
들어가는 말
-
내가 생각하는 객체지향프로그래밍의 핵심은 프로그램을 '메모리 상의 기계'로 구현한다는 것이다.
-
먼저 절차적 언어는 프로그램을 코드의 순차적 실행으로 만들었었다. 물론 조건과 반복이 있지만 결국 프로그램은 위에서 아래로 실행한다.
때문에 함수 단위로 관리하더라도, 중복되는 코드와 이에 대한 수정은 비효율적 방식으로 해결된다. -
따라서 효율적 해결을 위해 객체지향은 '변수(속성)와 메서드(기능)의 집합', 곧 클래스라는 '부품 설계도'를 만든다. 그리고 각 부품 간의 관계를 설정해, 프로그램 실행과 함께 부품들이 자동 조립되어 '기계'를 구현하게 한다.
-
결과적으로 기계(프로그램)의 문제가 발생할 시, 부품만 교체해주면 된다.
즉, 클래스를 고치거나 변경하면 된다.
1. 객체지향언어
객체지향언어는 절차적 언어에 규칙을 추가해, 유기적인 프로그램을 구현한 것으로 ‘프로그램 유지보수’ 측면에서 큰 이점을 갖는다.
① 코드의 재사용성이 높다.
-
필요한 기능이 있으면, 그 기능이 포함된 클래스를 만들거나 원래 있는 클래스를 메모리에 로딩해서 언제든지 사용할 수 있다.
-
클래스 자체도 기존 클래스를 상속받아 확장해서 만들 수 있다.
② 코드의 관리가 용이하다.
-
클래스 단위로 코드가 묶여있어, 수정할 대상이 포함된 클래스의 코드만 수정하면 된다.
-
특히, 다형성을 이용하면 조상의 참조변수로 자손의 인스턴스를 사용할 수 있다.
그래서 필요할 때, 인스턴스만 교체해주면 된다.
③ 신뢰성이 높은 프로그래밍이 가능하다.
-
제어자나 메서드를 이용해서 외부에서 클래스 내부에 데이터에 접근하는 것은 개발자가 제어할 수 있다.
-
그래서 들어오는 값을 확인한 뒤, 기능을 처리하거나 아예 사용자에게 필요하지 않는 데이터를 제한함으로써 클래스의 오남용을 방지할 수 있다.
2. 클래스와 객체
클래스와 객체의 정의와 용도
클래스 : 객체를 정의한 설계도
용도 : 메모리에 로딩하여 실제 사용할 ‘객체’를 만드는 데 사용
-
클래스 자체는 설계도이다.
프로그램상에서 우리는 클래스를 사용하는 것이 아니라 클래스를 기반으로 만들어낸 부품인 ‘인스턴스’를 사용한다. -
설계도인 클래스만 잘 정의하면, 필요할 때 인스턴스로 만들어서 사용하면 된다는 이점이 있다.
-
JDK는 그래서 프로그래밍을 위한 기본 설계도(JAVA API)를 제공한다.
객체와 인스턴스
-
클래스를 메모리에 올려 인스턴스를 만드는 과정을 '클래스의 인스턴스화'라고 한다.
-
이렇게 만들어진 객체가 '인스턴스'이다.
객체의 구성요소
-
객체는 '속성'과 '기능'으로 이루어져 있으며, 이를 객체의 '멤버'라고 한다.
-
프로그램의 측면에선 데이터(멤버 변수)와 메서드의 집합체이다.
class TV {
// 속성(멤버변수)
boolean power; // 엔진 상태
int channel; // 속도
// 기능(메서드)
void power(){ power = !power; } // 전원 on/off 기능
void channelUp { channel++; } // 채널 올리기
void channelDown { channel--; } // 채널 내리기
}
/*
해당 예시에서 멤버변수의 기본값을 세팅해주지 않은 건,
인스턴스 생성 시 자동으로 자료형의 기본값으로 세팅되기 때문이다.
*/인스턴스의 생성과 사용
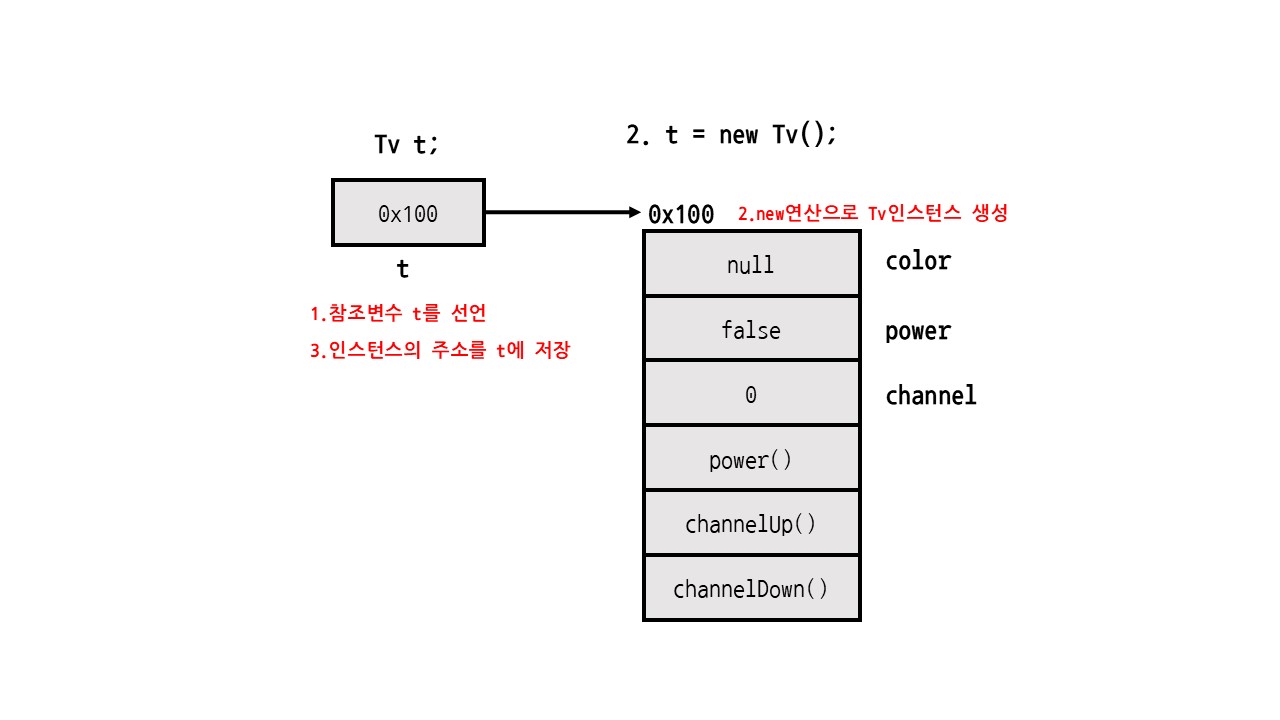
인스턴스 생성 :
new연산자로 인스턴스를 메모리 위에 로딩.
