Day12_20221005
4강 Convolutional Neural Networks
GOAL
- Convolution의 정의
- Convolution 연산방법과 기능에 대한 학습
- 기본적인 Convolutional Neural Network(CNN) 구조에 대한 학습
KEYWORD
- Convolution
- Continuous convolution
- Discrete convolution
- 2D image convolution
- Convolution Neural Networks
- Convolution layer & Pooling layer
- 이미지에서 유용한 정보를 추출하는 layer
- Fully connected layer
- classificatoin 과 같이 decision making 을 하는 layer
CNN 파라미터는 Stride 와 Padding 에 따라 계산될 수 있음- =
- : output size
- : output channel size
- : input size
- : input channel size
- : padding size
- : kernel size
- : stride size
- Parameter의 수 =
Convolution
- Signal processing 에서 처음 적용된 개념
- 2D image convolution 의 경우, 입력 데이터 공간 , 적용하고자 하는 convolutional filter 로 표현된다.
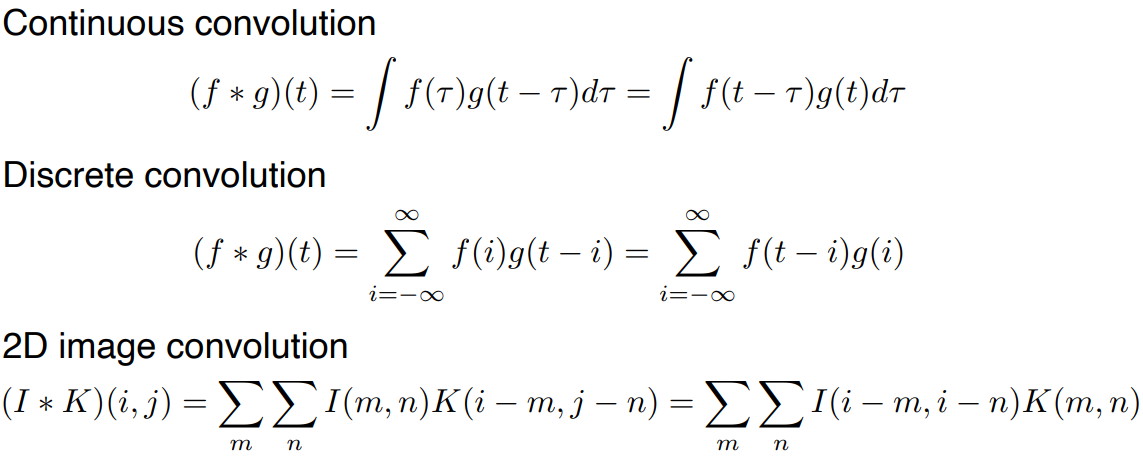
2D image convolution computation
Kernel 을 stride 만큼 움직이면서 겹치는 셀의 값을 곱해 모두 더한 값이 output cell 의 값이 된다.
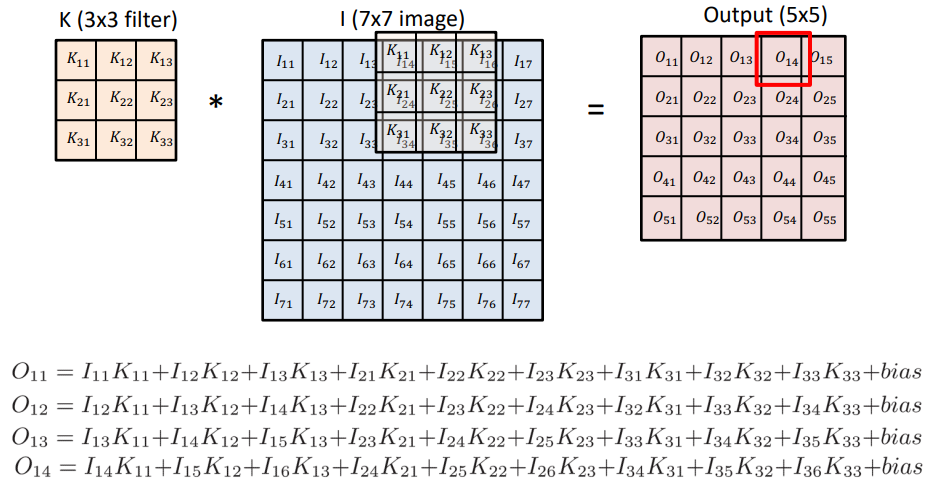
2D convolution in action
예를 들어 값이 모두 인 convolution filter 가 있다고 생각해보면
각 픽셀 값의 평균이 output 을 이루게 되므로 blur 효과가 있다.
filter 의 값에 따라 추출 ( 강조 ) 되는 이미지의 특성이 달라진다.
