PPT 에 필기하며 강의 수강중
- PPT 내용 옮기기 완료
2강 추천 시스템 Basic 2
GOAL
연관 규칙 분석 ( Association Rule Analysis )
- 연관 규칙, 빈발 집합, 연관 규칙 척도에 대해 설명
- 연관 규칙 탐색 과정 : Brute-Force 알고리즘
- 최대 단점 : 연산량을 해결하기 위해 제시된 방법론 탐구
컨텐츠 기반 추천 ( Content-based Recommendation )
- 유저 정보나 유저-아이템 상호작용 정보를 사용하지 않는 추천 기법
- 타켓 유저가 구매 / 클릭 등의 피드백을 제공한 아이템들 집합과 유사한 아이템 추천
- TF-IDF 점수를 활용하여 문서 아이템을 추천하는 컨텐츠 기반 추천
참고TF-IDF : 텍스트 데이터 사이의 유사도를 계산하는 가장 고전적인 방법
개요
추천시스템에서는 아직도 머신러닝 기법을 많이 사용한다.
왜 ?딥러닝 모델로 얻을 수 있는 성능 향상 폭이 크지 않다.
왜 ?model inference time ( latency ) 의 이유
- latency 와 trade off 할 만큼 딥러닝 모델이 좋은 성능을 보이지는 않는다.
연관 분석 ( Association Analysis )
- 연관 규칙 ( association rule ) 과 탐색 알고리즘에 대해 알아보자.
연관 규칙 분석 ( Associatioon Rule Analysis, Association Rule Mining )
- 장바구니 분석 혹은 서열 분석
- 연속된 거래들 속 아이템 사이의 규칙을 발견하기 위한 기법
- 하나의 상품이 등장했을 때 다른 상품이 같이 등장하는 규칙을 찾는 것
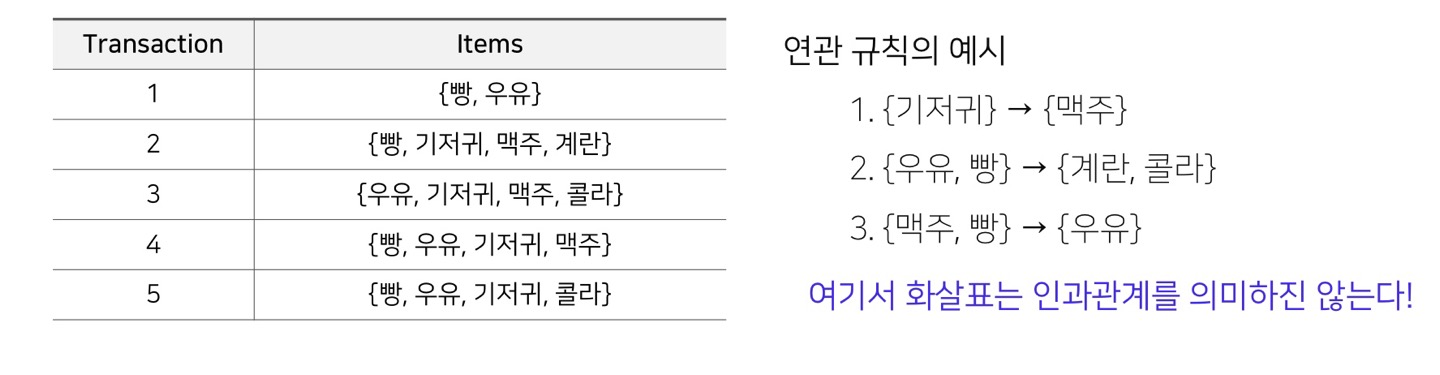
연관 규칙( Association Rule ) 과 Itemset
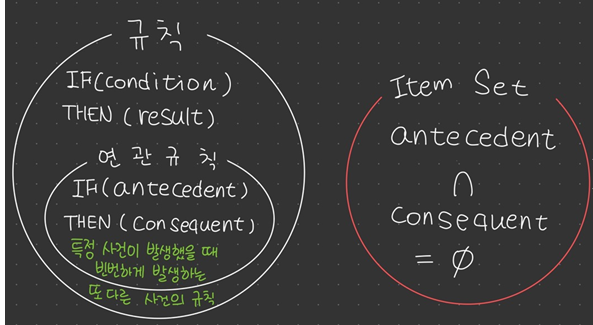
- 규칙 : IF ( condition ) THEN ( result )
- 연관 규칙 : IF ( antecedent ) THEN ( consequent )
- 규칙 중에서 빈번하게 나타나는 것
빈발 집합 ( Frequent Itemset )
- itemset
- 1개 이상의 item 집합
예{ 맥주, 기저귀 }- k-itemset : k 개의 item 으로 이루어진 itemset
- 1개 이상의 item 집합
- support count
- 전체 transaction data 에서 itemset 이 등장하는 횟수
예
- 전체 transaction data 에서 itemset 이 등장하는 횟수
- support
- itemset 이 전체 transaction 에서 등장하는 비율
예
- itemset 이 전체 transaction 에서 등장하는 비율
- frequent itemset
- 유저가 지정한 특정 값 ( minimum support ) 값 이상의 itemset 을 의미
- 반대 : infrequent itemset
- 유저가 지정한 특정 값 ( minimum support ) 값 이상의 itemset 을 의미
연관 규칙 척도 : support, confidence, lift
-
support
빈도가 높거나 구성 비율이 높은 규칙을 찾거나 불필요한 연산을 줄일 때 사용된다.
