Index를 쓰는 이유
조건을 만족하는 튜플들을 빠르게 조회하기 위해
상황에 따라서 빠르게 정렬하거나 그룹핑을 하기 위해 쓰기도 함.
-
이미 사용하고 있는 테이블에 index 걸기
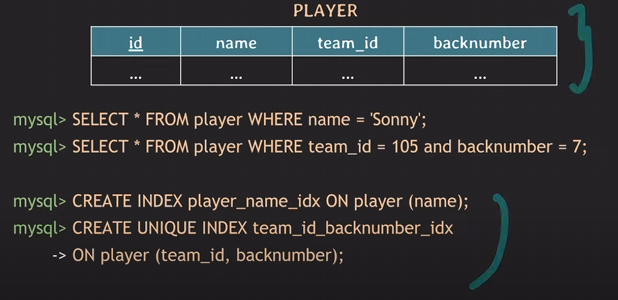
중복을 허용하는 index는 그냥INDEX라 적고 만들어주면 됨.
튜플들을 UNIQUE하게 식별할 수 있는 attribute를 index 걸어줄 때UNIQUE INDEX라고 적음.
-
테이블 생성시 index 걸기
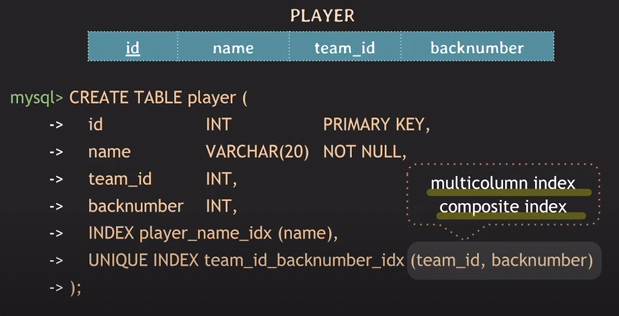
2개 이상의 attribute로 구성된 인덱스를 multicolumn index 혹은 composite index라고 함.
또한 PRIMARY KEY에는 index가 자동 생성되므로 명시해주지 않아도 됨.
-
테이블에 어떤 index들이 걸려있는지 확인하기
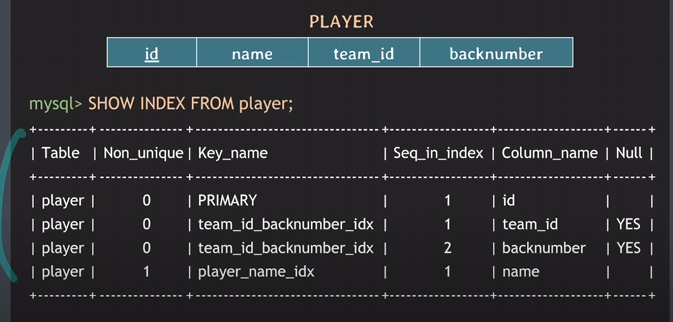
Key_name이 곧 Index name임.
중복된 Key_name은 Seq_in_index(시퀀스인인덱스)를 보면 번호가 순차적으로 매겨져있는 걸 볼 수 있음. 즉, multicolumn index임을 알 수 있음!
multicolumn index가 어떤 attribute로 이루어져있는지 확인하려면 Column_name을 통해 확인할 수 있음.
B-tree 기반의 index가 동작하는 방식
사용되는 query에 맞춰서 적절하게 index를 걸어줘야 query가 빠르게 처리될 수 있다
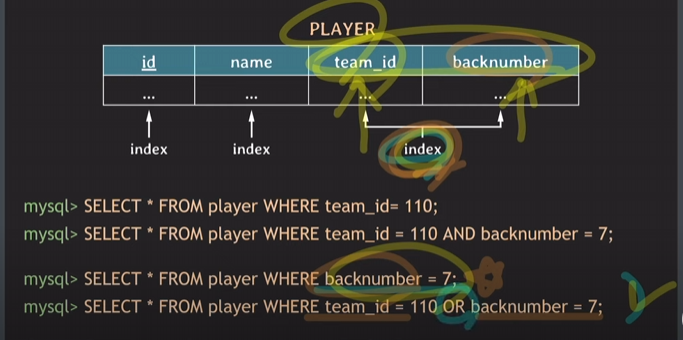
team_id의 인덱스를 먼저 적어줬기 때문에 team_id를 기준으로 backnumber(순차적으로 정렬x)를 찾기때문에 full scan인 상황이 될 수 있어서 backnumber만을 인덱스로 찾기는 어려움.