인스턴스 사용 : 해당 클래스 타입의 참조변수에 인스턴스의 주소를 저장해서 사용.
class Tv {
boolean power;
int channel;
// 기능(메서드)
void power(){ power = !power; }
void channelUp { channel++; }
void channelDown { channel--; }
}
class TvInstance {
public static void main(String args[]){
Tv t; // 참조변수 생성
t = new Tv(); // 인스턴스 생성
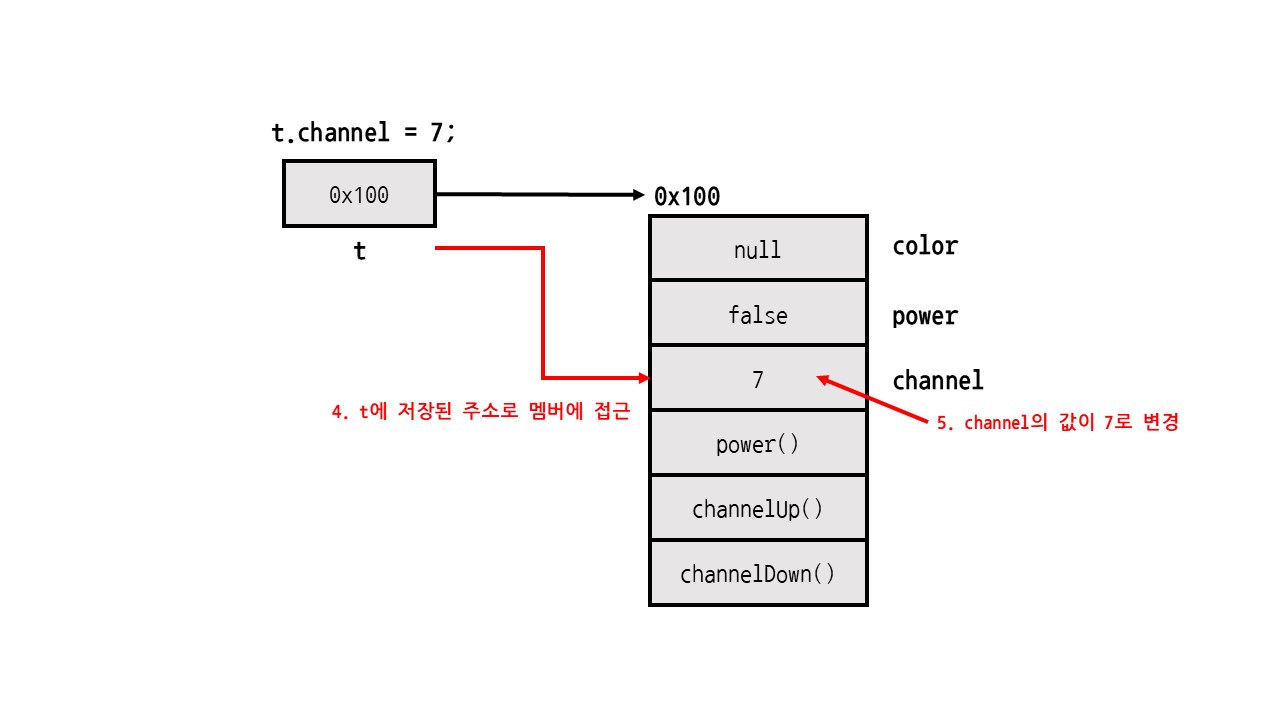
t.channel = 7; // 채널의 값 7
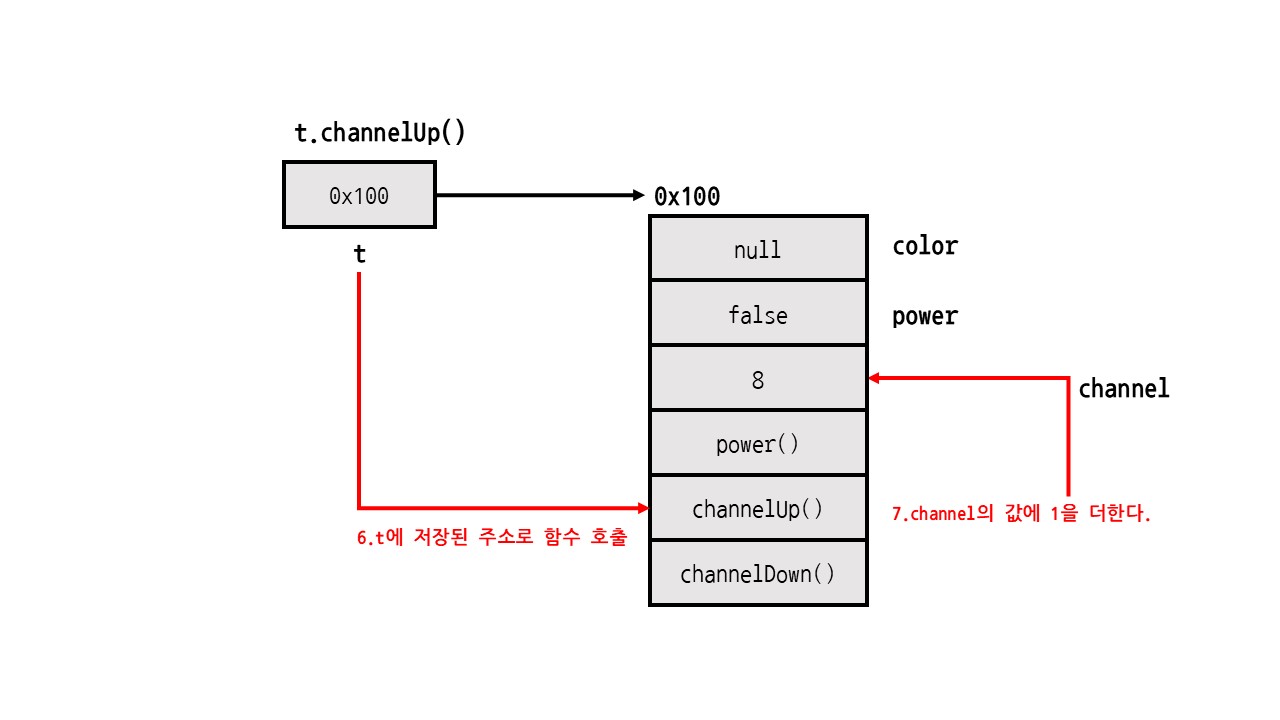
t.channelUp(); // 채널 올리기 메서드 호출
System.out.println(t.channel); // 8
}
}
- 인스턴스는 참조변수를 통해서만 다룰 수 있다.
즉, 참조변수는 JVM의 heap 영역에 로딩된 인스턴스의 주소를 저장한다. 따라서 참조변수와 인스턴스의 타입은 일치해야 한다.
객체 배열
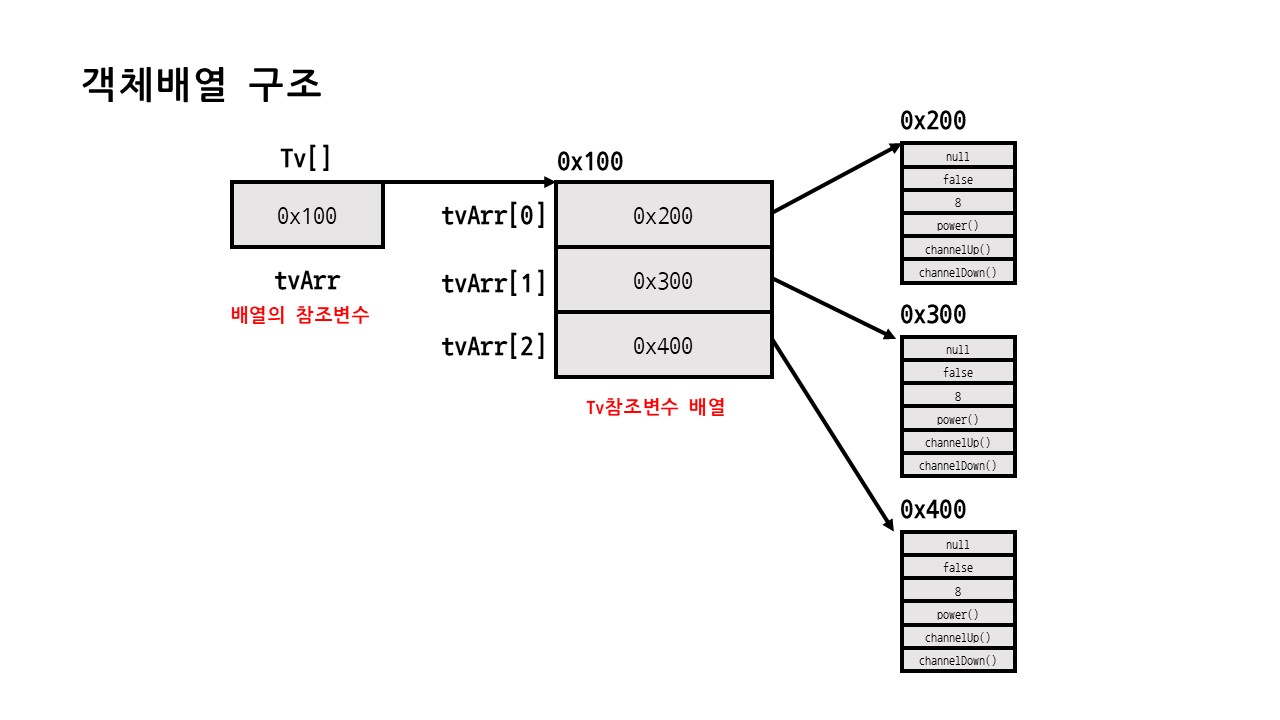
인스턴스의 참조변수 역시 배열로 다룰 수 있다.
