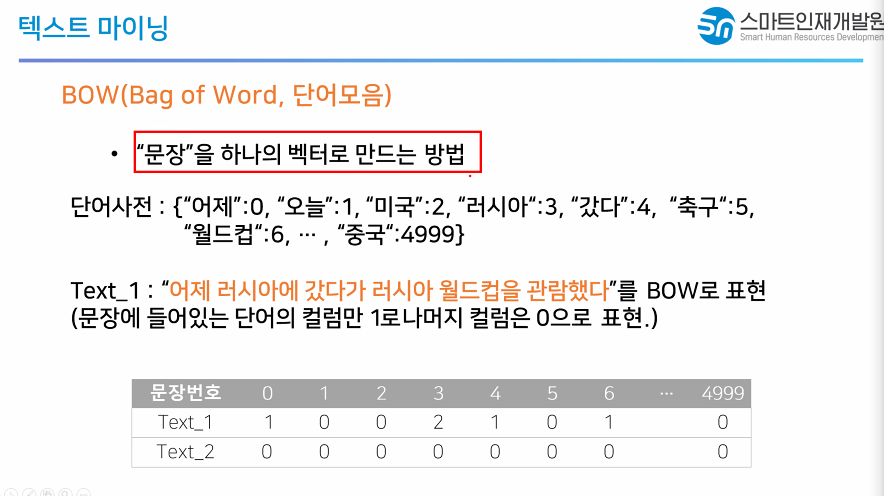
어제라는 단어는 0번 1개 있으므로 1 러시아는 2
갔다는 4번에 1 이런식으로 단어사전에서 해당 단어가 나왔는지 빈도수를 기반으로 체크한다.
1조금중요 2많이 중요하다고 생각할 가능성이있다
무조건 많이 나온게 무조건 중요하다는것은 아님
따라서 tfidf라는 방법을 써서 많이 나올수록 중요하긴하지만 무조건 중요한건아니다
여러문서에서 나오면 안중요하다
바나나라는 책이있고 딸기라는 책이있고 사과라는 책이 있을때
책마다 나오는 단어들이 조금씩 다르다

책에 들어간 단어의 빈도수
말뭉치(문서들의 합)를 모아놓으면
과일 15
노랑 3
빨강 9
바나나 4
딸기 6
사과 5
- BOW방법론에서는 가장 빈도가 높은 과일이라는 단어가 중요하다
- TFIDF 방법론
- 많이 나왔는가 > 각 문서에서 발생한 빈도
- 문서에서 단어가 발생한 빈도 > 전체문서중에서 해당 단어가 들어가있는 문서의 수 > 역수를 사용 > 적은 문서에서 발견될수록 가치있는 정보다.
- 1번값과 2번값을 곱해서 큰 수가 나올수록 중요한 단어
과일은 전체 3개 문서중에서 3개 다 들어갔다 3/3 = 1
노랑은 1/3 = 0.33 > 3/1 = 3(역수)
바나나는 1/3 = 0.33 > 3/1 = 3(역수)
과일 : 5/18 3/3 = 10/36 = 0.33
빨강 : 7/18 3/2 = 21/36 = 0.6
딸기 : 6/18 * 3/1 = 36/36 = 1

머신러닝 정리(반드시 기억할 것)
1. 머신러닝 순서(7단계)
1) 문제정의
- 인공지능으로 어떤 기능을 제작하려하는지 최대한 자세하게
2) 데이터 수집 > 시간 가장 많이 소요
- 사이트에서 다운로드 받기(AI HUB, KAGGLE, GOOGLE DATASETS, ROBOFLOW)
- 직접 수집할 땐 최대한 많이(정확한 예측) 최대한 다양하게(깊은 분석)
3) 데이터 전처리
- 결측치 여부
- 이상치 여부
4)탐색적 데이터 분석 > 많이 생략되는편
- 도표, 통계치, 그래프 등을 사용해서 데이터 자세하게 바라보기
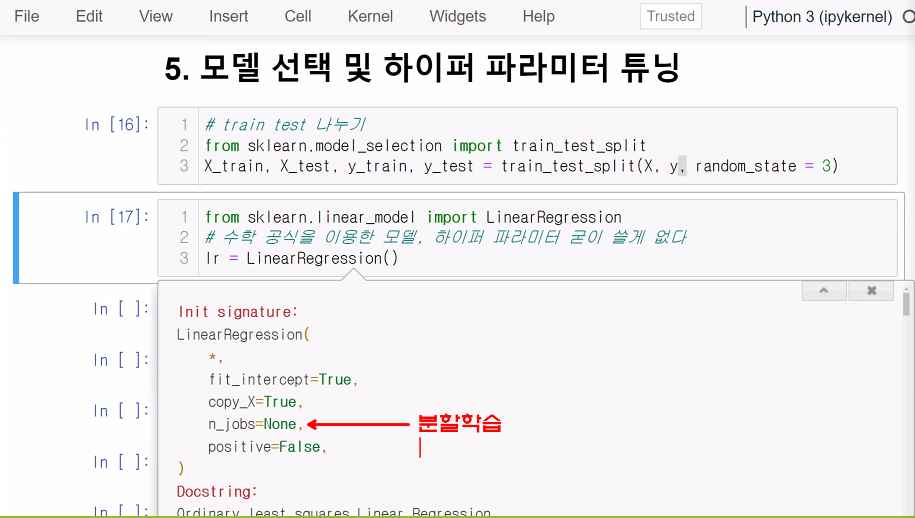
5) 모델 선택 및 하이퍼 파라미터 튜닝
- 목적, 데이터에 따라 적합한 모델 사용
- 모델의 세부적인 것들을 변경해주면 원활한 학습 가능
6) 학습 > 70시간
- 모델에 데이터를 주고 규칙을 찾게한다
7) 예측 및 평가
- 새로운 데이터를 모델에 줬을때 올바른 값을 출력하는가
- 새로운 데이터를 모델에 줬을 때 정확하게 값을 출력하는가
모든 데이터분석은 이 순서를 기반으로 흘러간다.
