DDD의 Aggregate
Aggregate
DDD의 Aggregate는 객체들의 집합이다.
Aggregate 내부에는 단 하나의 전역 식별성을 가진 Root Entity가 존재하며 Aggregate를 대표한다.
그 밖에는 지역 식별성을 가진 Local Entity, 값과 그에 대한 행위를 캡슐화하는 Value Object가 있다.
풍부한 표현력을 가진 객체들로 소프트웨어를 구성하기 위해서는 Aggregate가 충분히 커야한다.
도메인에 맞게 설계된 Aggregate는 소프트웨어를 간결하게 만들고 표현력을 높인다. 반대로 잘못 설계되면 소프트웨어를 불필요하게 복잡하게 만들고 모델의 표현력을 잃게 한다. 성능에도 좋지 않은 영향을 미친다.
어떤 기준을 가지고 Aggregate를 설계해야 하는지 알아보자.
이 글에서는 1:1 혹은 1:N 관계를 가진 객체들을 1개의 Aggregate로 통합하거나 2개의 Aggregate로 분리하는 예시를 들어 설명한다. 이를 데이터 베이스에서는 관점 정규화나 비정규화로 볼 수있지만, 그 보다는 DDD에서 말하는 풍부한 표현력을 갖춘 도메인 객체를 만들기 위한 방법을 말하고자 한다.
Aggregate의 구성 요소들이 각각 어떤 역할을 맡고 어떤 형태를 가져야 하는지는 이 글에서 다루지 않는다.
세가지 기준
기본적으로 Aggregate는 가능한 적을수록 좋다. 소프트웨어가 간결해지고 모델 표현할 수 있는 영역을 넓혀주기 때문이다.
가능하면 적은 수의 Aggregate로 설계하자. Aggregate를 분리 할 때는 그에 맞는 이유가 있어야한다.
아래 세가지 기준을 통해 Aggregate를 분리하거나 통합해야 하는 이유를 말해보려 한다.
- 생명주기 (통합 혹은 분리)
- 경합 (분리)
- 불변식 (통합)
생명 주기
생명주기는 Aggregate가 처음 생성되서 완전히 소멸하기까지의 기간이나 과정을 나타낸다. 생명주기가 비슷하다면 통합하고 다르다면 분리하는게 좋다.
그림 출처: 도메인 주도 개발(에릭 에반스)
통합
두 Entity가 있을때, 어떤 Entity의 생명주기가 다른 Entity의 생명주기에 포함된다면 두 Entity를 하나로 만드는게 좋다.
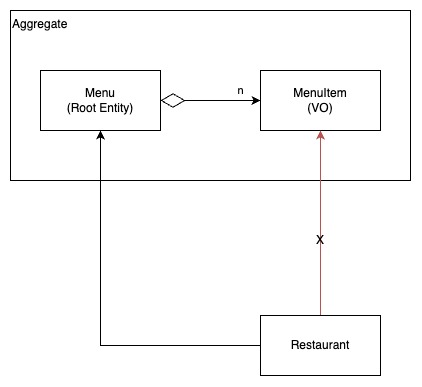
아래 예시를 살펴보자.
Menu는 여러개의 MenuItem으로 이루어진다.
class Menu {
String id;
...
}
class MenuItem {
String id;
String menuId;
String name;
...
}
이 설계에서는 Menu와 MenuItem이 서로 다른 Root Entity로 각각 Aggregate를 이룬다.
Menu에 MenuItem을 추가하는 간단한 유즈케이스의 구현을 살펴보자.
class MenuService {
...
void addMenuItem(String menuId, String menuItemName, ...) {
Menu menu = menuRepository.findById(menuId);
if(menu == null) {
// 예외 처리
}
MenuItem item = new MenuItem(menuItemName, ...);
item.setMenuId(menuId);
menuItemRepository.save(item);
}
}
사전에 생성되어 있는 Menu를 조회하여 확인하고, Menu를 가리키는 MenuItem을 생성함으로서 Menu에 MenuItem을 추가한다.
