해당 알고리즘을 이해 하기전 자료구조 그래프 개념을 숙지하기 바란다.
DFS와 BFS는 탐색 알고리즘의 일종이다.
이 알고리즘을 가지고 그래프의 모든 노드를 방문할 수 있다.
DFS
DFS (Depth-First Search) '깊이 우선 탐색'이라고도 하며 그래프에서 깊은 부분을 우선으로 탐색하는 알고리즘이다.
스택을 이용하여 구현한다.
동작과정
글
① 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
② 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
③ 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
방문하지 않은 인접한 노드가 여러 개일 경우 크기가 가장 작은 수를 스택에 넣는다.
그림
#0
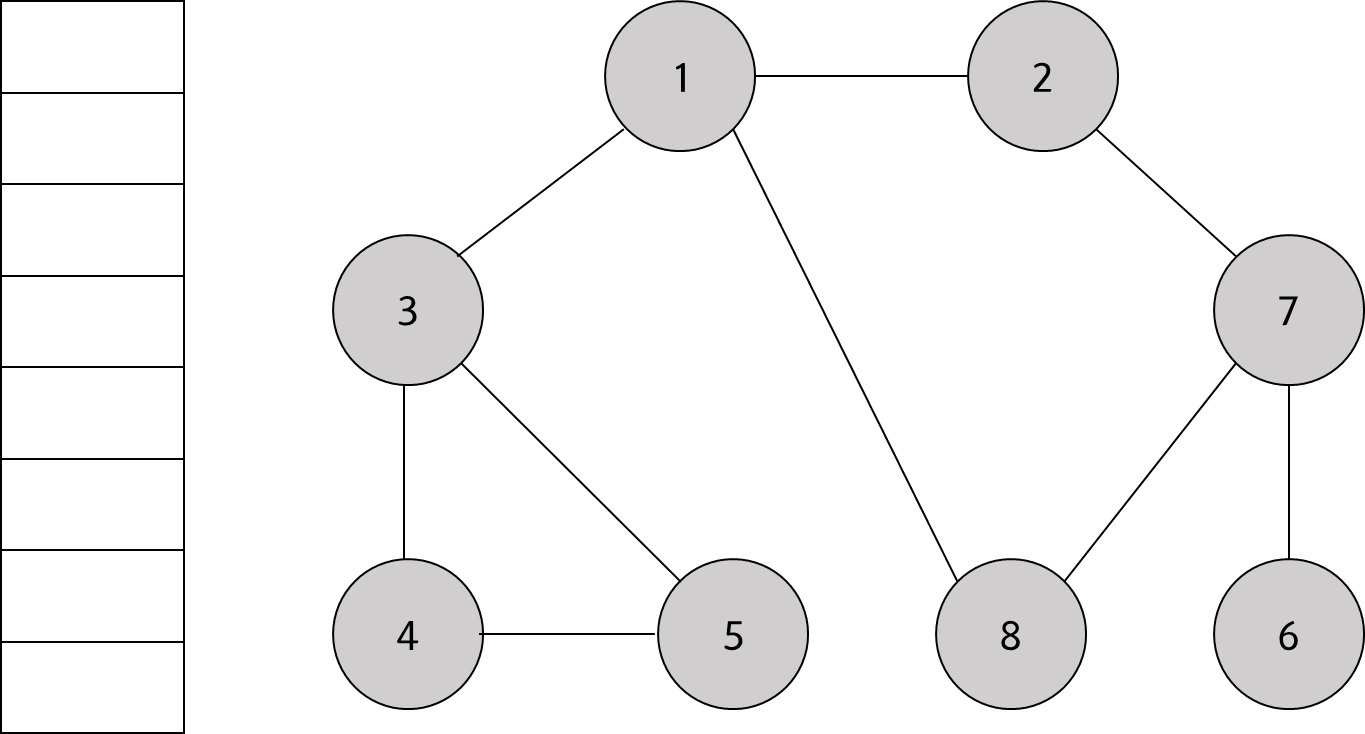
아래 그래프를 가지고 DFS 동작과정을 설명하겠다.
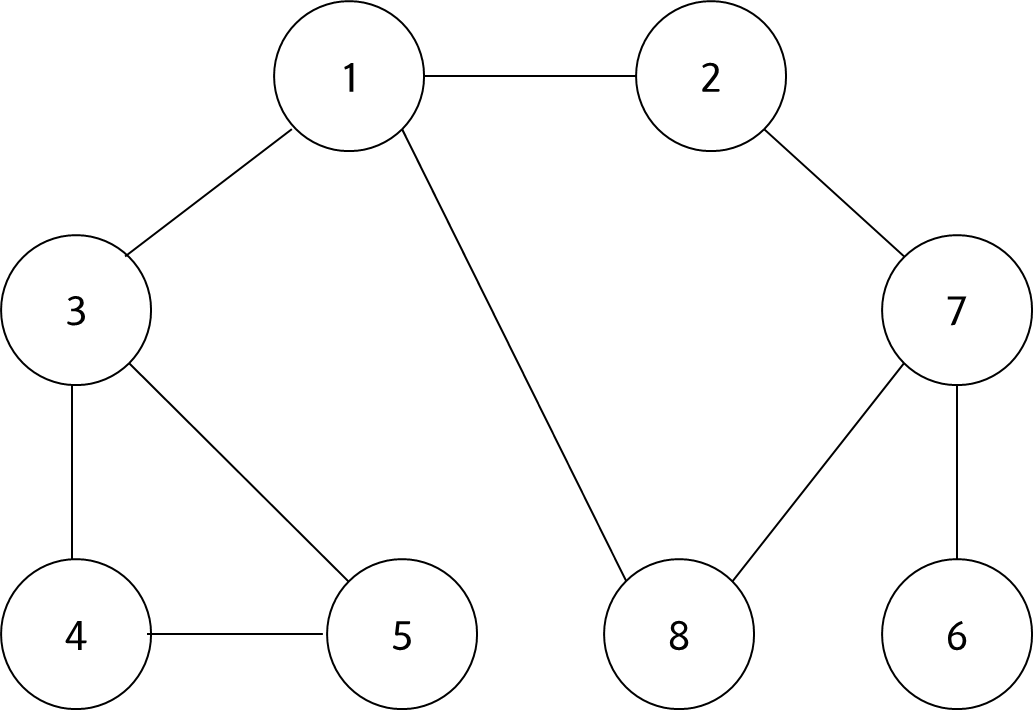
#1
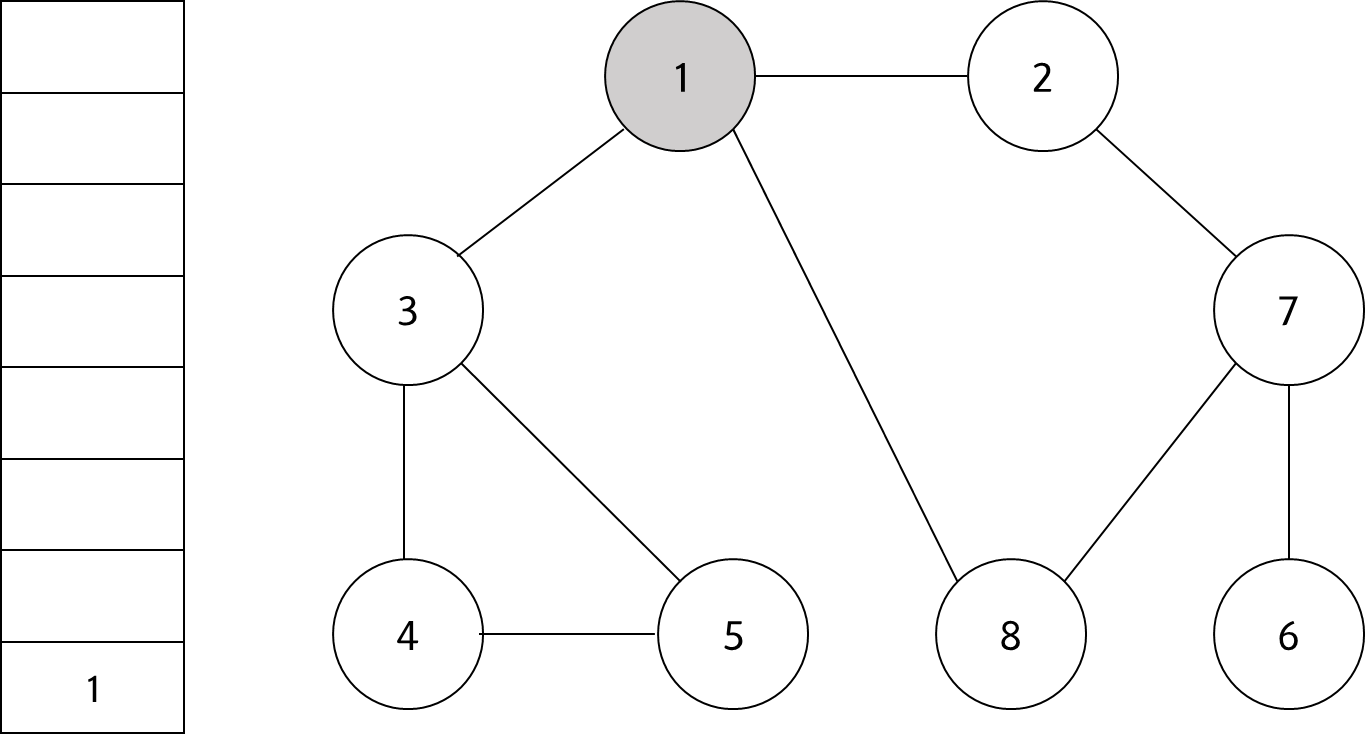
시작 노드인 '1'을 스택에 삽입하고 방문 처리 한다.