즉, 인스턴스의 주소가 저장된 배열로 다수의 객체에 쉽게 접근이 가능하다.
Tv tvl, tv2, tv3; == Tv[] tvArr = new Tv[3];class Tv {
boolean power;
int channel;
// 기능(메서드)
void power(){ power = !power; }
void channelUp { channel++; }
void channelDown { channel--; }
}
class TvInstanceArr {
public static void main(String args[]){
Tv[] tvArr = new Tv[3]; // 객체 배열 생성, tvArr는 객체배열의 참조변수
// 객체배열에 인스턴스 저장
for(int i=0; i<tvArr.length; i++){
tvArr[i] = new Tv();
}
// 배열로 인스턴스에 접근
tvArr[0].channelUp();
tvArr[1].channel = 12;
tvArr[2].power();
}
}위 코드를 구조화 시키면 다음과 같다.
- 객체 배열은 웹개발 시, DTO를 다룰 때 중요하게 쓰인다.
클래스의 또 다른 정의
프로그래밍의 관점에선 클래스는 데이터를 저장하는 형태이다.
① 데이터와 함수의 결합
- 데이터를 저장하는 공간은 다음과 같이 발전되었다.
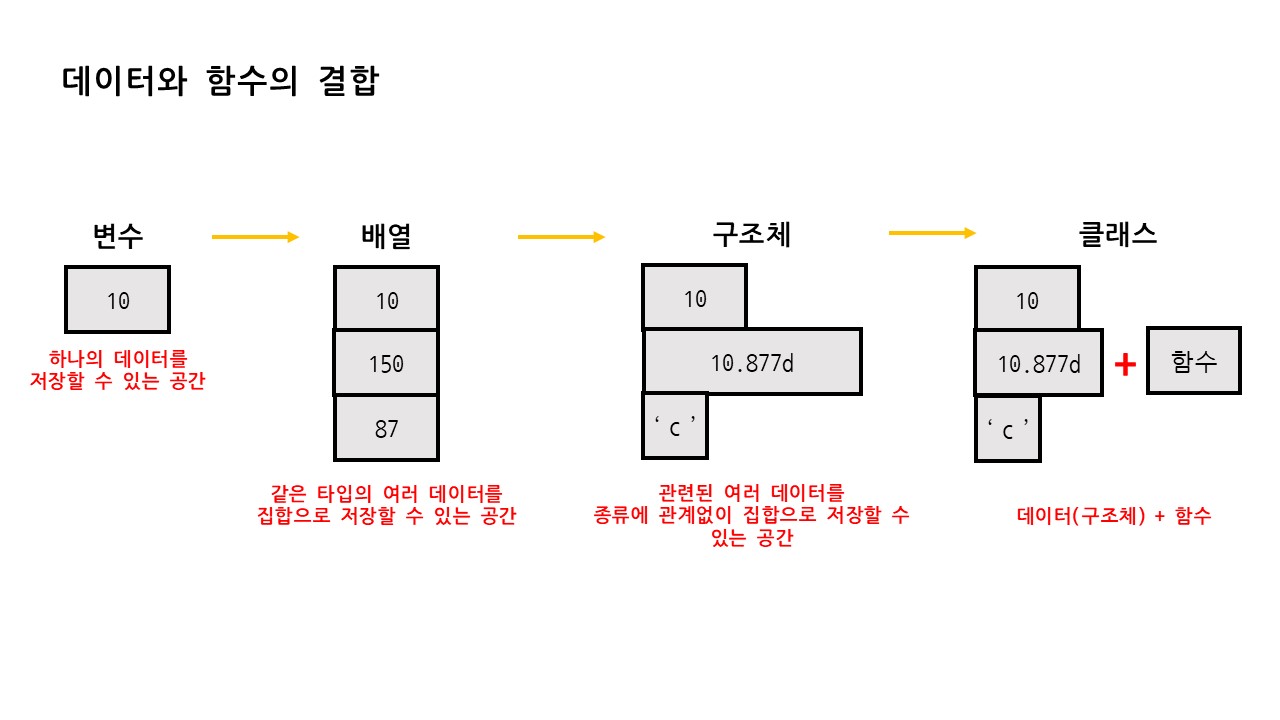
-
생각해보면 당연한 이야기이다. 하나의 데이터를 위해 '변수'가 생겼고, 이를 더 많이 다루기 위해 '배열'이 생겼다. 하지만 배열은 같은 타입만 가능하다.
따라서 자료형에 상관없이 저장하는 '구조체'를 만들었고, 이를 다시 관련 기능과 함께 다루기 위해 '클래스'가 만들어졌다. -
즉, 프로그래밍 관점에서 클래스는 공통된 목적으로 관계된 서로 다른 '멤버 변수'와 이와 관련된 작업을 하는 '메서드'의 집합이다.
② 사용자정의 타입
- '기본 자료형'은, 보편적으로 사용될 자료형을 언어 개발자들이 미리 만들어 제공한 것이다.
이를 반대로 보면 언어 개발자들은 기본형 이외의 것은 예측할 수가 없다.
그건 사용하는 프로그래마다 다르니까
- 때문에 프로그래머는 멤버 변수, 메서드, 제어자를 사용해서 자신에게 필요한 '참조 자료형'을 클래스로 구현한다.
- 즉, 프로그래머가 '관계성'을 파악해서 하나의 자료형(부품)을 만들어내는 것이 '객체지향'의 핵심이다.
『 핵심 정리 』
-
클래스는 객체의 설계도이며, 이를 메모리에 로딩한게 '인스턴스'다.
-
클래스에 소속된 변수와 메서드를 '멤버'라고 한다.
-
프로그래밍 관점에선 클래스는 발전된 데이터 저장방식 (데이터-함수의 집합)
-
인스턴스는 같은 타입의 참조변수로 접근해서 사용할 수 있다. 참조변수는 배열로 다룰 수 있다.
-
참조변수와의 연결이 끊어지면 Garbage Collector가 메모리 상에서 자동으로 없앤다.
3. 변수와 메서드
위치에 따른 변수의 종류
변수는 선언 위치에 따라 크게 세 종류가 있으며, 이에 따라 '생성 시기'가 전부 다르다.
