1강 강의 소개
zzsza - Product Serving Repogitory
★ 왜 이런 기술이 등장했는지, 어떻게 활용할 수 있을지에 촛점★
수평으로 전체적인 정보를 다양하게 수집하고 전체 필드를 볼 수 있는 능력을 키우자.
수직으로 오랜 시간 꾸준하게 갈고 닦자. 조급해하지 않기 !
2강 MLOps 개론
GOAL
- MLOps 가 무엇인지 학습한다.
- MLOps 가 필요한 이유를 이해한다.
- MLOps 의 각 Component 를 알아보고 왜 이런 것들이 생겼는지 이해한다.
- MLOps 관련 자료, 논문을 읽고 강의 내용 외에 어떤 내용이 있는지 파악해본다.
- MLOps Component 중 내가 매력적으로 생각하는 Top3 를 정해보고 왜 그렇게 생각했는지 작성해본다.
모델 개발 프로세스
문제정의 ㅡ EDA ㅡ Feature Engineering ㅡ Train ㅡ Predict
- 문제 정의 후 데이터 특성 확인 및 feature engineering ( 머신러닝 또는 테이블 데이터 ) 후 학습 및 예측
Research VS. Production
- Output 값이 이상할 때가 있다.
- 원인 파악 및 조치가 필요함
- 실제 서비스 환경에서는 모델의 성능이 계속 변한다.
- 새로운 모델의 성능이 잘 나오지 않으면 이전 모델을 사용해야 한다.
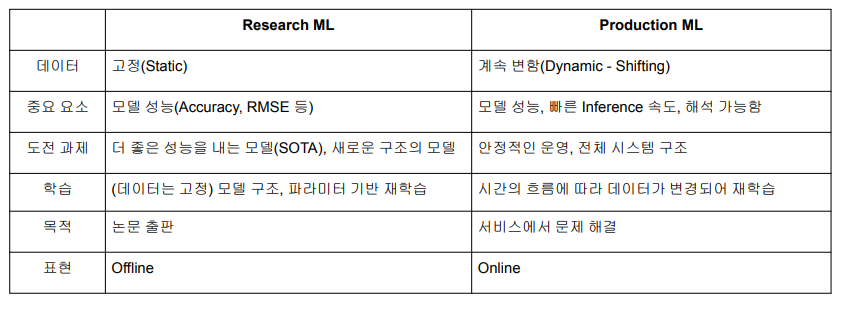
MLOps 란
MLOps = ML (Machine Learning) + Ops (Operations)
머신러닝 모델을 운영하면서 반복적으로 필요한 업무를 자동화시키는 과정
목표: 머신러닝 모델 개발과 모델 운영에서 발생하는 문제와 반복을 최소화하고 비즈니스 가치를 창출하는 것- 빠른 시간 내에 가장 적은 위험 부담으로 아이디어 단계부터 production 단계까지 ML 프로젝트를 진행할 수 있도록 기술적 마찰을 줄이는 것
★ MLOps 의 각 component 에서 해결하고 싶은 문제가 무엇이고 그 문제를 해결하기 위한 방법으로 어떤 방식을 활용할 수 있는지를 학습하자. ★
MLOps Component - Server Infra
고려할 것
- 예상 트래픽이 어느 정도되는가 ?
- 서버의 CPU, Memory 성능은 어느 정도가 적당한가 ?
- 스케일 업, 스케일 아웃이 가능한가 ?
- 자체 서버를 구축할 것인지 클라우드로 구축할것인지 ?
MLOps Component - Infra
- 클라우드 : AWS, GCP, Azure, NCP 등
- 온 프레미스 : 회사나 대학원의 전산실에 서버를 직접 설치
MLOps Component - Serving
Batch Serving
많은 양의 데이터를 일정 주기( 1일, 1주, 1달 등)로 한꺼번에 서빙( 예측 ) 한다.
- Jupyter Notebook 에서 실행하는 방식은 대부분 함수화를 통해 Batch Serving으로 쉽게 변경 가능한다.
- Dataframe 의 데이터를 한 번에 예측
Online Serving
실시간 예측
- 병목이 없어야 하고, 확장이 가능해야 한다.
