스택과 큐는 임시 데이터를 처리 할 수 있는 간결한 도구다. 운영 체제 아키텍쳐부터 출력 잡과 데이터 순회에 이르기까지 스택과 큐를 임시 컨테이너로 사용해 뛰어난 알고리즘을 만들 수 있다.
곧 설명하겠지만 스택과 큐는 임시 데이터를 처리하되 데이터를 처리하는 순서에 특히 중점을 둔다.
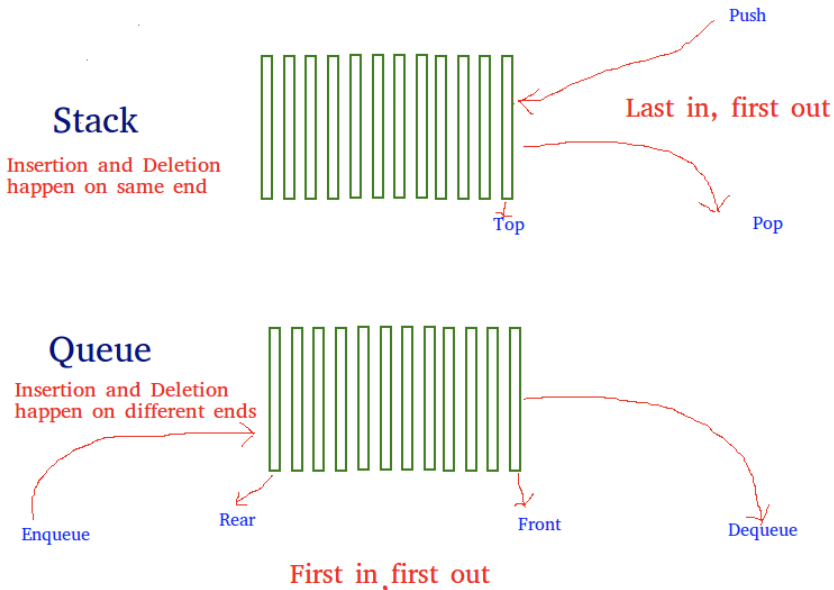
스택(stack)
스택(stack)이 데이터를 저장하는 방법은 배열과 같다. 즉, 단순히 원소들의 리스트다. 다만 스택에는 다음과 같은 세가지 제약이 있다.
- 데이터는 스택의 끝에만 삽입할 수 있다. - PUSH
- 데이터는 스택의 끝에서만 삭제할 수 있다. - POP
- 스택의 마지막 원소(top)만 읽을 수 있다. - PEEK
접시가 쌓여있으면 가장 위에 있는 접시를 제외하고는 다른 접시의 윗면은 볼 수 없다. 실제로 컴퓨터 과학책에서 스택의 끝을 위(top), 스택의 시작을 밑(bottom)이라 부른다.
스택에 새 값을 삽입하는 것을 스택에 푸시한다고 말한다. 접시 더미 위에 한 접시를 얹는다고 생각하면 된다.
스택의 위에서 원소를 제거하는 것을 스택으로부터 팝(pop)한다고 한다. 스택의 제약으로 인해 데이터는 위에서만 팝할 수 있다.
스택 연산을 묘사하는 데 쓰이는 유용한 두문자어가 “Last In, First Out” 을 뜻하는 LIFO다.
스택에 푸시된 마지막 항목이 스택에서 팝될 첫 번째 항목이라는 의미다. 마치 게으른 학생처럼 마지막으로 들어오지만 가장 먼저 나가는 것처럼 말이다.
큐(queue)
큐(queue) 역시 데이터를 처리하기 위해 디자인된 데이터 구조이다. 데이터를 처리하는 순서만 제외하면 많은 면에서 스택과 비슷하다. 큐를 극장에 줄 서 있는 사람들에 비유하면 줄 맨 앞에 있는 사람이 가장 먼저 극장에 들어간다. 큐 역시 큐에 첫 번째로 추가된 항목이 가장 먼저 제거된다. 그래서 컴퓨터 과학자는 First In, First Out의 약자인 “FIFO”로 표현한다.
그리고 흔히 큐의 시작을 앞(front), 큐의 끝을 뒤(rear)라 부른다.
큐도 스택과 마찬가지로 세 가지 제약을 갖는다. (조금 다르다!)
- 데이터는 큐의 끝에만 삽입할 수 있다.(스택과 동일) - INSERT
- 데이터는 큐의 앞에서만 삭제할 수 있다.(스택과 정반대) - REMOVE
- 큐의 앞에 있는 원소만 읽을 수 있다.(스택과 정반대) - PEEK
큐에서 원소를 삽입하는 것을 흔히 인큐(enqueue)라고 부르고, 큐에서 원소를 삭제하는 것을 디큐(dequeue)라고도 부른다.
또한 큐는 요청받은 순서대로 요청을 처리하므로 비동기식 요청을 처리하는 완벽한 도구이기도 하다. 이외의 이륙을 기다리는 비행기나 의사를 기다리는 환자처럼 정해진 순서대로 이벤트가 발생해야 하는 실세계 시나리오를 모델링하는 데 흔하게 쓰인다.

좋은 글이네요😘