ArgoCD를 연결해서 Auto-Sync를 켜놓고 따로 파일을 적용해서 안됐던 멍청이슈를 반복하지 않기 위해서.. 적어보려고 합니다. ArgoCD를 연결하셨다면 로컬에서 파일을 적용시키거나 Github에 반영하더라도 Auto-Sync 끄시고 적용하시길 바라요. 부디..🥹
환경 및 참고 자료
HPA 설정은 Kubernetes 공식문서의 Horizontal Pod Autoscaling와 HorizontalPodAutoscaler 연습을 참고하였습니다.
저는 EKS 환경에서 GitHub에 manifest 레포를 두고 이를 추적하는 ArgoCD로 배포를 관리하고 있습니다. HPA 적용 전에 레포에 등록된 yaml 파일은 아래와 같습니다.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
namespace: default
labels:
app: backend
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
resources:
requests:
cpu: 200m
memory: 250Mi
limits:
cpu: 500m
image: <이미지>
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
labels:
app: backend
name: backend-svc
namespace: default
spec:
ports:
- protocol: TCP
name: http
port: 80
targetPort: 8080
- protocol: TCP
name: https
port: 443
targetPort: 8080
selector:
app: backend
type: LoadBalancer그리고 아래 명령어로 부하를 주었습니다.
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.1; do wget -q -O- http://backend-svc; done"#1 ArgoCD Auto-Sync
❌ ArgoCD Auto-Sync Enable
먼저 Auto-Sync를 켜둔 상태로 로컬에서 api로 파일을 적용했습니다.
# hpa-backend.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: backend
namespace: default
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: backend
그러면 이렇게 CPU 사용률이 올라가는데도 REPLICAS가 올라가지 않는 상황을 확인할 수 있습니다. manifest 레포에 HPA를 적용했을 때도 같은 상황이 반복되었습니다.
🤔 원인

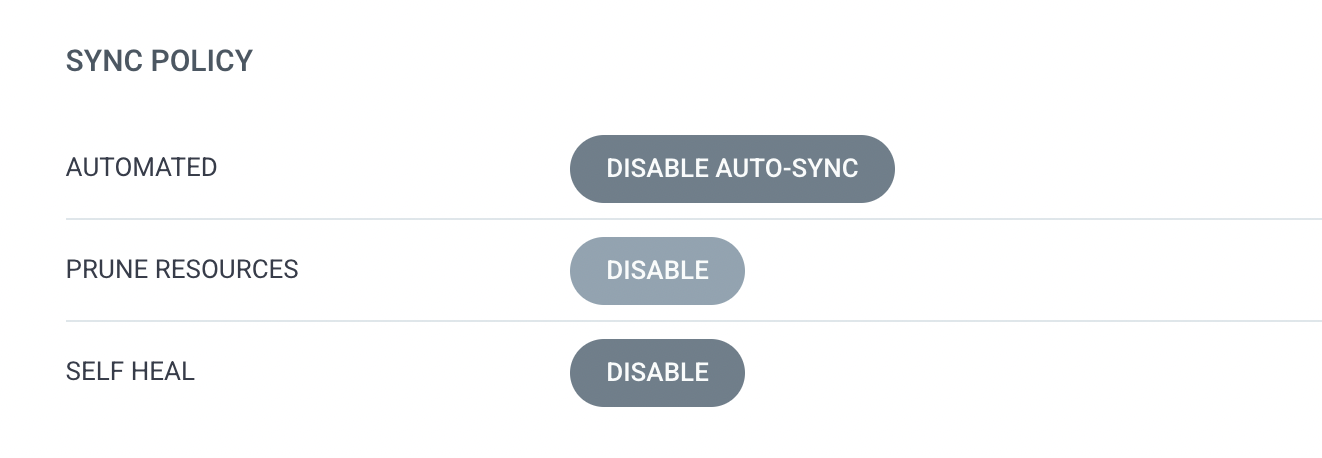
CD 자동화를 위해 켜두었던 ArgoCD의 Auto-Sync와 기타 옵션들 때문에 HPA 적용보다 deployment.yaml deployment replicas의 설정을 따라서 오토스케일링이 되지 않는 것입니다. HPA -> Deployment Replicas Sync -> HPA -> ... 의 무한 반복으로 결국 레플리카 개수를 따라가는 것이었죠.
⭕️ ArgoCD Auto-Sync Disable
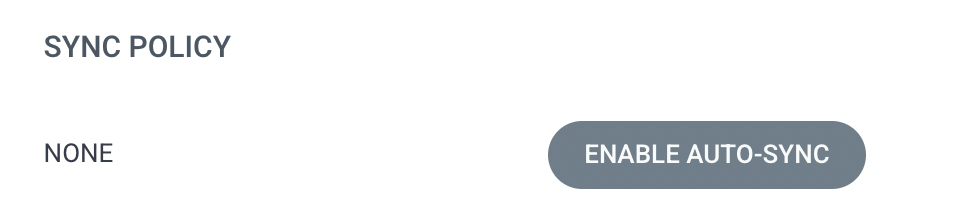
일단 ArgoCD의 Auto-Sync를 끄는 것으로 트러블슈팅을 시작했습니다.
그리고 Deployment의 Replica를 1로 바꾸고 파드 수 변경은 전부 HPA에서 하도록 수정했습니다.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
namespace: default
labels:
app: backend
spec:
replicas: 1
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
resources:
requests:
cpu: 200m
memory: 250Mi
limits:
cpu: 500m
image: <이미지>
ports:
- containerPort: 8080
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: backend
namespace: default
spec:
maxReplicas: 6
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: backend
---
apiVersion: v1
kind: Service
metadata:
labels:
app: backend
name: backend-svc
namespace: default
spec:
ports:
- protocol: TCP
name: http
port: 80
targetPort: 8080
- protocol: TCP
name: https
port: 443
targetPort: 8080
selector:
app: backend
type: LoadBalancer위의 파일을 manifest 레포에 적용하고 ArgoCD에 Sync를 적용했을 때,