이번에는 다른 설계를 살펴보자.
class Menu {
String id;
List<MenuItem> items;
}
class MenuItem {
String name;
...
}MenuItem은 더이상 Entity가 아니며 Menu에 속하는 VO(Value Object)이다. (List의 순서를 활용한다면 Local Entity로 볼 수 있다.)
이번에도 Menu에 MenuItem을 추가하는 간단한 유즈케이스의 구현을 살펴보자.
class Menu {
...
void addMenuItem(MenuItem item) {
items.add(item);
}
}
class MenuService {
...
// DTO를 통해 item의 정보를 입력받아 생성했다고 가정.
void addMenuItem(String menuId, String menuItemName, ...) {
Menu menu = menuRepository.findById(menuId);
if(menu == null) {
// 예외 처리
}
MenuItem item = new MenuItem(menuItemName, ...);
menu.addMenuItem(item);
menuRepository.save(menu);
}
}
위의 유즈케이스에는 MenuItem이 전역식별성을 가질 필요가 없으며 MenuItem의 생명주기는 Menu의 생명주기에 포함된다.
이 때는 MenuItem이 Menu와 통합되는 것이 좋다.
첫 번째 설계와 두 번째 설계의 차이점이 뭘까?
간단한 유즈 케이스의 구현이기 때문에 차이는 크지 않아 보이지만 첫 번째 구현은 두번째 구현보다 복잡하다. 그 이유는 아래와 같다.
-
소유 관계 표현
첫 번째 구현에서는 id 참조로 소유 관계를 표현해야 한다. 이는 모델에 직접 데이터가 포함되는 2번째 구현에 비해 복잡할 수 밖에 없다.
이런 경우, 연관 관계의 주인을 MenuItem로 해야 하는데(이는 잘 알려진 문제이다), 이는 직관에 어긋나며 상당히 복잡한 문제들을 낳는다. 가령, Menu를 삭제할 때 Menu에 포함되는 MenuItem도 찾아서 지워줘야 쓰레기 데이터를 남기지 않을 수 있다. -
모델의 표현력
더 중요한 차이점은 Menu에 MenuItem을 추가하는 로직의 위치이다. ("items.add(item);"의 위치)
첫 번째 구현에서는 모델 밖에 존재하던 부분이 두 번째 구현에서는 모델에 표현될 수 있었다. 데이터와 데이터에 대한 행위를 객체로 추상화, 캡슐화하여 표현하는 것은 객체지향의 기본이다. 위 예제에서는 단순히 한줄로 끝났지만 유즈케이스가 복잡할 수록 이 차이는 커질 것이다. 빈약한 모델과 비대해진 Service는 쉽게 찾아볼 수 있다.
(잘 납득이 되지 않아 더 실질적인 예를 찾는다면, 추후에 나오는 불변식 부분을 참고하자.)
위와 같은 이유로 두 Aggregate가 비슷한 생명주기를 가진다면 하나의 Aggregate로 설계하는 것을 고려해보자.
분리
이번에는, 생명주기가 다를 때를 살펴보자.
생명주기가 다를 때는 Aggregate를 분리하는게 좋다. 아래 간단한 예제를 보자.
class Owner {
String id;
...
}
class House {
String id;
String ownerId;
...
}
House는 Owner가 사라진 뒤에도 존재해야한다. House를 Owner의 VO로 만든다면, Owner가 삭제될 때 House도 같이 삭제될 위험이 있다.
생명 주기가 명백히 다를 때에는 Aggregate를 나눠야하는 이유가 된다.
경합
분리
생명주기가 같더라도 경합이 빈번한 경우에는 Aggregate를 분리하여 설계해아 할 수도 있다. 아래 예시를 살펴보자.
기차(Train)와 좌석(Seat)이 있다. 명절에는 유저가 좌석을 차지하기위해 치열히 경합한다.
Train은 Root Entity, Seat은 VO로 설계되면 과도한 경합문제를 맞이할 수 있다.
class Train {
String id;
List<Seat> seats
}
class Seat {
String reservedUserId;
...
