
서두
일단 CPU, RAM, SSD로 크게 나뉜다고 생각된다.
1. CPU: 연산처리장치
CPU의 성능은 Hz 1초당 깜빡이는 횟수? 클럭속도
초당 실행하는 사이클수 GHz 단위로 측정 근데 단지 클록속도가 결정하는 것은 아님
단일 클럭 사이클에서 다수의 명령이 완료 가능! 하나의 명령이 다수의 클럭에 완료 가능하기 때문에 동일한 CPU 브랜드와 세대에서 비교하는 것이 좋다
- RAM (Random Access Memory: 주기억장치)
프로그램이 실행되는 동안 필요한 정보를 저장하는 컴퓨터 메모리
시발 램도 종류가 줜나 많기 때문에 그걸 최대한 줄이자
엇! 순차적이 아니라 임의 순서로 엑세스 할 수 있는 데이터 저장소. 어느 위치로 가도 똑같은 속도로 접근하여 읽고 쓸 수 있다. - SSD (솔리드 스테이트 드라이브)
솔리드 스테이트 드라이브(SSD)는 하드 드라이브와 비슷하지만 더 빠르고 안정적인 새로운 유형의 스토리지 드라이브입니다. SSD는 거의 즉각적인 부팅과 로딩 시간을 제공하는 플래시 메모리를 사용하므로 회전하는 플래터(하드 드라이브와 같이)에서 기계적으로 데이터를 찾을 필요가 없어 거의 모든 데이터에 즉시 액세스할 수 있습니다.
헷갈리는거: 캐시 메모리는 어디에 존재 하는가
자주 사용하는 데이터를 캐시 메모리에 저장한 뒤, ram이 아니라 캐시에서 가져온다.
듀얼 코어 프로세서의 캐시 메모리 : 각 코어마다 독립된 L1 캐시 메모리를 가지고, 두 코어가 공유하는 L2 캐시 메모리가 내장됨
만약 L1 캐시가 128kb면, 64/64로 나누어 64kb에 명령어를 처리하기 직전의 명령어를 임시 저장하고, 나머지 64kb에는 실행 후 명령어를 임시저장한다. (명령어 세트로 구성, I-Cache - D-Cache)
L1 : CPU 내부에 존재
L2 : CPU와 RAM 사이에 존재
L3 : 보통 메인보드에 존재한다고 함
이때 Cache miss의 경우 3가지
- Cold miss:해당 메모리 주소를 처음 불러서 나는 미스
- Conflict miss: 캐시 메모리 주소에 할당되어 있어 나는 미스
- Capacity miss: 캐시 메모리 공간 부족
그럼 캐시 메모리를 무작정 늘리면 좋냐? 그게 아니라 접근 속도가 느려지고 파워를 많이 먹음
프로그램의 실행 과정
- 실행파일을 실행 : 여기서 실행파일은 하드디스크에 존재
- 실행 이미지가 RAM으로 복사
메모리 시스템이 뭘까?
메모리
- CPU 연산 되기 전에 메모리에서 순서대로 대기
종류가 다양 하고 성능과 용량이 제각각!
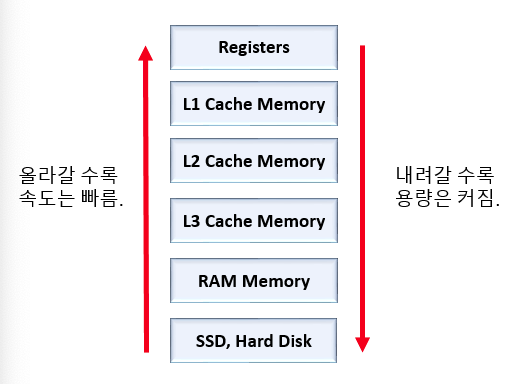
이렇게 그림으로 봤을 때 CPU랑 가장 가까운 것은 레지스터
현재 CPU의 연산속도가 너무 빨라서 메모리의 성능이 따라 가지를 못함
- 성능 메모리가 딸림
- 대역폭 딜레이 생김
주기억장치 RAM을 거쳐 CPU 내부 메모리인 Cache Memory를 통해 CPU로 데이터 이동
CPU에 내부 메모리가 있다고 ? == Cache Memory
보조기억장치 HDD SSD는 꺼도 데이터 live!
주기억장치 RAM: 데이터가 소멸!