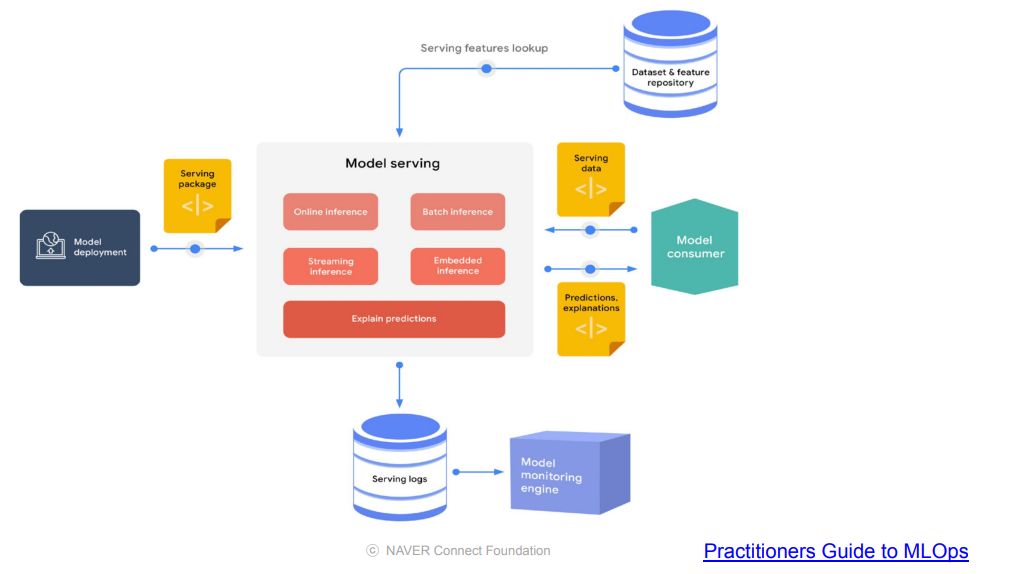
MLOps Component - Experiment, Model Management
모델 Artifact, 이미지 등을 저장
- 모델 생성일, 성능, 메타 정보 등을 기록
- 모델 Artifcat : 모델을 학습한 정보를 저장해두고 활용하는 것
예를 들어pickle 등
- 이미지 : 학습 과정에서 기록된 fature importance 등
- 모델 Artifcat : 모델을 학습한 정보를 저장해두고 활용하는 것
- 메타 정보를 통해 일정 기간 후에 모델의 성능이 떨어질 수 있음을 알 수 있다.
MLFlow 등의 도구를 이용하여 모델의 성능을 자동으로 기록, 비교할 수 있다.
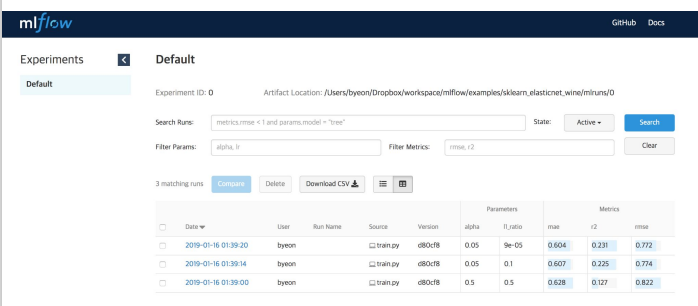
from pprint import pprint
import numpy as np
from sklearn.linear_model import LinearRegression
import mlflow
from utils import fetch_logged_data
def main():
# enable autologging
mlflow.sklearn.autolog()
# prepare training data
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
# train a model
model = LinearRegression()
with mlflow.start_run() as run:
model.fit(X, y)
print("Logged data and model in run {}".format(run.info.run_id))
# show logged data
for key, data in fetch_logged_data(run.info.run_id).items():
print("\n---------- logged {} ----------".format(key))
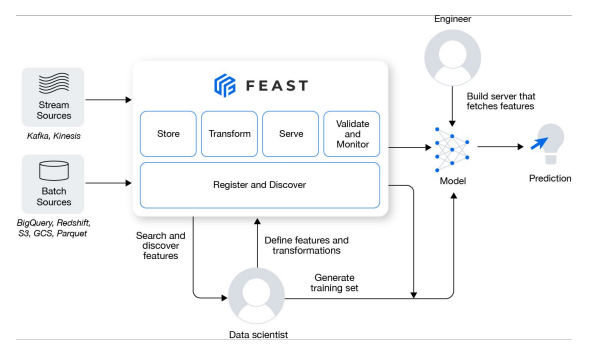
pprint(data)MLOps Component - Feature Store
Research 단계에서 사용한 model feature 들을 불러와 사용할 수 있다.
- Online : Kafka, Kinesis 등의 stream sources
- Offline : BigQuery, Redshift, S3, GCS, Parquest 등의 batch sources
from pprint import pprint
from feast import FeatureStore
store = FeatureStore(repo_path=".")
feature_vector = store.get_online_features(
features=[
'driver_hourly_stats:conv_rate',
'driver_hourly_stats:acc_rate',
'driver_hourly_stats:avg_daily_trips'
],
entity_rows=[{"driver_id": 1001}]
).to_dict()
pprint(feature_vector)
# Make prediction
# model.predict(feature_vector)MLOps Component - Data Validation
Feature 의 분포 를 확인할 수 있다.
