
본 프로젝트는 Spring Boot와 MySQL을 활용한 기록 프로젝트 입니다.
해당 글은 기록 프로젝트 진행 중, 애플리케이션 서버의 단일 장애점(SPOF) 문제와 CI/CD 과정에서의 전체 서비스 중단 위험 등을 해결하기 위해 선택한 기술적 접근 방식에 대해 설명합니다.
[요약]
초기 인프라는 애플리케이션 서버가 SPOF 문제가 존재하며 CI/CD 과정에서 전체 서비스 중단 위험이 있었으나, Active-Active 서버 이중화, AWS ALB 도입, DB Replication 등을 통해 안정성과 가용성을 개선하였습니다.
또한, CI/CD 과정에서 발생한 서비스 중단 문제를 해결하기 위해 Blue-Green 무중단 배포 전략과 포트 스위칭, 롤백 전략을 도입하여 트리거 기반 무중단 배포 환경을 구축하였습니다.
[인프라 개선 과정]
[초기 인프라]
초기 단계에서 인프라 아키텍처 구조는 아래와 같았습니다
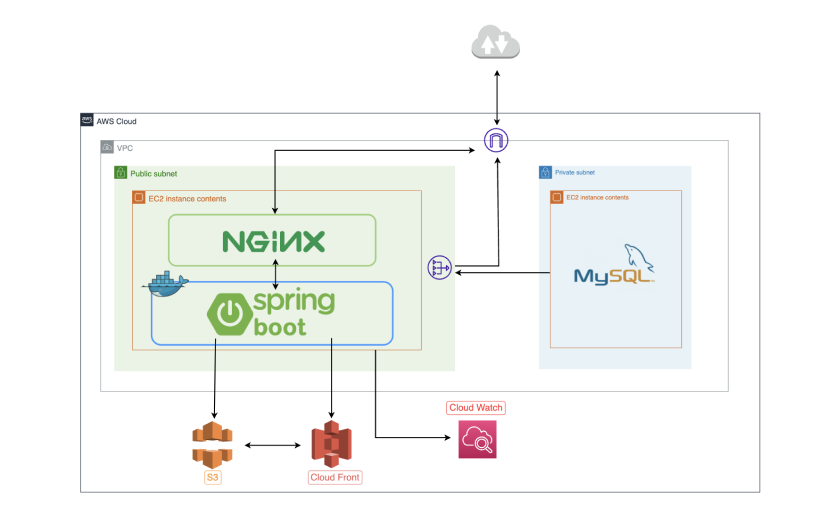
이러한 구조는 두 가지 주요 문제를 야기했습니다.
첫째, 애플리케이션 서버가 외부 공격에 직접적으로 노출되어 보안에 취약합니다.
둘째, 단일 장애점(SPOF)이 존재하여 애플리케이션 서버에 장애가 발생하면 전체 서비스가 중단됩니다.
이러한 문제점을 해결하고자 안정성과 가용성이 향상된 새로운 인프라 아키텍처를 도입했습니다.
[SPOF 문제를 개선한 인프라 (Active-Active)]
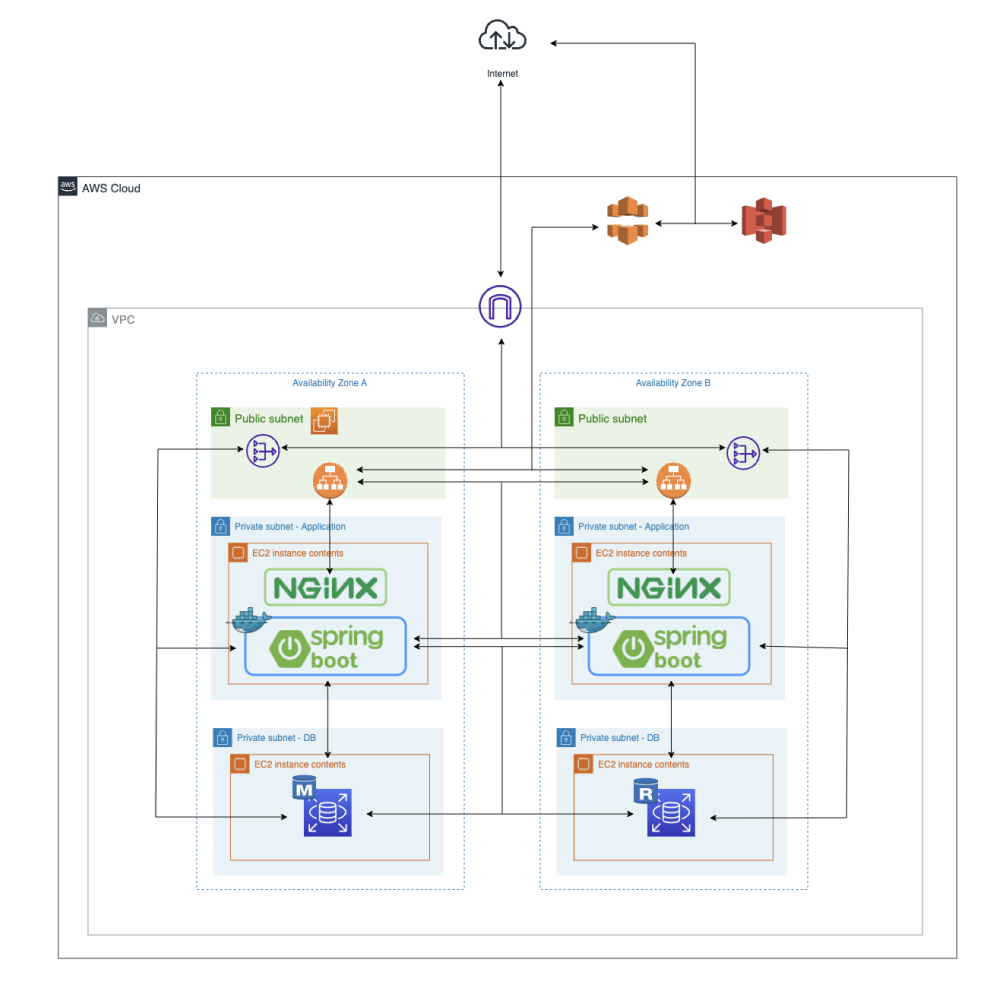
서버 이중화 구성은 Active-Active 방식을 선택하였습니다.
