❗해당 포스트는 글쓴이의 지식을 쌓고 정리하기 위해 작성되었으며, 다른 블로그 혹은 논문을 보고 작성하였습니다. 참고한 블로그 주소나 논문의 경우 포스트의 맨 아래에 링크를 남겨놓았습니다.
📣 Missing Value 개요
설문 조사와 같은 다양한 조사를 통해 얻은 Data에는 누락된 값 혹은 결측치(Missing Value)를 포함할 수 있다. 누락된 값은 보통 None, NaN, - 등으로 표시되는 경우가 많고, 이런 Missing Value를 아무런 처리 없이 Machine Learning, Deep Learning 등의 학습 데이터로 사용하면 모델의 정확성이 떨어질 수 있고, 예측하지 못했던 많은 오류들이 생겨날 수 있다. 그래서 Missing Value를 어떻게 처리할 수 있는지 그 방법들에 대해 소개할 것이다.
📚 Missing Value의 Type
우선, Missing Value의 Type에는 3가지가 있다.
1. Missing Completely At Random (MCAR)
👉 어떤 변수에 있는 결측치(Missing Value)가 다른 변수들과는 아무 상관이 없는 경우를 말한다.
👉 이 결측치의 경우, 보통 제거하는 방식이나 Data에서 단순 무작위 표본 추출을 통해 완벽한 Data Set을 만들 수 있다.
✳️ 데이터를 깜박하고 입력을 안하거나 전산 오류로 누락된 경우들이 이에 해당한다.
2. Missing At Random (MAR)
👉 결측치를 포함하고 있는 변수와는 관련이 없으나 다른 변수들과 관련이 있는 경우를 말한다.
✳️ 여성이 남성보다 체중을 기입하지 않는다고 한다면 체중이라는 변수에 결측치가 발생하지만 이는 체중 변수와는 관련이 없고 성별 변수와 관련이 있다고 볼 수 있다.
3. Missing Not At Random (MNAR)
👉 1번과 2번 유형이 아닌 경우를 말하는데, 결측치를 포함하고 있는 변수 자체와 관련이 있는 경우를 말한다.
✳️ 서비스에 불만족한 고객들이 만족도 설문에 응답하지 않는 경우가 이에 해당한다.
🔎 Missing Value 처리 방법
1. 그대로 두는 방법
👉 가장 쉬운 방법으로 알고리즘이 결측치를 처리하도록 두면 된다. XGBoost와 같은 알고리즘들의 경우 결측치를 고려하여 학습하고, LightGBM의 경우 Parameter로 결측치 처리 방식을 결정할 수 있다. 그러나 결측치를 따로 처리하는 부분이 없는 알고리즘들의 경우 미리 결측치를 처리해야 한다.
2. 결측치 데이터 제거
👉 결측치가 있는 데이터 부분을 제거하는 방식으로 중요한 정보를 가지고 있다면 데이터가 손실될 위험이 있다. 상황에 따라 결측치가 있는 Data의 Tuple 부분을 제거할 수도 있고, 결측치가 많은 Feature 자체를 제거할 수도 있다.
3. Mean / Median Imputation
👉 결측치가 있는 Feature 내에서 결측치가 아닌 나머지 값들(관찰된 값들)의 평균(Mean), 중앙값(Median)으로 결측치를 대체하는 방법이다. 다른 Feature는 고려하지 않으며, 숫자형(Numerical) Data에만 사용할 수 있다.
✨ 장점
- 간단하고 쉽게 적용할 수 있으며 빠른 처리가 가능
- 작은 크기의 숫자형 Data Set에 잘 동작함
🔥 단점
- 다른 Feature 간의 상관 관계를 고려하지 않고 단순히 결측치가 있는 Feature만 고려
- Categorical Feature에 대해서는 좋지 않은 결과를 제공
- 정확하지 않으며 이미 관찰된 범위 내의 값들로 결측치를 대체하는 것이기 때문에 불확실성에 반대됨
📖 예시 코드
import os
import pandas as pd
data = pd.read_csv(os.path.join(os.getcwd(), 'Data Path...'))
