Python
1.프로그래머스 강의_1
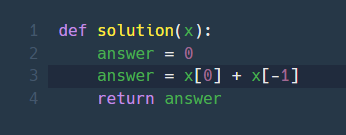
자료구조 (datastructure)은 왜 알아야할까?강의의 예시에서 결과를 보면 알 수 있듯이 리스트에서 전부 다 보고 찾아내야 하기 때문에 갯수에 비례하는 시간이 걸린다. 그러므로 어떤 자료구조를 만들어야 시간을 줄일 수 있을지 찾아내야 한다.알고리즘이란?(algo
2.프로그래머스 강의_2
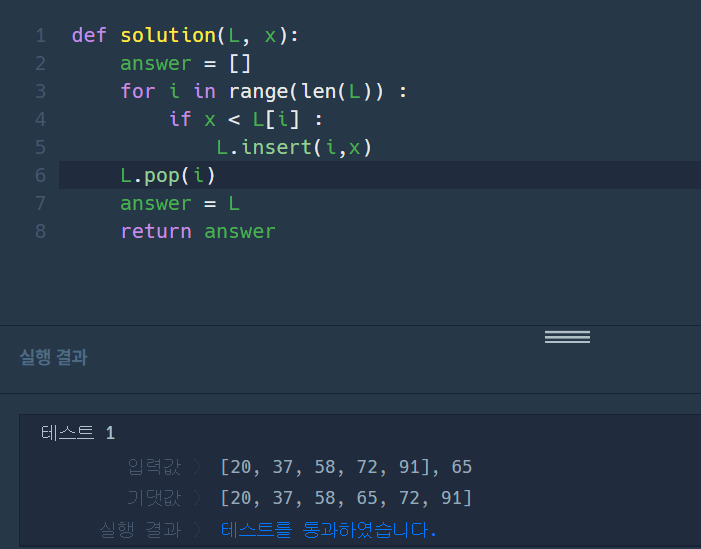
배열 : 원소들을 순서대로 늘어놓은 것index는 0부터 시작한다.L = 1,2,3,4,5 라고 하였을 때 0번째 : 1 , 1번째 : 2, 2번째 : 3으로 볼 수 있다.L(1) ==> 2L(-1) ==>5리스트(배열) 연산1) 원소 덧붙이기 L.append(6)2)
3.프로그래머스 강의_3
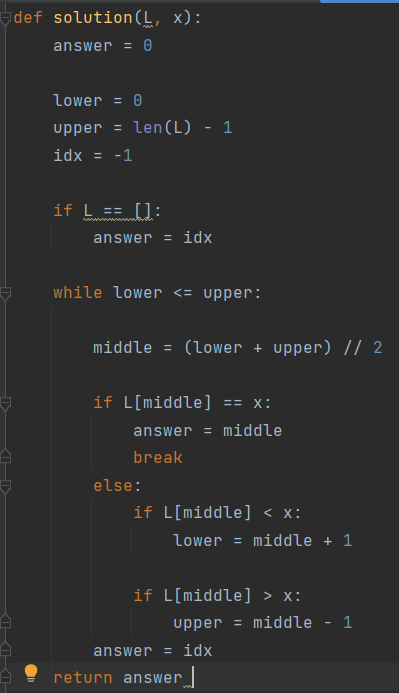
정렬무작위의 배열 L = 3,8,2,7,6,10,9 를 정렬 sort 하면 결과 값은 L = 2,3,6,7,8,9,10 이다. 이렇게 순서대로 해주는 것을 sort한다고 한다.(1) sorted() 내장 함수(built-in funcion)정렬된 새로운 리스트를 얻어
4.프로그래머스 강의_4
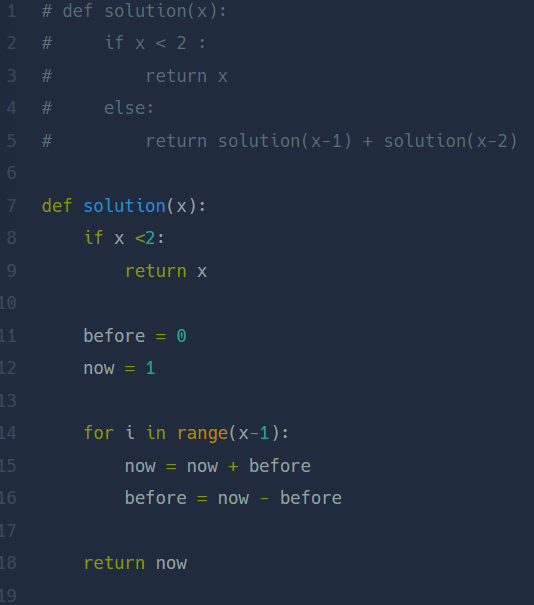
재귀 알고리즘 (Recursive Algorithm)하나의 함수에서 자신을 다시 호출하여 작업을 수행하는 것 ex) 문제 : 1부터 n까지 모든 자연수의 합을 구하시오. n의 조건을 설정해 주지않으면 마이너스 숫자가 계속 반복되기 때문에 재귀함수에서 종결 조건을 주는
5.프로그래머스_강의5
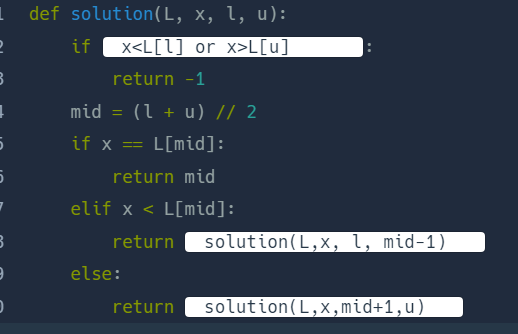
하나의 함수에서 자신을 다시 호출하여 작업을 수행하는 것 1) 조합의 수 계산 문제 : n개의 서로 다른 원소에서 m개를 택하는 경우의 수===> 효율성 측면에서 과연 좋을까???2) 문제 : 하노이의 탑3) 피보나치 수열의 재귀알고리즘에대한 효율 fibo(4)
6.프로그래머스 강의_6

알고리즘의 복잡도 (Complexity of Algorithms) 문제를 푸는데 있어 얼만큼의 자원을 필요로하는가이다. 1) 시간 복잡도(Time Complexity) ** 문제의 크기와 이를 해결하는데 걸리는 시간 사이의 관계 2) 공간 복잡도(Space C
7.프로그래머스 강의_7
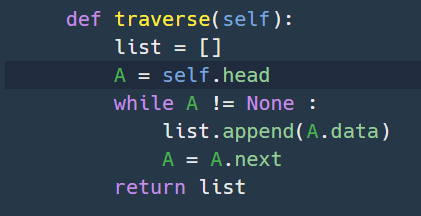
Data ( 예 : 정수, 문자열, 레코드,...)A set of operations (삽입, 삭제, 순회, 정렬, 탐색, ...)각각의 아이템 : Node ( Data, Link (next) )Node 내의 데이터는 다른 구조로 이루어질 수 있음 (문자열, 레코드,
