
Django ORM, QuerySet API 의 특징과 작동원리를 파악하고 API의 Loading 개념과 ORM 최적화에 관한 세션을 듣게 되었다. Django ORM의 특징인 Lazy Loading, Caching, EagerLoading에 대해서 간단하게 살펴보고 Eager Loading을 내가 만든 API에 적용해보자.
Django ORM
Django QuerySet은 ORM 개념을 통해 Server와 Database를 mapping해준다. Django ORM은 어떻게 SQL문으로 변환되어 데이터베이스에 요청해줄까?
Lazy Loading
Django ORM은 Query가 선언되는 순간 SQL을 호출하는 것이 아니라 Slicing, Iteration 등 Query Evaluation을 하는 순간에만 호출된다.
q = Space.objects.all()
q2 = q.filter(id=1)
q3 = q2.exclude(id=2).annotate(count=Count('like'))
list(q3)실제로 위와 같은 코드를 실행할 경우 SQL문은 단 한번만 실행된다. 위의 q, q2, q3을 선언해준 것은 DB에 hit되지 않고, 오로지 list(q3)을 통해 Query가 직접 evaluation 될때만 DB에 호출된다.
Caching
QuerySet은 호출된 후
result_cache라는 곳에 요청된 쿼리를 cashing(저장)한다.
q = Space.objects.all()
q2 = q.filter(id=1)
q3 = q2.exclude(id=2).annotate(count=Count('like'))
q3[0]
q3[0]
q3[0]
list(q3)Lazy Loading은 Query Evaluation이 되는 순간에 항상 SQL문을 호출한다. 따라서 위와 같은 코드는 반복되는 QuerySet 호출임에도 불구하고 총 4번의 Query를 실행하게 된다.
이렇게 불필요한 Query 호출문제를 해결하기 위해 QuerySet은 호출된 후 그 정보를 Caching하여 Query를 저장한다.
q = Space.objects.all()
q2 = q.filter(id=1)
q3 = q2.exclude(id=2).annotate(count=Count('like'))
list(q3)
q3[0]
q3[0]
q3[0]위의 코드에서 호출 순서만 달라졌을 뿐인데도 list(q3)이 호출되어 총 Query는 1번이 된다. Query를 Caching하기 때문에 그 정보를 이용해 q3[0]을 실행할 경우 불필요한 Database Hit을 줄일 수 있다.
Eager Loading
QuerySet이 Evaluation될 때 N+1 Problem을 해결하기 위해
select_related,prefetch_related를 통한 호출 개념이다.
예를 들어 User와 Item이 One-to-One RelationShip이라고 생각해보자. 각 User에 대응하는 Item의 정보를 얻고싶다고 가정할때,
users = User.objects.all()
for user in users:
user.item와 같이 코드를 짠다고 해보자.
이럴 경우 만 명의 user가 존재할때, users라는 QuerySet에는 1번의 Query로 모든 user의 정보를 담아왔지만, Iteration을 통해 Item 정보를 가져올 경우 각 user당 1번의 추가 Query, 즉 10000개의 Query가 추가로 발생한다.
user가 N명인 경우 총 N+1번의 Query가 발생하기에 N+1 Problem이라고 부르는 것이다.
이 같은 문제를 해결하기 위해 User를 선언하면서 미리 Item의 정보를 호출하는 select_related Method를 사용한다.
users = User.objects.all().select_related("item")
for user in users:
user.item이렇게 처음 User를 선언할 경우 select_related로 Item을 User에 Inner Join하여 SQL문을 선언해주면, 단 1번의 DB Hit으로 줄어들게 된다. prefetch_related는 M2M이나 역참조인 경우 사용하며, 추가로 Query 1개를 더 사용한다.
Apply Eager Loading
이제 2차 Proejct에서 내가 만든 API에 Eager Loading을 적용해보자.