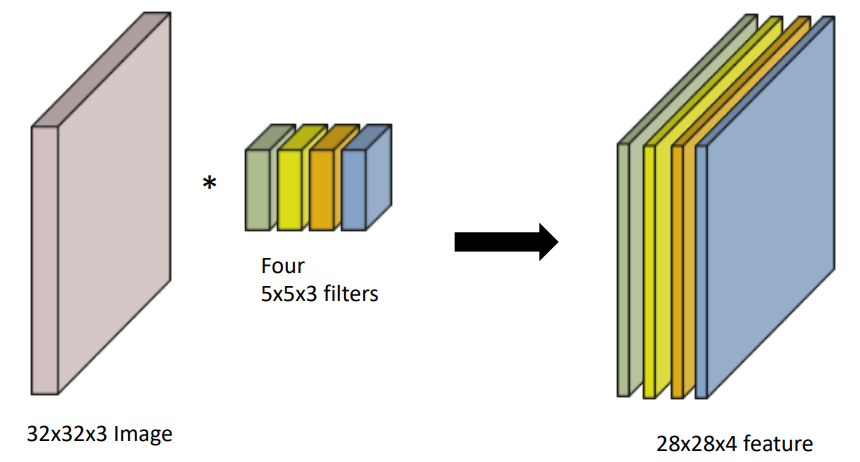
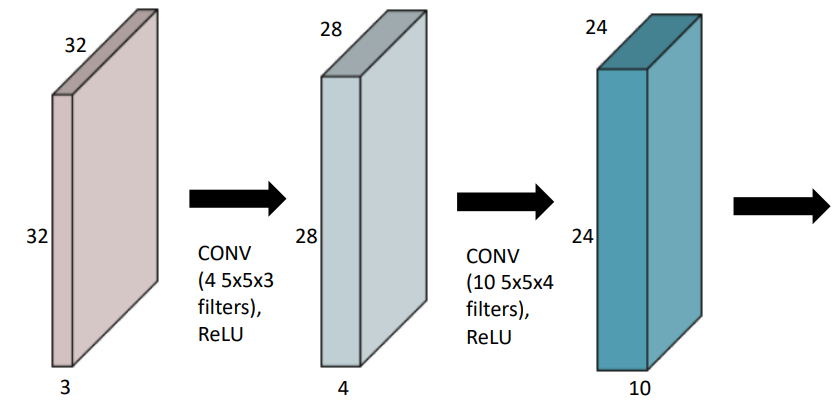
RGB Image Convolution
- Input : 32x32x3
- filter : 5x5x3 , channel = 4
- output : 28x28x4
Stack of covolutions
참고한 번의 convolution 을 하고 나면 activation function 을 적용해준다.- 이 때 첫 번째 layer 에서 parameter 수는 300개이다.
Convolutional Neural Network
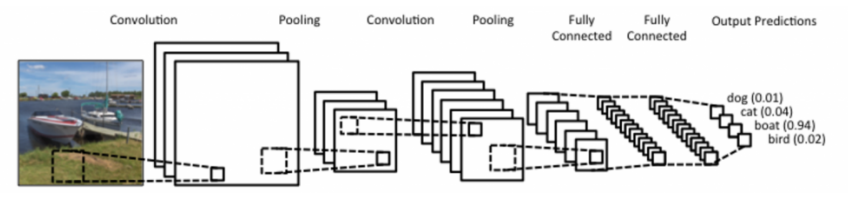
CNN 은 convolutional layer , pooling layer , dense layer 로 구성되어 있다.
- convolutional layer , pooling layer : feature extraction
- dense layer : decision making ( e.g. classification , .. )
참고Parameter 의 숫자를 줄이기 위해 dense layer 를 축소하고 convolutional layer 를 깊이 쌓는 것이 요즘 동향
왜?Parameter 의 숫자가 늘어날수록 학습이 어렵고 Generalization Performance 가 떨어진다고 알려져 있기 때문이다.
