🐬 o( ̄▽ ̄)ブ Airflow 사용 경험기를 담고 있습니다.
- Local 환경에서 필요한 package 를 모두 설치하여 진행했습니다.
- Reference : 시흠님 Apache Airflow Tutorials for Beginner
- Reference : Apache Airflow 공식문서
01. Airflow 로 자동화할 태스크 정하기
- 주변 시설 공공 데이터 다운로드
- 공공 데이터 업데이트 주기가 일정하지 않으므로 주기 단위로 수집하는 것은 불필요
05.개선 방안에서 해결 방법 제시
- 수집한 주변 시설 데이터를 활용하여 격자 별 점수 산정
- 공공 데이터 업데이트 주기가 일정하지 않으므로 주기 단위로 실행하는 것은 비용이 너무 비쌈
05.개선 방안에서 해결 방법 제시
- 부동산 매물 API 데이터 수집 ( 완료 )
- 수집한 데이터에 주변 시설 정보 매칭하기 ( 완료 )
- 처리한 데이터 DB(MySQL) 에 적재 ( 완료 )
02. 에어플로우 설치
OS 및 Python
- Ubuntu 18.04
- Python 3.6.9
- Refreence 는 Python 3.8.x 로 진행했으나, 현재 글에서는 GCP 에서 제공한 버전 그대로 사용
# 가상환경 생성
python -m venv .venv
source .venv/bin/activate # 패키지 설치
pip install pip --upgrade
pip install apache-airflow==2.2.303. Airflow 배포
1 ) Airflow 루트 경로 설정
mkrdir airflow
cd airflow
# 현재 경로를 프로젝트의 루트 경로로 설정
export AIRFLOW_HOME=.
# meta database의 default 값은 MySQL
# airflow 환경의 역할이나 권한을 설정하며 현재 및 과거 DAG task 실행 결과를 저장
airflow db init2 ) 관리자 계정 생성
airflow users create \
--username 유저네임 \
--password 비밀번호 \
--firstname bbang2 \
--lastname ho \
--role Admin \
--email hobbang2@abcd.com3 ) Webserver 및 Scheduler 실행
airflow webserver --port 8080
airflow scheduler04. Airflow DAG 작성하기
dags라는 명칭의 폴더 안에 작업
- DAG : Directed Acyclic Graph
- Airflow 에서 파이프라인 단위의 개념
1 ) DAGs Example
TODO
- DAG 정의
- Task 정의
a ) DAG 정의
with DAG(
dag_id='zigbang_whole_test', # DAG 식별자용 아이디
description='My DAG', # DAG 설명
default_args=default_args,
schedule_interval='@once', # 일회성 실행
# schedule_interval=timedelta(days=1), 1일을 주기로 실행
tags=['hobbang_house']
) as dag:b ) Task 정의
- Reference : 시흠님 Apache Airflow Tutorials for Beginner
t1 = BashOperator(
task_id="print_hello",
bash_command="echo Hello",
owner="heumsi", # 이 작업의 오너입니다. 보통 작업을 담당하는 사람 이름을 넣습니다.
retries=3, # 이 Task가 실패한 경우, 3번 재시도 합니다.
retry_delay=timedelta(minutes=5), # 재시도하는 시간 간격은 5분입니다.
)def print_world() -> None:
print("world")