null_idx = data[data['Column 이름'].isnull()].index
notnull_idx = data[data['Column 이름'].notnull()].index
data['Column 이름'][null_idx] # 결측치 Data만 뽑아오기
data['Column 이름'][notnull_idx] # 관측치 Data만 뽑아오기
# 관측치 Data에서 평균값 계산 및 결측치 대체
meanImputation = data.fillna(data[data['Column 이름'].notnull()].mean())
meanImputation['Column 이름'][null_idx] # 대체된 결과 확인
# 관측치 Data에서 중앙값 계산 및 결측치 대체
medianImputation = data.fillna(data[data['Column 이름'].notnull()].median())
medianImputation['Column 이름'][null_idx] # 대체된 결과 확인4. Most Frequent Value / Zero / Constant Imputation
👉 관찰된 값들 중 가장 빈번하게 나온 값 혹은 0(Zero), 특정 상수(Constant)로 결측치를 대체하는 방법이다. 이 방법은 범주형(Categorical) Feature에도 적용할 수 있다.
✨ 장점
- 간단하고 쉽게 적용할 수 있으며 빠른 처리가 가능
- Categorical(범주형) Feature에 적용 가능
🔥 단점
- 다른 Feature 간의 상관 관계를 고려하지 않음
- Data에 Bias가 발생할 수 있음
import os
import pandas as pd
from collections import Counter
data = pd.read_csv(os.path.join(os.getcwd(), 'Data Path...'))
null_idx = data[data['Column 이름'].isnull()].index
notnull_idx = data[data['Column 이름'].notnull()].index
data['Column 이름'][null_idx] # 결측치 Data만 뽑아오기
data['Column 이름'][notnull_idx] # 관측치 Data만 뽑아오기
# 최빈값 계산 및 결측치 대체
cnt = Counter(data[data['Column 이름'].notnull()]['Column 이름'])
MFImputation = data.fillna(cnt.most_common(1)[0][0])
# 대체된 결과 확인
MFImputation['Column 이름'][null_idx]
zeroImputation = data.fillna(0) # 0으로 결측치 대체
zeroImputation['Column 이름'][null_idx] # 대체된 결과 확인
constImputation = data.fillna(25) # 임의의 상수로 결측치 대체
constImputation['Column 이름'][null_idx] # 대체된 결과 확인5. K-Nearest Neighbor Imputation (K-NN)
👉 지도 학습(Supervised Learning)의 한 종류로 Classification에 사용되는 알고리즘으로 Feature Similarity를 이용하여 가장 근처에 있는 K개의 Data를 찾는 방식이다. Python의 impyute , scikit-learn 라이브러리를 사용할 수 있다.
✨ 장점
- Data Set에 따라 Mean, Median, Most Frequent Value보다 정확한 경우가 많음
- 기저 Data의 분포에 대한 가정을 하지 않음
- 수치 기반 Data 분류 작업에서 성능이 우수함
🔥 단점
- 전체 Data Set을 Memory에 올려야 하기 때문에 Memory가 많이 필요
- Outlier에 민감한 부분이 있음
- 적절한 K 값을 선택해야 함
6. Multivariate Imputation by Chained Equation (MICE)
👉 결측치 부분을 여러 번 채우는 방식으로 작동한다. 불확실성을 다룰 때 Multiple Imputation이 Single Imputation보다 훨씬 좋다. 또, Chained Equation 방법은 Continuous, Binary, Categorical, Survey Skip Pattern 등에서도 적용할 수 있기 때문에 매우 유연한 방법이다.
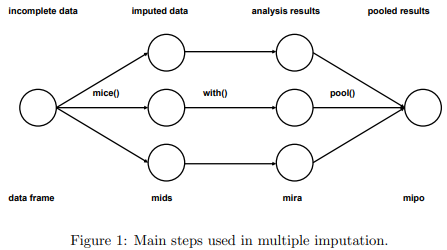
1. Imputation 과정 : Data의 분포를 토대로 결측치를 대체하여 Data Set을 M개 생성
2. Analysis 과정 : M개의 Completed Data Set을 분석
3. Pooling 과정 : Analysis 과정에서 분석한 평균, 분산, 신뢰구간을 바탕으로 Data Set을 합침
7. Deep Learning을 이용한 Imputation (with Datawig)
Amazon이 개발한 OSS의 결측치 보완 라이브러리로, 아파치 MXNet을 기반으로 함
👉 Deep Neural Network(DNN)을 이용하여 Machine Learning Model을 학습하고 결측치를 유추하는 방법이다. Numerical Feature의 결측치를 보충할 수 있고, Categorical 혹은 Non-Numerical Feature에 대해서 매우 효과적이다. MICE와 마찬가지로 Model과 다른 Feature에서 추출한 정보를 이용하여 결측치가 있는 Feature를 보충하고, 해당 Feature의 속성이나 모든 Feature의 잠재적 값의 유사도를 얻는다.