어떤 network 를 볼 때 각 layer 의 parameter 숫자와 network 전체 parameter 규모에 대한 감이 있어야 한다.
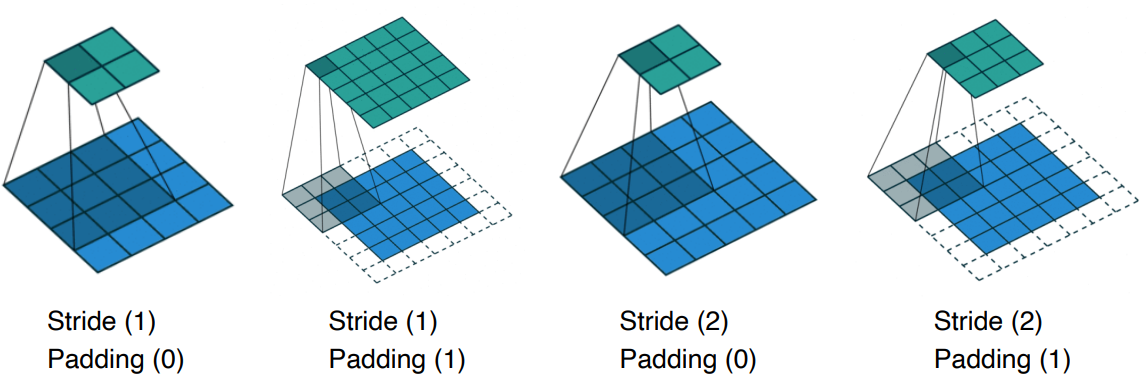
Stride and Padding
- Strde : convolutional kernel 을 몇 픽셀 이동하여 적용할 것인지를 결정
- 필터를 적용하는 간격
- 얼마나 dense / sparse 하게 계산할 것인지를 결정하는 요소
- padding : 가장자리에 어떤 값을 덧대어주어 output 의 image 크기가 줄어드는 것을 방지
- 입력 데이터 주변에 특정 값을 채우는 것
- 주어진 stride 값에 맞게 적절한 padding 값을 선택하면 input 과 output image 의 크기가 같아진다.
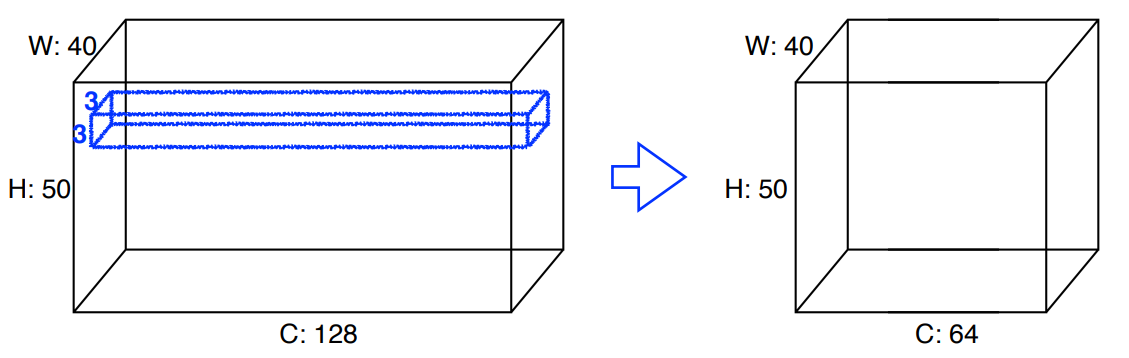
Convolution Arithmetic
Parameter의 수 =
Parameter의 수 =
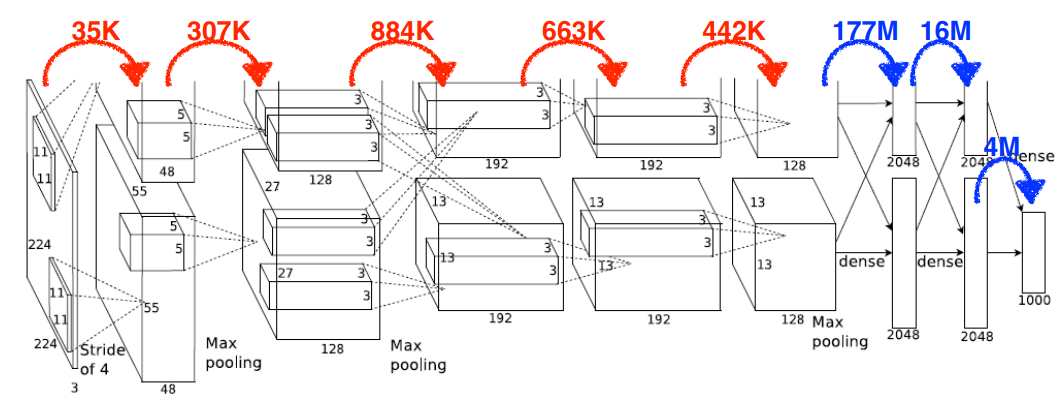
Exercise : Alexnet
참고 Alexnet 은 GPU 사양 문제로 모델을 2개로 나누어 학습함
- 하나의 커널이 모든 위치에 동일하게 적용되어 dense layer 에서 parameter 의 숫자가 훨씬 많다.