Active-Standby 방식에서는 한 서버가 대기 상태로 유지되므로 자원의 비효율적 활용 문제가 있다고 판단하였기에, Active-Active 방식을 진행하면서 로드밸런서를 앞단에 두어 클라이언트 요청을 여러 애플리케이션 서버에 분산시키는 구성을 선택하였습니다.
이 방식은 각 서버가 동시에 요청을 처리하여 자원을 최대한 활용하고, 가용성을 높이는 효과가 있다고 판단하였습니다.
[로드밸런서를 AWS의 ALB로 선택한 이유]
로드밸런서를 AWS의 ALB가 아닌 Nginx를 사용하는 방법 또한 고려하였지만, 아래와 같은 이유로 ALB를 사용하게 되었습니다.
- EC2 인스턴스의 IP주소가 바뀔때마다 Nginx를 사용하게 된다면, ip 설정을 변경해야 하기에 관리의 어려움이 존재합니다.
- ALB는 AWS의 여러 가용성 영역(AZ)에 걸쳐 자동으로 트래픽을 분산시키며, 이를 통해 고가용성을 확보할 수 있지만, Nginx를 로드 밸런서로 사용할 경우 이러한 설정을 수동으로 구성해야 하며, 특히 다중 AZ를 고려하는 경우 추가적인 설정과 관리가 필요하다고 판단하였습니다.
[그럼에도 불구하고 왜 Nginx가?]
그럼에도 불구하고 Nginx를 인스턴스내에서 유지한 이유로는 Nginx가 리버스 프록시 기능 외에도 캐싱을 활용하여 정적 파일을 서버 메모리에 저장하고, 클라이언트가 같은 파일을 요청할 때마다 빠르게 응답할 수 있도록 돕기 때문에 이를 통해 네트워크 대역폭 사용을 줄이고 응답 속도를 향상시킬 수 있다고 판단하였습니다.
[Replication]
또한 Reader DB와 Writer DB를 분리하여
하나의 디비 서버로 몰리는 트래픽을 분산하여 가용성과 안정성을 증가시킬 수 있었습니다.
[SPOF 문제를 개선한 인프라 (Active-Active)의 문제점]
하지만 해당 인프라 구조에서도 CI/CD 과정에서 일정시간동안 서비스가 제공되지 않는다는 문제점이 존재하였습니다.
이를 해결하기 위해 무중단 배포를 계획하였고, 그로 인해 인프라 구조가 변경되었습니다.