✨ 장점
- 다른 방법에 비해 꽤 정확함
- Categorical Feature를 처리할 수 있음
- CPU, GPU 지원
🔥 단점
- 한 번에 한 개의 Feature만 보충 가능
- 대규모 Data Set의 경우 속도가 상당히 느림
- 해당 Feature와 관련된 다른 Feature를 직접 지정
8. Regression Imputation
👉 결측치가 없는 Feature를 Label로, 결측치가 있는 Feature를 Target으로 두고 Regression Task를 진행하는 방법이다. 다른 Feature와의 관계는 보존할 수 있지만, 예측치의 다양성을 반영하지 못하는 단점이 있다.
9. Stochastic Regression Imputation
👉 Regression 방법에 Random Residual Value를 더하여 결측치를 보충하는 방식으로 Regression 방법의 이점과 Random Component의 이점을 가진다.
10. Extrapolation / Interpolation
👉 동일한 Feature에 대해 이산형 범위 내에 있는 다른 관측치로 결측치를 추정하는 방법이다.
✳️ Interpolation : 어떤 사람의 20살일 때의 키, 몸무게와 40살일 때의 키, 몸무게 정보를 토대로 30살일 때의 키, 몸무게 값을 예측하는 것
✳️ Extrapolation : 어떤 사람의 지금까지의 키, 몸무게 정보를 바탕으로 10년 후의 키, 몸무게 정보를 예측하는 것
11. Hot-Deck Imputation
👉 다른 Feature에서 비슷한 값을 가진 Data 중에서 하나를 Random Sampling하여 그 값을 대입하는 방법이다. 결측치가 있는 Feature의 값의 범위가 한정되어 있을 때 이점을 갖고, Random으로 가져왔기 때문에 어느 정도 변동성을 가지고 있으며 표준 오차의 정확도에 어느 정도 기여한다.
✳️ 예시
- 관측치 부분
| Age | Gender | Income |
|---|---|---|
| 49 | Male | 70M |
| 53 | Male | 90M |
- 결측치 부분
| Age | Gender | Income |
|---|---|---|
| 50 | Male | NaN |
- Hot-Deck 적용 결과
| Age | Gender | Income |
|---|---|---|
| 50 | Male | 70M |
12. Cold-Deck Imputation
👉 Hot-Deck 방법과 비슷하지만 비슷한 양상의 Data 중에서 어떤 규칙에 맞는 하나의 값을 골라 대입하는 방법이다. Hot-Deck의 Random Variation이 제거된다.
✳️ 어떤 규칙의 예시 : 비슷한 Data 중에서 N번째 Sample의 값을 골라 대입하는 방식, ...
✨ 각 Imputation에 관한 Code는 추후에 Update할 예정...
참고 자료
- 뚜찌지롱님의 "결측값(Missing Value)"
- 썽하님의 "누락 데이터(Missing value)를 처리하는 7가지 방법 / Data Imputation"
- Curycu님의 "결측값 대체(imputation)에 관하여"
- jee-9님의 "결측치(Missing values, Nulls) 처리에 대해서 (Imputation): SimpleImputer, IterativeImputer, MICE .."
- yooj_lee님의 "[머신러닝/ML] 결측치 처리하는 7가지 방법 (Seven Ways to Make up Data)"
- 차돌님의 "[머신러닝] K-NN 알고리즘(K-최근접 이웃) 개념"
- Buuren, S. V., & Groothuis-Oudshoorn, K. (2011). Mice: Multivariate Imputation by Chained Equations in R. Journal of Statistical Software
- Datawig 참고 사이트
