제목은 스스로 하는 반성입니다. 파면 팔수록 그동안 무중단배포라는 단어를 너무 쉽게 붙여왔고 무중단배포가 아님에도 무중단배포라고 칭했던 경우가 잦았던 것 같아 아무 배포나 무중단배포라고 부르지 않기 위해서! 무엇이 무중단배포이고 무엇이 아닌지 확실히 정리해보려고 합니다.
Zero Downtime Deployments
무중단배포는 서비스 운영과 클라이언트 입장에서 서비스가 끊어지지 않으면서(Zero-downtime) 신규 소프트웨어를 배포하는 기술로 운영 중인 서비스를 중단하지 않고 업데이트 과정에서 서비스가 동작하지 않는 영향을 주지 않는 것이 중요합니다.
Downtime (중단 시간)
= 시스템, 네트워크, 애플리케이션 또는 서비스가 예정되지 않은 방식으로 작동을 멈추거나 접근할 수 없게 되는 시간
CI/CD에서 CD(Continuous Deployment/Delivery)를 제대로 구현하려면 무중단배포를 이해해야하고 꾸준한 업데이트가 이루어지는 애자일, 데브옵스 방식에서는 더욱 중요합니다. 무중단배포 전략에서도 소개하겠지만 쿠버네티스의 큰 장점 중 하나도 무중단배포를 지원한다는 점입니다.
잘못된 용례
지금까지 백엔드에서 하나의 물리 서버에 하나의 애플리케이션 서버를 실행하며 서버를 실행하는 동안 서버가 중단되지 않고 서비스가 제공되지 않을 일도 없을테니 '무중단배포'라고 부르곤 했습니다.
어떻게 그렇게 생각할 수가 있나 싶지만 지금이라도 반성하고 있습니다..
하지만 진짜 무중단배포라고 부를 수 있으려면 새로운 소프트웨어로 트래픽을 옮기는 과정에서 서버, 데이터베이스, 로드밸런서 등의 다중화를 통해 한 번에 트래픽을 옮기는 것을 지원하거나 또는 점진적인 버전업으로 업데이트 과정에서도 사용자 입장에서 서비스가 정상적으로 동작해야 합니다.
무중단배포 ❌ 예시
- 서비스 업데이트를 하려면 점검 공지를 띄우고 서비스 사용을 막아야 함
- 기존에 돌리던 서버를 멈추고 재구동함 (ex. Recreate Deployment, Hot Reload)
- 일부 배포 과정에서 서버 또는 서비스가 제대로 동작하지 않음 (트래픽 유실 발생)
중요성
위에서 언급한 것처럼 하나의 가벼운 애플리케이션 서버를 구동한다면 업데이트를 위한 빌드, 테스트, 서버 구동까지 시간이 얼마 걸리지 않고 1초, 짧으면 0.5초 끊기는 게 그렇게 중요한지, 사용자가 업데이트하는 순간에 요청을 보낼 확률이 얼마나 될지를 계산할 수 있겠지만 서비스 크기가 대규모가 된다면 서버 재구동을 위한 시간이 1시간 이상이 될 수도 있고 그에 따라 발생하는 손익이 얼마일지 생각해볼 수 있습니다.
무중단배포가 필요하고 중요한만큼 무중단배포는 어떻게 구현하는지는 무중단배포 전략을 알아보며 자세히 이해할 수 있습니다.