[최종 인프라 구조]
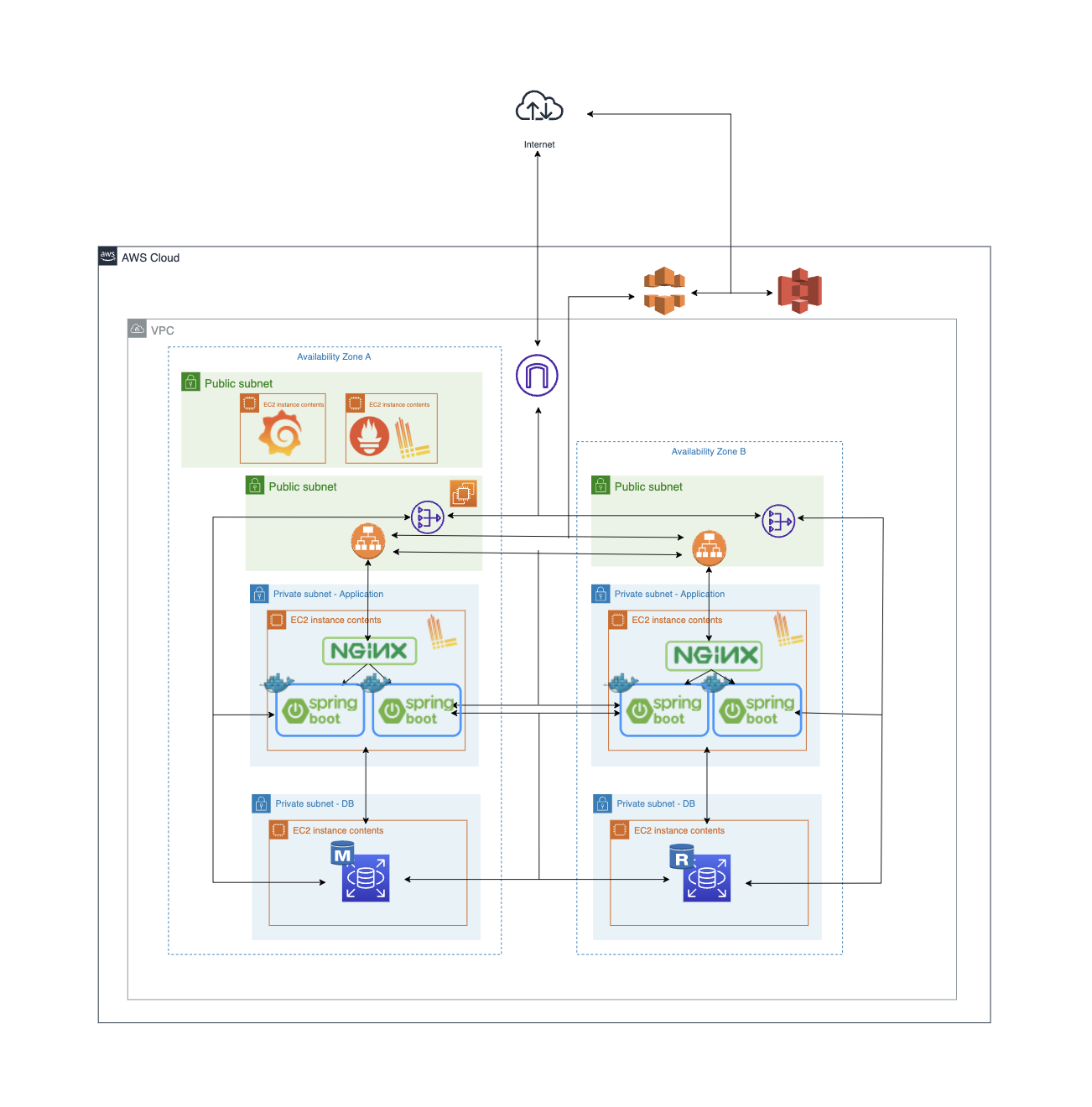
무중단 배포 전략으로는 Blue-Green 배포 전략을 선택하였습니다.
Blue-Green 배포전략은 다른 배포전략과는 다르게 구버전과 신버전의 공존이 존재하지 않기에 롤백이 용이하다는 장점이 매력적으로 다가왔고, 저희가 추구하는 목표 중 하나인 안정성과 연관되어 서비스가 안정적으로 제공된다는 점이 프로젝트의 방향성과 맞다고 판단하였습니다.
ELB의 Auto-Sacaling을 사용하여 손쉽게 블루그린 배포전략을 사용할 수 있다고 생각되었지만, 해당 Auto-Sacaling에 권한이 없기에 인스턴스 내부에 Docker Container로 Blue-Green 배포를 시도하였습니다.
[배포 과정]
CD Workflow에서 prod-a서버와 prod-b 서버에서 deploy.sh 스크립트를 실행시키는 것으로 시작됩니다.
아래와 같은 과정으로 배포가 진행됩니다.
- 모든 서버에 Green 배포를 수행한다.
- 스크립트로 기존에 Nginx가 바라보고 있는 포트를 찾아서 Blue로 판단한다.
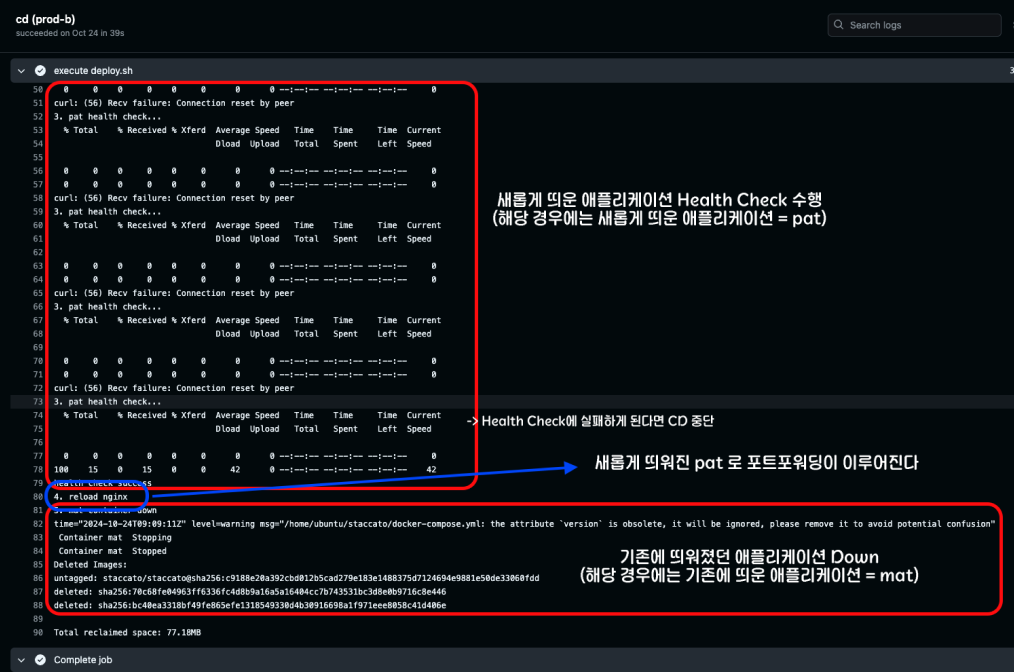
- 존재하는 Green 컨테이너가 있다면, 중지시키고 새롭게 생성한다.