Logging
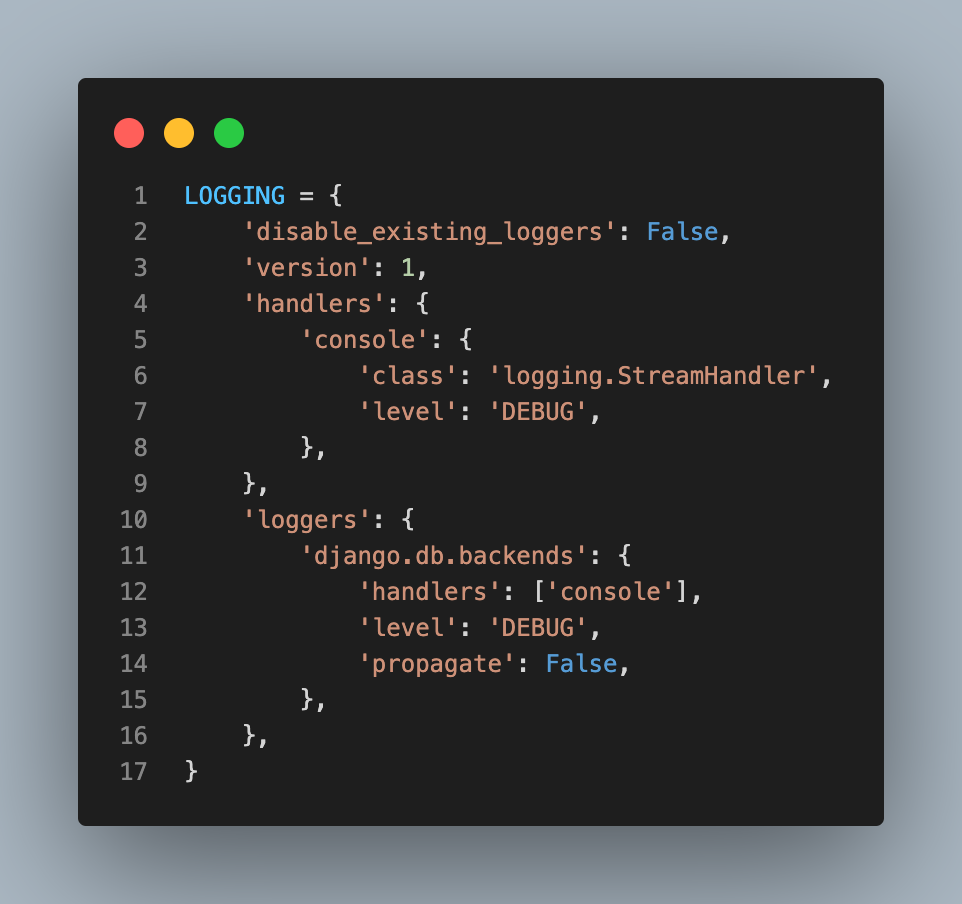
서버를 구동하고 View를 호출할 경우 코드 실행시마다 쿼리가 찍히게 settings.py에 설정하자.
Decorator
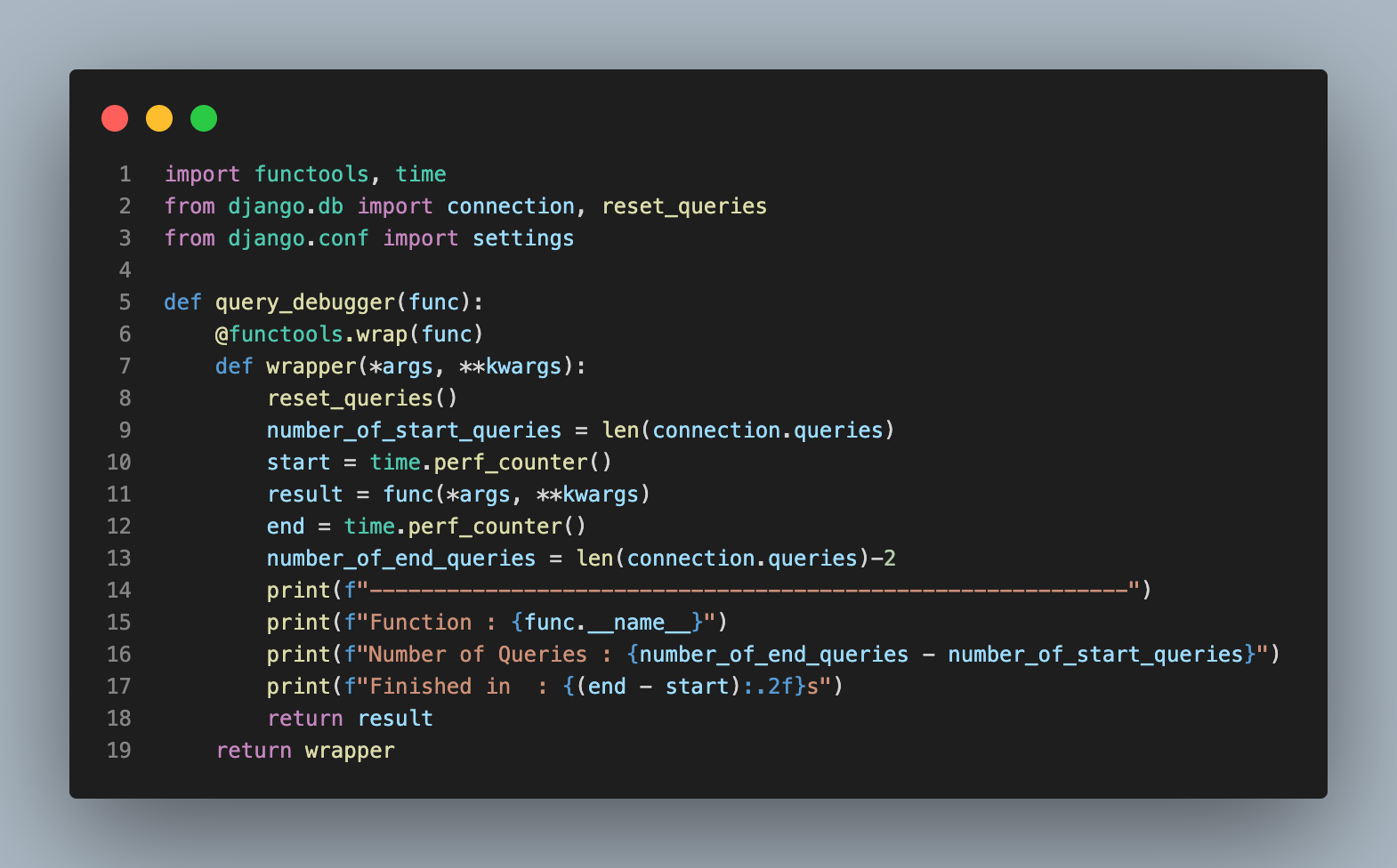
실행한 총 Query 개수와 실행시간을 Terminal에 출력하도록 Decorator를 작성한다.
Original Code