즉, 어디에 변수를 선언하는지에 따라서 변수를 사용할 수 있는 지점들이 다르다.
변수의 분류
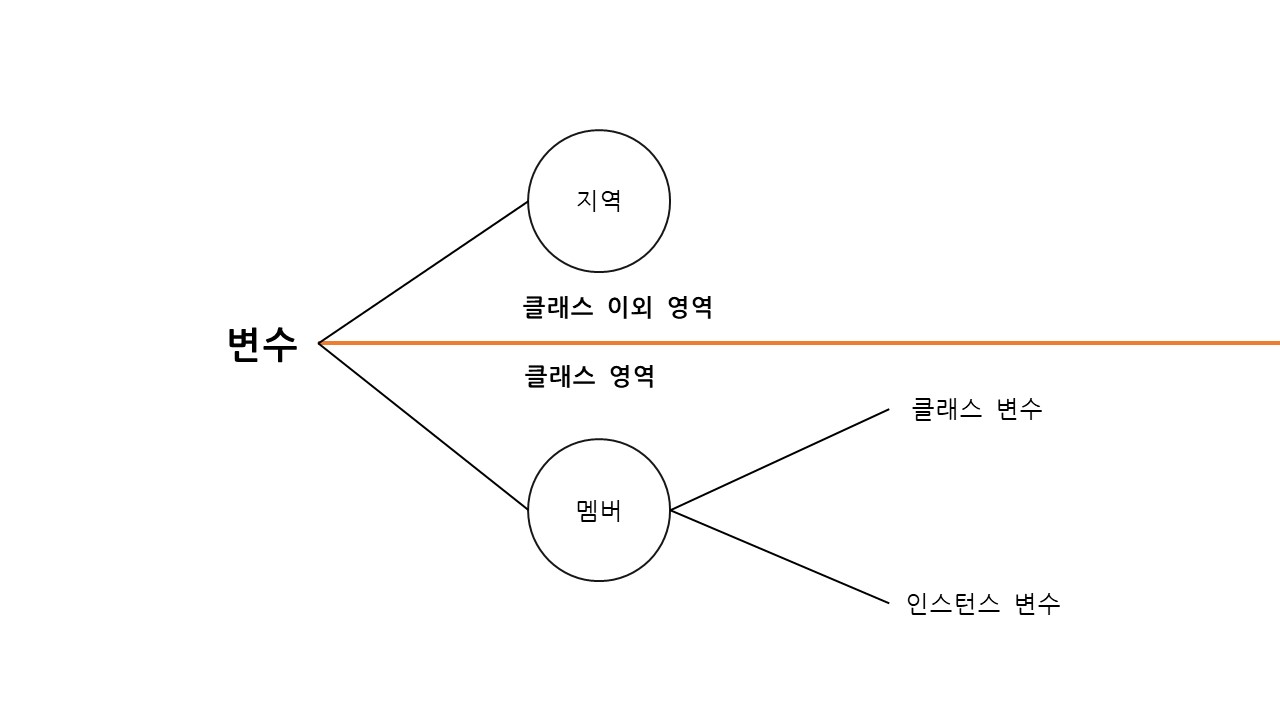
-
선언 위치는 '클래스 영역 / 이외 영역(메서드, 생성자, 초기화블럭)'으로 나뉜다.
이 중 클래스 영역의 멤버 변수를 제외하면 모두 '지역 변수'이다. -
지역 변수 : 메서드 영역(scope) 안에서 사용되고, 사용 후엔 공간이 반환된다.
-
멤버 변수 :
static이 붙으면 '클래스 변수', 아니면 '인스턴스 변수'
변수의 생성시점
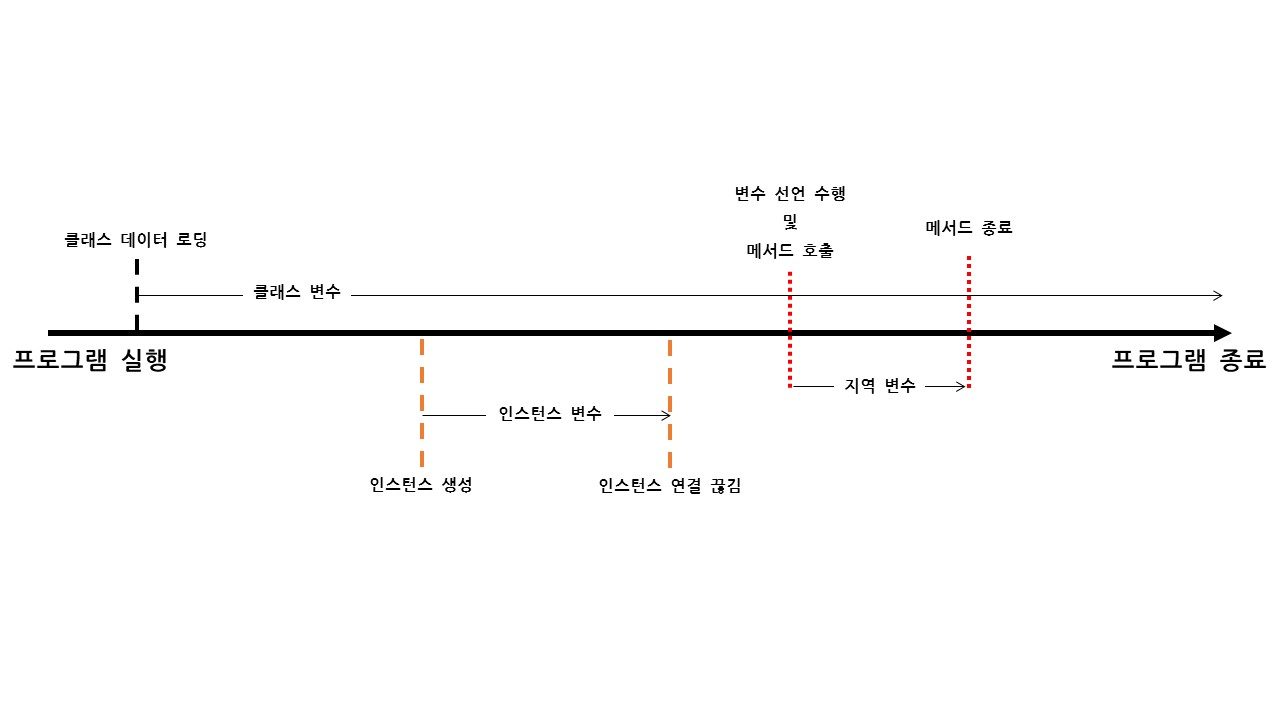
지역 변수
-
메서드 내(선언부, 구현부)에 선언되어 메서드 시작부터 끝까지만 사용이 가능하다.
즉, 메서드가 실행될 때 저장공간이 만들어지고 메서드 호출이 끝나면 저장공간이 반환된다. -
영역 자체는 블럭
{}을 중심으로 구분된다.
물론 메서드의 매개변수도 지역변수이지만, 애초에 모든 영역은 블럭으로 구분된다.
따라서 조건, 반복문이든 메서드든 블럭으로 구분된 영역 안에서만 지역변수가 사용된다.
main() 안에서 일반적으로 사용했던 변수들도 모두 지역변수이다.
인스턴스 변수
-
클래스가
new연산을 통해서 heap 영역에 생성될 때, 인스턴스 내부에 함께 생성된 저장공간이다.
때문에 인스턴스가 생성되지 않으면 사용할 수 없다. 동시에 인스턴스가 사라지면 함께 사라진다. -
인스턴스는 '독립적'이다. 곧 만들어지는 인스턴스마다 메모리 공간이 다르다는 것.
