stored procedure(스토어드 프로시저)
: stored function과 유사함.
사용자가 정의한 프로시저이며 RDBMS에 저장되고 사용됨.
구체적인 하나의 task를 수행함.
조건문을 통해 분기처리를 하거나 반복문을 수행하거나 에러를 핸들링하는 다양한 로직을 정의할 수 있다.
예제
두 정수의 곱셈 결과를 가져오는 프로시저 작성
delimiter $$
CREATE PROCEDURE product(IN a int, IN b int, OUT result int)
//input 파라미터인 a와 b는 IN으로 작성, output인 result는 OUT
//주의!! 적지 않으면 default값인 IN으로 모두 인식됨.
BEGIN
SET result = a * b; //SET 키워드 사용
END
$$
delimiter ;
실행
call product(5,7,@result);
select @result;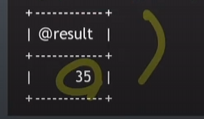
두 정수를 맞바꾸는 프로시저 작성
delimiter $$
CREATE PROCEDURE swap(INOUT a int, INOUT b int)
//INOUT은 파라미터의 값으로 정의할 수도 있고 동시에 반환값을 저장
BEGIN
set @temp = a; //변수 temp를 만들어 a의 값을 임시 저장
set a = b; //b의 값을 a에 저장
set b = @temp; //temp에 저장돼있던 a의 값을 b에 저장
END
$$
delimiter ;
실행
set @a = 5, @b = 7;
call swap(@a, @b);
select @a, @b;
서로 바뀐 결과 확인
사용자가 프로필 닉네임을 바꾸면 이전 닉네임을 로그에 저장하고
새 닉네임으로 업데이트하는 프로시저 작성
delimiter $$
CREATE PROCEDURE change_nickname(user_id INT, new_nick varchar(30))
//IN을 명시하지 않아도 기본값이 IN이 됨
BEGIN
insert into nickname_logs( //기존의 닉넴 정보를 저장해야돼서 insert
//기존의 닉넴 정보 가져오기
select id, nickname, now() //업데이트되는시간
from users
where id = user_id
);
update users set nickname = new_nick
where id = user_id;
END
$$
delimiter ;
call change_nickname(1,'ZIDANE');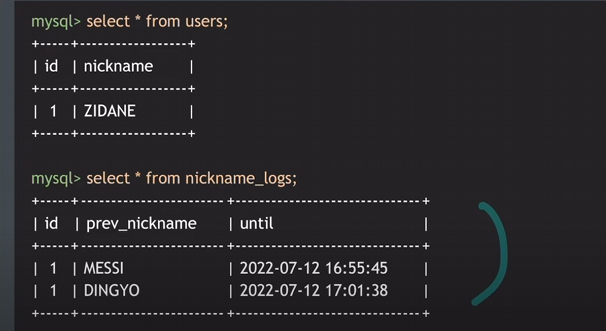
stored procedure과 stored function의 차이

- 파라미터로 값을 반환하는 Procedure와 return 키워드로 값을 반환하는 FUNCTION 예시


- SQL statement에서 호출하는 예시

stored procedure 장점
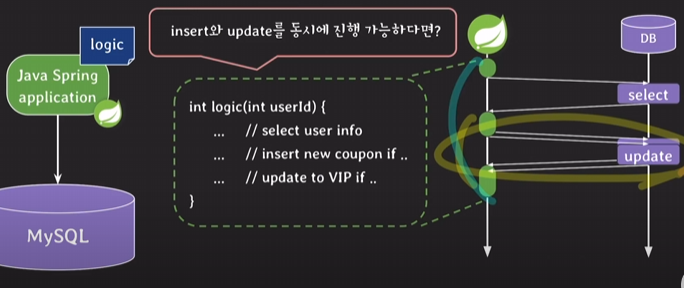
- application에 transparent하게(변경 전의 부분을 바꾸지 않고도 내용을 바꿀 수 있는 것) 동작할 수 있다.
로직 tier와 데이터 tier에서 비즈니스 로직을 바꿔줄 때 순차적으로(일괄적으로 하면 해당 서비스는 트래픽을 받고 있기 때문에 바꿔주는 동안 트래픽을 처리하지 못함)해야하기 때문에 바꿔줄 때마다 컴파일 새로 하고, 빌드해서, 배포 파일 만든 뒤에, 하나하나 새로운 인스턴스로 시작해줘야한다.
