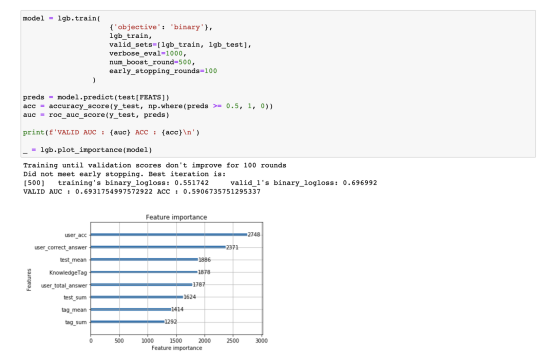
3강 Baseline (LGBM, LSTM, Transformer)
GOAL
- 데이터 접근 방식을 배워보자.
- 1 ) Tabular approach
- 데이터를 정형 데이터로 취급하여 LGBM 과 같은 모델을 통해 예측하는 방식
- 2 ) Sequential approach
- RNN, LSTM, Transformer 와 같은 시계열 모델들을 사용해 예측
Sequence 모델링
feature engineering 예시
- 특정 시간 및 요일의 인기 정보
- 할인 금액으로 할인 건수 반영
- 프로모션 반영 비율
- ( 문제 푸는 데 소요된 시간 - 평균 소요 시간 ) 으로 특성을 줄 수 있다.
- 타켓, 업종별 구매 금액 컬럼을 추가하여 소비 성향을 반영할 수 있ㄲ다.
1 ) 집계 ( aggregation ) , Feature Engineering
- 시퀀스를 녹여내기 위한 feature engineering 이 필수적이다.
단점정보의 손실이 발생
2 ) Transaction 그대로 사용, Feature Engineering
- architecture 를 잘 설계해서 기본 피쳐만 쓸지, feture engineering 을 통해 추가할지 결정해야한다.
Tabular Approach
정형 데이터 형태로 가정하고 모델 적용
1 ) 기본적인 feature engineering 1
문제를 푼 시점에서의 사용자의 적중률 =
- 문제를 푼 갯수 또는 비율을 새로운 column 으로 제공할 수 있다.
2 ) 기본적인 feature engineering 2
문제 및 시험 별 난이도 =
- 시험 별 평균 또는 태그 별 평균을 추가하여 새로운 column 으로 제공할 수 있다.
3 ) ★ Train/Test Data Split : 사용자 단위로 split
Train 과 Test 를 어떻게 나눌지 판단한다.
- Data leakage 가 발생하지 않는지 주의해야한다.
- Train/Test Data Set 을 적절히 나누어야 generation 성능이 높아진다.
사용자 별로 묶어서 split 해야 user 의 실력이 보존된다.
참고동일인의 데이터는 train 과 validation 중 한 곳에 포함되어야 한다.
4 ) Model Training
하이퍼 파라미터 및 feature 들을 조절해가며 최고의 모델을 확인한다.
참고하이퍼 파라미터는 되도록 마지막에 조절하는 것이 좋다.- lightGBM 에는 overfitting 을 방지하는 parameter 등 많은 parameter 가 존재한다.
- DKT 문제에서 메인으로 사용되는 모델은 아님
- lightGBM 에는 overfitting 을 방지하는 parameter 등 많은 parameter 가 존재한다.
Sequential Data
Task 의 종류에 따라 입출력의 구조가 다르다.
1 ) One-to-One
주식의 시가로 종가 예측
2 ) One-to-Many
3 ) Many-to-One
마지막 sequence 에서 어떤 일이 생길지 추론한다.
