JPA를 공부하면서 N + 1 이라는 것을 알고 있었다.
하지만 CRUD 작업에 급급했기에 직접 쿼리가 어떻게 발생하고 있는지 확인하지 않았다.
그냥 기능 구현에 급급했던것 같다. 이번에 새로운 직장인 휴가관리 프로젝트를 개인적으로 진행하면서 N + 1 상황을 직접 마주할 수 있었고 관련해서 정리하면서 성장하려고 한다.
문제 상황
팀원 휴가를 조회하는 API를 만들고 있었다. 응답에는 작성자 이름(=유저 이름)이 포함돼야 한다.
하지만 휴가 테이블에는 이름을 직접 저장하지 않고, USER 테이블의 PK를 FK로 들고 있는 전형적인 설계다.
그래서 자바 세상(JPA)에서는 휴가 엔티티에서 참조를 통해 유저 이름에 접근했다.
// VacationHistory.java (요약)
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user; // author, writer … 어떤 네이밍이 더 나을까요?네이밍은 author, writer 중 하나면 충분히 직관적이라고 생각하지만, 더 좋은 의견이 있다면 댓글 부탁드립니다!
로그로 본 N + 1
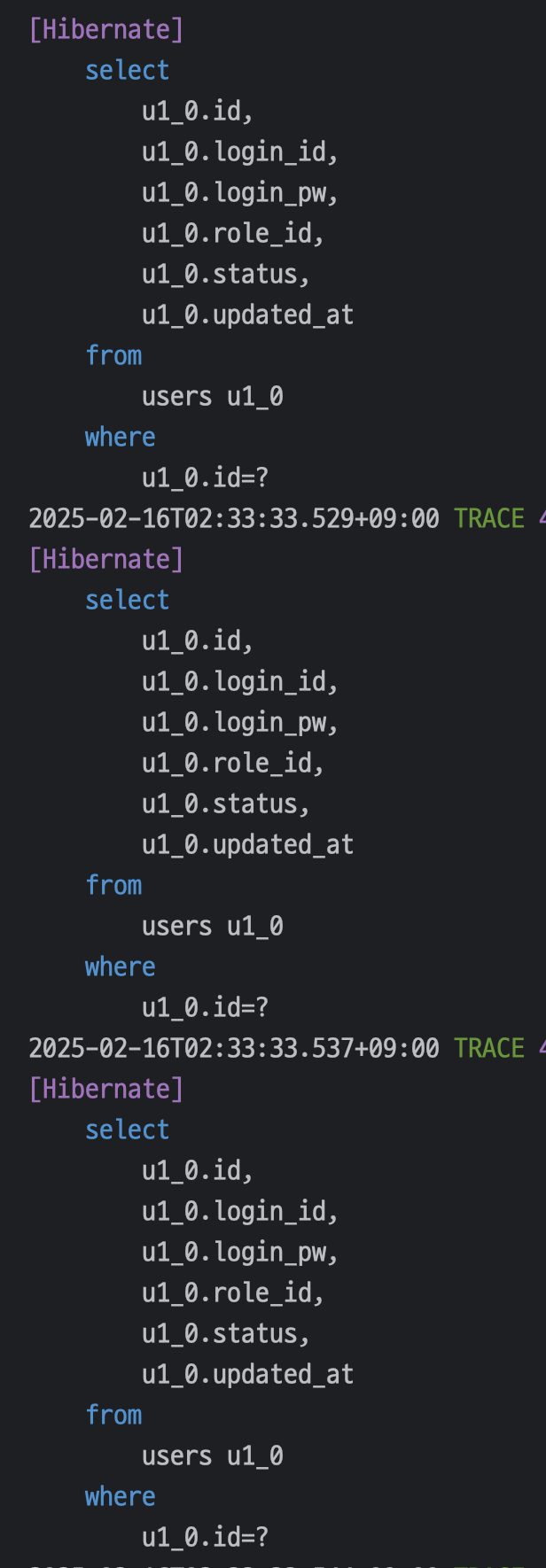
다음 스크린샷은 User 테이블을 추가 조회하는 쿼리가 연달아 날아가는 모습이다.
휴가 3건이면 쿼리가 3번, 앞으로 유저 수가 100명, 1000명 늘어나면 1000번….
이건 누가 봐도 비효율이다. “차라리 한 방에 가져오면 안 될까?”
JOIN VS FETCH JOIN
👉 결론부터: JOIN FETCH를 쓰면 N + 1을 없앨 수 있지만,
꼭 필요한 경우에만, 그리고 페이징 제약을 기억하면서 사용하자.
JOIN (일반 조인)
@Query("""
SELECT vh
FROM VacationHistory vh
JOIN vh.user u
WHERE vh.startDate >= :lastMonthLastWeek
AND vh.endDate <= :nextMonthFirstWeek
AND vh.department.id = :departmentId
ORDER BY vh.startDate
""")
List<VacationHistory> findAllByDepartment(...);- SQL 차원에서는 JOIN 으로 묶여 한 번에 가져오는 것처럼 보인다.
- 하지만 영속성 컨텍스트에는 VacationHistory 만 저장되고, User 는 프록시 상태로 남는다.
- vh.getUser().getName() 이 호출되는 순간 추가 SELECT 가 날아가 N + 1 발생.
- 연관 필드를 EAGER 로 바꿔도 별도 SELECT 나 조인 으로 한 번 더 불러오는 건 마찬가지일 수 있다.
JOIN을 사용해서 문제를 해결하기 위해서는 DTO 프로젝션 방법을 선택해야한다. (다음글에서 정리)
JOIN FETCH
@Query("""
SELECT vh
FROM VacationHistory vh
JOIN FETCH vh.user u
WHERE vh.startDate >= :lastMonthLastWeek
AND vh.endDate <= :nextMonthFirstWeek
AND vh.department.id = :departmentId
ORDER BY vh.startDate
""")- 단일 쿼리에 VacationHistory와 User 를 모두 끌어와서 즉시 영속성 컨텍스트에 적재.
- 이후 vh.getUser() 를 호출해도 추가 쿼리가 없다 → N + 1 종결
- 내부적으로는 SQL JOIN 으로 구현되지만, JPA가 중복 행을 병합해 엔티티는 하나씩만 유지한다.
항상 FETCH JOIN을 사용하면 안될까?
👍 장점
N + 1 해결 & 직렬화에도 유리
복잡한 매핑이라도 쿼리 1회로 데이터 확보
⚠️ 주의할 점
불필요한 데이터까지 한 번에 끌어와서 메모리 낭비할 수 있다.
컬렉션(fetch join) + 페이징을 동시에 쓰면,
(Hibernate 기준) DB단 LIMIT/OFFSET이 무력화되고
모든 데이터를 긁어온 뒤 메모리 페이징 → OOM 위험하다.
마무리
N + 1 문제가 발생한 것과 어떻게 문제를 해결할 수 있는지 간단하게 작성해보았다.
하지만 아직 구체적인 상황에 따라서 최적의 선택을 하는 방법까지 학습하지 못했다.
무조건 FETCH JOIN을 사용하는 것도 올바른 방법도 아니라고 생각한다. 관련된 내용을 정리해서 추가 글을 작성해야겠다.