- Tensorflow Data Validation
- tensorflow data-validation github
- google Data Validation for Machine Learning
- AWS Deequ : Unit Test for Data, Data Quality

Data Drift, Model Drift, Concept Drift
- Research 단계와 Production 단계에서 보이는 데이터 차이
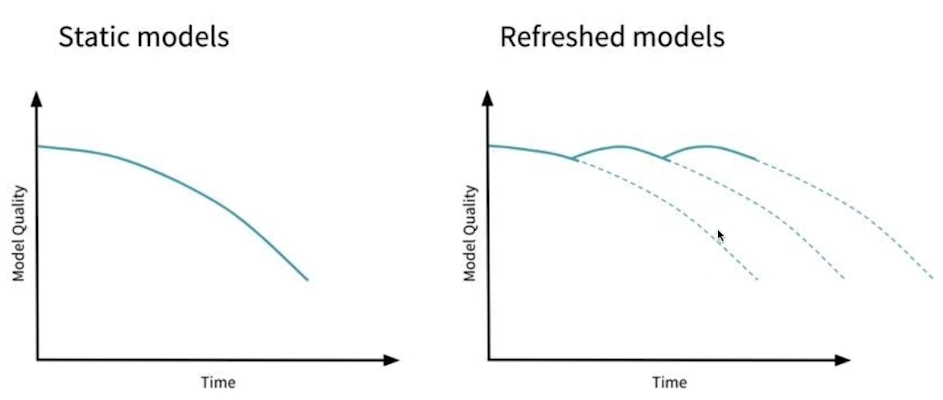
★ 데이터 분포의 차이를 확인하고 그에 맞는 대응을 할 수 있다.
MLOps Component - Continuous Training
시간이 지남에 따라 모델의 성능이 떨어진 경우
- ( 1 ) 새로운 데이터 기반
- ( 2 ) 일정 기간 기반
- ( 3 ) metric 기반
- ( 4 ) 수동으로 요청시 마다 training
MLOps Component - Monitoring
모델의 지표, 인프라의 성능 지표를 잘 기록해두어야 한다.
MLOps Component - AutoML
머신러닝 모델을 직접 운영하면서 신경써야 하는 부분
- 다양한 툴을 이용하여 자동화가 가능하다.
MLOps Component - 정리
★ 인프라 ( 서버, GPU )
★ Serving
Experiment, Model Management
Feature Store
Data Validation(Data Management)
Continuous Training
Monitoring
AutoML
MLOps 가 처음부터 필요한 것은 아니다. 처음에는 Minimal Value Product 로 시작해서 운영 리소스가 많이 들 때 하나씩 구축하는 방식을 활용하자.
레퍼런스
각 tool 들이 어떤 문제를 어떤 식으로 해결하고 있는지에 집중하여 학습
- Component 의 라이브러리를 사용해보고 비교해보기
- 클라우드의 MLOps 서비스 사용해보기
- Uber MLOps 논문, 기술블로그
- 사라진 듯..?
- https://techy8855.tistory.com/26
- 구글 클라우드의 Practitioners Guide to MLOps
- Superb AI의 실리콘밸리의 ML옵스
3강 Model Serving
GOAL
- 학습시킨 모델을 어떻게 프로덕트 단으로 서빙할 수 있는지 이해하기
- Rules of Machine Learning: Best Practices for ML Engineering 문서 읽고 정리
- Online Serving / Batch Serving 기업들의 Use Case 찾아서 정리하기
- (어떤 방식으로 되어 있는지 지금은 이해가 되지 않아도 문서를 천천히 읽고 정리하기)
Serving
- 머신러닝 모델을 개발하고 Real World 환경의 앱, 웹에서 사용할 수 있게 하는 것
용어 정리
두 용어가 혼재되어 사용되기도 한다.
- Serving
- 모델을 웹/앱 서비스에 배포하는 과정, 모델을 활용하는 방식, 모델을 서비스화하는 관점
- Inference
- 모델에 데이터가 제공되어 예측하는 경우, 사용하는 관점
예를 들어Online Serving / Online Inference
예를 들어Batch Serving ( + Inference )
Online Serving
- 요청이 올 때마다 실시간으로 예측
- 클라이언트(애플리케이션)에서 ML 모델 서버에 HTTP 요청(Request) 을 하고, 머신러닝 모델 서버에서 예측한 후, 예측 값(Response) 를 반환
웹 서버
- HTTP 통신을 통해 브라우저가 요청하는 HTML 문서나 오브젝트를 전송해주는 서비스 프로그램
- Request 를 받으면 요청한 내용을 Response 하는 프로그램
API ( Application Programming Intreface )
- 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
Serving Input - Single Data Point
단일 데이터를 받아 실시간으로 예측하는 예제
- 기계 고장 예측 모델
- 센서의 실시간 데이터가 제공됐을 때, 특정 기계 부품이 앞으로 N 분 안에 고장날지 말지를 예측
- 음식 배달 소요 시간 예측
- 해당 지역의 과거 평균 배달 시간, 실시간 교통 정보, 음식 데이터 등을 기반으로 음식 배달 소요 시간을 예측
Online Serving Basic
참고 개발 조직과 데이터 조직의 협업하는 방식에 따라 다르게 개발할 수 있다.