Unit Test 블로깅을 하며 내가 작성했던 코드에 대해 Query 개수와 실행시간을 확인하고 성능을 향상시킬 수 있는 방법을 생각해봤다.
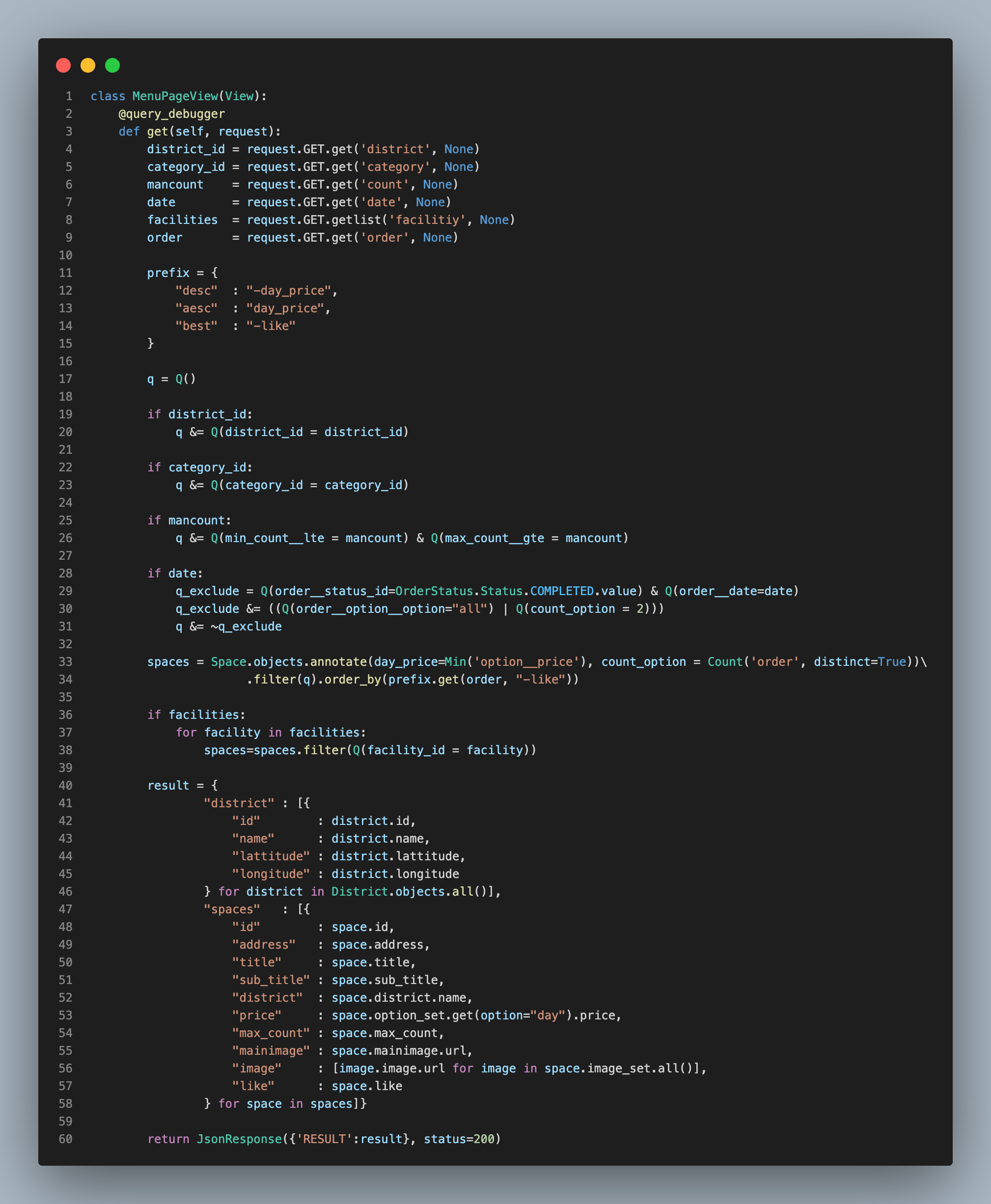
다시 손을 본 코드인데도 불구하고 Query는 100개, 실행시간은 0.25초나 되었다.

Improve Perfomance
- Image 역참조의 경우
prefetch_related사용