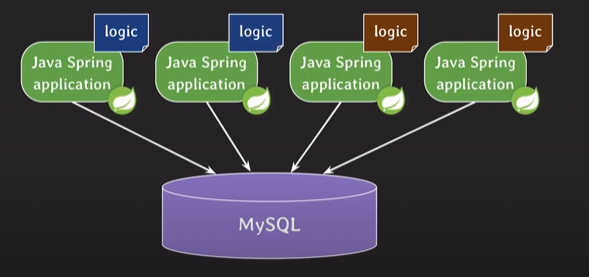
위의 번거로움을 개선하기 위해 비즈니스 로직을 stored procedure로 관리한다면
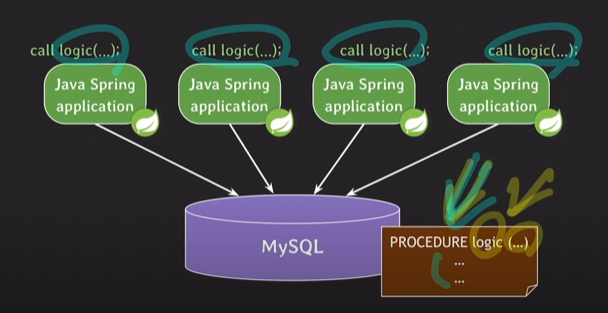
로직티어에서 프로시저만 호출하여 프로시저의 body부분만을 수정하여 간단하게 변경할 수 있다.
- network traffic을 줄여 응답 속도를 향상시킴
비즈니스 로직이 로직 tire(=비즈니스 어플리케이션 ex.자바스프링) 서버에 있을 때는 로직 안에 여러 개의 SQL문을 수행할 때마다 network traffic 발생
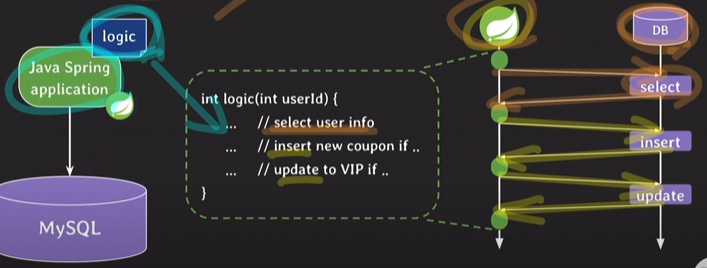
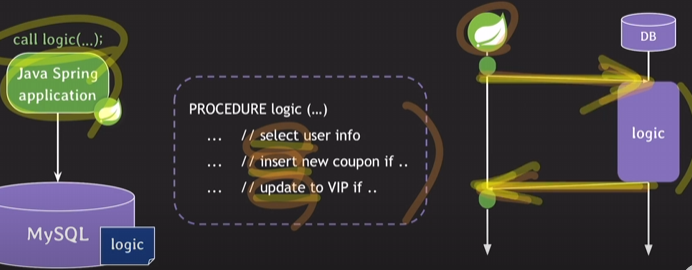
위처럼 하지 않고 비즈니스 로직이 RDBMS에 있고 프로시저 안에 SQL문들이 있으면 웹 어플리케이션에서 프로시저를 호출만 하고 프로시저 안의 SQL이 수행되면서 최종적으로 한 번만 응답을 주게 됨
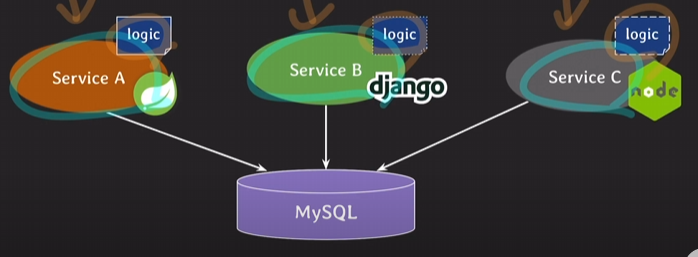
- 여러 서비스에서 재사용 가능
같은 DB에 대해서 여러 서비스가 사용할 때 같은 로직을 써야한다면 각각 java, python, js로 같은 로직을 구현해야한다.
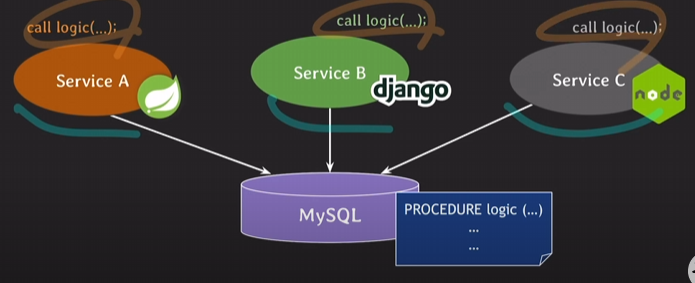
위처럼 하지 않고 비즈니스 로직을 프로시저를 통해 RBDMS에 저장을 해놓고 사용하게 되면 각각의 서비스는 해당 로직을 호출만 해주면 됨
- 민감한 정보에 대한 직접 접근을 제한할 수 있다
개발자나 임직원이 고객의 주민번호나 신용카드 정보에 대한 직접적인 접근을 막고 프로시저를 통해 DB에 접근하도록 한다.