때문에 인스턴스 변수 역시, 인스턴스 별로 변수명이 동일해도 다르게 유지할 수 있다.
클래스 변수
-
인스턴스와 같은 클래스 영역에 작성되지만, 변수 앞에
static이 붙어 있다.
클래스 변수는 '클래스 데이터'가 '선언, 생성'될 때, JVM의 method area에 단 '하나'만 생성된 저장 공간이다.참조변수의 선언이나 객체의 생성처럼 클래스 정보가 필요할 때, 클래스가 메모리에 로딩된다.
-
즉, 모든 인스턴스가 하나의 클래스변수를 공유해서 사용한다.
그래서 모든 인스턴스가 공통적으로 유지해야하는 경우에 클래스 변수로 선언한다. -
클래스가 메모리에 로딩 될 때, 함께 생성되어 프로그램 종료 시까지 유지된다.
-
클래스명.클래스변수명의 형식으로 참조하여 사용하며, 인스턴스를 생성하지 언제든지 호출할 수 있다. -
접근제한자
public을 사용하면 '전역 변수'의 성격을 갖는다.
클래스변수와 인스턴스 변수 예시
카드를 예시로 두 차이를 간단하게 살펴보자
class card{
String kind;
int number;
static int width = 100; // 폭
static int height = 200; // 높이
}-
카드 클래스를 메모리에 로딩하면 카드 인스턴스가 만들어진다. 곧 서로 다른 종류의 카드들이 만들어진다.
-
종류와 숫자는 인스턴스별로 달라야 하니까, 인스턴스 변수이다.
반대로 카드의 규격은 모두 같아야 하니까, 클래스 변수로 선언했다. -
만약 카드 규격을 바꾸고 싶으면, 클래스 변수만 수정해서 모든 카드 인스턴스의 규격을 바꾼다.
『 핵심 정리 』
-
변수는 선언 위치에 따라 멤버, 지역으로 구분된다.
-
다시 멤버는
static의 유무에 따라 클래스 변수와 인스턴스 변수로 구분된다.
클래스 변수에public을 붙이면 '전역 변수'의 성질을 가진다. -
지역 변수는 블럭 내에 선언된다.
주로 메서드 내에 선언되며, 메서드 실행시 만들어지고 메서드가 종료되면 반환된다. -
공통된 값을 유지할 때는 '클래스 변수' / 인스턴스마다 다른 값일 때는 '인스턴스 변수'
메서드
메서드는 특정 작업을 수행하는 문장들을 하나로 묶은 것이다.
-
개인적으로 프로그램은 컴퓨터가 사용자의 목적에 맞게 어떤 기능을 수행하는 것이 본질이라 생각한다. 그리고 이를 구현하는 방식이 '연산'인 것인 것이고.
이런 맥락에서 메서드는 프로그램의 최소 단위라고 생각한다. 즉, 국소적인 기능을 담당하는 게 '메서드'라는 것이다. -
메서드 자체는 사용자가 입력만 넣으면, 원하는 결과를 도출해낸다. 그래서 사용자는 메서드의 세부적인 원리를 알지 않고, 쉽게 사용할 수 있다.
리모컨의 원리를 알고 쓰는 사람이 몇이나 되겠음.
메서드를 사용하는 이유
① 높은 재사용성
- 메서드를 한번 만들어 놓으면 언제든지 호출해서 사용할 수 있다.
② 중복된 코드의 제거
- 반복되는 코드는 메서드 하나로 묶어 관리할 수 있다.
이 자체로도 코드의 재사용성을 높이지만 제일 중요한 건 '유지보수'가 편리해진다.
③ 프로그램의 구조화
-
프로그램은
main()안에서 실행된다. 가볍게 100줄 정도는 읽을 수 있지만 실제 애플리케이션의 main은 기본이 그 이상이다.
그만큼 처리되는 작업들이 많다는 것인데, 이걸 절차적으로 쭉 나열한다 생각해보면 답이 없다. -
그래서 메서드 단위로 필요한 작업들을 구분하여 main을 최대한 구조적으로 만들어준다.
(걍 코드 가독성을 높여준다는 뜻으로만 이해해도 됨) -
또 클래스의 기능들을 정의할 때도 미리 메서드로 기능들을 구조화 해두면 구현부만 작성해주면 된다.
public static void main(String args[]){
int[] numArr = new int[10];
initArr (numArr); // 1. 배열을 초기화
printArr (numArr); // 2. 배열을 출력
sortArr (numArr); // 3. 배열을 정렬
printArr (numArr); // 4. 배열을 출력
}
/*
실제로 쓰면 인스턴스들을 메모리에 미리 로딩 시켜놓고 그때마다 메서드들을 호출해서 사용한다.
또는 메서드 단위로 인스턴스(계층)들을 오고 가며 작업을 처리한다.
*/메서드의 선언과 구현
메서드는 '선언부 / 구현부'로 이루어져 있다.
// 선언부
(제어자) 반환타입 메서드명 (매개 변수)
// 구현부
{
// 호출 시 수행될 코드
}
// 예시
int add (int x, int y){
return x+y;
}선언부
메서드명, 매개변수 선언, 반환타입으로 구성
-
선언부는 메서드의 기능, 필요한 데이터, 반환되는 결과값에 대한 정보를 제공해준다.
또 맨 앞부분엔 제어자를 붙여서 사용범위나 접근성을 제어할 수 있다. -
메서드 선언부가 변경되면 호출하는 부분들도 모두 변경해야되는 걸 주의하자.
1) 매개변수 선언
- 매개변수는 사용자로부터 값을 전달받는 메모리 공간. 전달 방식은 후술하겠지만 일단은 메서드가 작업하는데 필요한 값을 받을 변수를 선언한다고 이해하자.
- 일반 변수선언과 달리 같은 타입이라도 변수 타입을 생략할 수 없다.
- 매개변수의 수는 제한이 없다. (배열, 참조변수, 가변인자 등)
- 메서드가 종료되면 필요없기 때문에, '지역 변수'이다.
2) 메서드명
- 메서드명은 해당 메서드가 어떤 기능을 하는지 이름만 보고 알 수 있게 명명하는 것이 좋다.
3) 반환타입
- 매개변수의 반대, 메서드의 작업 결과에 대한 정보이다. 반환값이 어떤 형태인지 적어줘야 하는데, 이게 없으면 오류난다.
- 반환타입이 없을 때는
void라고 적는다.
구현부
실제 메서드의 기능을 구현한다.
1) return문
-
반환타입이
void가 아니면 구현부 내에는 return문이 꼭 있어야 한다.
사실, void도 return문이 존재한다. 컴파일러가 자동으로 추가해주는 것뿐이다. -
return문은 단 하나의 값만 반환할 수 있다.
-
이 값의 타입은 선언부의 반환타입과 일치하거나, 적어도 산술변환, upcasting이 가능한 것이다여 한다.
예를 들어 주소도 될 수 있고, 객체배열도 될 수 있고 상속 관계 안에서 자손 타입도 가능하다. -
굳이 값 자체 아니더라도 연산결과의 타입만 맞다면 수식으로 해도 괜찮다.
int add(int a, int b){ return a+b; // 수식을 계산한 결과를 반환 } -
if문 안에return을 넣는 경우, if문이 실행되지 않을 수 있기 때문에 컴파일 에러가 생긴다.
그래서if-else로 항상 반환값이 있게 만들어야 한다.int max(int a, int b){ if(a>b){ return a; // false일 경우에는 반환값이 없다. } else { return b; // 이제 어떤 경우든 반환값이 있다. } }
2) 지역변수
-
앞서 말한 것처럼 메서드 내에 선언된 변수는 그 메서드 안에서만 사용이 가능하다.