}
위의 설계에서 Seat을 수정하기 위해서는 Train 전체를 수정해야한다. 아래의 경우를 생각해보자.
User에 의해 Train의 Seat이 예약될 때, Seat의 reservedUserId가 예약하는 User의 Id로 변경된다고 해보자.
시스템은 기존에 이뤄진 예약을 보장해야 하기 때문에 이미 예약이 이뤄진 Seat에 대한 예약은 실패로 만들어야한다.
Seat을 수정하기 위해선 Train을 수정해야한다. 따라서 시스템은 Train에 대해 잠금 기법을 사용하여 Seat이 비어 있을 때에만 예약을 처리 해야할 것이다.
이 경우엔 서로 다른 User가 경합을 피할 수 있는 상황에서도 Train을 두고 경합해야한다.
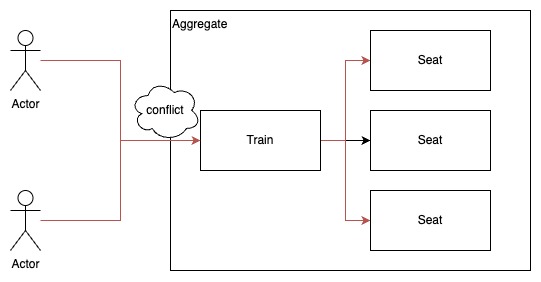
User A는 10번 Seat, User B가 15번 Seat을 예약하려는 상황에서도 두 User는 전체 Train을 두고 경합 해야한다.
이는 성능 문제를 야기하고 때로는 더 큰 문제가 발생할 수도 있다. 따라서 경합 상태가 잦은 경우에는 Entity를 분리하는 것이 좋다.
class Train {
String id;
...
}
class Seat {
String id;
String trainId;
...
}
Train과 Seat을 각각의 Root Entity로 설계하면 앞서 말한 경합 문제는 사라진다.
서로 다른 Seat을 예약하려는 User는 경합하지 않아도 된다.
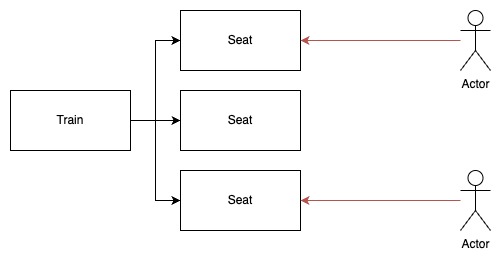
현대의 인터넷 환경의 소프트웨어는 경합 상태에 놓이기 쉽다. 그런 이유 때문인지 Aggregate를 잘게 나누는 관습이 퍼져있는 것 같다. 도메인에 적합한 설계인지 되돌아보자.
불변식
통합
데이터가 변경될 때마다 유지되야 하는 일관성 규칙을 불변식이라고 한다. 불변식이 지켜지지 못하면 예기치 못한 버그가 생겨날 것이다.
서로 다른 Aggregate 사이의 불변식이 지켜지도록 하는것은 어려운 일이다. 불변식이 복잡하다면 더더욱 어렵다.
(이를 구현하기 위해 복잡한 이벤트 처리, 배치등이 활용되곤 한다.)
이때는 하나의 Aggregate로 설계하는 것이 좋다. 아래와 같은 불변식을 생각해보자.
Truck에 싣을 수 있는 Package(택배)의 weight의 총합은 limit 이하여야 한다.
Truck, Package 이 다른 Aggregate 설계된 경우를 살펴 보자.
class Truck {
String id;
int limit;
...
}
class Package {
String id;
String truckId;
int weight;
...
}
Truck에 Package을 적재하는 간단한 유즈케이스의 구현을 살펴보자.
불변식을 확인하기 위해 Truck에 포함된 모든 Pacakge를 추가로 조회해야한다.