- 뒷 단의 fully connected layer 를 최대한 줄이고 앞 단의 convolutional layer 를 깊게 쌓는 구조를 많이 쓴다.
- Convolution layer 를 이용하여 parameter 의 size 를 줄임
- 뒷 단의 fully connected layer 를 최대한 줄이고 앞 단의 convolutional layer 를 깊게 쌓는 구조를 많이 쓴다.
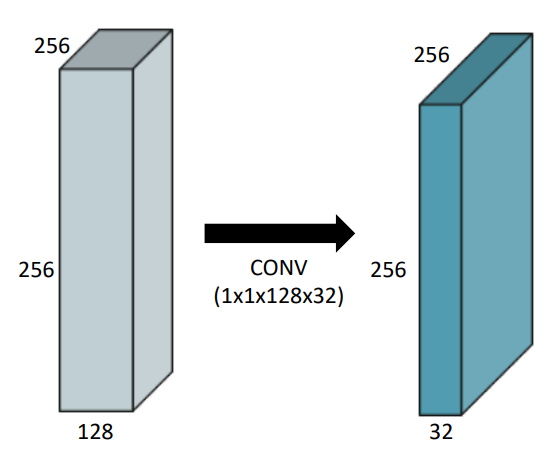
Convolution
Dense Layer 에서 parameters 갯수를 줄이기 위해 사용된다.
사용 목적- Dimension reduction
- To reduce the number of parameters while increasing the depth
예를 들어bottleneck architecture
5강 Convolutional Neural Networks
잘 정리하던 내용이 날아가서 GooLeNet 까지는 머리에 남은 내용만 정리함
GOAL
- 주요 network 에 대한 구조를 살펴보자.
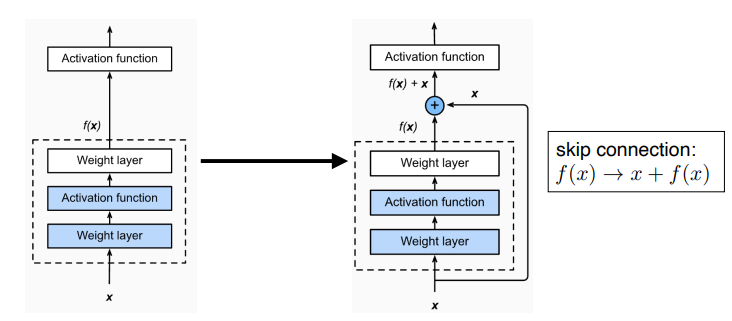
Network Description AlexNet 최초로 Deep Learning을 이용하여 ILSVRC에서 수상 VGGNet 3x3 Convolution을 이용하여 Receptive field는 유지하면서 더 깊은 네트워크를 구성. GoogLeNet Inception blocks 을 제안. ResNet Residual connection(Skip connection)이라는 구조를 제안. h(x) = f(x) + x 의 구조
DenseNet Resnet과 비슷한 아이디어지만 Addition이 아닌 Concatenation을 적용한 CNN.
AlexNet
Gradient vanishing 문제를 개선하기 위해 ReLU function 이 사용됨
filter size 가 11인 것이 특이점 - 현재는 parameter 수를 줄이기 위해 filter size 를 크게 잡지 않는다.