Request에 대해 결과를 반환하며 Dictionary를 만드는 과정에서 Space가 역참조하는 Image Table을 호출하는 것을 알게 되었다.
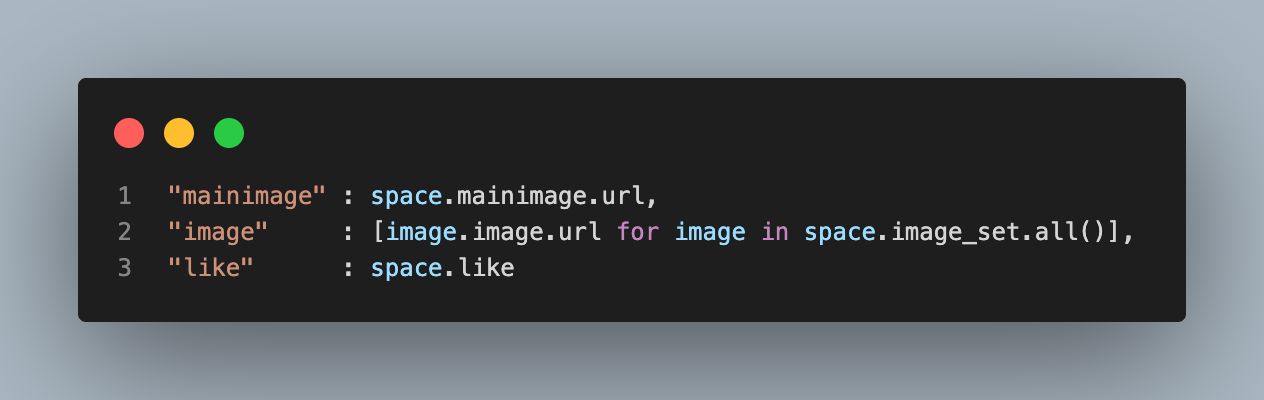
Image 호출시 N+1 Problem이 발생한다는 것을 깨닫고 space를 선언할 경우 미리 prefetch_related를 사용해 Image를 호출해주었다.
