1강 DKT 이해 및 DKT Trend 소개
- DKT 문제 소개 및 필요성 이해
DKT 란
Deep Knowledge Tracing
지식 구성 요소 ( 학생에게서 알고 싶은 요소 ) 와 지식 상태 ( 각 지식에 대한 학생의 이해도 ) 를 이용하여 변화하는 지식 상태를 지속적으로 추적
데이터가 많아질수록예측은 정밀해진다.데이터가 적을수록오버피팅 현상이 쉽게 생긴다.- Regularization
- Dropout
- Batch Normalization
- Data 증대
- 캐글은 주어진 dataset 에서 feature engineering, skill 을 이용해 성능을 최대화
- 현업에서는 데이터를 증가시키거나 문제를 재정의 하는 것이 빠른 방법일 수 있다.
문제 추천, 학업도 예측 및 파악 등에 사용할 수 있다.
DKT 대회
- 주어진 sequence 다음에 올 문제를 맞출지 / 틀릴지 예측하는 binary classification 문제
Metric
AUC / ACC
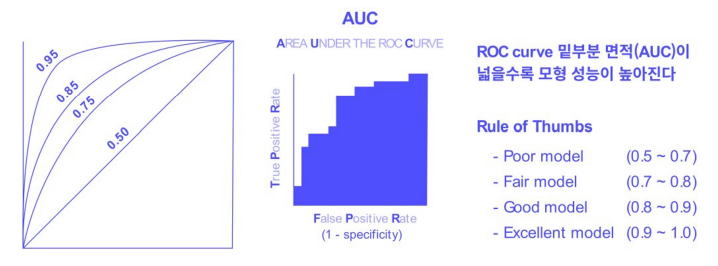
1 ) AUC-ROC Curve
- AUC( Area Under the Curve ) : ROC 곡선 아래 영역
- AUC 가
높을수록클래스를 구별하는 모델의 성능이 높다.
- AUC 가
- ROC ( Receiver Operating Characteristic ) : 모든 임계값에서 분류 모델의 성능을 보여주는 그래프
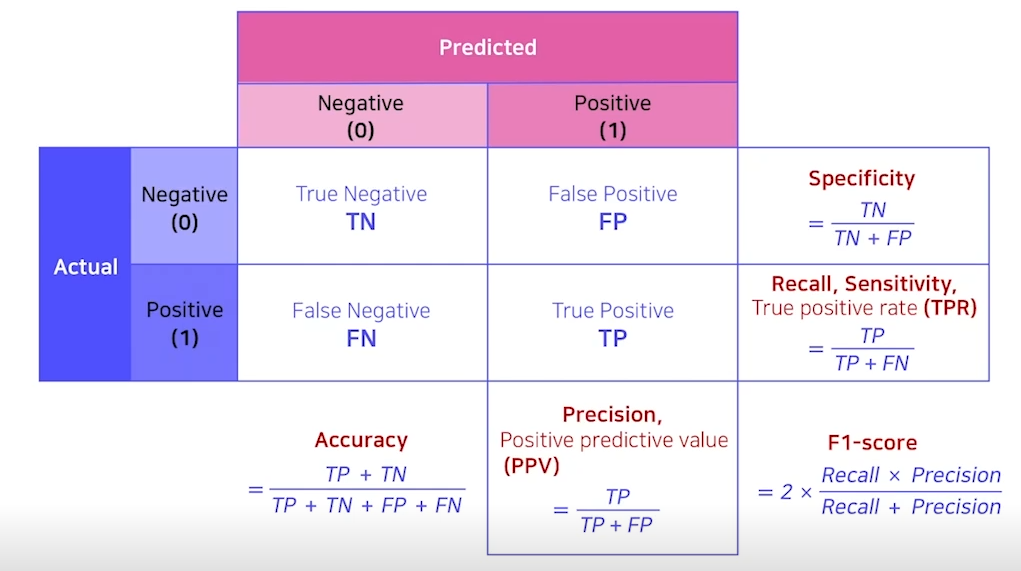
2 ) Confusion Matrix
- 참고 : 표의 기본 구성은 아래와 같다.
- confusion matrix 가 주어졌을 때, 구성이 같은지 확인해야한다.
- 단점
- 0 과 1 사이의 예측 값을 threshold 를 이용해 0 또는 1 의 값으로 결정한다.
- threshold 에 metric
- Accuracy : 전체 중에 맞은 비율( TP + TN )
- Precision : 모델이 positive 로 예상한 것 중 실제로 positive 인 것의 비율
- 모델이 적게 예측할수록 높아진다.
- Recall : 실제 positive 인 것 중에 모델이 positive 로 예상한 것의 비율
- 모델이 많이 예측할수록 높아진다.
precision 과 recall 은 trade-off 관계
- F1-Score : Precision 과 recall 을 조화롭게 표현
3 ) AUC
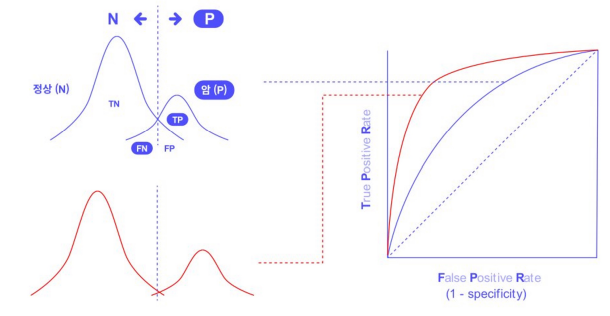
- FPR : x 축, Fasle Positive Rate
- 실제 False 인 것 ( TN + FP ) 중 틀린 것 ( FP ) 의 비율
- TPR : y 축, True Positive Rate
- 실제 True 중에 ( FN + TP ) 맞은 것 ( TP )의 비율
참고일반적인 성능 지표가 있지만, 절대적인 기준은 아니다.- inbalance 일수록 AUROC 는 낮게 나온다.
