
String 형인 str 인자에서 중복되지 않은 알파벳으로 이루어진 제일 긴 단어의 길이를 반환해주세요.
str: 텍스트 return: 중복되지 않은 알파벳 길이 (숫자 반환)
예를 들어,
str = "abcabcabc"
return 은 3
=> 'abc' 가 제일 길기 때문str = "aaaaa"
return 은 1
=> 'a' 가 제일 길기 때문str = "sttrg"
return 은 3
=> 'trg' 가 제일 길기 때문First Try
- For문으로 Iteration을 돌려서 해당하는 str인자와 중복되는 다음 str인자 사이의 길이를 측정
- 그 길이가 Iteration중 나온 최대길이보다 크면 최대길이에 대입
- 최대 길이 maxlength return
def get_len_of_str(s):
# 아래 코드를 작성해주세요.
maxlength = 0 # return 해야하는 최대길이
index = 0 # i의 index
length = 0 # iteration마다 측정한 문자열 길이
for i in s:
length = s.find(i,index+1) - index # 다음 index부터 시작하여
# str인자 i 찾고 index를 빼서 길이 구하기
if length > maxlength: # maxlength update
maxlength = length
index+=1 # index 추가
return maxlength-> Error 발생!
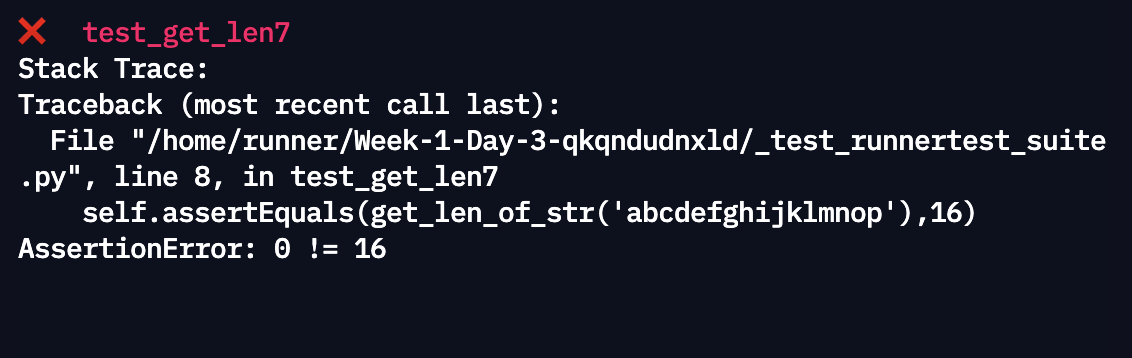
Error 원인 = find()함수는 문자열을 찾지 못했을 경우 -1을 출력한다. 따라서 문자열에 중복된 str인자가 존재하지 않을 경우 for문의 length가 모두 음수로 나와 maxlength가 초기값인 0을 return했다.
Second Try
Question: .find(i,index+1)이 -1인 경우 length에 어떤 값을 입력해야 하는가?
-> Iteration시 i 입장에서 중복되는 문자를 찾을 수 없을 경우 i 부터 문자열 끝까지의 길이를 length에 넣는다면?
ex1) abcdefghijklmnopqu = 중복되는 문자가 하나도 없는 경우
ex2) abcdebghijklmnopqu = 중간에 중복되는 다른 문자가 있는 경우
1의 경우 a부터 문자열 끝까지 넣어도 가능하지만, 2의 경우 a가 중복되는 a가 없다고 해서 문자열 끝까지의 길이를 length에 넣으면 그 안에 중복되는 b가 있기에 오류가 날 것이다.
중복되는 문자가 하나도 없으면 length에 대입하고, 아니면 스킵해준다.
index부터 문자열 끝까지 list를 만들어 set()과 비교해 길이가 같으면 중복되는 문자가 없는것!
알고리즘을 다시 적용해보자.
def get_len_of_str(s):
# 아래 코드를 작성해주세요.
maxlength = 0
index = 0
length = 0
for i in s:
list=[]
if s.find(i,index+1) == -1: # 현재 index와 중복되는 문자 없음
for j in s[index:]: # 현재 index부터 문자열 끝까지 list
list.append(j)
if len(set(list)) == len(list): # list와 set 길이 비교
length = len(s)-index # 같으면 index부터 끝까지 길이 대입
# 다르면 최대 길이 될수가 없으므로 대입x
else:
length = s.find(i,index+1)-index # index 이후로 중복되는 문자 있으면 사이 길이 대입
index+=1
if length > maxlength:
maxlength = length
return maxlength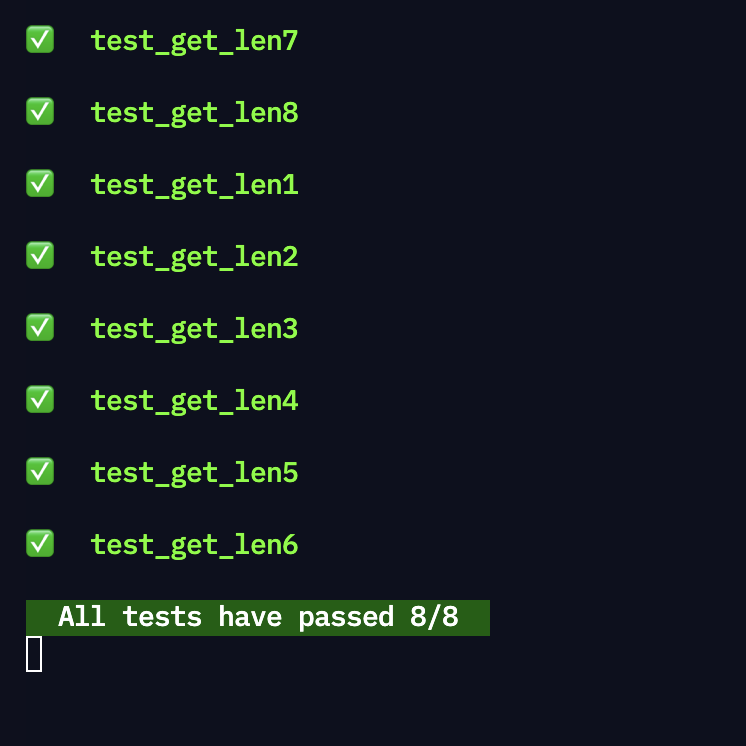
제대로 Pass했다!
Simple Answer
def get_len_of_str(s):
maxlength = 0
for i in range(len(s)):
lenstr = ''
length = 0
for j in s[i:]:
if j not in lenstr:
lenstr+=j
length+=1
else:
lenstr=j
length=1
if length > maxlength:
maxlength = length
return maxlength
어디를 가든 마음을 다해 가자