- 새롭게 생성한 Green 컨테이너가 정상적으로 동작하는지 HealthCheck를 시도한다.
- Health Check가 성공한다면 Nginx가 바라보고 있는 포트를 Green으로 변경한다.
CD WorkFlow
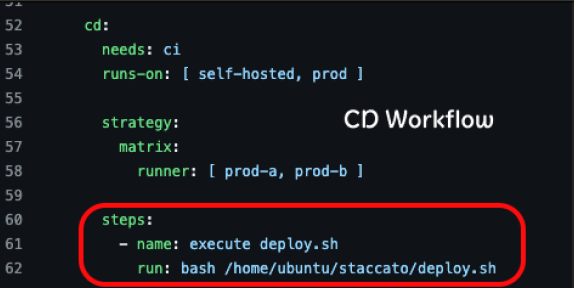 |  |
|---|
deploy.sh
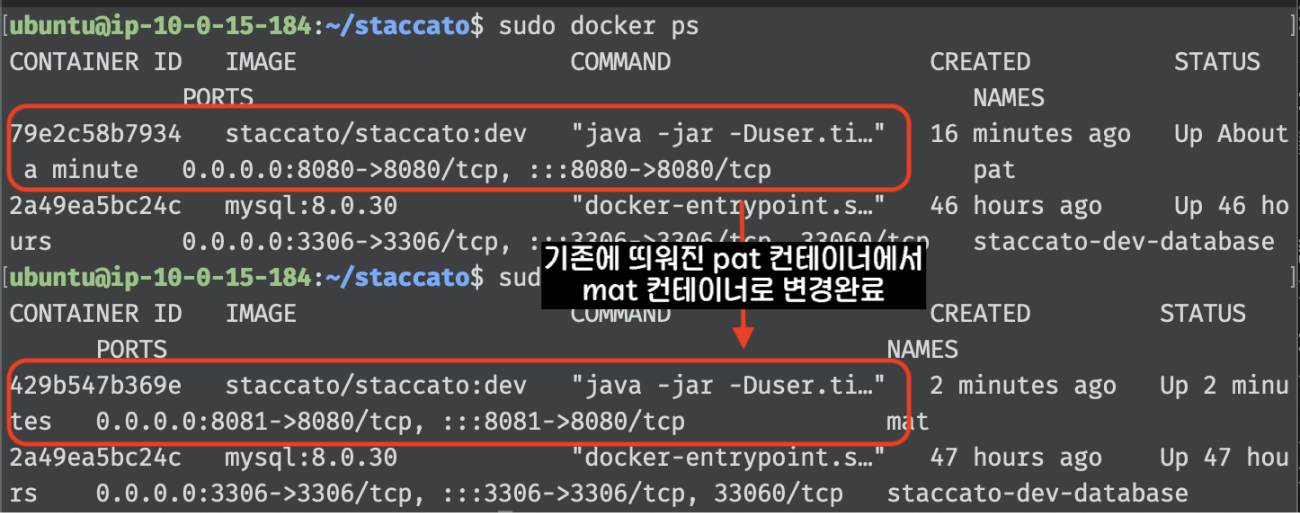
(하나의 인스턴스 내부에 애플리케이션들을 pat와 mat로 명칭)
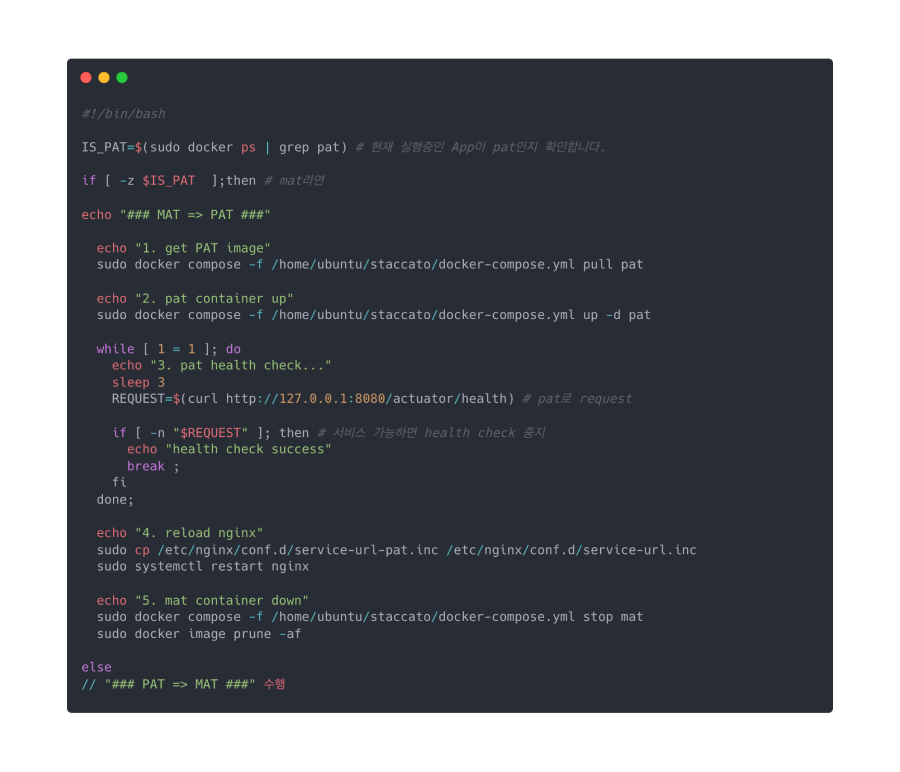
[이것이 정말 Blue-Green 무중단 배포일까?]
해당 인프라 구조에서도 문제가 있다고 판단하였습니다.