-
이를 지역변수라 하고, 매개변수도 포함된다.
-
메서드가 호출되면 저장공간이 생성되고, 메서드가 작업 결과를 반환하면 사라진다.
메서드의 호출
정의된 메서드를 사용하려면 호출해야만 한다.
호출 시,()에 메서드에 지정된 값들을 전달해줘야 한다.
인자(argument), 매개변수(parameter)
-
메서드 정의 시, 사용자가 넘겨줄 값을 '매개변수'라고 한다.
반대로 호출 시에, 사용자가 넘겨주는 값이 '인자'이다. -
인자는 매개변수의 타입, 순서, 개수 모두 일치해야 한다.
적어도 '자동형변환'이 일어나야 한다. ( 다형성으로 응용 )
메서드의 실행흐름
-
같은 클래스 내의 메서드끼리는 '참조변수'없이 서로 호출이 가능하다.
다른 클래스의 메서드를 사용하려면 인스턴스를 생성해, 참조변수로 메서드 호출을 해야 한다. -
단, static메서드는 같은 클래스 내의 인스턴스 메서드를 호출 할 수 없다.
왜냐면 static메서드가 메모리에 로딩된 시점에 인스턴스가 생성되지 않았을 수도 있기 때문이다.
class MyMath {
long add(long a, long b) {
long result = a+b;
return result;
}
long subtract (long a, long b) { return a - b; }
long multiply(long a, long b) { return a * b; }
double divide (double a, double b) { return a / b; }
// 같은 클래스 내의 메서드 간 호출
void callInnerMethod(long x, long y){ // instance Method
add(x, y); // instance Method
}
}JVM의 메모리 구조
JVM은 자바 프로그램 실행을 위한 가상머신이다.
머신이 프로그램을 실행하기 위해선 메모리 영역이 필요하며, 이를 운영체제로 부터 할당받는다.
그럼 JVM은 용도에 따라서 여러 영역으로 나누어 관리한다.
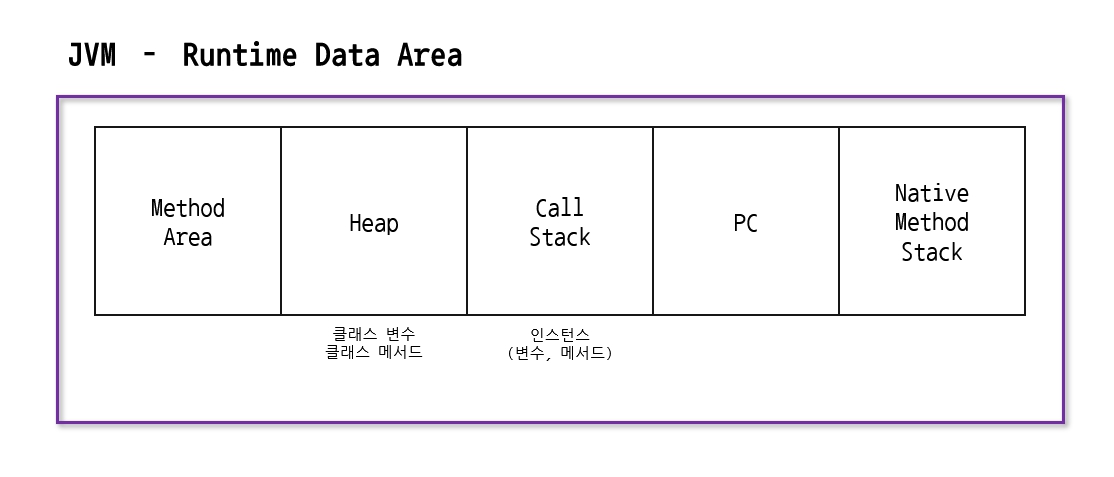
JVM의 메모리 영역은 5가지이다.
- Method Area : 클래스의 정보, 클래스 변수, 메소드 코드 등을 저장하는 공간
- JVM은 프로그램 실행 중 어떤 클래스가 사용(선언, 생성)되면,
해당 클래스의 클래스 파일을 분석해서 클래스 데이터를 메서드 영역에 저장한다. - JVM이 시작될 때 생성, 모든 스레드가 공유한다.
- 따라서 클래스 변수의 생성 주기는
프로그램 실행 → 종료까지다.
- JVM은 프로그램 실행 중 어떤 클래스가 사용(선언, 생성)되면,
- Heap : 인스턴스 저장 공간
- 동적으로 생성되는 인스턴스는 이곳에 생성되며, 가비지 컬렉션의 대상이 된다.
- 모든 스레드가 공요한 공간이다.
- 참조변수와 인스턴스의 연결이 끊기면, GC가 메모리에서 제거한다.
- Call-Stack : 메서드 작업을 위한 메모리 공간
- 호출 메서드를 위한 공간들이 할당되며, 지역변수와 리턴값, 중간 연산 결과 등을 저장한다.
- 스레드마다 별도 생성되며, 메서드 호출마다 프레임이라는 공간을 생성해서 사용한다.
- 메서드가 종료되면 사용한 프레임도 반환되어 비워진다.
- 따라서 지역변수의 생성 주기는
메서드 호출 → 메서드 종료까지다.
-
PC : 현재 수행중인 명령어의 주소를 저장하는 공간
-
Native Method Stack : 자바 이외의 언어로 작성된 네이티브 코드를 위한 스택 영역
번외. Call-Stack에 스레드가 나온 김에 스레드에 대해서 알아보자.
스레드(Thread)
: 프로세스 내에서 실행되는 CPU의 작업 단위
스레드를 이해하려면, 프로세스에서부터 시작하는게 좋다.
스레드가 나오게 된 배경
전제
- 스레드는 ‘프로세스‘의 한계를 극복하기 위해 만들어 졌다.
문제
- 초기 컴퓨터는 한번에 하나의 프로세스만 처리할 수 있었다.
과정
-
프로세스
-
프로그램은 컴퓨터가 실행할 명령어의 집합이며, 프로그램이 실행되면 '프로세스'가 된다.
-
프로세스의 핵심은 CPU가 처리할 '메모리 위에 독립된 공간'를 가지는 것이다.
-
이 독립된 공간은 OS에 의해 배당된 가상주소공간이다.
-
즉, 프로세스는 CPU가 처리할 작업이자 단위다.
-
다만 한번에 한 프로세스만 처리가 가능하여 'I/O'같은 외부작업이 있다면
CPU와 메모리는 대기상태가 된다. -
즉, 자원낭비가 있었다. 이를 효율적이게 사용하고자 여러 프로세스를 부분적으로 실행했다.
-
이 때, 다른 프로세스의 시간이 오래걸리면 다음 프로세스은 대기 상태가 되는 문제가 있었다.
-
-
멀티태스킹
-
앞선 문제를 해결하고자 각 프로세스를 일정 시간동안 실행하는 '멀티 태스킹'이 생겼다.
-
멀티태스킹은 각 프로세스를 짧은 시간동안 실행해, 사용자의 입장에선 각 프로세스가 연속적, 동시적으로 사용되는 것처럼하는 방법이다.
-
하지만 프로세스는 독립적인 메모리 공간을 사용하기에 한계가 있었다.
-
그 한계는 다음과 같다.
(1) 하나의 프로세스는 여러 작업을 동시에 할 수 없다.
(2) 프로세스 간 자원공유가 어려움
(3) 프로세스 간의 작업 전환, 컨텍스트 스위칭은 무거운 작업이다.
(4) 멀티코어 CPU를 효율적으로 사용할 수 없다.
-
따라서 프로세스를 더 잘게 쪼개기로 하는데, 그게 ‘스레드’이다.