- 구조
- Rectified Linear Unit ( ReLU ) activation
- Preserves properties of linear models
- Easy to optimize with gradient descent
- Good generalization
- Overcome the vanishing gradient problem
- GPU implementation ( 2 GPUs )
- Local response normalizatoin , Overlapping pooling
- LRN : 반응이 좋은 것들을 제외하고 학습
- 현재는 batch normalization 이 사용됨
- LRN : 반응이 좋은 것들을 제외하고 학습
- Data augmentation
- Dropout
- Rectified Linear Unit ( ReLU ) activation
VGGNet
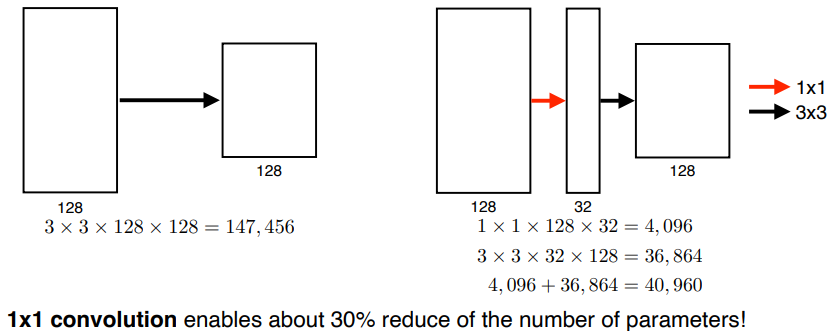
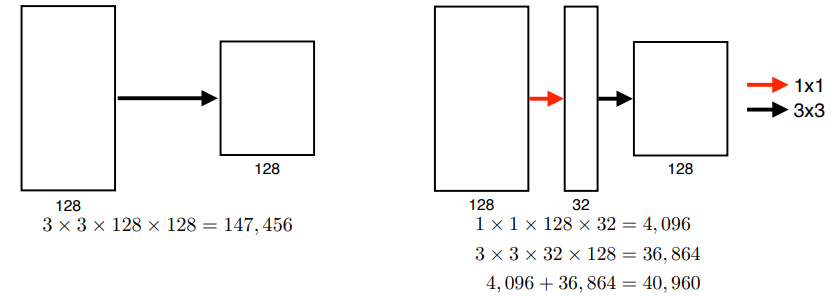
3x3 filter 를 사용해 parameter 의 수를 줄였다.
- Receptive field 는
5x5filter 와 같지만, parameter 의 수는 절반 3x3 계산: 3x3x128x128 + 3x3x128x128 = 294,9125x5 계산: 5x5x128x128 = 409,600]
Receptive field 를 동일하게 유지하면서 parameter 의 크기를 줄일 수 있다. ( 이런 이유로 요즘은 filter size 가 7 을 넘어가는게 잘 없다! )
- 구조
- Increasing depth with 3x3 convolution filters ( with stride 1 )
- 1x1 convolution for fully connected layers
- Dropout (p=0.5)
- layer 수에 따라 VGG16, VGG19
GooLeNet
Network In Network (NIN) 과 Inception Block 으로 구성됨
Inception block 은 1D CONV 연산으로 parameter 의 수를 줄인다.
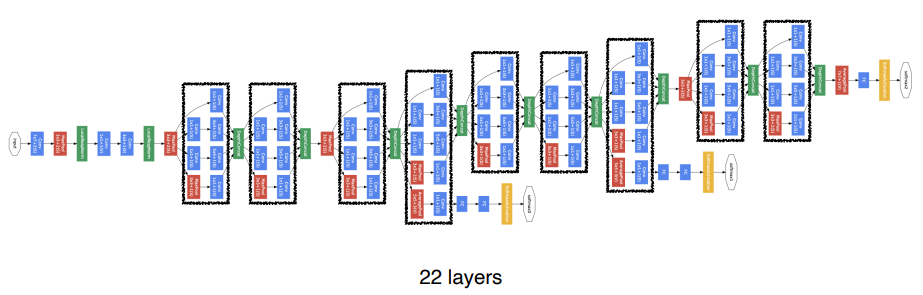
왜 1D Convolution 인가 ?
- 1x1 convolution 은 channel-wise dimension 을 줄인다.