AUROC 는 분포 metric :0 과 1 의 분포 차이가 클수록 높게 측정된다.
- 예측이 100% 잘못되었을 경우, AUC 는 0.0
- 예측이 100% 정확한 모델의 AUC 는 1.0
AUC가 이상적인 2가지 이유
- 1 ) 척도 불편 절대값이 아니라 예측이 얼마나 잘되는지 측정한다.
- 2 ) 분류 임계값 불변으로 어떤 분류 임계값이 선택되었는지와 상관없이 모델의 예측 품질을 측정한다.
단점
- 1 ) 잘 보정된 확률 결과가 필요한 경우에는 AUC 로는 이 정보를 알 수 없다.
- 2 ) 분류 임계값 불변이 항상 이성적이지는 않다.
- 허위 음성 ( FN ) , 허위 양성 ( FT ) 중 FN 이 증가하더라도 FT 를 낮추고 싶은 경우, AUC 가 적합하지 않다.
★ imbalace data 에서 AUC 가 비교적 높게 측정되는 경우가 있음
- imbalance data 는 True label 이 더 적다.
- True positive 가 더 적으므로 y 축으로 가파른 상승
- Test data 가 동일하게 유지된다는 가정하에 binary classification 모델의 상대적인 성능 비교가 가능하다.
DKT Trend
DKT 는 Sequence Data 를 다루므로 자연어 처리 분야의 발전에 많은 영향을 받는다.
Model
Transformer 위주의 모델링이 대세
- 최근에는 GNN 과 CNN 을 활용하려는 시도가 있었음
- LSTM, MANN, GCN, Transformer, Bi-LSTM, GNN, Attention, CNN, 1D-CNN
Data
- 최근부터 Elasped time, Lag time 등 다양한 feature 활용
- Question ID, Category, Text Description, Response, Timestamp, Elasped time, Lag time
Regularization Term
- 기존 모델 성능 개선을 위해 정규화 항을 추가하여 개선 시키려는 시도가 늘어남 ( 구조 변경 x )
- Reconstruction, Waviness, Skill
Embedding
- 기존의 방식이 활용됨
- qDKT, fastText 활용은 발전의 기회를 보여줌
- Category, Position, fastText
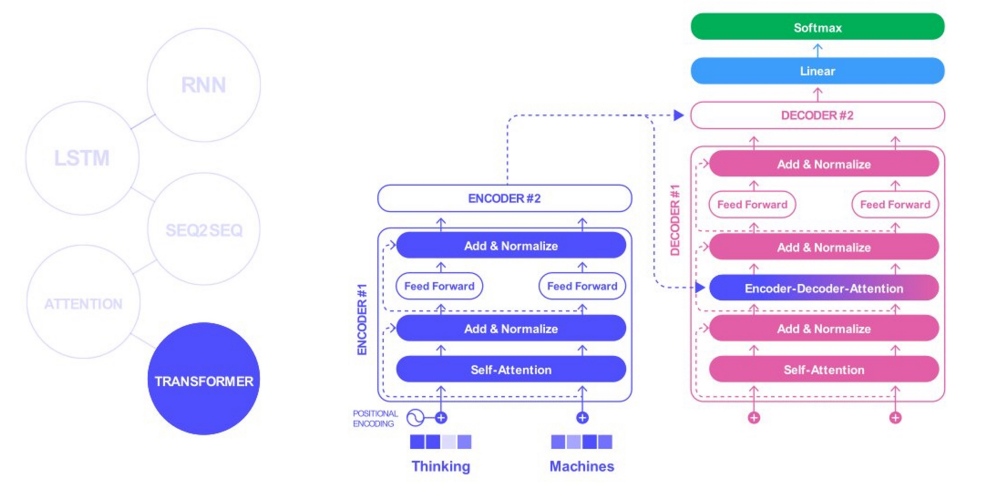
Sequence Data
RNN LSTM SEQ2SEQ ATTENTION TRANSFORMER
1 ) RNN
한계점: 이전 단어 정보를 반영하지 못함
2 ) LSTM
- Forget gate : 이전 정보를 얼마나 반영할지 결정
- Input gate : 현재 정보를 얼마나 반영할지 결정
- Output gate : Forget 과 input 의 정보를 조합하여 output 산출
한계점: 기계 번역 등의 언어 모델에 활용하기 위한 모델의 연구가 필요해짐
3 ) SEQ2SEQ
- Encoder 와 Decoder 모두 input 이 CV ( context vector )
한계점: 150 ~ 200 step 이 넘어가면 이전 정보를 받아들이지 못함 ( context vector 에 너무 의존하는 문제 )
4 ) ATTENTION
- Decoder 에서 output 을 만들 때 cv ( context vector ) 에만 의존하는 것이 아니라, encoder 의 각 정보를 함께 이용
한계점: 학습 속도가 느림, 병렬 처리가 어려움
3 ) TRANFORMER
- 병렬 처리를 위해 sequence 를 끊음
- 어순은 positional encoding 으로 해결
- BERT 에서는 positional embedding 을 한다. ( self-attention .. )
- 어순은 positional encoding 으로 해결
- Feature engineering 으로 sequence 에 대한 정보를 녹여내면 (?) LGBM, LSTM, Conv-1D, TF 로 시퀀스 모델링을 할 수도 있다.
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