문제 예시 상황 1 : A-Prod 환경에서는 신버전으로 포트가 변경되었는데, 아직 B-Prod 환경에서는 구버전으로 포트포워딩이 이루어지고 있는 경우
문제 예시 상황 2 : A-Prod 환경에서는 신버전으로 포트가 변경되었는데, B-Prod 환경에서는 신버전 배포가 실패하여 구버전을 바라보고 있는 경우
두가지 상황에서 구버전과 신버전의 공존이 특정 시점에 존재한다는 문제점이 존재했습니다.
Blue-Green 배포전략을 선택한 이유는 구버전과 신버전의 공존이 없기 때문이였는데, 기존에 목표했던 바를 완벽히 이루지 못했습니다.
[진정한 무중단이 되기 위해서는]
GithubActions가 모든 인스턴스에서 Green 컨테이너가 정상적으로 띄워졌다는 Trigger를 받고, 그 이후 일괄적으로 Nginx가 가리키고 있던 포트를 바꿔버린다면?
- 진정한 무중단에 가까워진다고 판단하였습니다.
(Nginx가 포트를 스위칭하는 과정에서 발생하는 딜레이는 현재 고려하지 않았습니다)
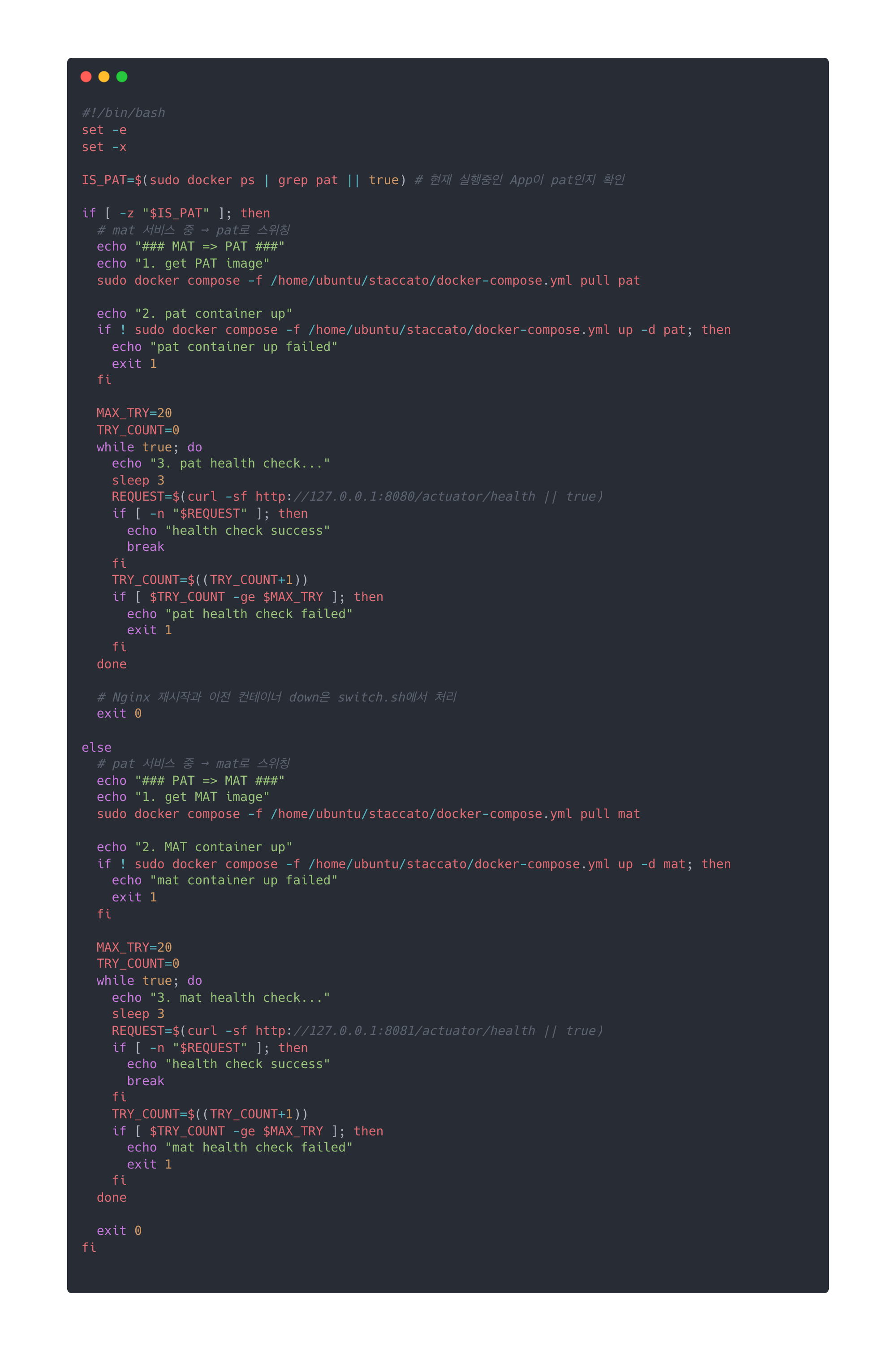
[deploy.sh 수정]
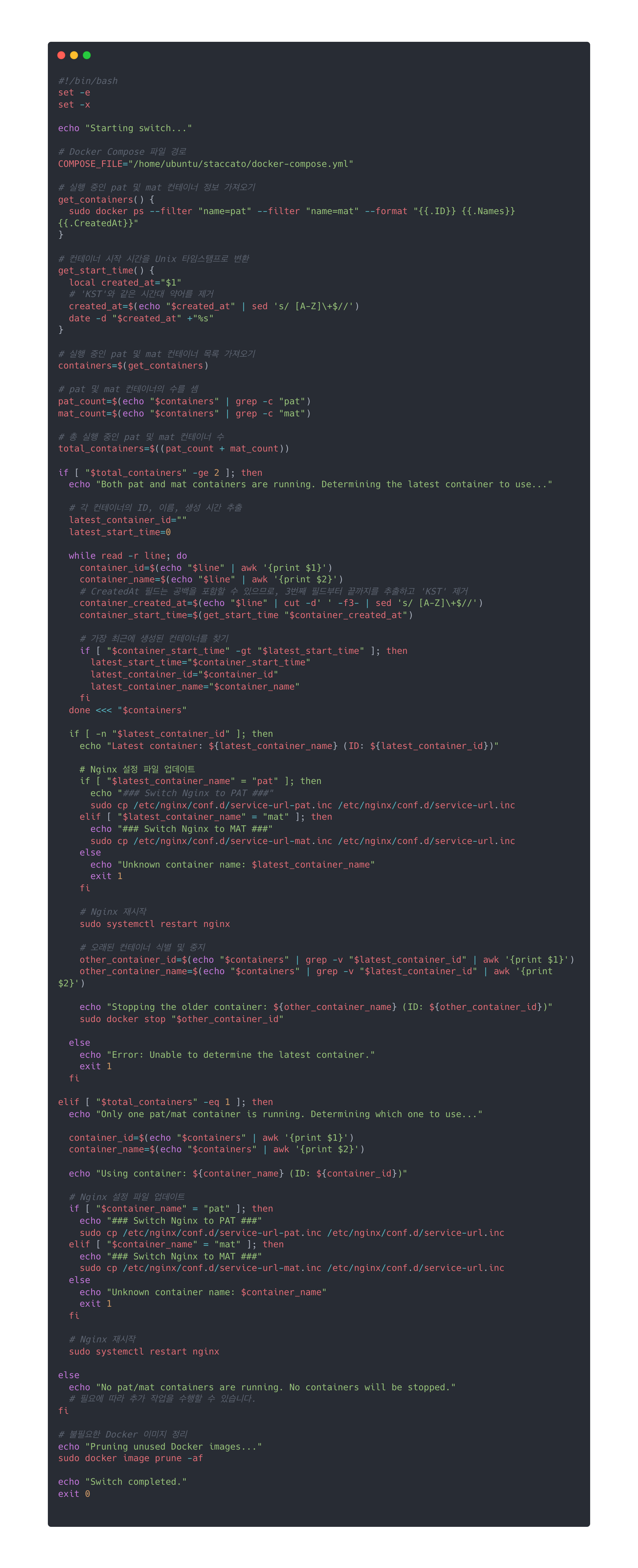
기존 deploy.sh 에서 처리하던 Nginx가 가리키던 포트를 스위칭하는 작업과 이전 Container를 down 시키는 부분이 switch.sh로 위임되었습니다.