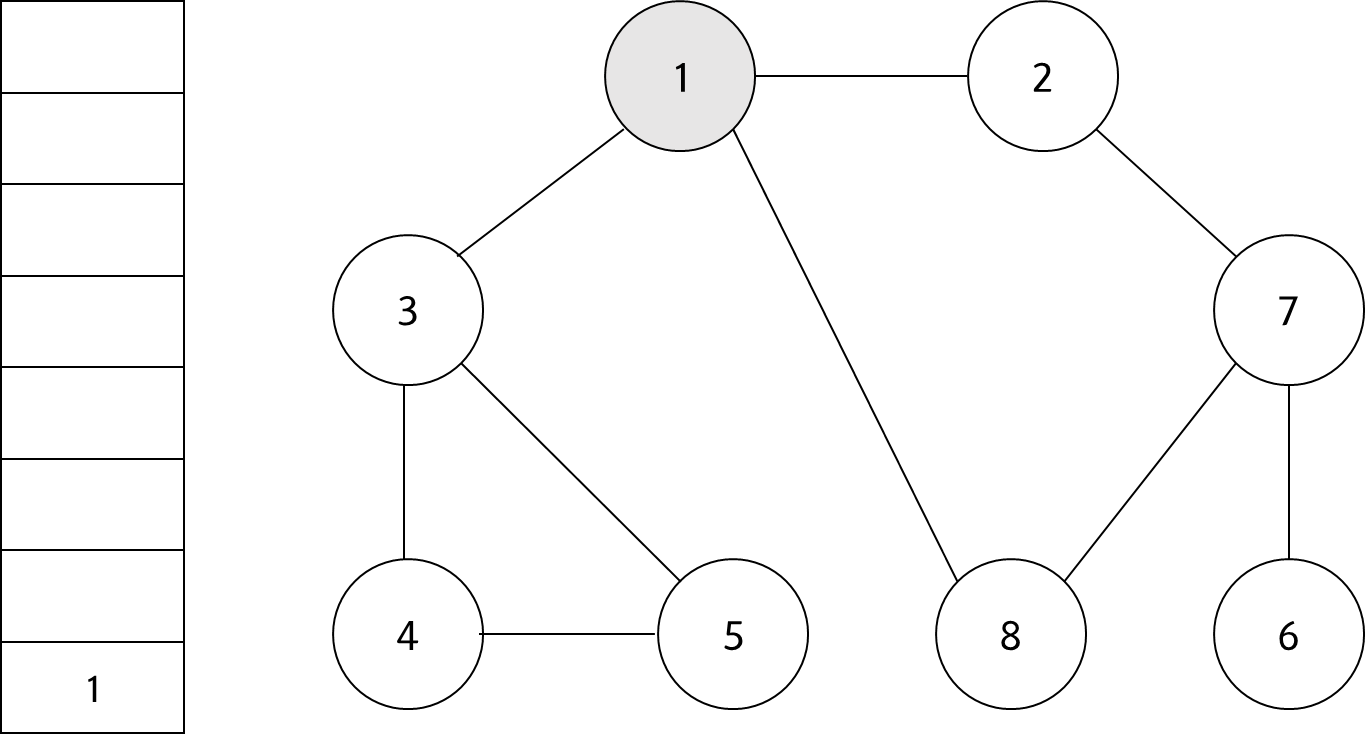
#2
스택의 최상단 노드인 '1'에 방문하지 않은 인접 노드 '2', '3', '8'이 있다. 이 중에서 가장 작은 노드인 '2'를 스택에 넣고 방문 처리를 한다.
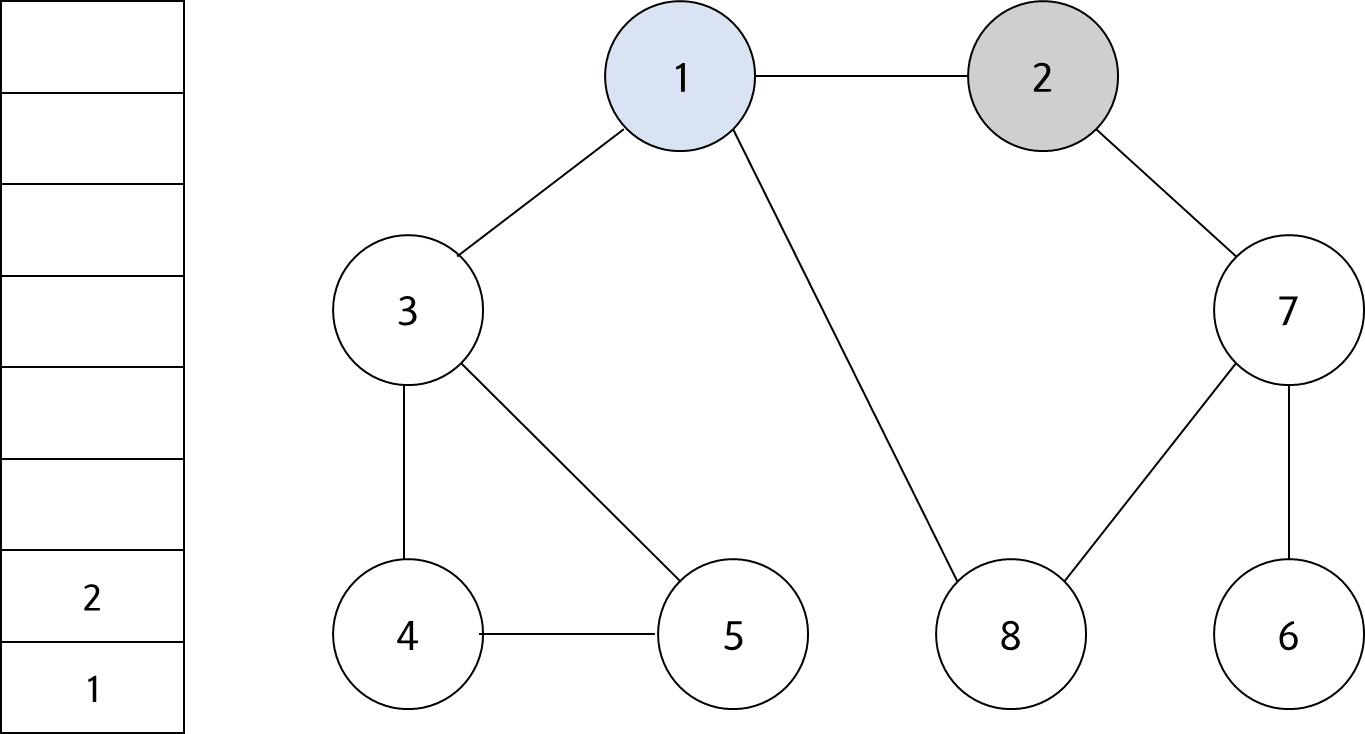
#3
스택의 최상단 노드인 '2'에 방문하지 않은 인접 노드 '7'이 있다. 따라서 '7'번 노드를 스택에 넣고 방문 처리를 한다.
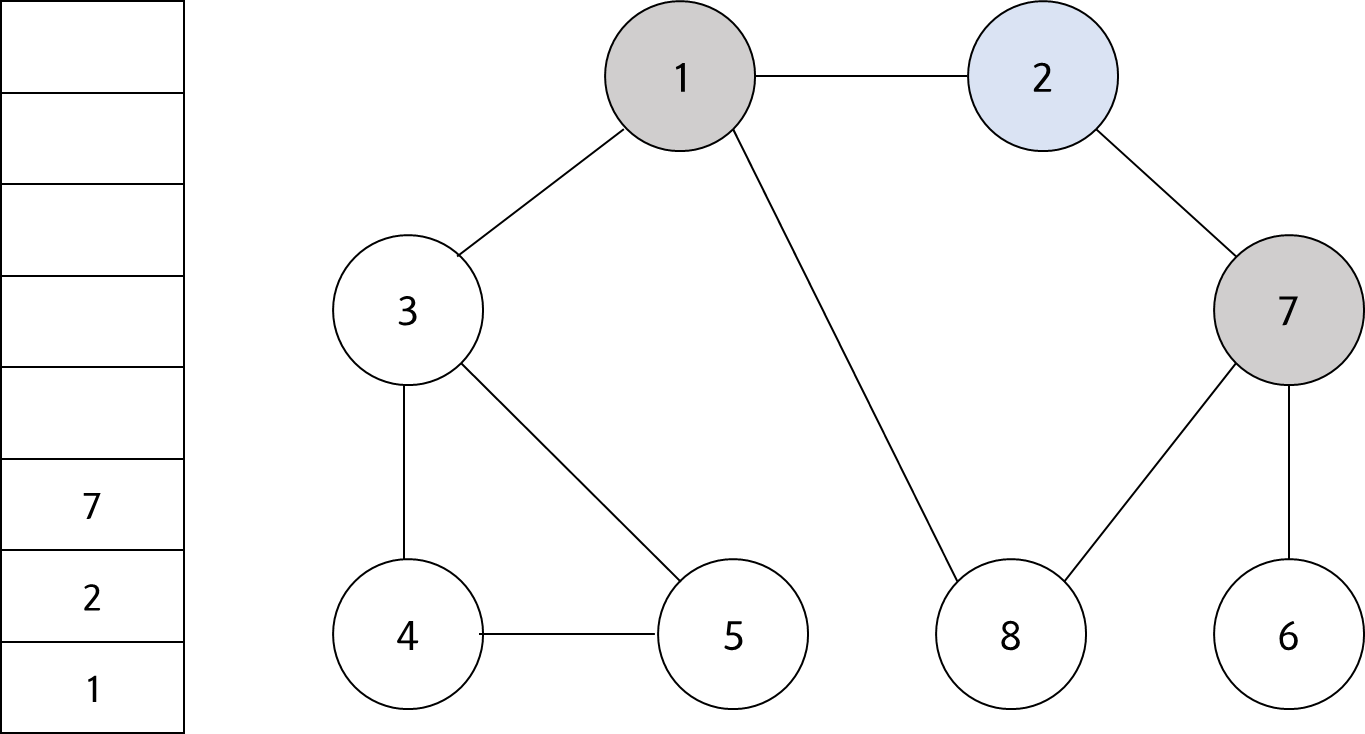
#4
스택의 최상단 노드인 '7'에 방문하지 않은 인접 노드 '6'과 '8'이 있다. 이 중에서 가장 작은 노드인 '6'을 스택에 넣고 방문 처리를 한다.