활용DKT, DSB, 오늘의 주가 예측예를 들어소비 정보로 성별, 이탈율 추론 등4 ) Many-to-Many
5 ) Sequence-to-Sequence
LSTM
1 ) Input/Output Shape In LSTM
- ( batch size, sequence size, hidden_size )
import torch
import torch.nn as nn
# Size : [batch_size, seq_len, input_size/num_of_features]
input = torch.randn( 3, 5, 4 )
lstm = nn.LSTM(input_size=4, hidden_size=2, batch_first=True)
output, h = lstm(input)
output.size() # => torch.Size([3, 5, 2]), batch_size, seq_len, hidden_size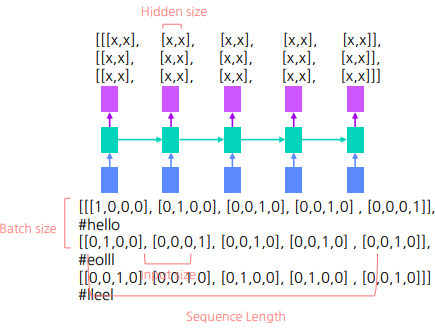
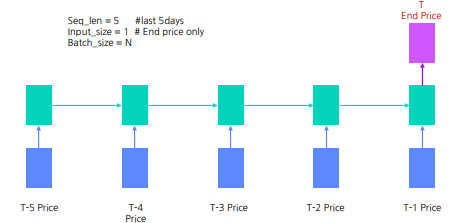
2 ) LSTM Example
- seq_len = 5 # last 5 days
- Input_size = 1 # End price only
- Batch_size = N
참고 Linear layer 와 projection 으로 차원을 늘리고 줄일 수 있다.
LSTM 을 활용한 주식 가격 예측 #1 : 종가만 사용
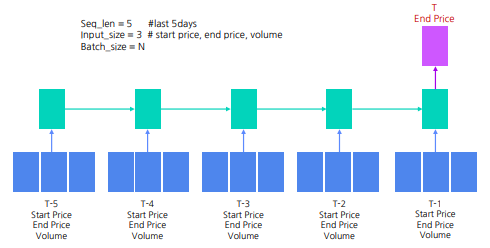
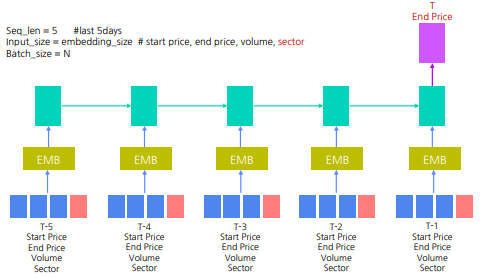
LSTM 을 활용한 주식 가격 예측 #2 : 시가, 종가, 거래량 사용 (모두 연속형 변수)
LSTM 을 활용한 주식 가격 예측 #3 : 시가, 종가, 거래량, 섹터 사용 (연속형과 범주형의 조합)
- label encoder 와 dictionary mapping 등으로 범주형 변수를 실수로 바꾼 후 continuous 변수와 concat 하여 embedding layer 에 전달
Transformer
1 ) Input/Output Shape In Transformer (hugging face)
config = BertConfig(
3, # vocab_size, not used
hidden_size=4, num_attention_heads=1)
# Size: [batch_size, seq_len, input_size]
input = torch.randn( 3, 5, 4 )
# Size: [batch_size, seq_len]
mask = torch.randn(3, 5)
transformer = BertModel(config)
encoded_layers = transformer(inputs_embeds=input, attention_mask=mask)
sequence_output = encoded_layers[0]
sequence_output.size() #=>torch.Size([batch_size, seq_len, input_size])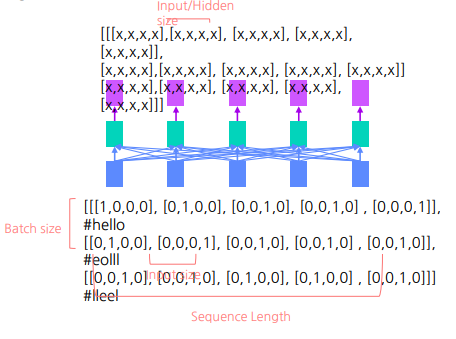
2 ) Transformer Example
sequential 한 요소를 제거하고 self-attention 을 도입
- seq_len = 5 # last 5 days
- Input_size = 1 # End price only
- Batch_size = N
참고 Linear layer 와 projection 으로 차원을 늘리고 줄일 수 있다.