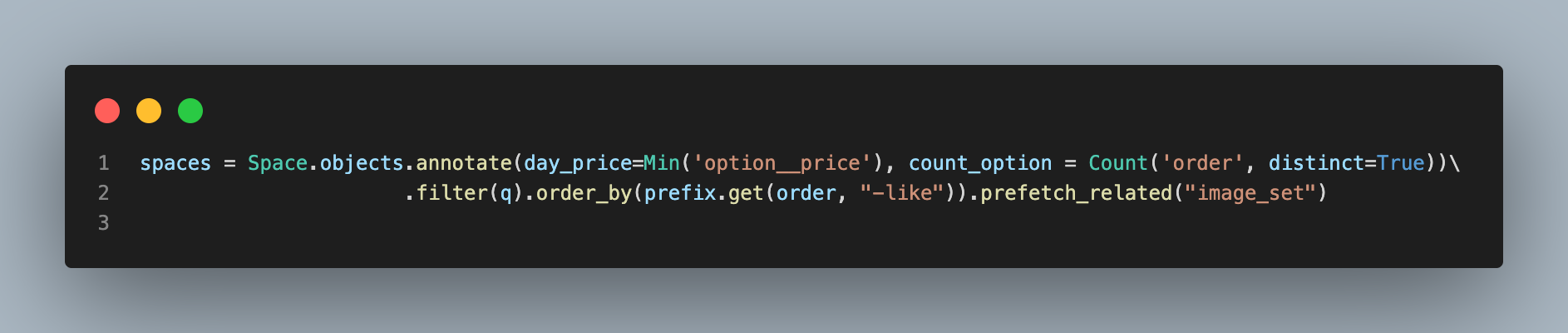
그 결과 총 Query 수가 67개로 줄어들었다! 2개는 기본적으로 세팅되어있기에 빼야한다!

- 이미 선언된 Annotate를 활용해
day_price사용
똑같은 문제로 역참조 관계인 Option을 호출하면서 N+1이 발생했다.
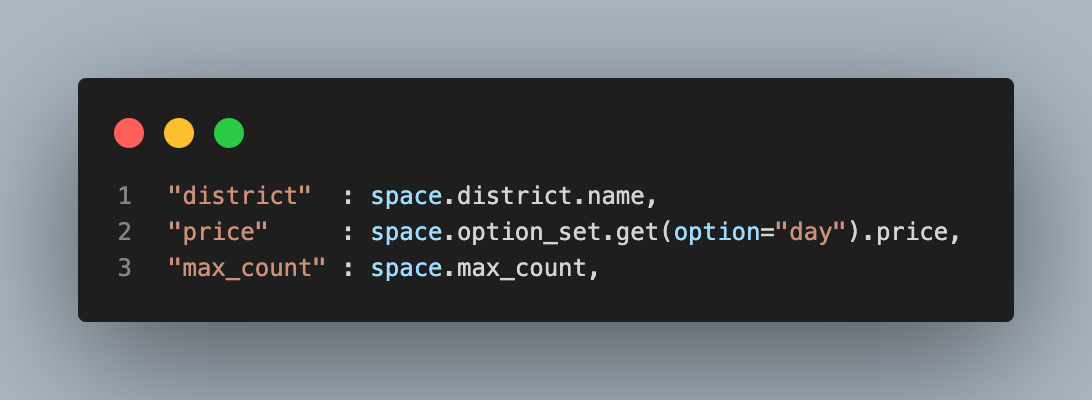
그런데 여기서 option_set.get(option="day").price는 이미 위에서 Filtering을 하며 Annotate로 spaces QuerySet에 추가됨을 깨달았다.
처음 경우와 마찬가지로 prefetch_related할 수 있겠지만, 이미 Annotate한 day_price를 사용했더니 총 Query 수가 35개로 줄어들었다!