- 머신러닝 서버에서 전처리를 하는 경우
- 전처리 서버와 모델 서버로 나누는 경우
- 서비스 서버에 ML 서버가 포함되는 경우와 ML 서버를 별도로 운영하는 경우가 있음
Online Sering 구현 방식
- ( 1 ) 직접 API 웹 서버 개발
- Flask, FastAPI
- ( 2 ) 클라우드 서비스 활용
- AWS 의 SageMaker, GCP의 Vertex AI 등
장점: 쉬운 사용, 소수의 인력으로 운영시 유용단점: 익숙해야 잘 활용, 비용이 비쌈
- ( 3 ) Serving 라이브러리 활용
- Tensorflow Serving, Torch Serve, MLFlow, BentoML 등
장점: FastAPI 나 Flask 를 추상화하고 있음 ( 추상화된 패턴을 잘 제공함 )
다양한 Serving 방법을 선택하는 가이드
참고 주어진 환경( 일정, 인력, 예산, 요구 성능 등 ) 에 따라 달라진다.
- ( 1 ) 프로토타입 모델을 클라우드 서비스를 활용해 우선 배포
- ( 2 ) 직접 FastAPI 등을 활용해 서버 개발
- ( 3 ) Serving 라이브러리를 활용해 개발
Online Serving 에서 고려할 부분
( 1 ) 재현 가능한 코드를 작성
- 버전 Dependency 관리가 중요하다.
- Virtualenv, Poetry, Docker 등
( 2 ) latency : 하나의 예측을 요청하고 반환값을 받는 데까지 걸리는 시간
- Input 을 기반으로 DB 에 있는 데이터를 추출해서 모델을 예측해야 하는 경우
- Input 의 user id 로 DB 를 조회하여 예측한 후 값을 받는 경우
- latency 가 길어질 수 있다.
- 모델이 수행하는 연산
-예를들어RNN, LSTM
- 모델 경량화 또는 간단한 모델 사용 등의 방법
- 병렬 / 분산 / 큐
- 결과 값에 대한 보정이 필요한 경우
- 유효하지 않은 예측 값이 반환되는 경우
데이터 전처리 서버 분리 / Feature 미리 가공 - Feature Store / 모델 경량화 / 병렬 처리 ( Ray ) / 예측 결과 캐싱 등 상황에 맞는 해결 방법 사용
Batch Serving
Workflow Scheduler 로 특정 기간 단위로 자동 실행
- 주기적으로 학습 / 예측하는 경우
- 함수 단위를 주기적으로 실행 ( 관련 라이브러리는 따로 존재하지 않음 )
- Airflow, Cron Job
- 학습과 예측을 분리해서 서빙할 수도 있다.
예를 들어 1시간 뒤 수요 예측, 재고 및 입고 최적화를 위해 매일 매장별 제품 수요 예측
Batch Serving Basic - 장점
- Jupyter Notebook 에서 작성한 코드를 함수화한 후, 주기적으로 실행하는 구조
- Online Serving 보다 구현이 수월하고 간단
- 한 번에 많은 데이터를 처리하여 latency 문제 발생 확률이 적음
Batch Serving Basic - 단점
- 실시간 활용을 할 수 없음
- Cold Start 문제
Online Serving VS. Batch Serving
Input 관점
- 데이터를 하나씩 요청하는 경우 : Online
- 여러 데이터가 한꺼번에 처리되는 경우 : Batch
Output 관점
- Inference Output 을 어떻게 활용하는지에 따라 다르다.
- API 형태로 바로 결과를 반환해야하는 경우 : Online
- Server 와 통신이 필요한 경우 : Oneline
- 주기적으로 예측해도 괜찮은 경우 : Batch
실시간 모델 결과가 어떻게 활용되는지 생각해보자
- Batch Serving 의 결과를 DB 에 저장하고 쿼리하여 조회하는 방식으로 사용할 수도 있다.
- 우선 Batch Serving 으로 모델을 운영하면서 점차 API 형태로 변환해도 된다.
- Rules of Machine Learning: Best Practices for ML Engineering 문서 읽고 정리
- Online Serving / Batch Serving 기업들의 Use Case 찾아서 정리하기
- (어떤 방식으로 되어 있는지 지금은 이해가 되지 않아도 문서를 천천히 읽고 정리하기)
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