8.프로그래머스 강의_8
pos가 가리키는 위치에 ( 1<= pos<= nodeCount +1)newNode 를 삽입하고 성공/실패에 따라 True/False를 리턴L.insertAt(pos, newNode) pos-1 => prev pos => prev.next ==> prev
9.프로그래머스 강의_9
아이폰에서 여러 프로그램을 켜놨을 때 삭제할때삽입과 삭제가 유연하다는 것이 가장 큰 장점==> 새로운 메서드를 만들자 insertAfter(prev, newNode) -> 맨 앞에는 어떻게? popAfter(prev) -> 맨 앞에서는 어떻게??연결리스트 연산 - 맨
10.프로그래머스 강의_10
한 쪽으로만 링크를 연결하지 말고, 양쪽으로!! ==> 앞으로도 (다음 node) 뒤로도 (이전 node) 진행가능 ==> 데이터를 담고 있는 node 들은 모두 같은 모양이 된다!새로운 노드의 이전노드를 prev노드로 설정새로운 노드의 다음 노드를 next노드
11.프로그래머스 강의_11
자료(data)를 보관할 수 있는 (선형) 구조단, 넣을 때에는 한 쪽 끝에서 밀어넣어야 하고 => 푸시(push) 연산꺼낼 때에는 같은 쪽에서 뽑아 꺼내야 하는 제약이 있음 => 팝(pop) 연산후입선출(LIFO-Last-In First-Out) 특징을 가지는 선형
12.프로그래머스 강의_12
스택의 응용 ( 수식의 후위 표기법 ) 중위 표기법(infix notation) 연산자가 피연산자들의 사이에 위치 ex) (A + B) * (C + D) 후위 표기법(postfix notation) 연산자가 피연산자들의 뒤에 위치 ex) AB + CD + * ==>
13.프로그래머스 강의_13
중위표기법 (연산자가 피연산자들의 사이에 위치)후위표기법 (연산자가 피연산자들의 뒤에 위치)AB + CD+\*앞 두개가 피연산자, 두 피연산자 사이에 적용할 연산자연산자를 만났을 때 피연산자를 pop 해서 계산한 후 다시 스택에 push 한다.다시 피연산자를 push하
14.프로그래머스 강의_14
단, 넣을 때에는 한 쪽 끝에서 밀어 넣어야 하고===> 인큐(enqueue) 연산 꺼낼 때에는 반대 쪽에서 뽑아 꺼내야 하는 제약이 있음.===> 디큐(dequeue) 연산선입선출(FIFO:First-In First-Out)특징을 가지는 선형 자료구조 데이터 원소
15.프로그래머스 강의_15
자료를 생성하는 작업과 그 자료를 이용하는 작업이 비동기적으로 (asynchronously) 일어나는 경우자료를 생성하는 작업이 여러 곳에서 일어나는 경우양쪽 다 여러 곳에서 일어나는 경우자료를 처리하여 새로운 자료를 생성하고 나중에 그 자료를 또 처리해야 하는 작업의
16.파이썬 범위규칙