Transformer를 활용한 주식 가격 예측 #1 : 종가만 사용
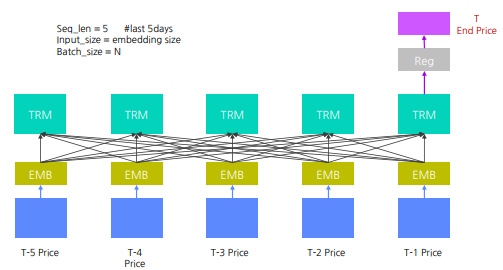
Transformer를 활용한 주식 가격 예측 #2 : 시가, 종가, 거래량 사용 (모두 연속형 변수)
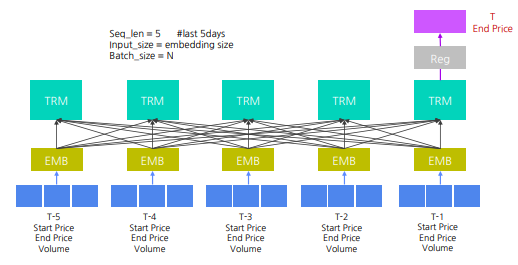
Transformer를 활용한 주식 가격 예측 #3 : 시가, 종가, 거래량, 섹터 사용 (연속형과 범주형의 조합)
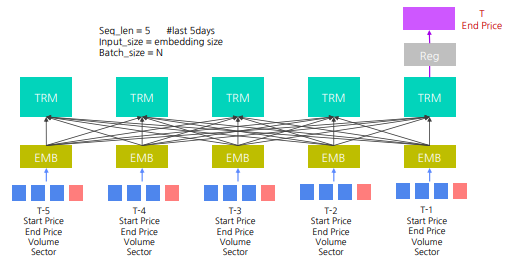
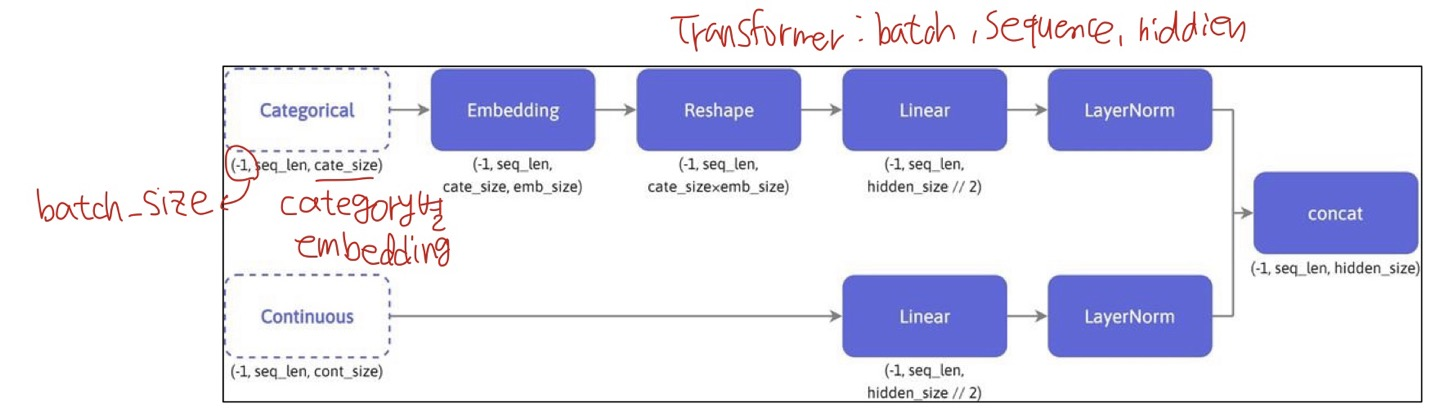
- label encoder 와 dictionary mapping 등으로 범주형 변수를 실수로 바꾼 후 continuous 변수와 concat 하여 embedding layer 에 전달
Embedding
*label encoder 와 dictionary mapping** 등으로 범주형 변수를 실수로 변형하여 embedding layer 로 전달 category 수 만큼의 lookup table 로 embedding vector 가 산출된다.
- category 별로 embedding
★ Many to Many, Many to One 등의 요소를 이해하고 , input/output shape 을 결정할 수 있다면 문제를 풀 수 있다 !
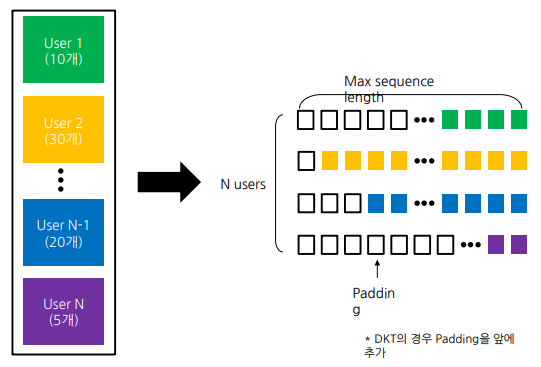
Input Transformation
사용자 단위로 Sequence 생성
- 사용자의 문제 풀이를 하나의 문장으로 생각해보자.