정리
-
스레드는 프로세스 내의 작업 단위로 하나의 프로세스는 한 개 이상의 스레드를 가진다.
-
각 스레드는 프로세스의 메모리 안에서 독립된 stack영역을 가진다.
-
이 영역은 포인터로 구별되기 때문에 포인터만 전환하면 작업 전환이 쉽다.
-
또한, 프로세스 내의 heap영역 안의 자원을 공유한다. 따라서 한 프로세스 내의 데이터 공유가 쉽다.
-
여러 개의 스레드를 동시에 실행하는 것을 '멀티스레딩'이라고 한다.
-
멀티스레딩을 사용하면 멀티코어 CPU에서 동시적, 병렬적인 실행을 구현할 수 있다.
-
하지만 프로세스의 자원공유는 스레드의 동시성 문제가 발생할 수 있으므로 주의해야 한다.
결과적으로 스레드라는 더 작은 단위로 인해, 작업을 처리하는 ‘멀티태스킹, 멀티스레딩, 멀티프로세싱’의 효율을 높일 수 있다
JVM과 메서드의 관계
class CallStackTest {
public static void main(String[] args) {
firstMethod(); // static 메서드는 객체 생성없이 호출가능하다.
}
static void firstMethod() {
secondMethod();
}
static void secondMethod() {
System.out.println("secondMethod()");
}
}
/* ▼ 실행결과
secondMethod()
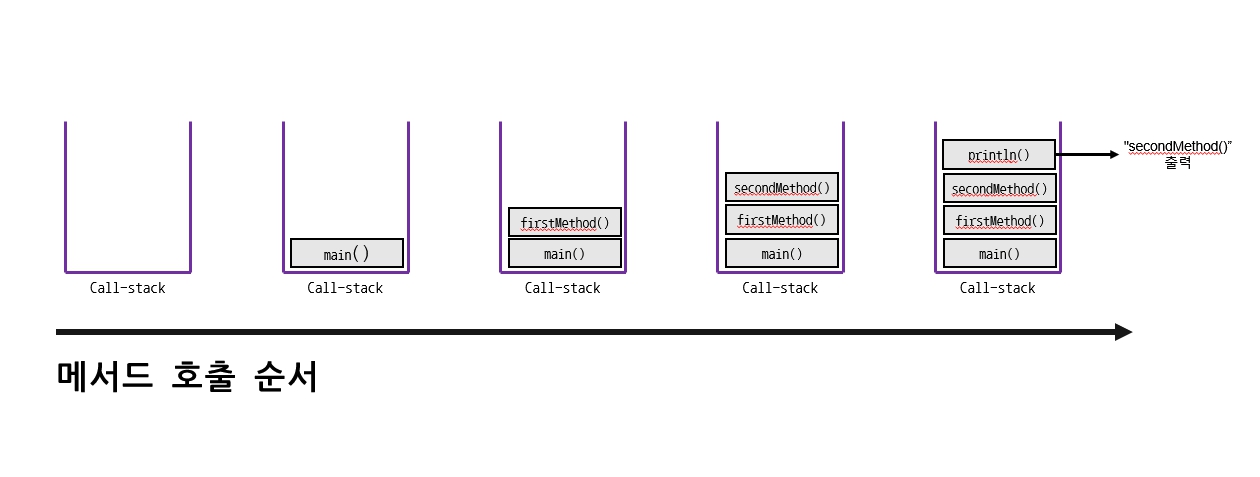
*/
-
메서드가 호출되면 수행에 필요한 메모리 공간을 콜스택에 할당받는다.
이 공간은 메서드 별로 구별되어 있다. -
첫번째 호출된 메서드의 공간은 콜스택의 맨 밑에 마련되고, 순서대로 바로 위에 다음 호출된 메서드들의 공간이 생긴다.
-
다른 메서드를 호출한 메서드(caller)는 대기 상태가 된다.
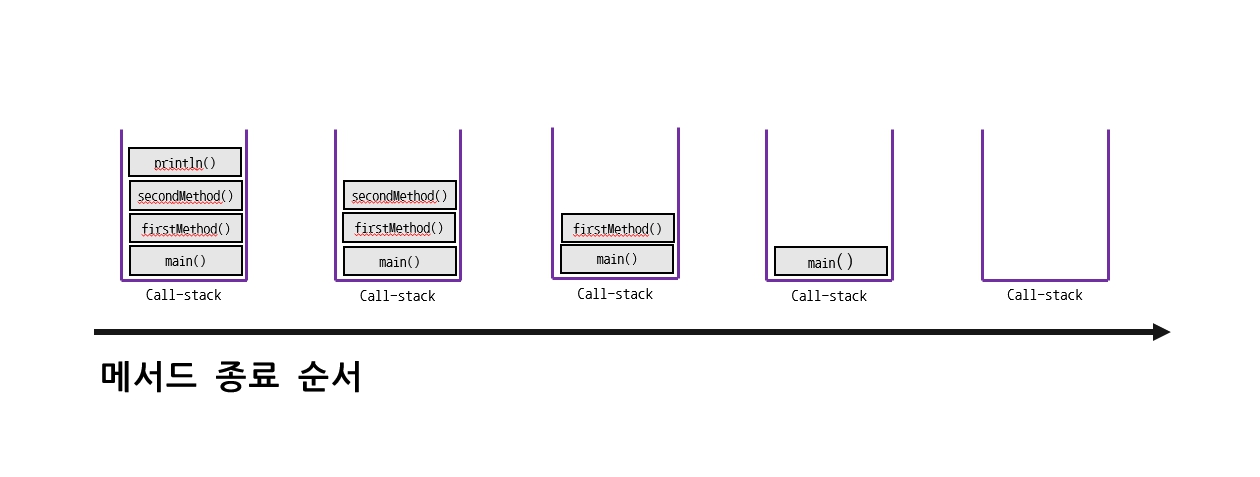
-
역으로 메서드가 종료되면, 맨 위에서부터 차례대로 콜스택에 배당된 메모리 공간이 반환된다.
이때 사용한 지역변수들도 함께 사라진다. -
반환타입이 있는 메서드는 종료하면서 결과값을 자신을 호출한 메서드에게 반환한다.
그러면 대기 상태에 있던 메서드를 이를 갖고 작업을 한다.
매개변수
매개변수는 메서드 내에서 사용한 데이터를 넘겨받는 변수(공간)이다.
메서드에 값을 전달하는 방식
매개변수를 알아보기 앞서, 데이터를 전달하는 두 가지 방식을 살펴보자.
1. Call by Value
- 가장 기본이 되는 전달 방식
- 값을 매개변수에 복사하는 방식
- 값이 복사되었기 때문에 원본의 값을 변경되지 않는다.
- 매개변수의 타입은 '기본형'이다.
class CallByValue{
public static void main(String[] args){
int a = 10;
cbValue(a);
System.out.println("main() : " + a);
}
void cbValue(int b){
System.out.println("input : "+ b);
b = 20;
System.out.println("change : "+ b);
}
}
/* ▼ 실행결과
input : 10
change : 20
main() : 10
*/2. Call by Adress
- 참조변수는 주소를 저장한다.
따라서 주소를 매개변수에 복사해서 전달하는 방식 - 본질은 Call by Value와 다르지 않다.