- Health Check 성공 시 exit 0 반환
- Health Check 실패 시 exit 1 반환
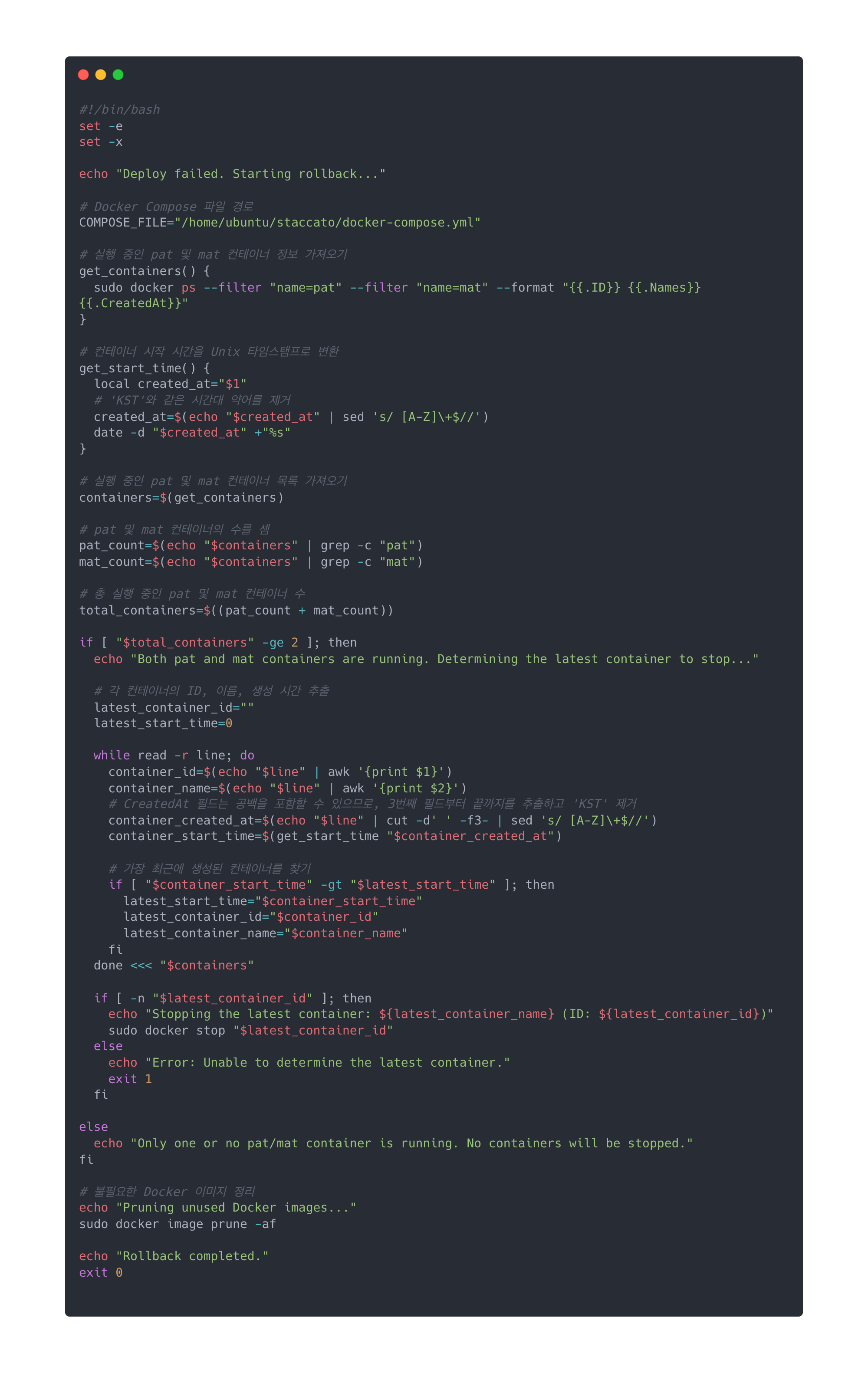
[rollback.sh 생성]
배포 실패 시 실행되는 롤백 스크립트로 pat와 mat 컨테이너 간의 상태를 확인하고, 필요한 경우 롤백 작업을 수행하는 역할을 담당합니다.