무중단배포 전략
Rolling Deployments
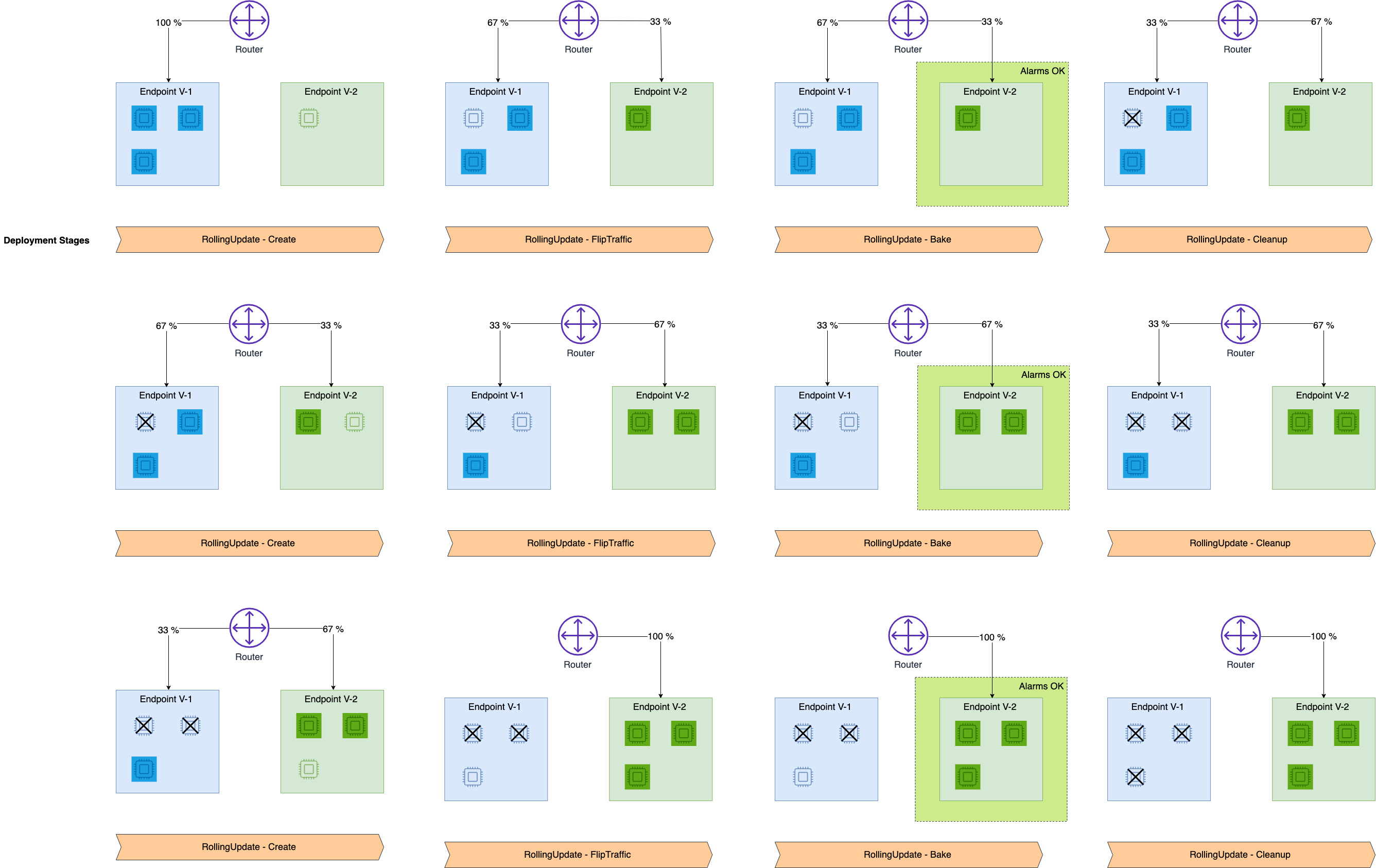
롤링 배포는 기존 배포를 점진적으로 새 배포로 업데이트 하는 방식이며 쿠버네티스에서도 이 방법을 활용힙니다.
새로운 버전의 소프트웨어를 배포하기 위해 새로운 인스턴스를 생성하고 기존 인스턴스를 삭제하기를 반복합니다. 인스턴스가 업그레이드 되면 앞단의 로드밸런서는 다운될 기존 인스턴스로의 라우팅을 끊고 신규 인스턴스로 트래픽을 전환합니다.
롤링 배포는 점진적으로 업데이트하기 때문에 다음 배포로 넘어가기 전에 새 배포가 정상인지 확인하고 비정상일 경우 롤백이 쉽다는 장점이 있습니다. 다른 방식이 다중화에 자원이 많이 필요한 것에 비해 컴퓨팅 자원이 한정적일 때도 적용 가능합니다. 하지만 기존/신규 버전이 모두 운영되기 때문에 호환성 문제가 발생할 수 있습니다.
ex. 1번 서버 다운 + 버전업 신규 인스턴스1 생성 → 버전업 끝나면 2번 서버 다운 + 버전업 신규 인스턴스2 생성 → ... (다운/업데이트 되는 인스턴스의 수 1개 이상 가능)
Surge Deployment
Rolling Deployment가 Surge Deployment를 차용한 것이어서 간단히 롤링 배포가 어떤 개념에서 시작했는지 소개하고자 가져왔습니다.