파이썬에서 이름 공간을 찾는 규칙을 LEGB Rule이라고 한다. Local : 함수 내 정의된 변수Enclosing Function Local : 함수를 내포하는 또 다른 함수 영역, 내부함수에서 자신의 외부 함수의 범위Global : 함수 영역에 포함되지 않는 모듈
17.프로그래머스 강의_16
큐가 FIFO 방식을 따르지 않고 원소들의 우선순위에 따라 큐에서 빠져나오는 방식예) Enqueue 작은 수가 우선순위가 높다고 가정6 7 3 2 => 큐의 길이는 4 예) Dequeue 2 3 6 7 => 우선순위대로 빠져나온다.운영체제의 CPU 스케줄러서로 다른
18.프로그래머스 강의_17
정점(node)과 간선(edge)을 이용하여 데이터의 배치 형태를 추상화한 자료구조leaf, root 이파리, 뿌리 에서 따온 이름root가 위에 있고 가지치기로 마지막이 leaf가 있는 구조루트(Root)노드리프(Leaf)노드 (가지를 치는 노드가 없음)내부(Int
19.프로그래머스 강의_18
이진 트리(Binary Trees) 이진 트리의 추상적 자료구조 (1) 연산의 정의 size() : 현재 트리에 포함되어있는 노드의 수를 구함 depth() : 현재 트리의 깊이(또는 높이; height)를 구함 순회(traversal) : (2) 이진트
20.프로그래머스 강의_19
(1) 원칙 수준(level)이 낮은 노드를 우선으로 방문같은 수준의 노드들 사이에서는 부모 노드의 방문 순서에 따라 방문왼쪽 자식 노드를 오른쪽 자식보다 먼저 방문한다.==> 재귀적(recursive)방법이 적합한가?한 노드를 방문했을 때 나중에 방문할 노드들을 순
21.프로그래머스 강의_20
모든 노드에 대해서 왼쪽 서브트리에 있는 데이터는 모두 현재 노드의 값보다 작고 오른쪽 서브 트리에 있는 데이터는 모두 현재 노드의 값보다 큰 성질을 만족하는 이진트리. (중복되는 데이터 원소는 없는 것으로 가정) ?! 정렬된 배열을 이용한 이진 탐색과 비슷하다.
22.프로그래머스 강의_22
힙(Heaps) 이진트리의 한 종류(이진 힙-binary heap) 루트(root)노드가 언제나 최댓값 또는 최솟값을 가진다. 최대 힙(max heap), 최소 힙(min heap) 완전 이진 트리여야 함 최대 힙(Max Heap)의 예 재귀적으로도 정의됨
23.프로그래머스 강의_23
힙(Heaps) 최대 힙에서 원소의 삭제 루트 노드의 제거 : 이것이 원소들 중 최댓값 트리 마지막 자리 노드를 임시로 루트 노드의 자리에 배치 자식 노드들과의 값 비교오ㅘ 아래로, 아래로 이동 -> 자식은 둘 있을 수도 있는데, 어느 쪽으로 이동? 최대 힙에서 원소
24.프로그래머스 강의_21
이진 탐색 트리(Binary Search Trees) 이진 탐색 트리에서 원소 삭제 키(key)를 이용해서 노드를 찾는다. => 해당 키의 노드가 없으면, 삭제할 것도 없음 => 찾은 노드의 부모 노드도 알고 있어야 함 찾은 노드를 제거하고도 이진 탐색 트리 성질