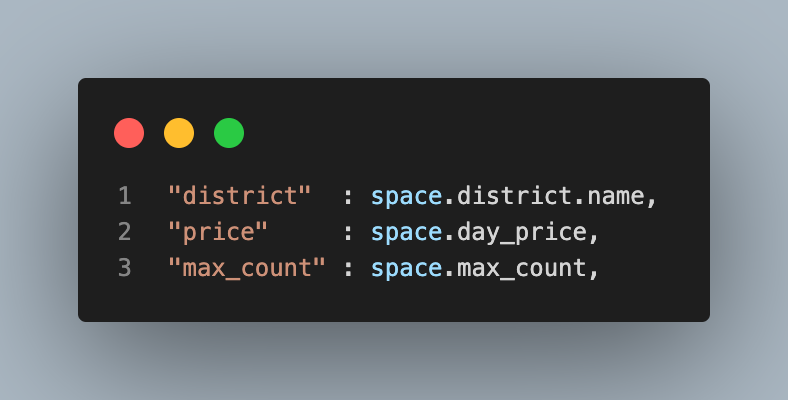

- District 정참조의 경우
select_related사용
다시 코드를 검토하는 과정에서, Space가 정참조 District Table을 호출하는 것을 알았다. 따라서 1번 과정에서 사용한 prefetch_related와 더불어 select_related를 사용해주고, 코드가 너무 길지 않게 분리하여 선언해주었다.
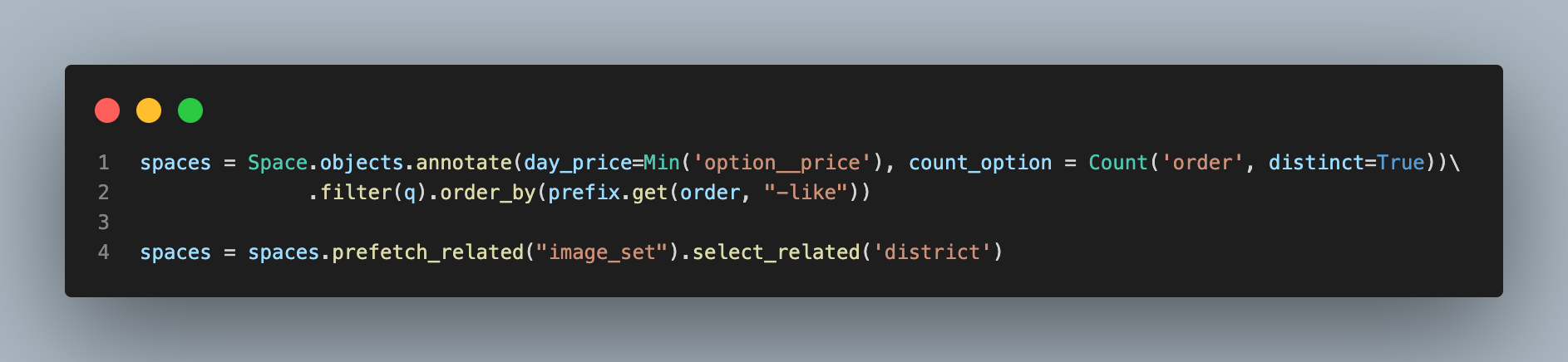

테스트 결과 Query가 총 3개로 줄어들었다..!
Django ORM의 특징을 이해하고 API의 성능을 테스트 한 후 몇 줄의 Code만 개선했을 뿐인데 총 Query가 100개에서 3개로 줄어들었다! 이는 District Table을 호출하면서 1번, 그리고 Filter된 Space Table을 호출하며
prefetch_related를 사용했기에 2번 호출하여 DB에 총 3번 Hit된 것으로 보인다!
TIL
처음 세션을 들을때는 Django ORM에 대해 제대로 이해하지 못하고 그저 성능 테스트와 관련되었다고 생각하고 말았다. 그런데 실제로 내가 만든 API에 대해 성능 Test를 진행하고, QuerySet의 구조와 동작원리를 이해한 후 코드 몇 줄 바꿔서 성능을 눈에 띄게 향상시켜보니 정말 놀라웠다.
1차 프로젝트 때는 기능구현에만 급급해서 내가 만든 코드의 성능에 대해 생각도 하지 않았는데, 실제로 현업에서 일할 경우를 고려해보니 앞으로 기능을 구현할 경우 최대한 API 성능을 테스트하고 개선하기 위해 노력해야겠다.