ResNet
다시보기
참고 ResNet 논문 설명
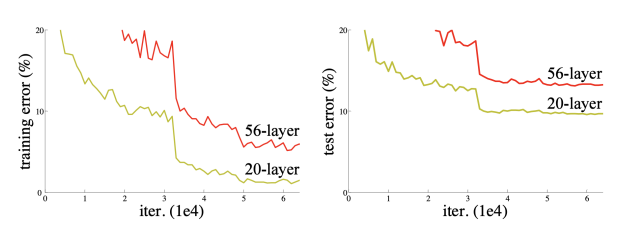
- 기존 문제점 : Network 가 깊어질수록 학습이 어려운 문제 ( 이전의 feature 가 잘 전달되지 않기 때문 )
layer 가 깊어질수록 error 가 커졌다.
- 구조
- Identity map ( skip connection ) 추가
DenseNet
6강 Computer Vision Applications
GOAL
- Segmantic segmentation 의 정의와 핵심 아이디어
- Object detection 의 정의와 핵심 아이디어, 여러 종류들에 대한 학습
Segmantic 방식의 문제점, detection 방식의 문제점 그리고 흐름에 대한 이해를 해보자
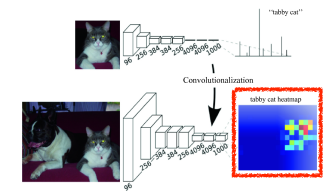
Semantic Segmentation : FCN
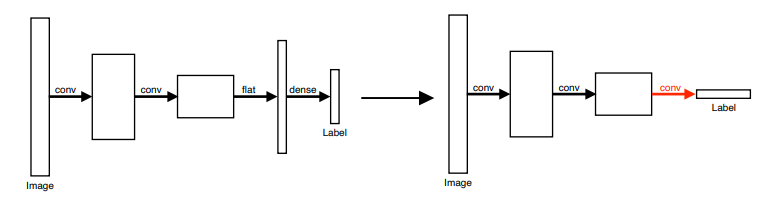
Image 를 다시 fully connected convolution layer 로 전달하여 heat map 을 생성
Convolutionalization
Flatten 과정을 거쳐서 dense layer 로 전달하던 것을 convolutional layer 로 전달
- parameter 의 수는 같다.
- dense layer : 4x4x16x10 = 2,560
- convolution layer : 4x4x16x10 = 2,560
parameter 의 수가 줄어드는 것도 아닌데 왜 하는걸까?
Convolution layer 를 거치면서 heat map 형태로 추출

Deconvolution
참고 Parameter 의 수, architecture 의 크기 계산 관점에서 convolution 의 역연산으로 이해하면 좋다.
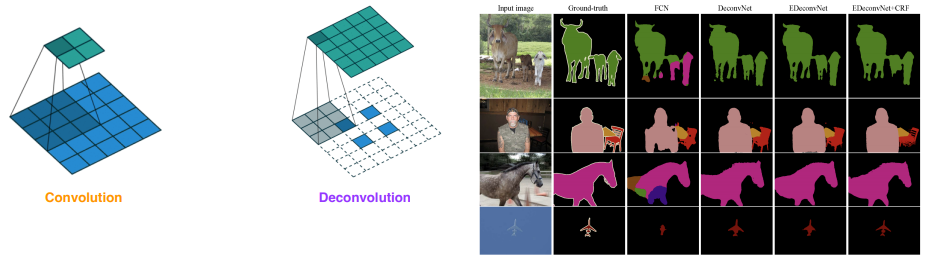
사실 상 convolution 연산을 복원하는 것은 불가능하지만 직관적인 이해만 가져가자구 !
Detection
이미지 안에 어느 물체가 어디 있는지 dectection
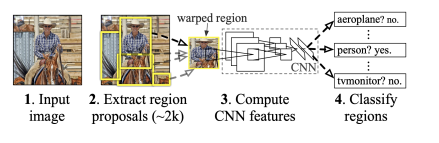
R-CNN
이미지에서 selective search 를 통해 모든 bounding box 를 찾고, 전체에 대해 AlexNet을 수행한다.
단점: 매우 느리고 정확하지 않다.
1 ) Bounding box 를 찾기 - 약 2000개의 selective search
2 ) 각각의 proposal 에 대해 AlexNet을 이용하여 feature 계산
3 ) linear SVMs 를 이용해 분류
SPPNet
이미지 안에서 CNN 을 한 번만 수행하여 feature map 에 해당하는 sub tensor 를 가져온다.
1 ) 이미지 기반으로 bounding box 를 추출
2 ) 이미지 전체에 대해 convolution feature map 을 만든다.