- pat와 mat 모두 띄워져있으면 최신에 띄워진 컨테이너 down
- pat 혹은 mat가 띄워져있으면 다운받은 docker image만 삭제
[CI/CD Workflow 수정]
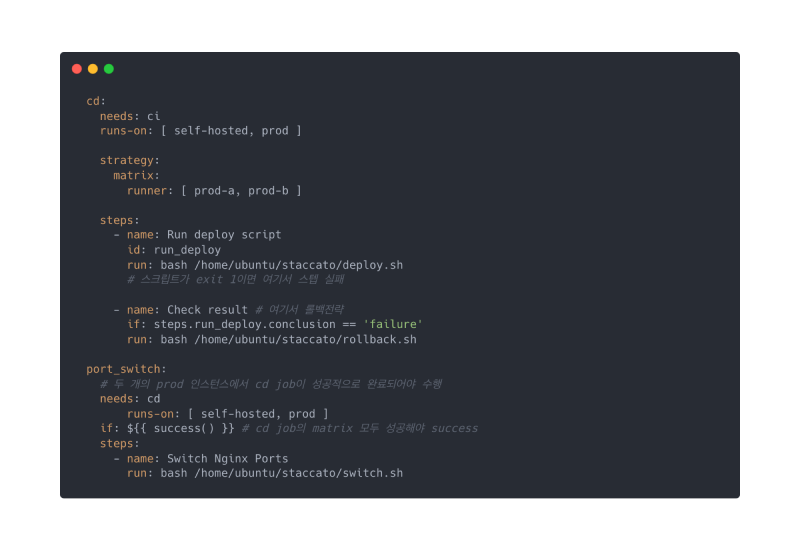
배포가 실패되었을 때 실행되는 롤백 전략과 배포가 성공했을 때 포트 스위칭 전략이 추가되었습니다.
[switch.sh 생성]
두 개의 인스턴스에서 deploy.sh가 모두 성공하여 GithubActions의 port_switch job 이 실행된다면해당 스크립트가 실행됩니다.
pat와 mat 두 개의 Docker 컨테이너 중에서 가장 최신에 시작된 컨테이너를 식별하여, Nginx가 가리키는 포트를 해당 컨테이너로 설정하고, 이전 Container를 down 시키는 역할을 담당합니다.
[무중단 배포 최종 CI/CD]
1. Run deploy script
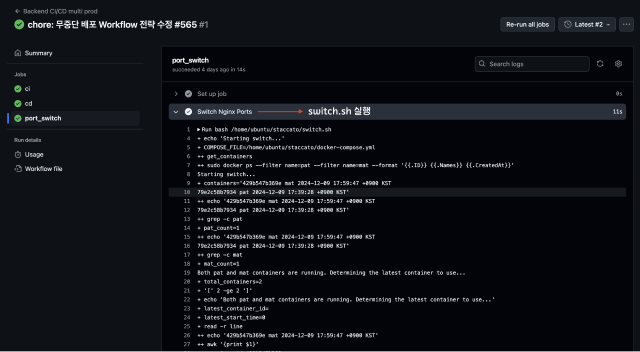
2. Switch Nginx Ports
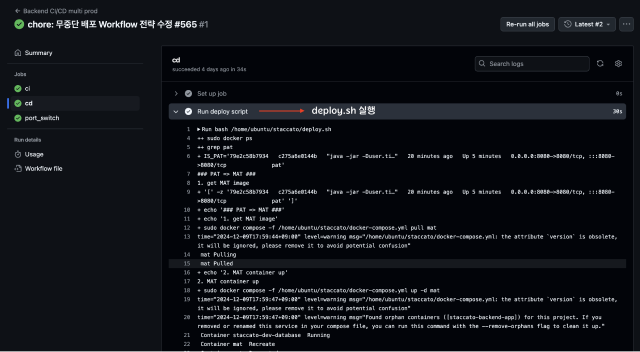
[무중단 배포 서버 Container & Health Check]
 Container Check Container Check |  Health Check Health Check |
|---|
[이제 정말 무중단 배포 끝..?]
- 모든 서버에게 성공 트리거를 받은 후 일괄적으로 포트를 스위칭하게 설정해놓았기에 구버전과 신버전이 공존하는 시간이 줄어들었고, 우리의 제어 하에 무중단 배포가 정상적으로 이루어졌다!
고 볼 수도 있지만 추가로 고려해야 할 사항이 있습니다.
- DB 레벨에서의 변경(ex: 스키마 변경 작업)이 이루어져도 정상적으로 작동할까?
- 포트스위칭 작업에서의 지연은 고려하지 않아도 될까?
만약 운영환경에서 flyway를 통해 스키마 버전을 관리하고 있다면, 신 버전(=스키마의 변경작업이 일어난) 배포가 완료되는 순간 DB 스키마도 변경 사항이 반영이 되었을 것입니다. 만약, 하위호환이 불가능한 변경 사항이었다면, 롤백 및 포트 전환까지의 시간동안 서비스는 장애가 발생할 것 입니다.
또한, 일부 서버에서 배포에 실패하여 롤백이 발생해도, DB는 자동으로 롤백되지 않습니다.
하위호환이 불가능한 변경작업이 아니었다면 호환 측면에서는 문제가 되지 않을 수 있겠지만, flyway를 사용하게 된다면 버전 체크 시 오류로 판단할 수 있습니다.
이와 같이 무중단 배포를 진행하면서 Infra, Application, DB 등 다양한 계층에서의 고려사항들을 탐구했으며, 현재 구조에서의 문제점을 지속적으로 발견하고 개선해 나가는 과정을 거쳤습니다.