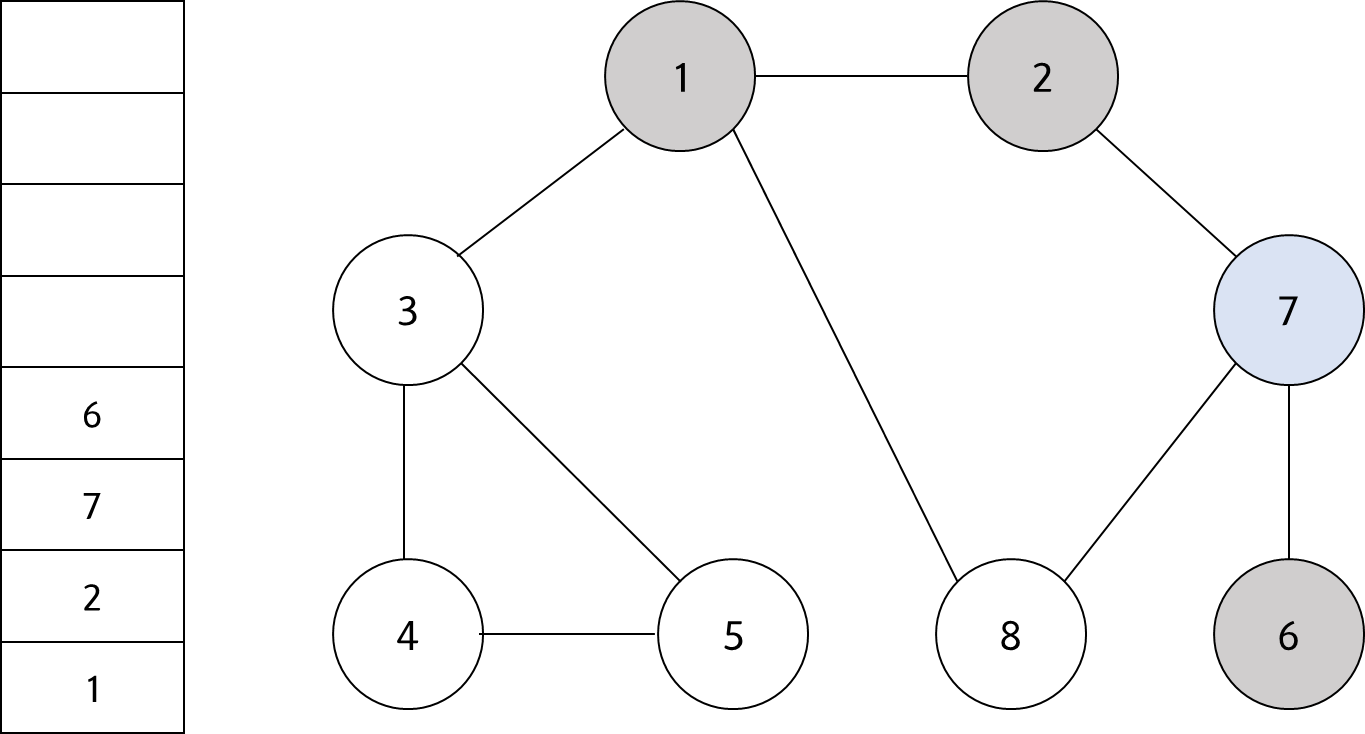
#5
스택의 최상단 노드인 '6'에 방문하지 않은 인접 노드가 없다. 따라서 스택에서 '6'번 노드를 꺼낸다.
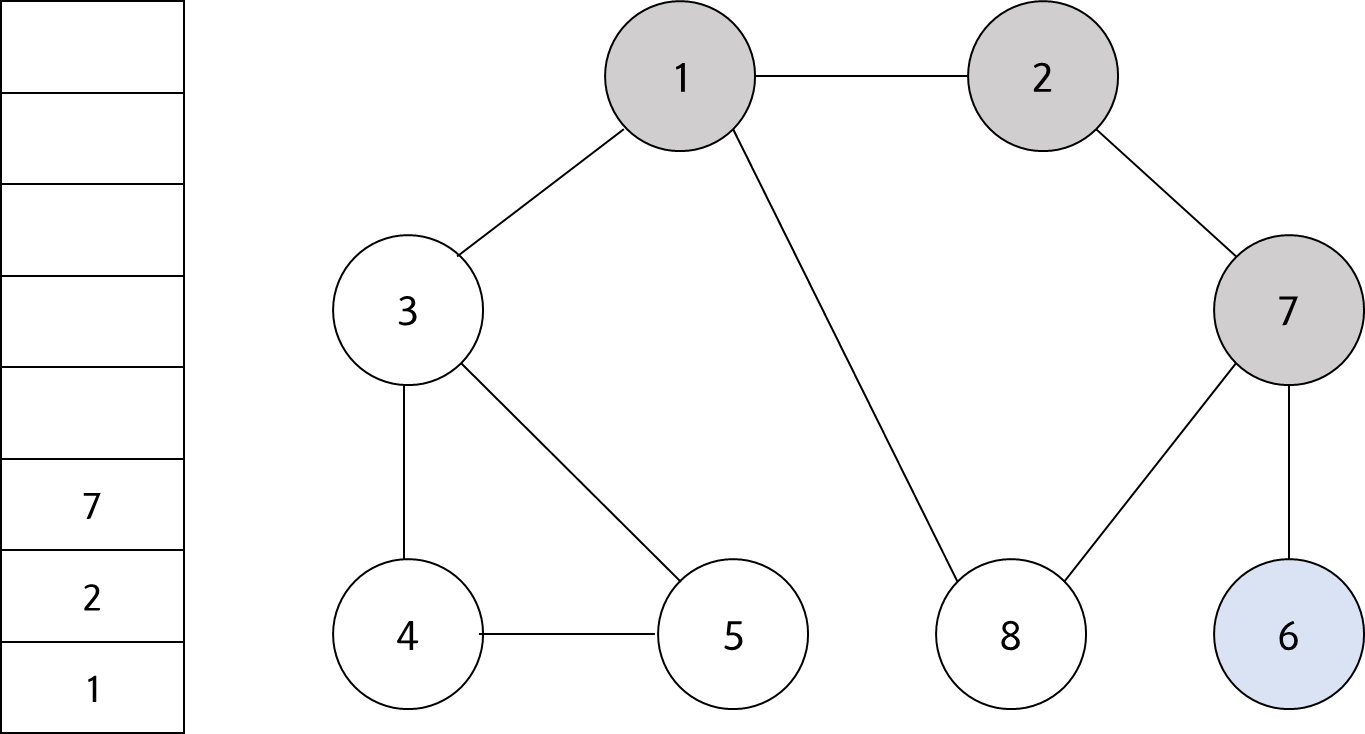
#6
스택의 최상단 노드인 '7'에 방문하지 않은 인접 노드 '8'이 있다. 따라서 '8'번 노드를 스택에 넣고 방문처리를 한다.
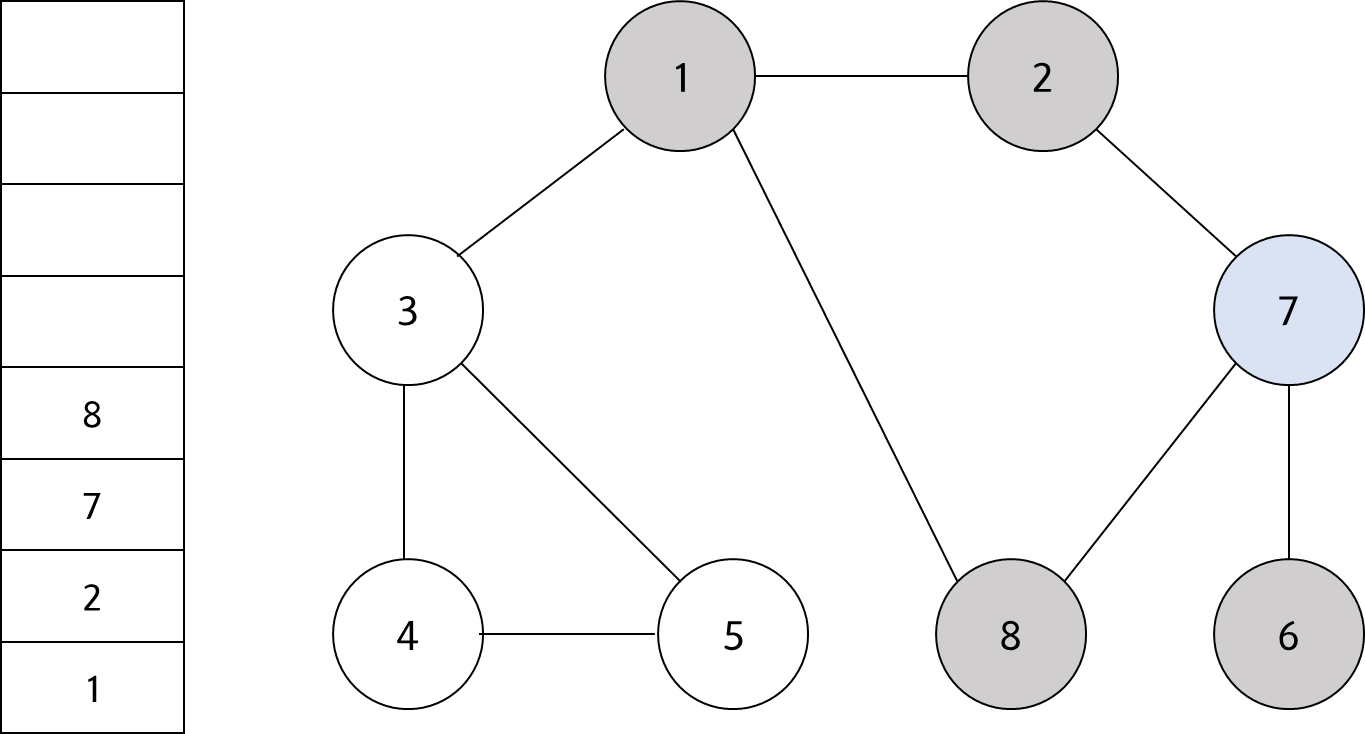
#7
스택의 최상단 노드인 '8'에 방문하지 않은 인접 노드가 없다. 따라서 스택에서 '8'번 노드를 꺼낸다.