하지만 의도적으로 정보를 빼내오는 의지로 덤빈다면 return값으로 정보를 주면 빼내올 수 있어서 접근을 완벽하게 제한하는 건 아님
stored procedure 단점과 실무에서의 적은 활용도
- 유지 관리 보수 비용이 커짐
로직의 소스코드를 봤다가 프로시저 코드를 봤다가 왔다갔다 해야하며 버전 관리를 로직과 프로시저 둘 다 해줘야한다. 또한 개발자가 프로시저 관련 문법을 알아야하는 비용도 든다
- DB 서버를 추가하는 것은 간단한 작업이 아님
비즈니스 로직을 프로시저를 통해 RDBMS에 두게 되면 DB서버에 CPU 사용량과 메모리 사용량이 급증하기 때문에 traffic이 갑자기 몰리게 되면 긴급하게 대응을 해야하지만 DB에 있는 데이터를 새 RBDMS에 복제해야돼서 그러지 못함
- stored procedure가 언제나 tranparent인 건 아니다
기존의 A프로시저를 놔두고 프로시저명을 B로 바꾸고 싶은 프로시저를 새로 생성해서 로직의 소스 코드에서 B프로시저를 호출할 수 있도록 코드를 바꾸고 웹 애플리케이션의 서버 하나하나를 다시 재시작하고 나서 기존의 A프로시저를 삭제해야한다.
- trasparent하다고 무조건 좋은 것도 아님
RBDMS에 위치한 프로시저 로직이 버그가 있었다면 버그가 있었던 동안의 트래픽들은 버그가 있는 로직을 사용했던 것임
- 비즈니스 로직을 소스 코드에 두고도 응답 속도를 향상시킬 수 있다
- 쓰레드풀을 사용하든가 NonBlock I/O를 사용해서 동시에 DB서버로 요청을 보내 응답시간을 줄임
- Cache(캐시)를 써서
getFromCache(id)란 코드는getPoint(int id)란 로직이 파라미터로 id값을 받으면 그 아이디에 대한 포인트가 캐시에 있는지 확인한다.
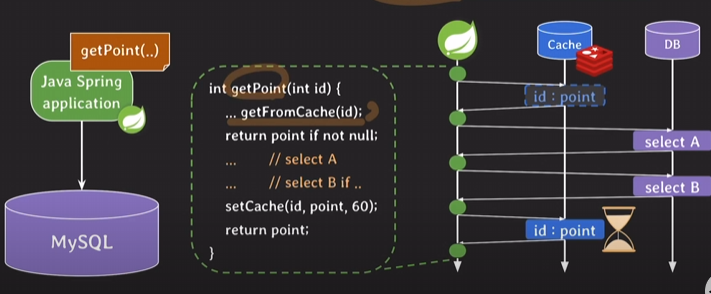
당연히 맨 초기에는 캐시에 아무것도 없으므로 이후 로직이 실행되어 select가 두 번 실행된다.
그 결과를 바탕으로 포인트 계산을 한 뒤에 그 포인트를 캐시에 키-값 형태로 넣어주고 그 값을 얼마동안 저장할 건지 쓰고(여기선 60초) point값을 리턴해준다
이렇게 되면 같은 아이디에 대해서 getPoint(int id)를 호출하게 되면 일차적으로 캐시를 확인하고 캐시에 포인트가 있으면 바로 return함
따라서 아이디에 대한 포인트 정보가 캐시에 있는 동안에는 응답속도가 빨라지고 DB의 부하도 줄일 수 있는 장점이 있음
따라서 Cache가 실무에 굉장히 많이 쓰임
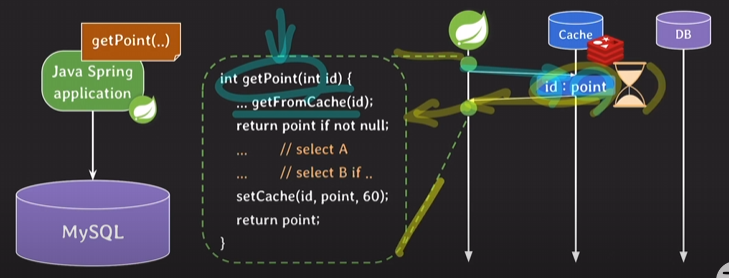
출처: https://www.youtube.com/watch?v=m2jx18yg8EA&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=11
