
! 오랜만에 돌아온 알고리즘 공부... 빡세게 해야지
1. 최단 경로 알고리즘
가장 짧은 경로를 찾는 알고리즘
보통 '길 찾기'에 많이 사용하는 알고리즘 이다.
최단 경로 알고리즘의 경우 보통 그래프로 표현하는데 각 지점은 그래프에서 노드로 표현되고, 지점 간 연결된 도로는 그래프에서 간선으로 표현된다.
주로 많이 사용 되는 최단 경로 알고리즘에는 밑에 3개가 있다.
- 다익스트라 최단 경로 알고리즘
- 플로이드 워셜
- 벨만 포드
2. 다익스트라 최단 경로 알고리즘
그래프에서 여러 개의 노드가 있을 때, 특정한 노드에서 출발하여 다른 노드로 가는 각각의 최단 경로를 구해주는 알고리즘
중요한 점은 음의 간선이 없을 때 정상적으로 동작한다.
- 음의 간선 : 0보다 작은 값을 가지는 간선
현실 세계에서의 길은 음의 간선으로 표현되지 않기 때문에 다익스트라 알고리즘은 실제로 GPS 소프트웨어의 기본 알고리즘은 채택 되곤 한다.
1) 원리 및 과정
- 출발 노드를 설정
- 최단 거리 테이블을 초기화
- 방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 선택
- 해당 노드를 거쳐 다른 노드로 가는 비용을 계산하여 최단 거리 테이블을 갱신
- 3번과 4번을 반복!!
중요한 점은 '각 노드에 대한 현재까지의 최단 거리'정보를 항상 1차원 리스트에 저장하며 리스트를 계속 갱신한다!!
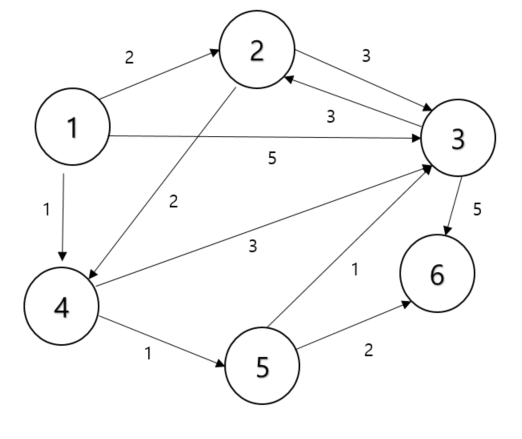
다음과 같은 예시에서 출발 노드는 1이다.
초기 상태에서 다른 모든 노드로 가는 최단 거리를 '무한'으로 초기화 한다.
이때 1e9라는 실수 자료형으로 처리한다.
-
방문하지 않은 노드 중에서 최단 거리가 짧은 노드를 선택하는데, 출발 노드에서 출발 노드로의 거리는 0으로 본다.
노드번호 1 2 3 4 5 6 거리 0 무한 무한 무한 무한 무한
-
다음으로 1번 노드에서 다른 노드로 가는 비용을 계산한다. 즉 1번 노드와 연결된 모든 간선을 하나씩 확인한뒤 테이블을 갱신한다.
노드번호 1 2 3 4 5 6 거리 0 2 5 1 무한 무한
-
다음 단계에서 최단 거리가 가장 짧은 노드를 선택하는데 여기서는
4 가 당첨!! 4에서 갈 수 있는 노드인 3번과 5번 까지의 거리를 구하고 표를 다시 갱신한다.노드번호 1 2 3 4 5 6 거리 0 2 4 1 2 무한
-
다음 에서는 2번 노드가 선택된다.(거리가 같을 경우 일반적으로 번호가 작은 노드를 선택) 이전 단계와 동일한 방법을 반복한다.
노드번호 1 2 3 4 5 6 거리 0 2 4 1 2 무한
-
결국 마지막의 테이블의 최종 갱신본은 다음과 같다.
노드번호 1 2 3 4 5 6 거리 0 2 3 1 2 4
이 테이블이 의미하는 바는 1번 노드로 출발했을 때 2번, 3번, 4번, 5번, 6번 노드까지 가기 위한 최단 경로가 각각 2,3,1,2,4라는 의미다.
2) 코드 구현
코드 구현을 위해서는 힙 자료구조를 사용한다.
힙 자료구조는 우선순위 큐를 구현하기 위하여 사용하는 자료구조중 하나인데 우선순위 큐는 우선순위가 가장 높은 데이터를 가장 먼저 삭제한다는 점이 특징이다.
이 우선순위 큐를 사용하기 위해서 파이썬에는 heapq 라이브러리를 사용한다.
우선 순위 큐에서는 (가치, 값)으로 구성되며 가치가 낮은 데이터가 먼저 삭제되는 최소 힙, 가치가 높은 데이터가 먼저 삭제되는 최대 힙을 이용할 수 있다.
다익스트라 알고리즘을 구현할 때에도 이 우선순위 큐를 활용한다. 원리는 위의 설명과 동일하고 거리와 노드를 넣을 때 (거리, 노드)의 튜플을 활용한다.
import heapq
import sys
input = sys.stdin.readline
INF = int(1e9) #무한을 의미하는 값
#노드의 개수, 간선 개수 입력받기
n,m = map(int, input().split())
#시작 노드 번호 입력
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트 만들기
graph = [[] for i in range(n+1)]
#최단 거리 테이블 모두 무한으로 초기화
distance = [INF] * (n+1)
#모든 간선 정보 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
#a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b,c))
def djkstra(start):
q = []
heapq.heappush(q,(0, start))
distance[start] = 0
while q:
#가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
dist, now = heapq.heappop(q)
# 현재 노드가 이미 처리된 적이 있는 노드라면 무시
if distance[now] < dist:
continue
#현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = dist + i[1]
#현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[i[0]]:
distance[i[0]] = cost
heapq.heappush(q, (cost, i[0]))
dikstra(start)
for i in range(1, n+1):
if distance[i] == INF:
print("infinite")
else:
print(distance[i])