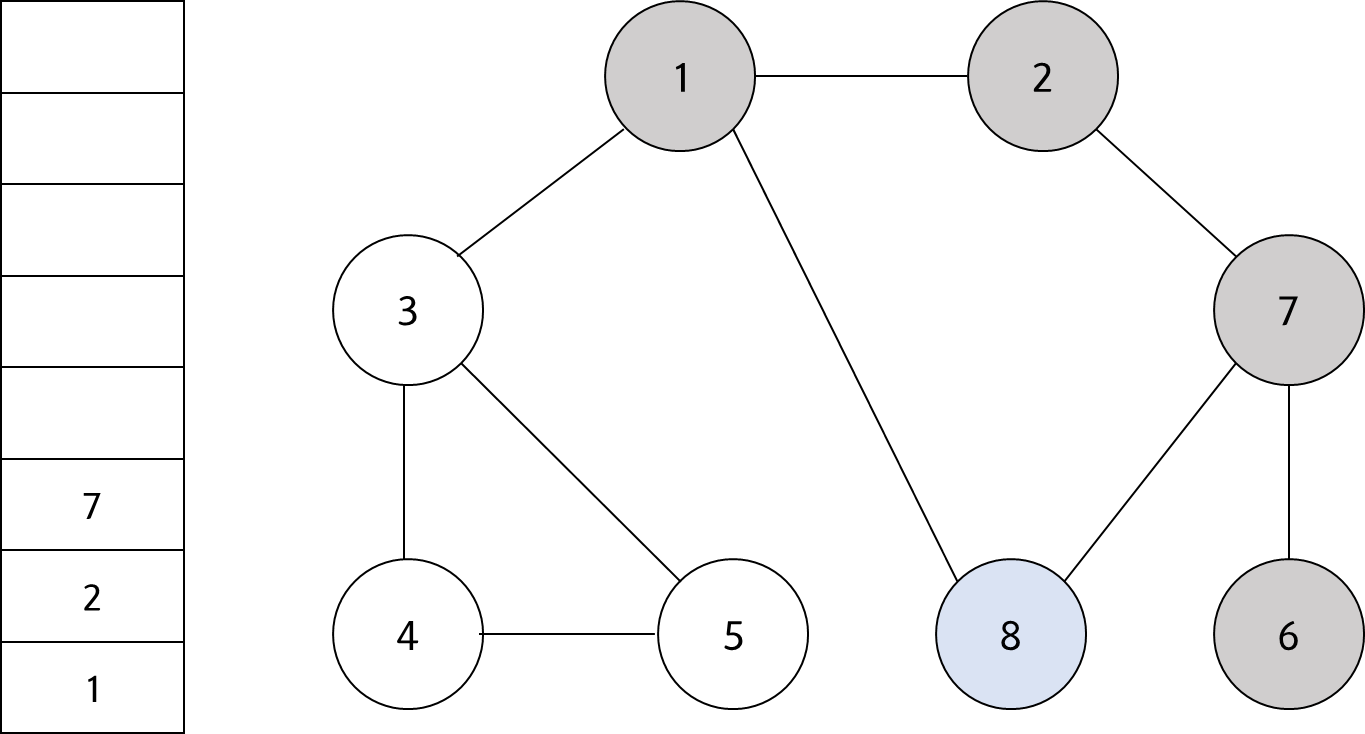
#8
스택의 최상단 노드인 '7'에 방문하지 않은 인접 노드가 ㅇ벗다. 따라서 스택에서 '7'번 노드를 꺼낸다.
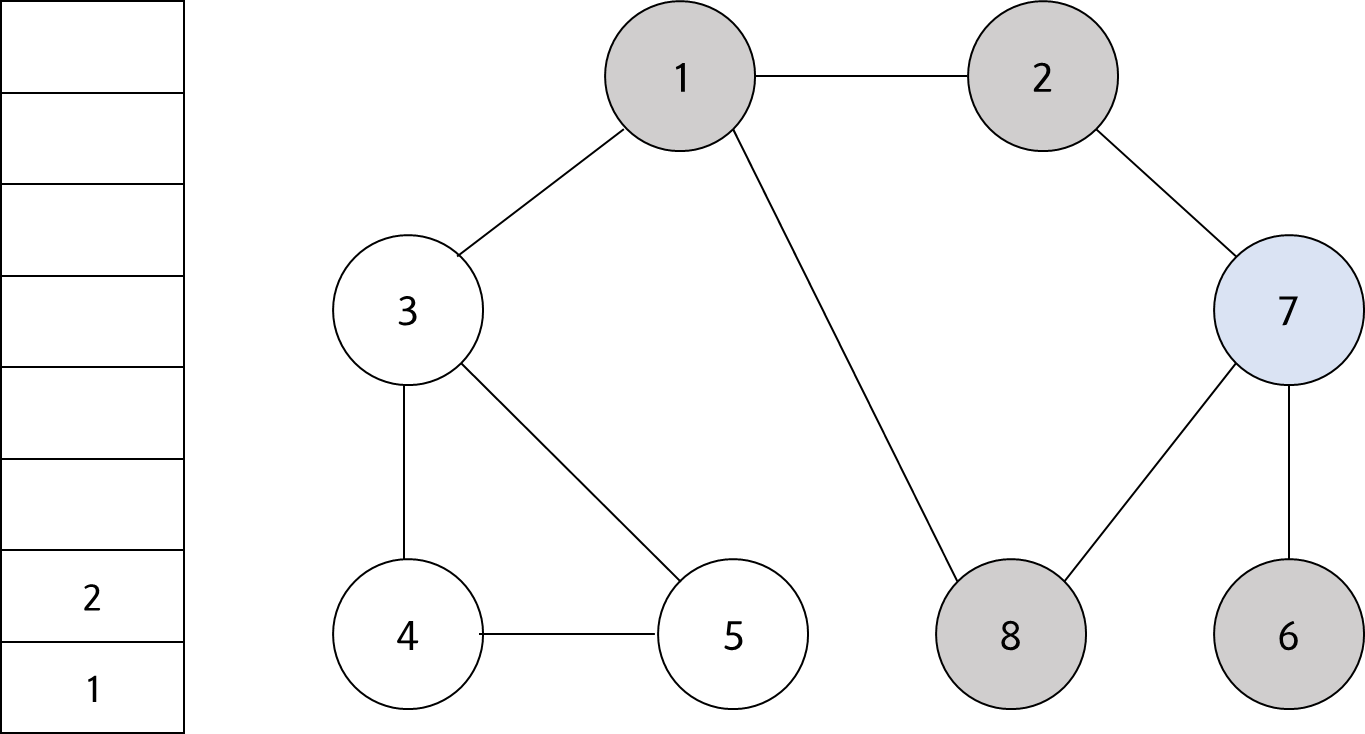
#9
스택의 최상단 노드인 '2'에 방문하지 않은 인접 노드가 없다. 따라서 스택에서 '2'번 노드를 꺼낸다.
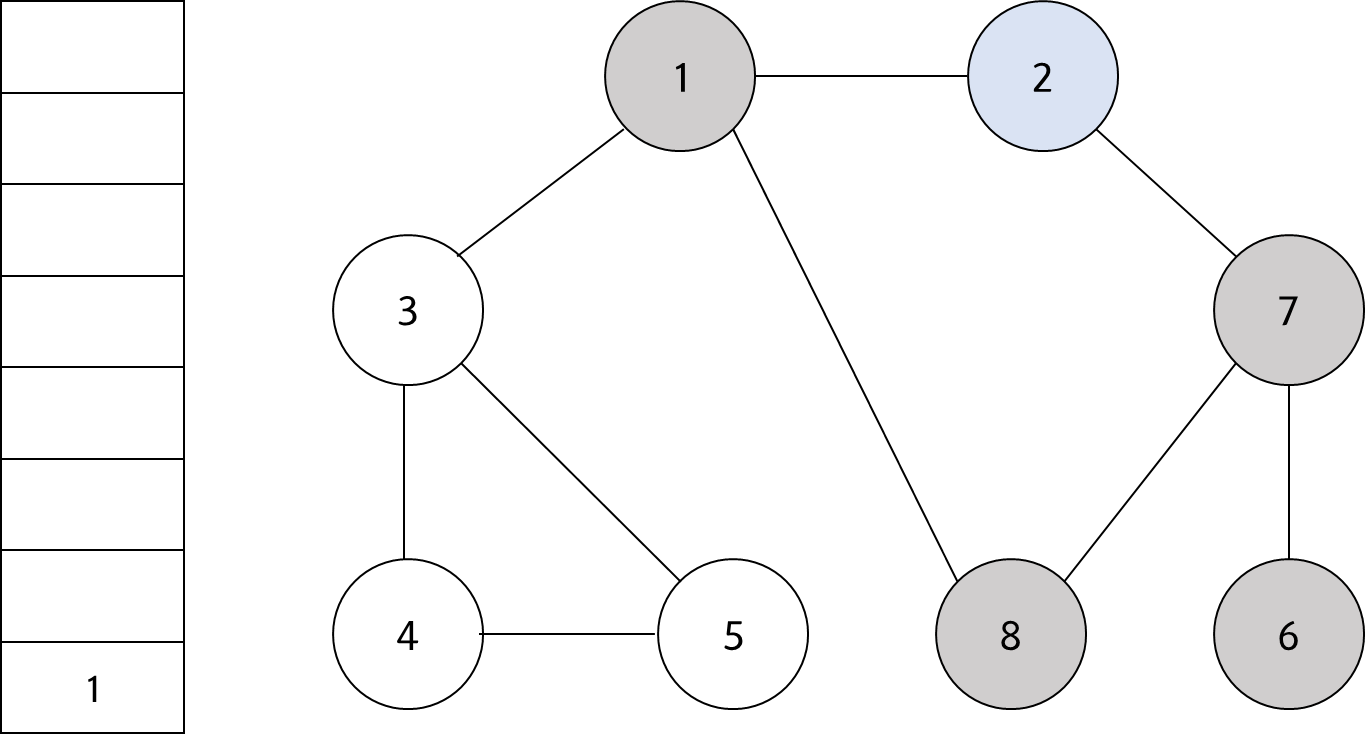
#10
스택의 최상단 노드인 '1'에 방문하지 않은 인접 노드 '3'을 스택에 넣고 방문처리한다.