# Task를 정의합니다.
# python 함수 print_world를 실행합니다.
t2 = PythonOperator(
task_id="print_world",
python_callable=print_world,
owner="heumsi",
retries=3,
retry_delay=timedelta(minutes=5),
)c ) Task 의존성(순서) 정의
t1 >> t22 ) 응용
- 부동산 매물 API 데이터 수집
- 수집한 데이터에 주변 시설 정보 매칭하기
- 처리한 데이터 DB(MySQL) 에 적재
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
from crawler_dong import get_whole_house_info_from_zigbang
# from airflow.providers.mysql.operators.mysql import MySqlOperator
from classify_house_by_grid import match_grid_id
from airflow.providers.mysql.operators.mysql import MySqlOperator
default_args = {
'owner': 'hobbang',
'depends_on_past': False, # 이전 DAG의 Task가 성공, 실패 여부에 따라 현재 DAG 실행 여부가 결정. False는 과거의 실행 결과 상관없이 매일 실행한다
'start_date': datetime(2022, 4, 25),
'retires': 1, # 실패시 재시도 횟수
'retry_delay': timedelta(minutes=5) # 만약 실패하면 5분 뒤 재실행
}
create_str = ''
update_str = ''
insert_str = ''
# with 구문으로 DAG 정의
with DAG(
dag_id='zigbang_whole_test',
default_args=default_args,
schedule_interval='@once', # 일회성 실행
tags=['hobbang_house']
) as dag:
python_crawling_zigbang= PythonOperator(
task_id='zigbang_crawl',
python_callable=get_whole_house_info_from_zigbang
)
python_match_grid_info = PythonOperator(
task_id='zigbang_match_grid',
python_callable=match_grid_id
)
# HOUSE_INFO2 table 없으면 생성하기
mysql_create_house = MySqlOperator(
task_id="create_house_info2",
mysql_conn_id="hobbang-mysql",
sql=create_str
)
# HOUSE_INFO2 table 기존 매물 sold_yn update
mysql_update_house = MySqlOperator(
task_id="update_house_info2",
mysql_conn_id="hobbang-mysql",
sql=update_str
)
# id 비교해서 새 item 넣어주기
mysql_select_house = MySqlOperator(
task_id="create_insert_info2",
mysql_conn_id="hobbang-mysql",
sql=insert_str
)
# mysql_update_house 제외 : 모델 고도화를 위해 업데이트 중지
python_crawling_zigbang >> python_match_grid_info >> mysql_create_house >> mysql_select_house
05. 공공 데이터 크롤링 자동화 방안
1 ) 데이터 갱신일자를 저장하는 테이블 생성
data_type Integer; # 수집한 데이터의 종류 ( 편의점, 약국, 등등 .. )
udpate_date Date; 2 ) 주기별로 API 또는 페이지 확인
a ) API 를 던져 데이터 배포일자 비교
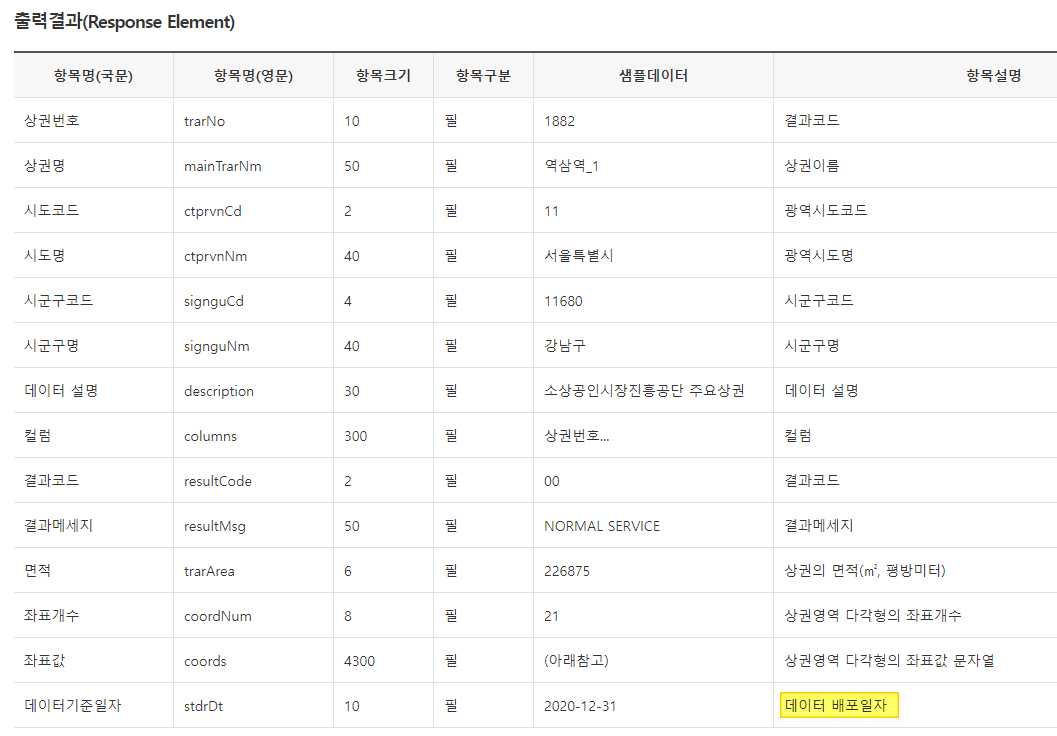
b ) CSV 또는 xml 로 제공하는 데이터의 경우, 페이지에서 직접 수집
- 최종수정일자 갱신 시 CSV 다운로드 하도록 동작
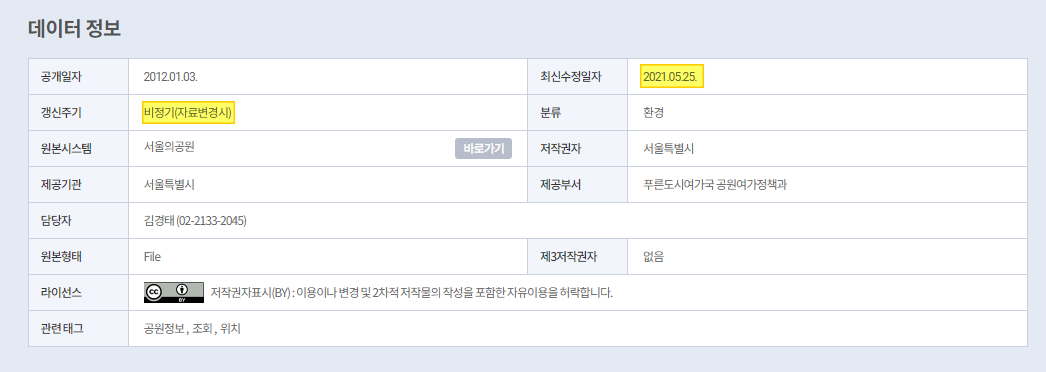
3 ) 테이블의 데이터 갱신일자와 비교하여 바뀌었을 경우 데이터 수집
4 ) Grid Matching
부록. MySqlOperator 사용하기
pip3 install apache-airflow-providers-mysql
- https://stackoverflow.com/questions/66441966/no-module-named-airflow-providers-mysql
- 이 패키지를 깔 때 꽤나 고생했던 기억이 있는데..