따라서 밑의 두 쿼리문은 위의 인덱스 상황만으로는 좋은 성능으로 빠르게 조회할 수 없음.
추가적으로 backnumber에 대한 index를 걸어줘야만함.
- RDBMS가 올바른 index를 사용하여 조회하는지 설정하기
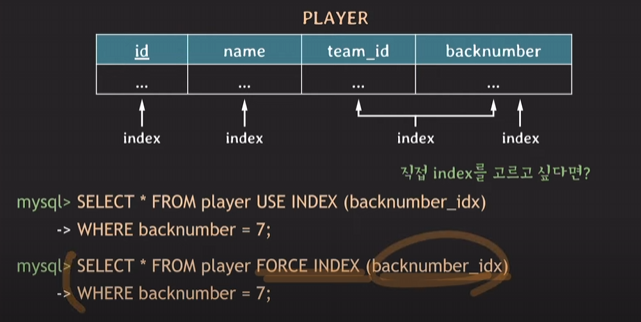
기본적으로 optimizer가 알아서 잘 찾아 조회하지만, 간혹 올바르게 찾지 못 했을 경우
USE INDEX(backnumber_idx)를 이용하여 '가급적 backnumber_idx를 써라'라는 명령을 줄 수 있지만 backnumber_idx를 쓰지 않으면 full scan으로 동작하기 때문에
더 강력한 명령어는
FORCE INDEX(backnumber_idx)를 이용하여 'backnumber_idx를 무조건 이용하여 조회해라'라는 뜻.
그렇다면 특정 인덱스를 제외하고 싶다면?
IGNORE INDEX(제외할 인덱스명)- 불필요한 인덱스는 생성하지 않아야 함.
왜?
-table에 write할 때마다 index도 변경되기 때문에 인덱스가 많을 수록 오버헤드가 발생할 수 있음
-인덱스에 대한 데이터를 저장해야하기 때문에 추가적인 저장 공간이 필요해짐
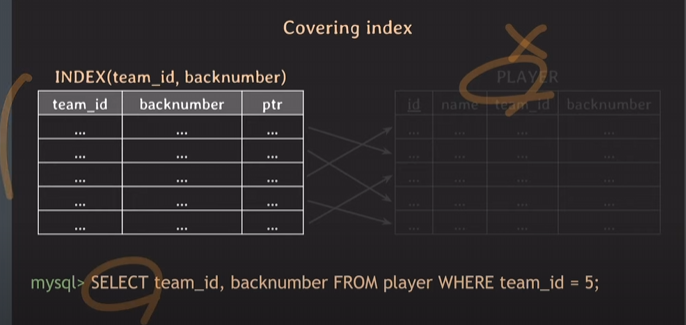
Covering index
조회하는 attribute(s)를 index가 모두 cover할 수 있을 때
조회 성능이 더 빠름
왜? 굳이 실제 table까지 가는 경우는 없으니까.
Hash index
hash table을 사용하여 index 구현
잘 사용 안 함
-
장점 : 시간복잡도 O(1)의 성능이기 때문에 조회가 굉장히 빠른 속도.
-
단점 :
-
hash table로 구현이 되어있어서 array를 활용하여 저장되는데 데이터가 어느정도 쌓이면 더 큰 데이터 사이즈로 바꿔줘야함(=rehasing)의 부담이 있음.

-
범위를 비교하는 조건으로 사용 불가능
=, =!의 equality 비교는 가능하지만<=, >와 같은 range의 비교는 불가 -
multicolumn index의 경우 전체 attributes에 대한 조회만 가능
ex) (a,b)의 인덱스를 만들었을 때 B-tree 기반의 index였다면 a로만 조회를 하고 싶을 때 index 조회가 가능했지만, hash index는 a와 b 모두 포함하는 조건이어야만 조회 가능.
출처 : https://www.youtube.com/watch?v=IMDH4iAQ6zM&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=25