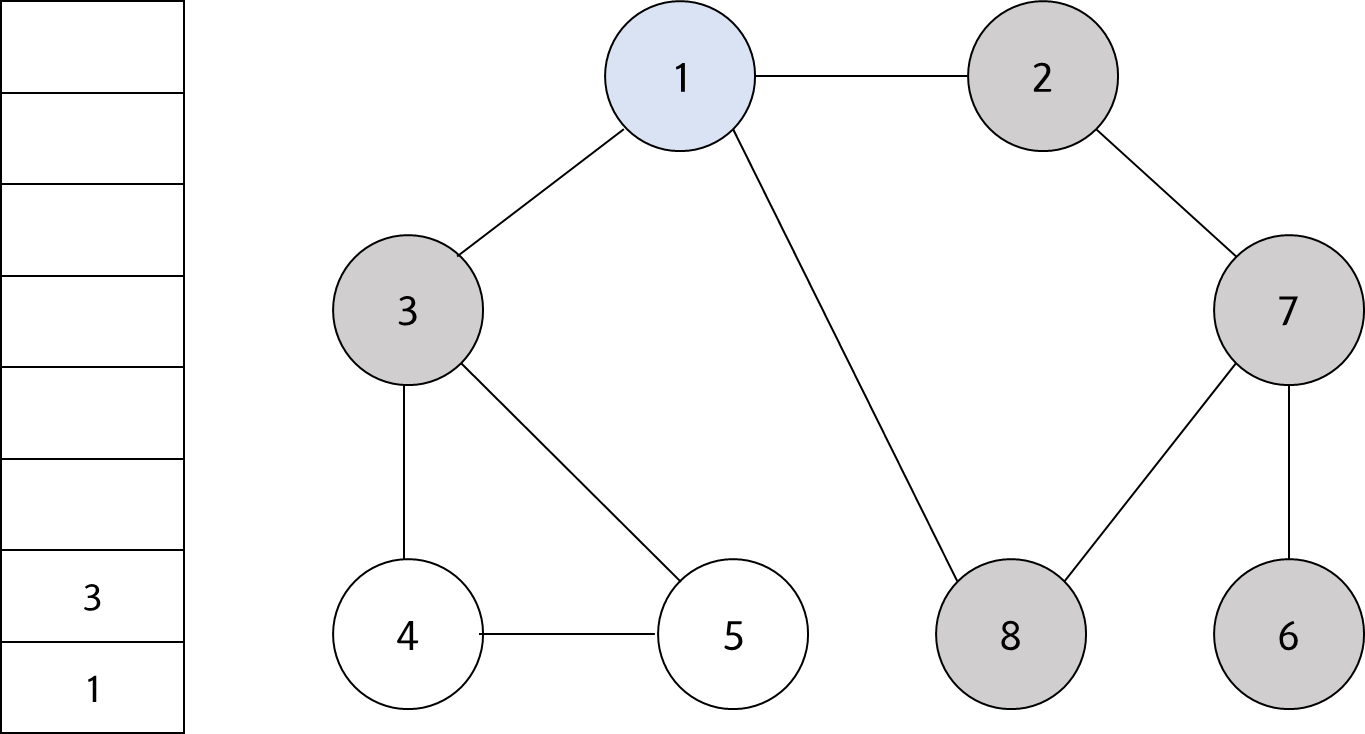
#11
스택의 최상단 노드인 '3'에 방문하지 않은 인접 노드 '4'와 '5'가 있다. 이 중에서 가장 작은 노드인 '4'를 스택에 넣고 방문 처리를 한다.
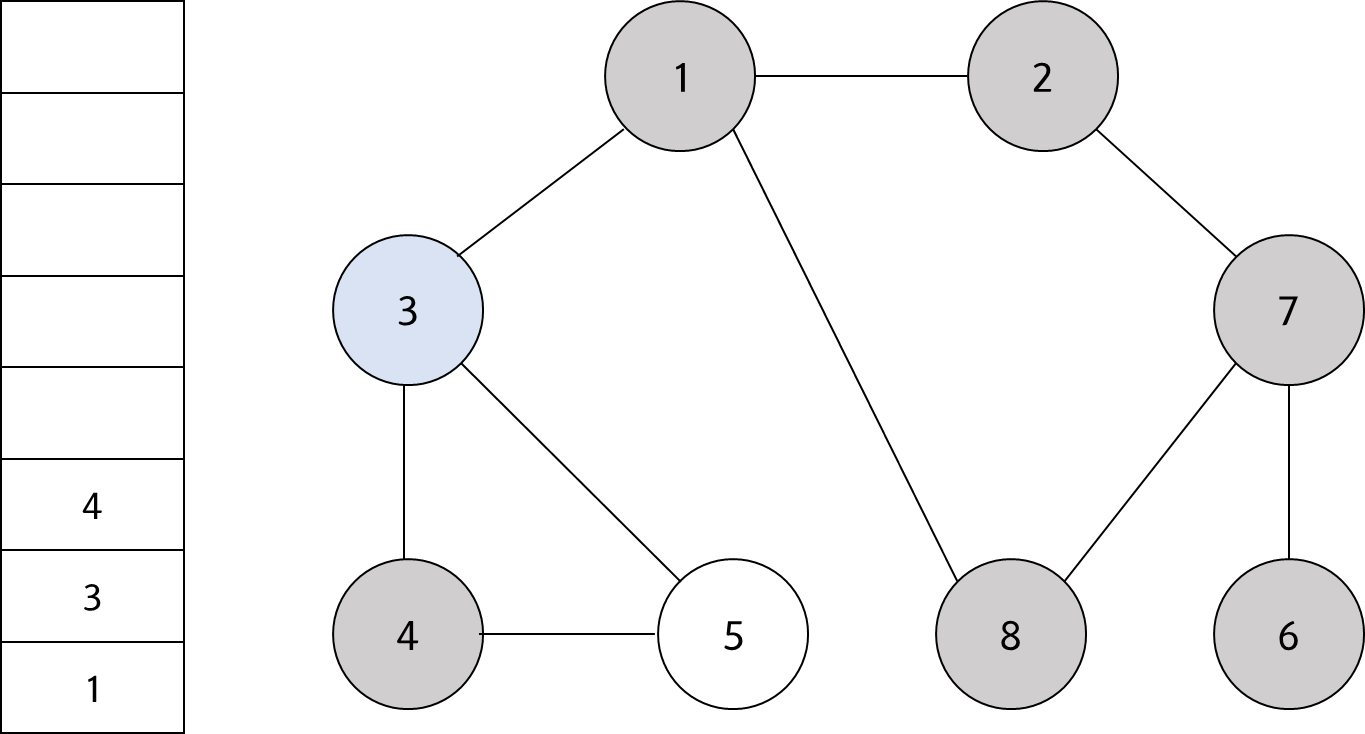
#12
스택의 최상단 노드인 '4'에 방문하지 않은 인접 노드 '5'가 있다. 따라서 '5'번 노드를 스택에 넣고 방문 처리를 한다.
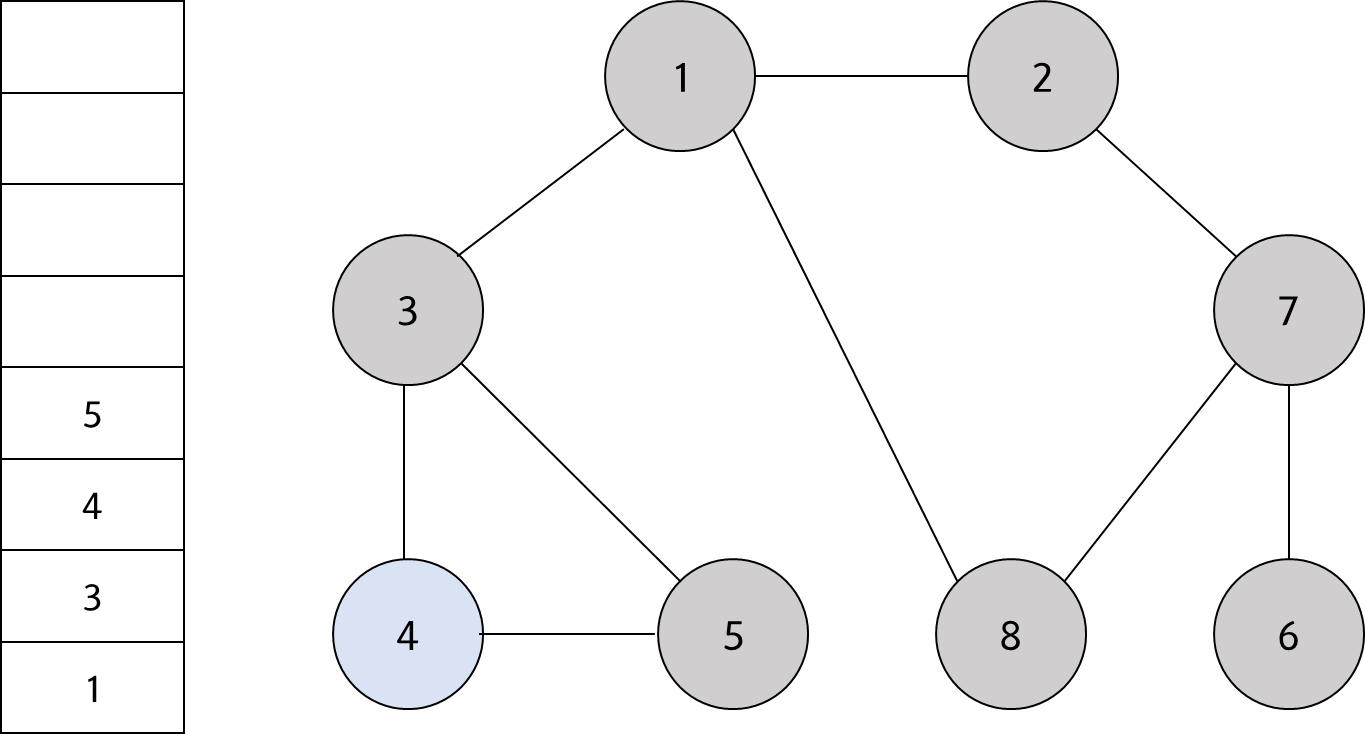
#13
스택에 남아 있는 노드중에 방문하지 않은 인접 노드가 없다. 따라서 모든 노드를 차례대로 꺼내면 다음과 같다.