3 ) bounding box 에 해당하는 convolutional feature map 의 Tensor 만 가져온다.
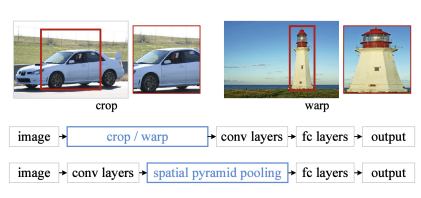
Convolution layer 는 한 번 돌지만 convolutional feature map 에 해당하는 Tensor 를 추출해 가져오는 것만 Region 별로 수행
R-CNN 보다 빠르고 정확하다.
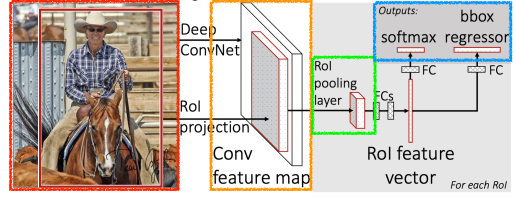
Fast R-CNN
R-CNN의 문제점 : 추출된 모든 bounding box에 대해 CNN 을 해야한다.
참고 SPPNet 과 유사하지만 ROI pooling 을 추가하여 bounding box 도출과 classification 을 한다는 점이 다르다.
1 ) Input 을 받아 semantic search 를 통해 bounding box 를 뽑는다.
2 ) convolutional feature map 을 한 번 얻는다.
3 ) 각 region 에 대해 ROI pooling 으로부터 fixed lenght feature 를 얻는다.
4 ) 분류값과 bounding box 도출
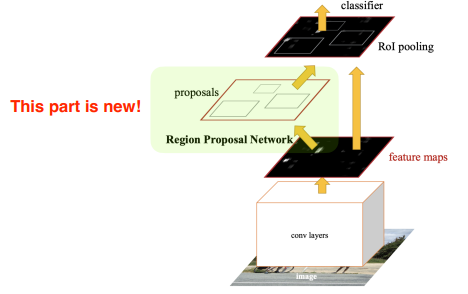
Fater R-CNN
임의의 boundary 를 추적하는 selective search 대신 학습을 통해 bounding box의 candidate 를 가져오자.
Region Proposal Net + Fast R-CNN +
bounding box 추출을 neural network 에 맡긴다.
Region Proposl Net
bounding box 안에 물체가 있을지 없을지를 판단한다.
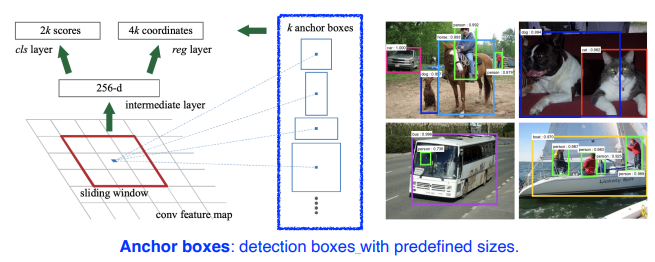
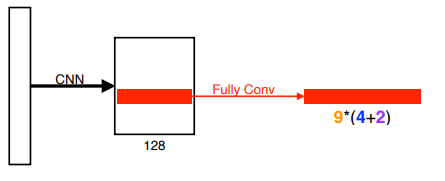
anchor box
미리 정해놓은 bounding box 의 크기
- 9 : 세 개의 region size ( 128, 256, 512) 와 세 개의 비율 ( 1:1, 1:2, 2:1 )
- 4 : 4개의 bounding box regression parameters ( bounding box 를 얼마나 키우고 줄일지 )
- 2 : 2개의 분류 ( 물체가 있다 / 없다 )
YOLO
Region proposal 과정 없이 bounding box 와 classification 을 한 번에 추출
1 ) 이미지를 SxS 격자로 나눈다.
2 ) 각 cell 을 B bounding box 로 예측한다. ( 논문에서 B = 5 )
- 각각의 bounding box 는 box refinement ( x / y / w / h )
- confidence ( of objectness )
3 ) 이 bounding box 에 속하는 object 가 어떤 class 에 속하는지 찾는다.
SxSx(B*5+C)의 channel 을 갖는 tesnor 를 도출한다.
- SxS : grid 의 cell 개수
- B*5 : (x,y,w,h) 의 bounding box offset 과 confidence
- C : class 의 개수