신규 인스턴스를 생성하면서 동시에 트래픽을 조금씩 신규 인스턴스로 옮기고 신규 인스턴스로 배포, 업데이트가 완료되면 모든 트래픽을 신규 인스턴스로 전환하고 기존 인스턴스로의 트래픽을 차단합니다.
단어 그대로 업데이트와 동시에 급하게 트래픽을 전환하는 방식으로 다운/업데이트를 반복하는 롤링에 비해 기존 인스턴스를 다운시키지 않고 트래픽만 전환하기 때문에 컴퓨팅 자원이 롤링 배포보다 많이 필요합니다.
Blue/Green Deployment
블루-그린 배포에서 블루는 기존 인스턴스, 그린은 신규 인스턴스를 가리킵니다. 트래픽을 한 번에 전환하는 올앳원스 트래픽 시프팅 방식입니다.
블루(기존)와 동일한 환경으로 신규 소프트웨어로 업데이트한 인스턴스를 구성하여 새로운 그린 구성이 끝나면 로드밸런서가 블루로의 트래픽을 한 번에 그린으로 전환합니다.
그린을 구성해서 미리 테스트를 모두 마친 후에 트래픽을 전환할 수 있고 그린이 비정상 동작을 하더라도 블루로 트래픽을 전환하여 빠르게 롤백할 수 있다는 장점이 있습니다. 하지만 운영 환경에 필요한 컴퓨팅 자원의 2배를 준비해야한다는 점이 부담스러울 수 있습니다.

Canary Deployment
옛날 탄광에 카나리 새를 날려보내 돌아오지 않으면 가스 유출을 감지했던 것에서 유래된 배포 방식이며 이전 방식들보다 비교적 복잡해 롤링 배포와 블루-그린 배포를 모두 생각하면 이해하기 쉬울 것 같습니다.
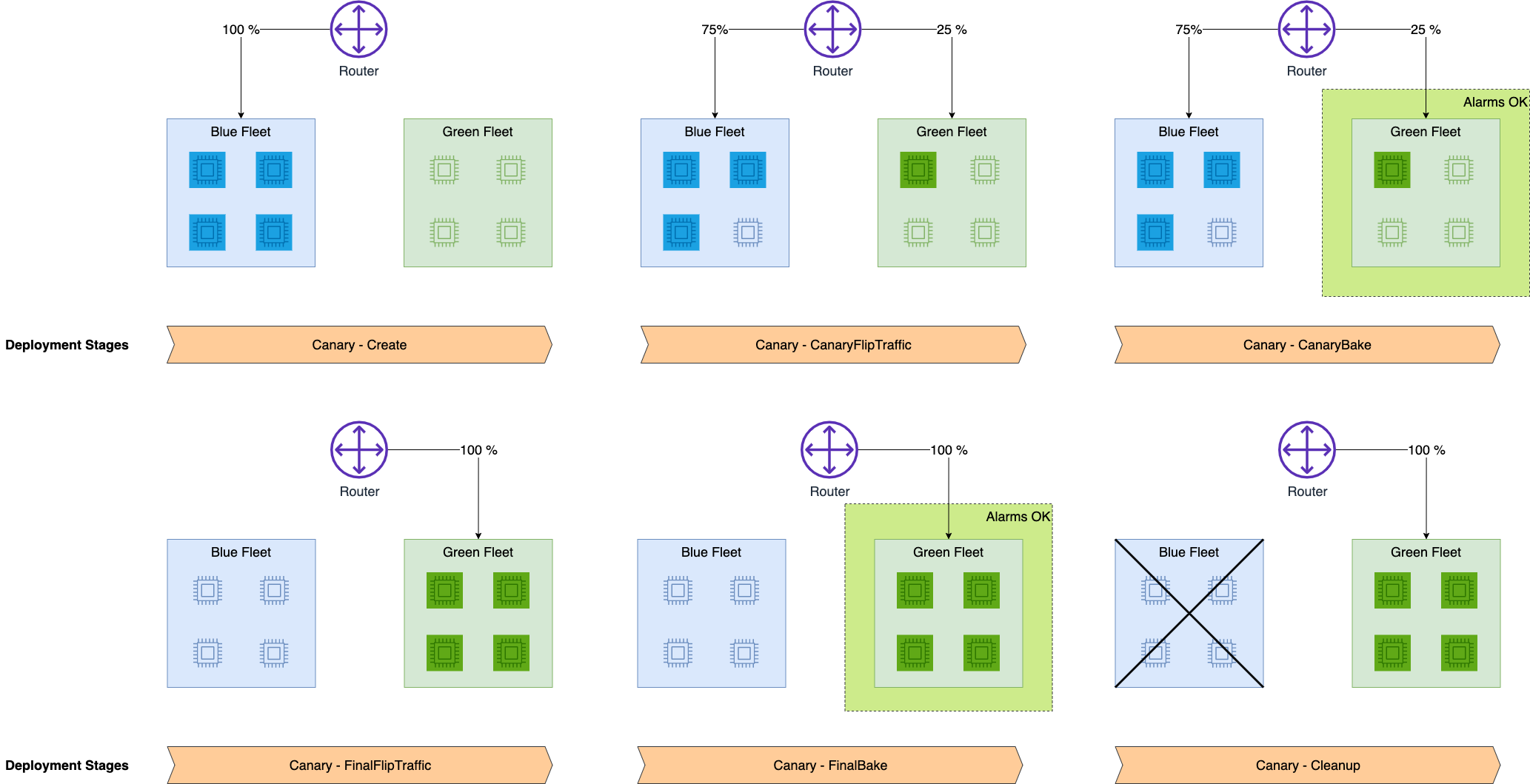
신규 인스턴스로 기존 환경보다 작은 규모로 배포하고 약간의 부하로 테스트하여 메트릭과 모니터링을 통해 일정 수준 이상의 오류가 발생하지 않으면 배포를 계속하고 반대의 경우에는 자동 롤백을 수행하도록 설정합니다.