이는 모델에서 표현되기 적합하지 않아 Service에 위치할 것이다.
class TruckService {
...
void loadPackage(String truckId, String weight, ...) {
Truck truck = truckRepository.findById(truckId);
if(truck == null) {
// 예외 처리
}
// 불변식
List<Package> loadedPackage = packageRepository.findAllByTruckId(truck.getId());
int loadedWeight = loadedPackage.stream().~.sum()
if(truck.limit < loadedWeight + weight) {
// 예외 처리
}
Package package = new Package(weight, ...);
package.setTruckId(truckId);
packageRepository.save(package);
}
}
이번에는 하나의 Aggregate로 설계된 경우를 보자.
Package는 Truck의 VO이다.
class Truck {
String id;
int limit;
List<Package> packages;
...
}
class Package {
int weight;
...
}이 설계에서 Truck에 Package을 적재하는 유즈케이스의 구현을 살펴보자.
이 설계에서는 모델 내부에 불변식을 간단하게 표현할 수 있다.
class Truck {
...
void addPackage(Package package) {
int currentWeight = packages.stream().~.sum();
if(limit < currentWeight + package.weight) {
// 예외 처리
}
}
}
class TruckService {
...
void loadPackage(String truckId, String weight, ...) {
Truck truck = truckRepository.findById(truckId);
if(truck == null) {
// 예외 처리
}
Package package = new Package(weight, ...);
truck.addPackage(package);
truckRepository.save(truck);
}
}생명 주기의 예와 비슷하지만 불변식이 추가 되었다.
첫 번째 구현에서 불변식은 모델에서 표현되기 적합하지 않아 Service에 위치한다.
불변식을 확인하기 위해 조회를 한번 더 해야한다. 타이밍 문제가 발생한다면 불변식이 깨질 가능성도 있다.
그에 비해 두 번째 구현은 매우 간단하고 모델의 표현력이 풍부하다.
불변식을 바로 확인할 수 있다. 타이밍 문제가 발생하더라도 덮어 쓰기 문제는 발생하겠지만 불변식은 깨지지 않을 것이다.
메모리에 존재하는 객체는 항상 불변식을 지킬 것이다. 불변식이 좀더 완전성 갖췄다고 볼 수도 있다.
두 번째 구현에서 Service는 한결 가벼워 졌으며 불변식을 포함하는 모델은 좀 더 풍부해 졌다고 볼 수 있다.
위와 같은 이유로 불변식이 복잡할 수록 하나의 Entity로 설계하는 것이 바람직 할것이다.
DDD
항상 설계는 도메인과 Usecase에 따라 많은 고민이 따라야 한다고 생각한다.
경합 상태를 우려해서 Aggregate를 미리 나누는 것은 소프트웨어의 간결성과 모델의 표현력을 포기하는 일임을 알아야 한다.
왜 현업에서는 풍부한 모델을 만들지 못할까 고민하다가 Aggregate를 잘게 나누는 관습이 하나의 큰 이유가 아닐까하는 생각이 들어 글을 썻다.
물론 항상 Aggregate를 최대한 크게, 적은 수로 만드는게 정답은 아니지만.. 잘게 나누었을 때 모델의 표현력이 떨어지는 현상은 많이 경험했다.
Usecase에 따라 Aggregate을 적절히 설계하는 것이 객체 지향을 향하는 첫걸음이 아닐까한다.
TMI
-
이 글의 예제는 트랜잭션이나 JPA 같은 기술들이 해결해 줄수 있지만 완전하지 않고 또 다른 문제가 발생한다고 생각한다.
-
처음으로 기술 관련 글을 쓰는데 너무 힘들었다.글을 쓰다가 관련 책의 내용을 확인하면 책에 훨신 더 정밀하고 좋은 표현들이 가득했기 때문에.. 글을 쓸 의욕이 없어지곤 했다. (에릭 에반스의 DDD가 거의 성경이다.)
-
예제가 적절하지 않을수도 있고, 표현이 부정확할수도 있다. 영어를 못한다.. 더 고치고 싶지만 이제 그만..
-
벨로그에서 글을 몇번이나 날려먹어서 중간에 때려칠뻔 했다.. 멘붕..