다만 주소를 통해 원본 데이터에 접근할 수 있다. - 매개변수의 타입은 '참조형'이다.
class Adress{ int a; }
class CallByAdress{
public static void main(String[] args){
Adress adr = new Adress();
adr.a = 10;
System.out.println("변경 전 adr.a값 : " + adr.a);
cbAdress(adr);
System.out.println("변경 후 adr.a값 : " + adr.a);
}
void cbAdress(Adress b){
System.out.println("input : "+ b.a);
b.a = 20;
System.out.println("change : "+ b);
}
}
/* ▼ 실행결과
변경 전 adr.a값 : 10
input : 10
change : 20
변경 후 adr.a값 : 20
*/번외. Call by Reference
- Java가 아닌 C++에서 사용되는 방식
- C++에선 개발자가 직접 주소를 조작할 수 있다.
- 그래서 매개변수와 선언된 변수가 같은 메모리 영역을 바라보게 할 수 있다.
참조형 반환타입
매개변수뿐만 아니라 반환타입도 '참조형'이 될 수 있다.
앞서 본 것처럼, 타입이 참조형이라는 것은 메서드가 '객체의 주소'를 반환한다는 것이다.
class Data { int x; }
class ReferenceReturnEx {
public static void main(String[] args) {
Data d = new Data();
d.x = 10;
Data d2 = copy(d);
System.out.println("d.x = "+d.x);
System.out.println("d2.x = "+d2.x);
}
static Data copy (Data d) {
Data tmp = new Data();
tmp.x = d.x;
return tmp;
}
}
/* ▼ 실행결과
d.x = 10;
d2.x = 10;
*/재귀 호출
메서드 내부에서 자신을 다시 호출하는 것을 '재귀 호출'이라 한다.
void method(){
method();
}-
메서드 호출 자체는 명령어 수행이다. 즉, 재귀 함수는 내부적으로 자신을 재호출하는 것이다.
그래서 일반 메서드 호출이랑 다를게 없다. -
호출된 메서드는 'call by value'로 복사한 값으로 작업한다.
그래서 caller와 상관없이 작업할 수 있다. -
다만, 재귀함수는 '제어문'으로 특정 조건에서 호출이 멈추게 해야한다.
-
재귀함수는 외부 메서드처럼 작업 후, 끝난다고 생각하면 안된다.
기존 코드가 똑같이 실행되기에, 호출을 끝내는 조건을 설정하지 않으면 '무한 호출'을 하게 된다. -
즉, 호출을 끝내는 조건이 있어야 '호출 스택' 맨 위 메서드부터 차례대로 처리될 수 있다.
(무한 호출은 결국 호출 스택의 저장 범위를 넘어서 '스택 오버플로우'에러는 발생시킴)
재귀호출은 대부분 반복문으로도 표현이 가능하다.
그리고 반복문에선 매개변수 저장이나, 반환 과정이 생략되어 속도가 더 빠르다.
그럼 굳이 왜 쓸까?
-
코드의 관점에서 볼 때, 반복문은 '같은 작업을 하는 연속된 코드'를 한번에 처리하는 문법이다.
-
같은 맥락에서 메서드도 프로그램 안에서 반복되는 코드를 하나로 묶어서, 메서드란 형식으로 호출해서 쓸 수 있게 한 것이다.
-
재귀호출도 메서드 안 '공통, 중복된 코드'를 또 호출하는 것이다. 다만 그 대상이 매개변수가 다른 자신인 걸 제외하면 말이다.
-
따라서, 재귀호출을 통해 코드를 간결하게 만들어 준다.
class Factorial{
public static void main(String args[]){
int input = 4;
// 재귀 호출
int result1 = factorial(input);
// 반복문
int result2 = 1;
for(int i=1; i<=input; i++){
result2 *= i;
}
}
static int factorial(int n){
// 매개변수의 유효성 검사
if(n <= 0 || n > 12) return -1;
if(n == 1) {
return 1;
}
return n * factorial(n-1);
}
}클래스 메서드와 인스턴스 메서드
변수처럼 메서드도 메모리 영역에 따라 구분된다.
클래스 메서드
-
static키워드가 붙어 있는 메서드 -
인스턴스 생성 없이 메서드 사용이 가능하다.
클래스명.메서드명(매개변수) -
JVM의 Method Area의 일부분인 Class Area에 클래서 정보가 로딩될 때, 함께 로딩된다.
-
일반적으로 인스턴스 변수, 메서드와 관련되지 않을 경우 클래스 메서드로 정의한다.
인스턴스 메서드
-
static키워드가 없는 메서드 -
인스턴스가 생성되야만 사용할 수 있다.
-
인스턴스 생성과 함께 heap영역에 메서드가 로딩된다.
-
인스턴스 변수를 사용하는 메서드는 일반적으로 인스턴스 메서드가 된다.
정리
- 모든 인스턴스가 하나의 값을 유지해야 하는 멤버변수에는
static을 붙인다.- 클래스는 하나지만, 인스턴스는 여러개가 가능하다.
이 때, 공통으로 값을 유지해야되는 멤버변수는 클래스영역으로 로딩해서 공유되게 한다.
- 클래스는 하나지만, 인스턴스는 여러개가 가능하다.
- 클래스 변수는 인스턴스를 생성 안해도 사용가능하다.
-
클래스 메서드는 인스턴스 변수를 사용할 수 없다.
-
메서드가 로딩된 시점에 인스턴스가 생성되어 있지 않으면 사용할 수 없다.
이로 인해 발생되는 문제를 막기 위해, 클래스 메서드는 인스턴스 변수를 내부적으로 사용할 없다. -
반대로 인스턴스 변수나 메서드는 static이 붙은 변수, 메서드 사용이 가능하다.
왜냐면 인스턴스가 생성되면 이미 클래스 정보가 JVM에 로딩되었기 때문이다.
-
- 인스턴스 멤버를 사용하지 않는다면
static을 붙이는게 효율적이다.
멤버 간의 참조와 호출
같은 클래스 멤버 간에는 인스턴스 생성 없이 참조, 호출이 가능하다.
단, 클래스 멤버는 인스턴스 멤버를 사용하려면 인스턴스 생성을 해야한다.
예시
class MemberCall{
int iv = 10; // 인스턴스 변수
static int cv = 20; // 클래스 변수
// 멤버 변수간 사용
int iv2 = cv; // 가능
static int cv2 = new MemberCall().iv; // 가능 (인스턴스 생성 O)
// static int cv2 = iv; 불가능 (인스턴스 생성 X)
// 클래스 메서드
static void staticMethod(){
System.out.println(cv);
// System.out.println(iv); 불가능 (인스턴스 생성 X)
MemberCall c = new MemberCall();
System.out.println(cv);
}
// 인스턴스 메서드
void instanceMethod1(){
System.out.println(iv);
System.out.println(cv);
staticMethod();
}
void instanceMethod2(){
System.out.println(iv); // 가능
System.out.println(cv); // 가능
staticMethod(); // 가능
instanceMethod1(); // 가능
}
}『 핵심 정리 』
-
메서드는 특정 작업을 수행하는 문장들을 하나로 묶은 것이다.
그래서 코드의 재사용성과 유지보수에 좋다. -
매개변수는 '지역변수'이며, 기본형은 '값을 복사' / 참조형은 '주소를 복사'한다.
-
멤버 변수처럼 메서드도 클래스, 인스턴스로 구분된다.
-
같은 클래스 내에 있을 때는 인스턴스 생성없이 참조할 수 있다.
다만 클래스 메서드의 인스턴스 메서드, 변수 사용은 제한된다. -
메서드엔 반환타입이 있어야 한다. 없을 경우 void로 반환타입을 정의한다.
내부적으론 void도 return문이 존재한다. -
if문 안에 return을 넣을 경우, 예외의 가능성 때문에 컴파일 에러가 생긴다.
-
반환타입은 선언부와 일치하거나, 산술변환이 가능해야 한다.
도움이 되셨다면 '좋아요' 부탁드립니다 :)