전체 N 개의 데이터 중에서 X 와 Y 가 함께 등장할 확률
-
confidence
confidence 가 높을수록 유용한 규칙임을 의미
1 ) 전체 N 개의 데이터 중에서 X가 포함된 데이터
2 ) 1 ) 의 데이터에 Y가 포함되어 있는 것
-
lift
: [X가 포함된 transaction 가운데 Y가 등장할 확률] / [Y가 등장할 확률]- lift = 1 : X, Y는 독립
- lift > 1 : X, Y가 양의 상관관계를 가짐
- lift < 1 : X, Y가 음의 상관관계를 가짐
연관 규칙 분석
- 주어진 데이터에서 하나의 상품(값)이 등장했을 때 다른 상품(값)이 같이 등장하는 규칙
연관 규칙 (Association Rule)과 Itemset
- 규칙 : IF (condition) THEN (result)
- {condition} {result}
- 연관 규칙 : IF (antecedent) THEN (consequent)
- 특정 사건이 발생했을 때 빈번하게 발생하는 또 다른 사건의 규칙
- Itemset : antecedent 와 consequent 각각을 구성하는 상품들의 집합
- antecedent 와 consequent 는 서로소를 만족
- antecedent : {빵, 버터}, consequent : {우유}
- antecedent 와 consequent 는 서로소를 만족
빈발 집합 (Frequent Itemset)
- 유저가 지정한 minimum support 값 이상의 itemset
예를 들어전체 transaction data 가 6개이고 두유와 커피가 함께 등장하는 itemset 이 3개일 경우, support 값은 0.5- minimum support 값을 0.3 으로 지정해두었을 경우, {두유, 커피} 는 frequent itemset 이 된다.
연관 규칙 척도 : support, confidence, lift
support
- 두 아이템 셋 X, Y 를 모두 포함하는 transaction 의 비율
confidence
- X 가 포함된 transaction 가운데 Y도 포함하는 transaction 비율 ( Y의 X에 대한 조건부 확률)
- confidence 가 높을수록 유용한 규칙을 뜻함
★ lift
- [X 가 포함된 transaction 중 Y가 나올 확률]/[Y가 나올 확률]
- lift=1 이면 X,Y 독립
- lift > 1 이면 X,Y 가 양의 상관관계, lift < 1 이면 X,Y 가 음의 상관관계
예를 들어[커피를 포함한 거래 중 두유가 포함될 확률]/[두유를 구매할 확률]
연관 규칙 사용법
- 1 ) minimum support, minimum confidence 로 의미없는 rule 제거
- 2 ) lift 값을 내림차순으로 정렬하여 의미 있는 rule 평가
- lift 가 크다는 것은 rule 을 구성하는 antecedent 와 consequent 가 연관성이 높고 유의미하다는 뜻

연관 규칙 탐색
- Brute-force approach 를 사용할 경우, 개별 트랜잭션 아이템들을 풀스킨하여 가능한 모든 itemset 의 support 를 사용한다.