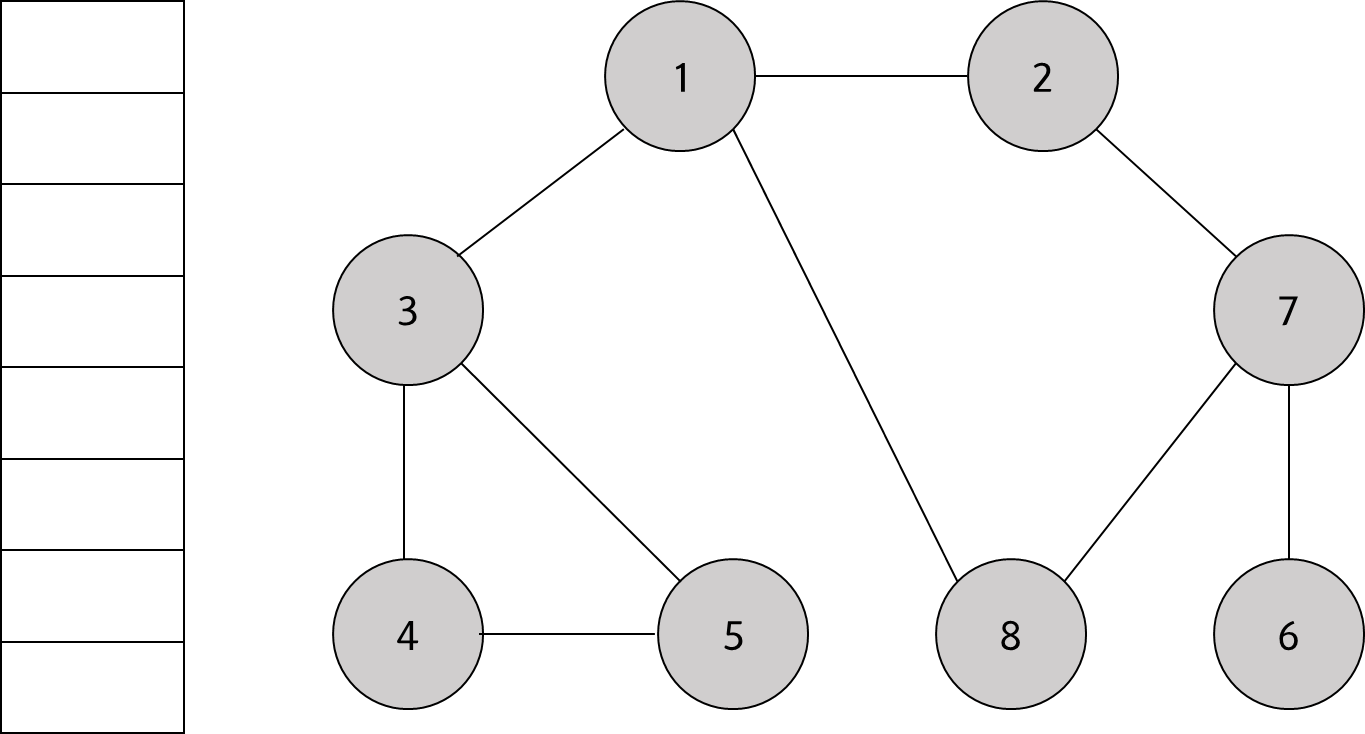
이렇게 그래프를 DFS를 사용하여 방문하면
1 → 2 → 3 → 8 → 7 → 4 → 5 → 6
순서로 모두 탐색할 수 있다.
시간 복잡도
N개의 데이터일 경우 O(N) 만큼 소요된다.
코드
DFS는 스택을 이요하는 알고리즘이기 때문에 실제 구현은 재귀 함수를 이용하여 구현 가능하다.
# DFS 메서드 정의
def dfs(graph, v, visited):
# 현재 노드를 방문 처리
visited[v] = True
print(v, end=' ')
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
# 첫 요소는 인덱스를 1번부터 사용하기 위해 비워두었다.
# 리스트의 인덱스가 노드 번호이며 요소 속 데이터가 해당 노드와 연결된 노드 들이다.
graph = [
[],
[2,3,8], # 1번 노드 | 2,3,8 노드와 연결됨
[1,7], # 2번 노드 | 1,7 노드와 연결됨
[1,4,5], # 3번 노드 | 1,4,5 노드와 연결됨
[3,5], # 4번 노드 | 3,5 노드와 연결됨
[3,4], # 5번 노드 | 3,4 노드와 연결됨
[7], # 6번 노드 | 7 노드와 연결됨
[2,6,8], # 7번 노드 | 2,6,8 노드와 연결됨
[1,7] # 8번 노드 | 1,7 노드와 연결됨
]
# 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
# 인덱스를 1번 부터 사용하기 위해 요소가 1개 더 많은 9개이다.
visited = [False] * 9
# 정의된 DFS 함수 호출
dfs(graph, 1, visited)1 2 7 6 8 3 4 5BFS
BFS (Breadth-First Search) '너비 우선 탐색'이라고도 하며 그래프에서 가까운 부분을 우선으로 탐색하는 알고리즘이다.
큐를 이용하여 구현한다.
동작과정
글
① 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
② 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
③ 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
방문하지 않은 인접한 노드가 여러 개일 경우 크기가 가장 작은 순서대로 큐에 삽입한다.
그림
#0
아래 그래프를 가지고 DFS 동작과정을 설명하겠다.
#1
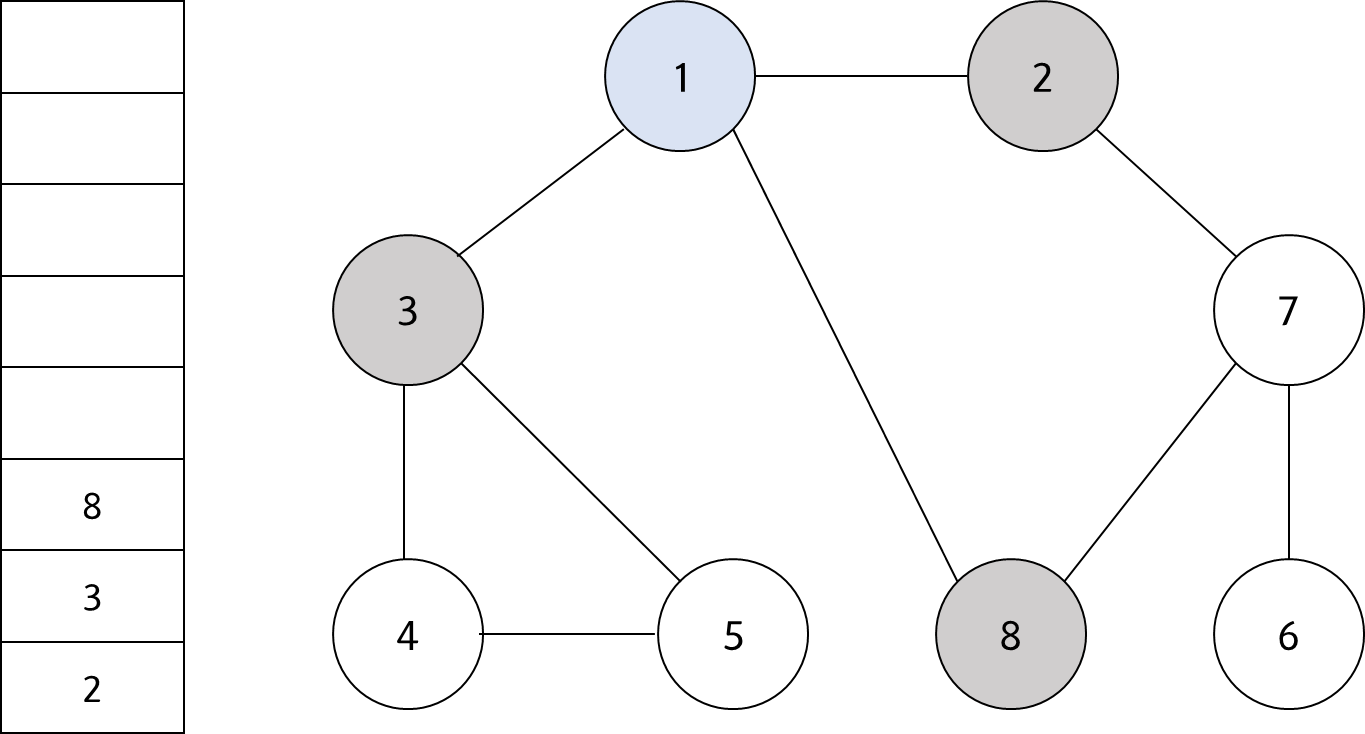
시작 노드인 '1'을 큐에 삽입하고 방문 처리를 한다. 방문 처리된 노드는 회색으로, 큐에서 꺼내 현재 처리하는 노드는 하늘색으로 표현했다.