위와 같이 초반 실행에 CPU를 쓰며 스케일업 되었고 안정화되는 과정에서 스케일아웃 되며 오토 스케일링이 적용되는 것을 알 수 있습니다.
그리고 아래처럼 OutOfSync가 되는 것이 문제가 아니라 오토스케일링이 적용되며 manifest와 동기화되어있지 않다는 뜻일뿐 문제가 아닙니다..!

#2 cpu: < unknown >
EKS 환경에서 HPA를 적용하려고 먼저 아래 명령어를 실행했습니다.
kubectl autoscale deployment backend --cpu-percent=50 --min=1 --max=10
하지만 위와 같이 cpu 사용량이 추적되지 않아 트러블슈팅을 시작했습니다!
metrics-server
metrics-server는 쿠버네티스 내장형 자동 스케일링 파이프라인을 위한 컨테이너 리소스 메트릭 수집 오픈소스입니다. 아래 주의와 같이 오토스케일링만을 위한 오픈소스입니다!
⚠️ Caution
Metrics Server is meant only for autoscaling purposes. For example, don't use it to forward metrics to monitoring solutions, or as a source of monitoring solution metrics. In such cases please collect metrics from Kubelet /metrics/resource endpoint directly.
먼저 metrics-server 설치하고 설치가 되었는지 kubectl top 명령어로 확인했습니다.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability-1.21+.yaml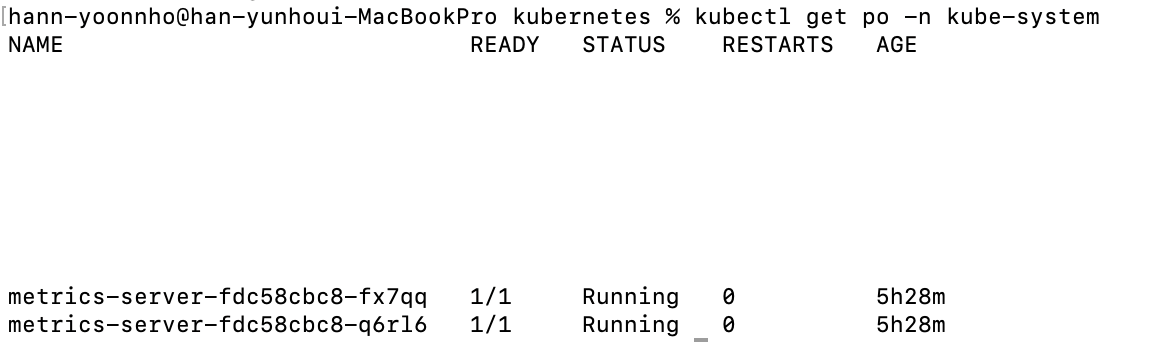

그리고 추적하려는 resources의 cpu 사용률을 가리키는 current는 requests를 기준으로 표시되기 때문에 requests를 설정합니다.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
namespace: default
labels:
app: backend
spec:
replicas: 1
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
# resources 추가하기
resources:
requests:
cpu: 200m
memory: 250Mi
limits:
cpu: 500m
image: <이미지>
ports:
- containerPort: 8080
...deployment의 requests와 limits 설정은 kubectl get deploy -o yaml | grep resources 명령어로 확인했고 설정 전후는 아래의 사진으로 비교할 수 있습니다.


추가로 hpa 생성 후 리소스 추적까지 약 30초의 시간이 필요합니다!

마무리
쿠버네티스도 오토스케일링을 하려면 YAML 파일 설정 이외에 다른 설정이 필요하다! 는 것을 직접 설정하며 알 수 있었고 EKS에서 리소스 프로비저닝을 하는 방법까지 생각해볼 수 있었습니다.🥳