- 가능한 모든 연관 규칙 나열
- 모든 연관 규칙에 대해 개별 support 와 confidence 계산
- minimum support, confidence 만족하는 rule 만 남기고 모두 pruning
문제점complexity 문제문제점제한시간 내에 의미있는 연관 규칙 탐색이 어렵다.
1 ) 가능한 후보 itemset 의 개수 줄이기 : ★ Apriori 알고리즘
2 ) 탐색하는 transaction 의 숫자 줄이기 : Direct Hsahing & Pruning 알고리즘
3 ) 탐색 횟수 줄이기 : FP-Growth 알고리즘
TF-IDF 를 활용한 컨텐츠 기반 추천
Content-based Recommendation
- 유저가 과거에 선호한 아이템과 비슷한 아이템을 추천
- 아이템의 성격에 따라 달라지며 부가 정보에 따라 결정됨
장점: 다른 유저의 정보를 사용하지 않고, 해당 유저가 소비한 item 의 데이터만 사용
- 새로운 item 이나 인기도가 낮은 item도 추천이 가능하다. (collaborator filtering 대비 장점)
- 추천 아이템에 대한 설명이 가능하다.
단점
- 아이템에 적합한 피쳐를 찾는 것이 어려움 (아이템 별로 사용하는 부가정보가 다름)
- 한 분야/장르의 추천 결과만 계속 나올 수 있음 (overspecialization)
- 다른 유저의 다양한 데이터를 활용할 수 없음 (상호작용 정보 사용 불가)
1 ) Item Profile
- Item 이 가진 부가정보 ( Item 의 feature ) 를 찾는 것
- 추천 대상이 되는 아이템의 feature 로 구성된 item profile
- Item 이 가지는 다양한 feature 를 vector 형태로 표현
TF-IDF (Term Frequency - Inverse Document Frequency)
2 ) User Profile
3강 Collaborative Filtering 1
유사도 측정 방법 (Similarity Measure)
두 개체 간의 유사성을 수량화하는 실수 값 함수 혹은 척도
- vector / 분포 / 집합 간의 유사도 등 유사성에 대한 여러 정의가 존재
- 기본적으로 거리의 역수 개념을 사용
- 두 개체 간 거리를 어떻게 측정하느냐 에 따라 동일 데이터 두 개에 대한 다양한 유사도가 존재할 수 있음
🐬 어떤 유사도를 쓸지는
주어진 데이터,추천시스템이 가지는 서비스 특징,offline test등을 고려해서 정함
1 ) Mean Squared Difference Similarity
- 각 기준에 대한 점수의 차이를 계산 (유클리드 거리에 반비례)
- 분모가 0 이 되는 것을 방지하기 위해 분모에 1을 더함 (smoothing)
2 ) Cosine Similarity
- 주어진 두 벡터의 각도를 이용해 구할 수 있는 유사도
- 두 벡터의 차원이 같아야 함
- 두 벡터의 평점의 크기가 달라도 유사도가 높음
3 ) Pearson Similarity (Pearson Correlation)
- 각 베터를 표본평균으로 정규화한 뒤에 코사인 유사도를 구함
- Cosine Similarity 와는 달리 각각 vector rating 크기 차이를 고려할 수 있음
- 도메인에 관계없이 무난한 성능
4 ) Jaccard Similarity
- Cosine, Pearson 유사도와 달리 길이(차원)이 달라도 이론적으로 유사도 계산 가능
- 두 집합이 같은 아이템을 얼마나 공유하고 있는지 나타냄
| 종류 | 비고 |
|---|---|
| Simple Aggregate (popularity, average score, recent uploads) | 인기도 기반 추천 |
| Association Analysis Content-based Recommendation | 연관 분석 , 컨텐츠 기반 추천 |
| Collaborator Filtering | 가장 많이 쓰이고 중요한 추천 기법 |
| Item2Vec Recommendation and ANN | word2vec 을 이용한 기법 |
| Deep Learning-based Recommendation | |
| Context-aware Recommendation | |
| Multi-Armed Bandit(MAB)-based Recommendation |
2강 정리 미완료
3강 키워드
Mean squared difference
Cosine similarity
Jaccard similarity
Pearson similarity
이 글은 네이버 커넥트재단 부스트캠프 AI Tech 교육자료를 참고했습니다.