- venv 환경 바깥에서 설치를 해주었던 기억이 있다.
1 ) connection 정보 설정하기
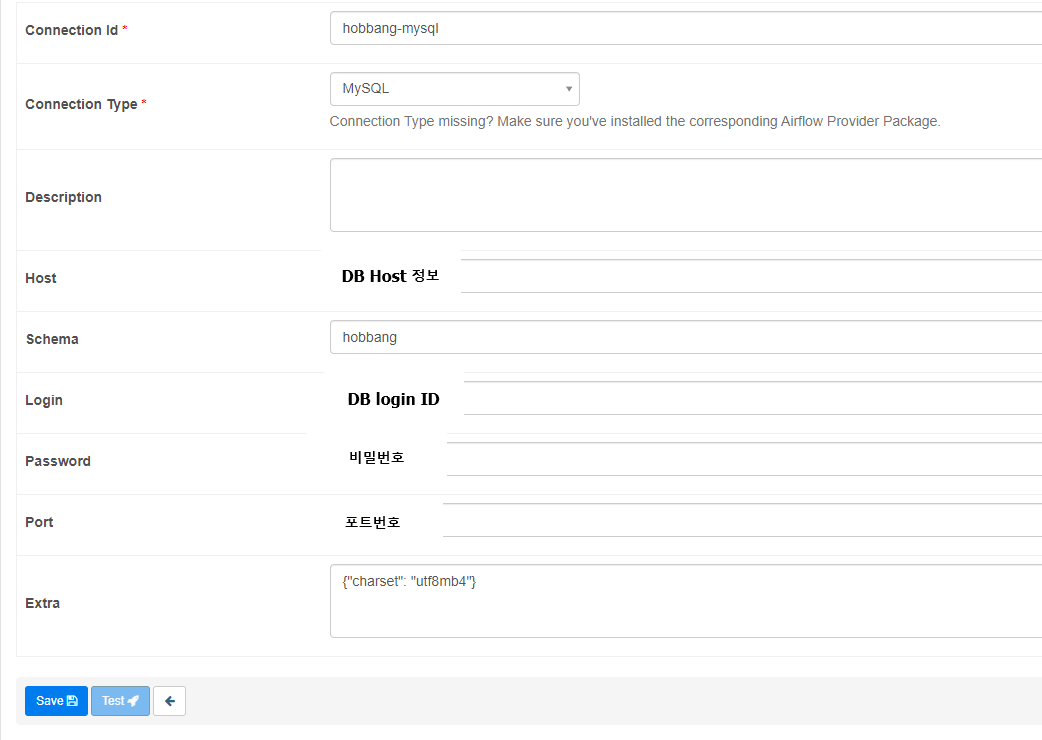
2 ) 정보 입력
- 참고 : charmap error
- {"charset": "utf8mb4"} 를 Extra 로 전달
File "/home/airflow/.venv/lib/python3.6/site-packages/MySQLdb/cursors.py", line 188, in execute query = query.encode(db.encoding) File "/usr/lib/python3.6/encodings/cp1252.py", line 12, in encode return codecs.charmap_encode(input,errors,encoding_table) UnicodeEncodeError: 'charmap' codec can't encode characters in position 438-441: character maps to <undefined>
3 ) DAG 에서 사용
# HOUSE_INFO2 table 기존 매물 sold_yn update
mysql_update_house = MySqlOperator(
task_id="update_house_info2",
mysql_conn_id="hobbang-mysql", # admin 에서 설정해둔 connection id
sql=update_str
)이 글은 네이버 커넥트재단 부스트캠프 AI Tech 교육자료를 참고했습니다.