#2
큐에서 '1'을 꺼내고 방문하지 않은 인접 노드 '2', '3', '8'을 모두 큐에 삽입하고 방문 처리한다.
#3
큐에서 노드 '2'를 꺼내고 방문하지 않은 인접 노드 '7'을 큐에 삽입하고 방문 처리를 한다.
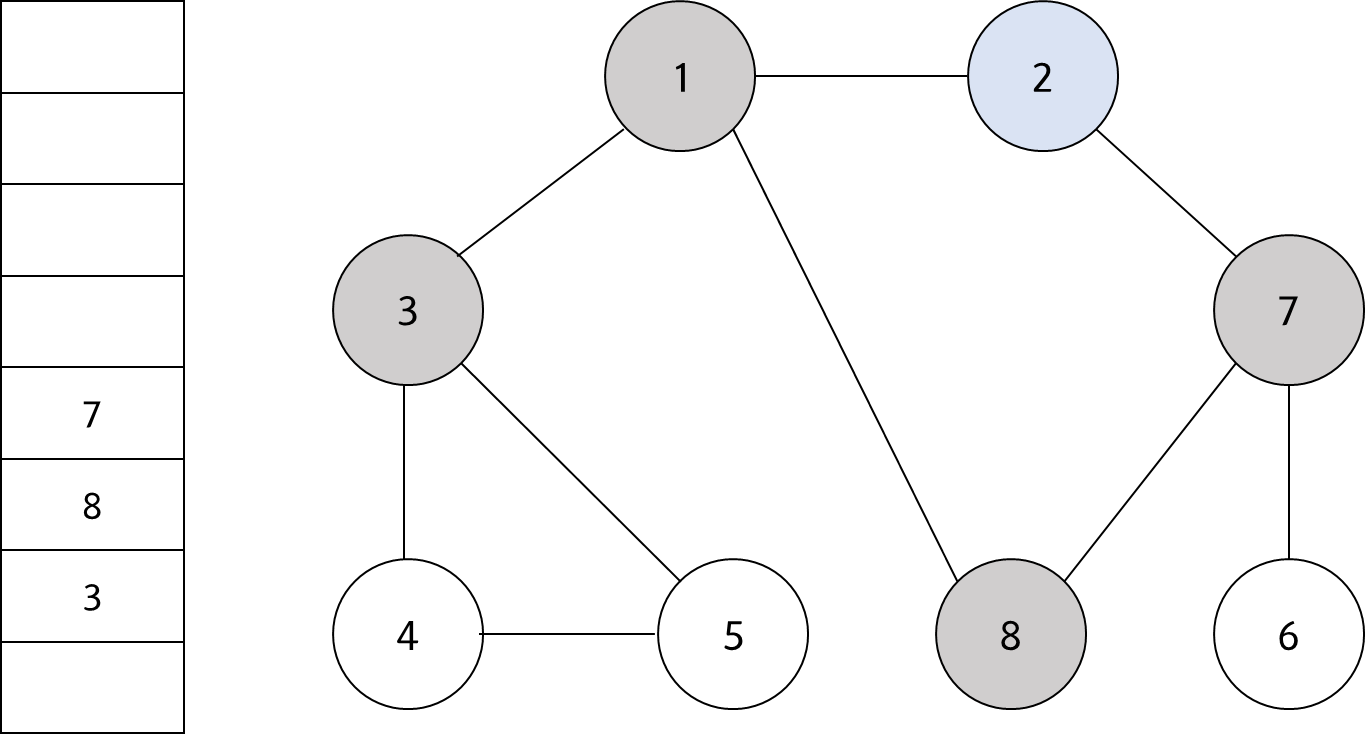
#4
큐에서 노드 '3'을 꺼내고 방문하지 않은 인접 노드 '4'와 '5'를 모두 큐에 삽입하고 방문 처리를 한다.
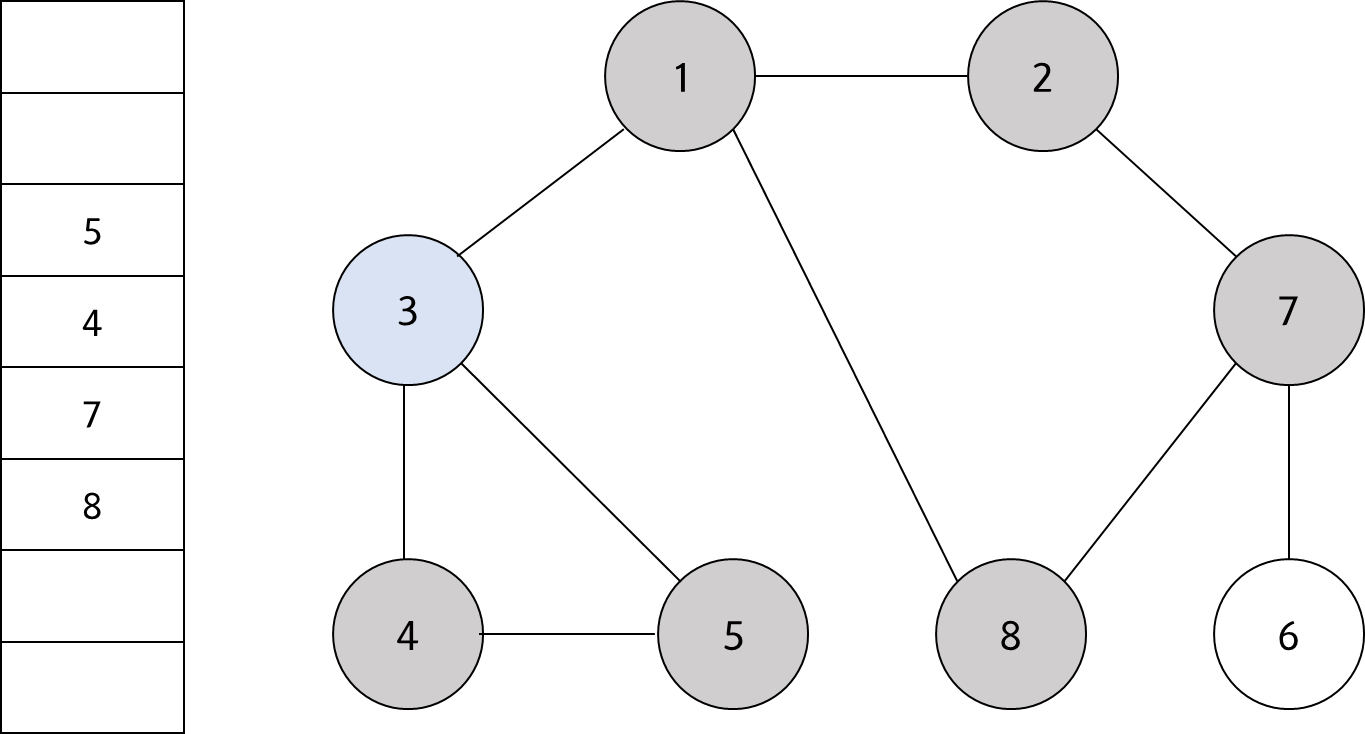
#5
큐에서 노드 '8'을 꺼내고 방문하지 않은 인접 노드가 없으므로 무시한다.
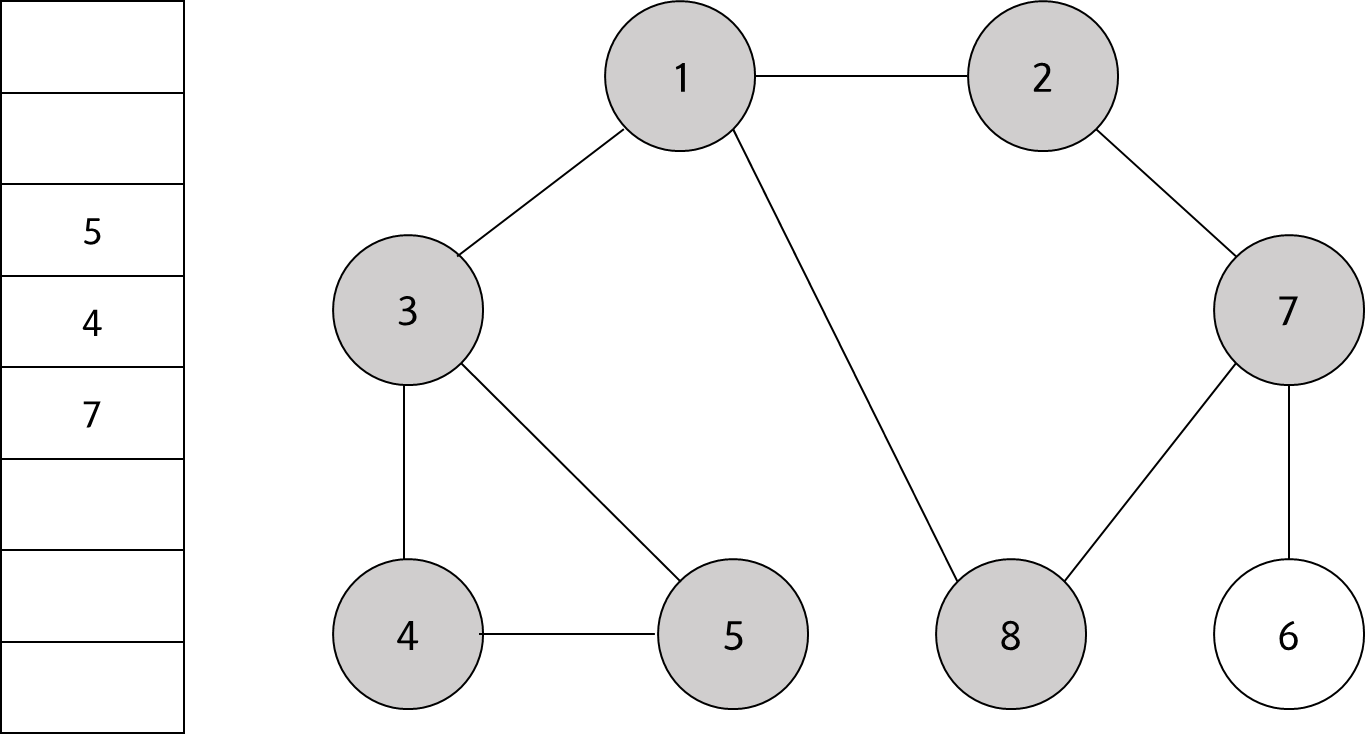
#6
큐에서 노드 '7'을 꺼내고 방문하지 않은 인접 노드 '6'을 큐에 삽입하고 방문 처리를 한다.