참고 padding 은 앞/뒤 어디에 넣어도 성능적으로 큰 차이를 보이지 않는다.
Max Sequence 값을 hyper parameter 로 보고, 성능에 가장 도움되는 sequence length 로 지정
Modeling
LSTM
기본으로 제공되는 feature 들을 병합하여 LSTM 에 주입
def forward(self, input):
test, question, tag, _, mask, interaction, _ = input
batch_size = interaction.size(0)
# Embedding
embed_interaction = self.embedding_interaction(interaction)
embed_test = self.embedding_test(test)
embed_question = self.embedding_question(question)
embed_tag = self.embedding_tag(tag)
embed = torch.cat([embed_interactioon,
embed_test,
embed_question,
embed_tag,],2)
X = self.comb_proj(embed)
######## LSTM Layer ####################
hidden = self.init_hidden(batch_size)
out, hidden = self.lstm(X, hidden)
#######################################
out = out.cotiguous().view(batch_size, -1, self.hidden_dim)
out = self.fc(out)
preds = self.activation(out).view(batch_size, -1 )
return predsLSTM + Attention
- 기존 LSTM 모델에 Attention Layer 추가
def forward(self, input):
test, question, tag, _, mask, interaction, _ = input
batch_size = interaction.size(0)
# Embedding
embed_interaction = self.embedding_interaction(interaction)
embed_test = self.embedding_test(test)
embed_question = self.embedding_question(question)
embed_tag = self.embedding_tag(tag)
embed = torch.cat([embed_interactioon,
embed_test,
embed_question,
embed_tag,],2)
X = self.comb_proj(embed)
hidden = self.init_hidden(batch_size)
out, hidden = self.lstm(X, hidden)
out = out.contiguous().view(batch_size, -1, self.hidden_dim)
######## LSTM Layer + Attention ####################
extended_attention_mask = mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=torch.float32)
extended_attention_mask = ( 1.0 - extended_attention_mask ) * -10000.0
head_mask = [None] * self.n_layers
# BERT 의 attention layer
encoded_layer = self.attn(out,extended_attention_mask, head_mask=head_mask)
sequence_output = encoded_layers[-1]
#######################################
out = self.fc(sequence_output)
preds = self.activation(out).view(batch_size, -1 )
return predsBERT
- 기존의 LSTM 레이어를 BERT 로 대체
def forward(self, input):
test, question, tag, _, mask, interaction, _ = input
batch_size = interaction.size(0)
# Embedding
embed_interaction = self.embedding_interaction(interaction)
embed_test = self.embedding_test(test)
embed_question = self.embedding_question(question)
embed_tag = self.embedding_tag(tag)
embed = torch.cat([embed_interactioon,
embed_test,
embed_question,
embed_tag,],2)
X = self.comb_proj(embed)
######## BERT Layer ####################
# Bert
encoded_layers = self.encoder(inputs_embeds=X, attention_mask=mask)
#######################################
out = encoded_layers[0]
out = out.contiguous().view(batch_size, -1, self.hidden_dim)
out = self.fc(out)
preds = self.activation(out).view(batch_size, -1 )
return predsFE and Model
Konstantin Yakovlev - How all works together
데이터 이해 및 EDA 과정을 마쳐두자.
- 이전 캐글 대회 및 현재 데이터에 대한 topic 을 읽으면서 데이터 이해도 높이기
- Make ground baseline with no fe
- baseline 을 최대한 빨리 만들자.
- Make a small FE and see I you can understand data you have
- 간단한 feature engineering 을 통해 데이터를 이해해보자.
- Find good CV strategy
- K-fold, stratified, time split 등 적절한 cross validation strategy를 찾아보자.
- Feature selection
- feature 를 넣고 빼면서 cv 와 leader board 성능이 함께 올라가는 것을 찾아보자.
- Make deeper FE
- Tune Model (crude tuning)
- Try other Models (never forget about NN)
- Try Blending/Stacking/Ensembling
- voting, blending ( means, ranking .. ) , seed ensemble
- Final tuning
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