작은 그린을 구성하여 조금씩 블루→그린으로 트래픽 변경하며 테스트하고 성능/오류를 모니터링하며 배포를 지속할지 결정하는 방식으로 이전 방식보다 더 많은 설정, 코드, 수고가 필요합니다.
신규 배포를 운영과 함께 테스트한다는 점에서 블루-그린 배포와 비슷하고 기존/신규 버전이 동시에 운영되고 점진적으로 트래픽을 전환한다는 점에서 롤링 배포와 유사합니다.
쿠버네티스의 무중단배포 지원
쿠버네티스는 롤링 배포 방식으로 deployment의 pod를 업데이트합니다. deployment.spec.strategy.type 에서 RollingUpdate 설정으로 롤링 배포 방식을 설정할 수 있습니다. 다른 타입은 Recreate로 무중단배포를 지원하지 않고 블루/그린과 카나리 방식은 개별적으로 구현해야합니다.
maxSurge- 새로 생성할 수 있는 인스턴스 백분율/숫자 최댓값maxUnavailable- 사용하지 못하는(다운된) 인스턴스 백분율/숫자 최댓값
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate: # 다운/업데이트 인스턴스 값/백분율 지정
maxSurge: 1
maxUnavailable: 1더하여 Probe를 통한 헬스체크로 롤백을 결정할 수 있도록 합니다.
꽤 오랜 시간동안 생각한 주제를 드디어 글로 정리하고 헷갈릴 때마다 다시 참고할 수 있을 것 같아 후련합니다!
언제나 그렇듯 잘못된 점이 있다면 지적, 조언 부탁드립니다!
출처
[90DaysOfDevOps] Zero Downtime Deployments
[kakao tech] kubernetes를 이용한 서비스 무중단 배포
[Kubernetes] Max Unavailable / Max Surge
사진 출처
[AWS] Amazon SageMaker 롤링 배포
[AWS] Amazon SageMaker 올앳원스 트래픽 시프팅
[AWS] Amazon SageMaker 캐너리 트래픽 시프팅