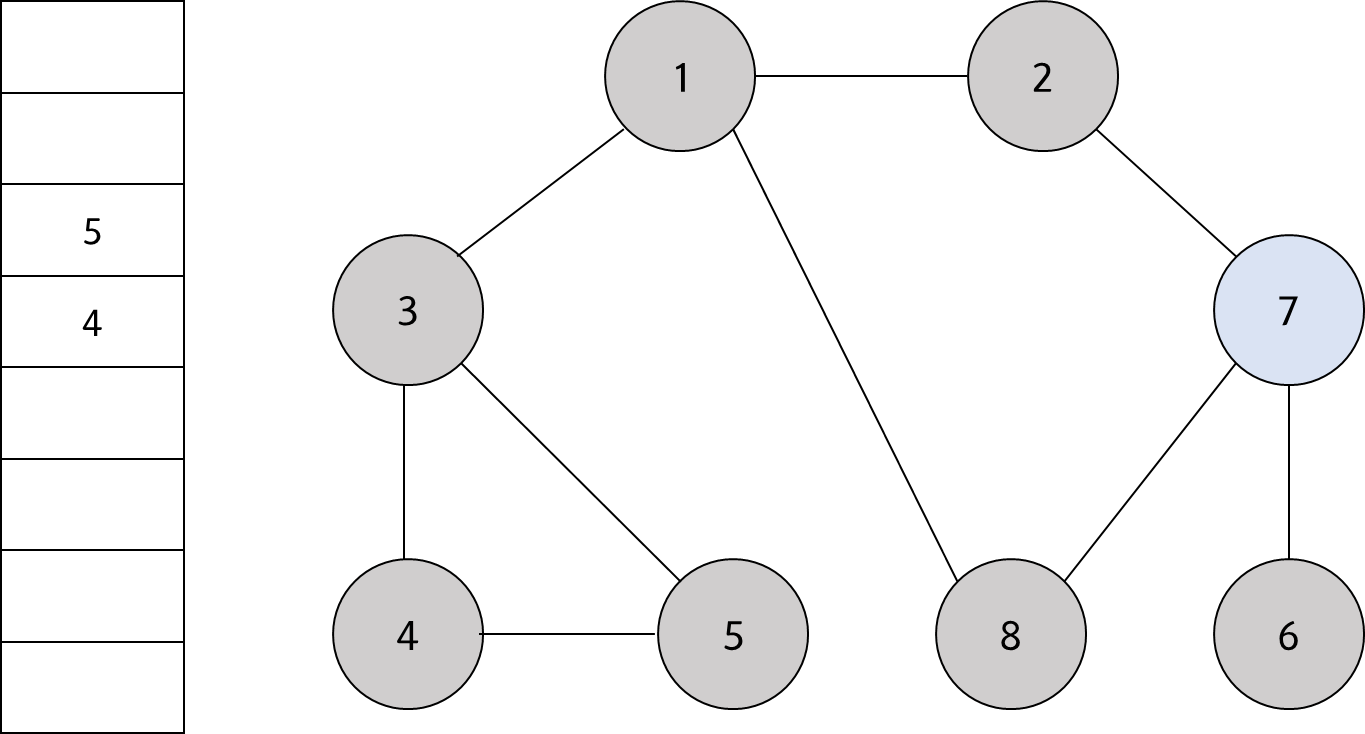
#7
남아 있는 노드에 방문하지 않은 인접 노드가 없다. 따라서 모든 노드를 차례대로 꺼내면 최종적으로 다음과 같다.
이렇게 그래프를 BFS를 사용하여 방문하면
1 → 2 → 7 → 6 → 8 → 3 → 4 → 5
순서로 모두 탐색할 수 있다.
시간 복잡도
N개의 데이터일 경우 O(N) 만큼 소요된다.
코드
from collections import deque
# BFS 메서드 정의
def bfs(graph, start, visited):
# 큐(Queue) 구현을 위해 deque 라이브러리 사용
queue = deque([start])
# 현재 노드를 방문 처리
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
# 큐에서 하나의 원소를 뽑아 출력'
v = queue.popleft()
print(v, end=' ')
# 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
# 첫 요소는 인덱스를 1번부터 사용하기 위해 비워두었다.
# 리스트의 인덱스가 노드 번호이며 요소 속 데이터가 해당 노드와 연결된 노드 들이다.
graph = [
[],
[2,3,8], # 1번 노드 | 2,3,8 노드와 연결됨
[1,7], # 2번 노드 | 1,7 노드와 연결됨
[1,4,5], # 3번 노드 | 1,4,5 노드와 연결됨
[3,5], # 4번 노드 | 3,5 노드와 연결됨
[3,4], # 5번 노드 | 3,4 노드와 연결됨
[7], # 6번 노드 | 7 노드와 연결됨
[2,6,8], # 7번 노드 | 2,6,8 노드와 연결됨
[1,7] # 8번 노드 | 1,7 노드와 연결됨
]
# 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
# 인덱스를 1번 부터 사용하기 위해 요소가 1개 더 많은 9개이다.
visited = [False] * 9
# 정의된 bFS 함수 호출
bfs(graph, 1, visited)1 2 3 8 7 4 5 6BFS DFS 비교
진행방법
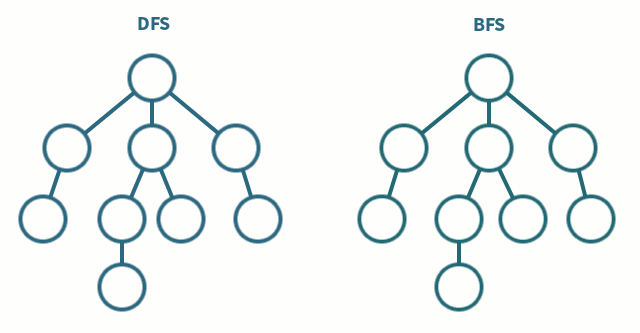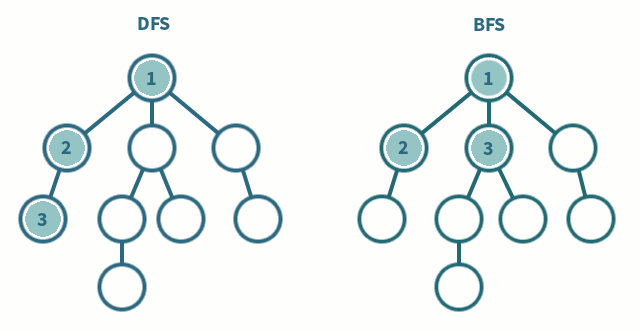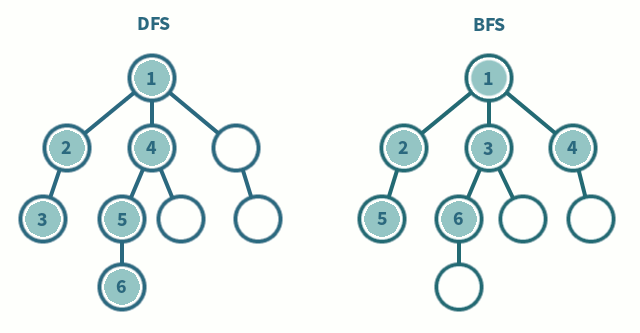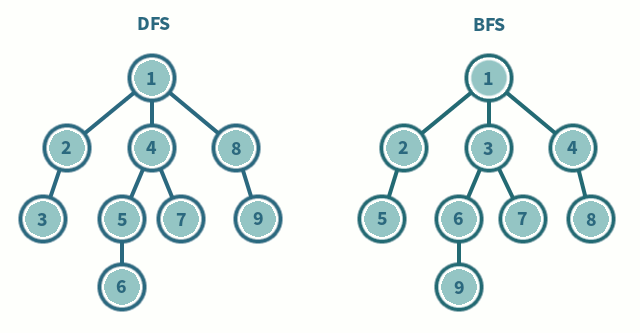
DFS - 하나의 정점에서 최대한 깊게 내려간 다음 정점으로 넘어간다.
BFS - 현재 정점에서 가장 가까운 정점으로 넘어간다.
비유하자면 각 10단원씩 있는 국어, 영어, 수학 시험 공부를 할 때
DFS는 국어를 10단원까지 완벽히 마스터 한다음에 영어 공부를 시작하고,
BFS는 국어, 영어, 수학을 1단원을 공부한 뒤 다시 국어, 영어, 수학 2단원을 공부하는 것으로 표현할 수 있다.
속도
속도는 BFS가 더 빠르다. 그러나 각 알고리즘 문제 마다 알맞는 역할이 있다.
활용 방법
- 그래프의 모든 정점을 방문하는 것이 중요한 문제 → DFS, BFS
- 경로의 특징을 저장해둬야 하는 문제 → DFS
- 최단거리 구해야 하는 문제 → BFS
- 검색 대상 그래프가 정말 클 때 → DFS, (BFS)
- 검색대상의 규모가 크지 않고, 검색 시작 지점으로부터 원하는 대상이 별로 멀지 않다면 → BFS, (DFS)
참고자료
이것이 취업을 위하 코딩 테스트다 with 파이썬 - 나동빈
너비우선탐색 - 나무위키
DFS, BFS의 설명, 차이점 - lucky-korma