자격증 시험에도 이 내용이 많이 나온다.
암기해라
2. 분류 평가지표(0~1 사이의 값으로 존재, 1일수록 좋음)
1) 정확도(Accuracy)
- 전체중에 정확히 맞춘 비율
- 정확도만으로는 모델의 성능을 믿기 힘들다
2) 재현율(Recall)
- 실제 양성중에서 예측한 양성의 비율
- 애매한것을 사용한다. > 도둑 판별기
3) 정밀도(Precision)
- 예측 양성중에서 실제 양성의 비율
- 애매한것을 사용하지않는다. > 안전한 동영상 판별기
4) F1 Score
- 정밀도와 재현율의 조화평균
- 값이 높으면 애매한게 없다.
5) ROC Curve
- 진짜 양성 비율중 거짓 양성 비율
3. 회귀 평가지표
1) MSE(Mean Squared Error, 평균제곱오차)
- 오차의 값이 0 ~ 무한대
- 1000이라는 오차가 나왔다라고 했을때 정확한 판단이 불가
- 큰 오차는 더욱 크게 표현, 작은 오차는 더 작게 표현
2) RMSE, MAE, MAPE
- RMSE : 평균제곱근 오차, 값이 작을때 사용
- MAE : 평균 절대 오차, 값이 작을때 사용, 특이값이 많을때
- MAPE : 평균 절대 비율 오차, 직관적으로 값을 보고싶을때
3) R2 Score = R squared
- E로 끝나는 회귀평가지표들은 0~무한대의 범위 > 한눈에 파악하기 힘들다
- R2 Score는 0~1까지로 변경 > 정확도처럼 사용 가능
- 코드에서 보는 평가지표
4. 경사하강법
- 점진적으로 최적의 값을 찾아가는 방법
- 오차가 작아지는 방향으로 이동시키는 방법
- 방향의 문제 : 어떤 방향으로 이동할 것인가
- 보폭의 문제 : 한번에 얼마만큼 이동할것인가
5. 일반화, 과대적합, 과소적합
- 일반화 : 모델이 학습이 잘되었다 = 일반화가 잘됐다 > 새롭게 들어오는 데이터를 예측 잘한다
- 과대적합 : 학습데이터에 과하게 학습해서 학습데이터는 잘 맞추지만 그 외 데이터는 잘 못맞추는 현상
train accuracy : 0.9, test accuracy : 0.75 > 과대적합
- 과소적합 : 학습데이터를 조금만 학습해서 학습데이터도 못맞추고 그 외 데이터도 못맞추는 현상
* 기억해두면 좋을 것들
1. L1규제, L2규제
1) L1규제 : 모든 가중치에 똑같은 힘으로 규제를 적용
특정 가중치는 0이된다 > 사용되지 않는다
사용되는 가중치와 사용되지않는 가중치가 나뉨
특성선택이 자동으로 이루어짐 > 특정 데이터가 중요할 때 사용
2) L2규제 : 모든 가중치에 똑같은 비율로 규제를 적용
모든 가중치는 0이되지않는다
모든 가중치를 사용
모든 데이터가 고르게 중요할 때 사용 > 일반적으로 많이 사용
프로젝트를 사용할 때 사용하는 모델들과는 동떨어짐. 개념이 중요하나 성능이 좋지는않음
2. 다양한 모델들
1) KNN(K Nearest Neighbors)
- 가까운 이웃이 가지고있는 값을 활용해서 예측
- 데이터가 군집을 이룰때, 예측시간이 빨라야할 때
2) Decision Tree
- 스무고개, 아키네이터
- 데이터가 사각형일때, 특성선택을 해야할 때
3) Ensemble 계열의 모델
-Bagging방법 : RandomForest 모델
- Boosting방법: 여러개의 모델을 연결해서 사용
AdaBoost, XGBoost, GBM, LGBML
- 학습과 예측의 속도가 느림
- 머신러닝 모델중에서는 보통 가장 좋은 결과
4) 선형 회귀모델
- 데이터를 최대한 잘 설명할 수 있는 선 찾기
-
3. 교차검증
4. Pandas, Numpy
5. 빅데이터분석기사 한정 암기해야한다
스펠링 탭은 쓸 수있다정도는 되야한다(코드 칠수 있는 정도)
(iris, boston 데이터셋 활용 데이터 분석 코드)
* 들어봤다
1. Encoding(Label encoding, One-hot encoding)
2. Scaling
3. GridSearch
4. Bow, TFIDF