메모리
- 동적램 DRAM: 용량은 크고, 느리고 저렴 --> 일반적으로 부르는 메모리
- 정적램 SRAM: 용량은 적고, 속도 빠르고 비쌈 --> only for cache memory
Cache Memory
L1, L2, L3로 계층이 분리
L1: 빠름, 용량 작음 (프로세서에 근접) <---
읽는 순서
CPU 연산에 필요한 데이터 --> L1에 요청 L1없음? L2요청 --> 연속
이 과정중에 일어나는 일이 캐쉬미스!!
즉, L1에 없으면 캐쉬미스가 일어난다!!!
이것이 곧 프로세스 성능을 좌우한다
L1에 없으면 L2꺼를 L1에 복사, L2에 없으면 L3에서 L2, L2에서 L1으로 가져와 쓴다
CPU는 0과 1 밖에 모르는 바보!
5를 0101이라는 이진수로 인식 0011 + 0010로 인식? WHY??????
컴파일러, 프로시저 호출, 버퍼 오버플로우란?
-
컴파일: C 또는 Java를 CPU가 이해할 수 있는 어셈블리어 같은 기계언어로 변환
즉, 다른 언어의 동등한 프로그램으로 변환하는 작업 -
어셈블러: 특히 어셈블리어를 기계어로 번역하는 프로그램
-
Buffer Overflow: 프로그램이 실행 될 때 입력받는 값이 버퍼를 가득 채우지도 못하고 흘러 넘쳐서 버퍼 이후의 공간을 침범 하는 현상! 데이터를 입력 받을 때 준비된 것보다 더 많은 양의 데이터를 입력받을 때 발생. 해커가 프로그램의 메모리 값을 변조할때 쓰임.
ex) 8칸 메모리에 4칸 버퍼인데 5칸 넣으면 버퍼 이후의 값이 바뀌는데, 사용자에게 통지하지 않음
데이터를 요청할때 서버는 메모리에 저장 된 다른 정보까지 끌고와 패킷을 채운 뒤 사용자에게 재전송해준다.
- 링커 과정: 링커(linker) 또는 링크 에디터(link editor)는 컴퓨터 과학에서 컴파일러가 만들어낸 하나 이상의 목적 파일을 가져와 이를 단일 실행 프로그램으로 병합하는 프로그램이다.
일단 정보의 분류를 구분해야 하는 데,
Bit -> Nibble -> Byte -> Word -> DoubleWord -> LongWord
- int: 4byte = 32bit 정수 데이터 저장
- char: 1byte = 8bit
- short: 2byte = 16bit 정수 데이터 저장
- long: 4byte 정수 데이터를 저장하는데 굳이 쓰진 않음
- longlong: 8byte C언어 제일 긴 자료형입니다.
- float: 4byte, 소수점 숫자를 저장할 때 사용
- double: 8byte, float보다 더 큰 실수를 저장할 때
오오 이게 사실 데이터의 크기랑 크게 연관성이 있다~
이제야 제대로 된 정리를 시작하자....
- 컴퓨터시스템: 하드웨어, 시스템 소프트웨어
- 반드시 배워야할 것
- 프로세서와 메모리시스템의 설계를 활용하여 C코드 최적화
- 컴파일러가 프로시저를 어캐 호출하는지
- 이를 이용해 버퍼 오버플로우 위험성으로부터 시스템을 어캐 보호 할것 인지 근데 이거 이용해서 ㅋㅋ 해킹도 가능할 수 있지 않을까? 정보 변환을 이용해서!
- 동적 메모리 할당 패키지, 유닉스 쉘, 웹 서버 작성
1.1 정보는 비트와 컨텍스트로 이루어짐
- 아스키 코드로 텍스트 파일을 저장하는데 spacing 이나 줄바꿈도 다 신경써서 바꿔진다
- 8비트로 아스키 코드를 표현가능한데 왜? 128헉...
1바이트를 구성하는 8비트 중에서 7비트만 쓰도록 제정된 이유는, 나머지 1비트를 통신 에러 검출을 위해 사용하기 때문이었다. Parity Bit라고 해서, 7개의 비트 중 1의 개수가 홀수면 1, 짝수면 0으로 하는 식의 패리티 비트를 붙여서, 전송 도중 신호가 변질된 것을 수신측에서 검출해낼 확률을 높인 것. 원시적인 CRC 체크섬이라고 할 수 있지만 당연히 이런 체크에 검출되지 않는 신호 에러도 얼마든지 생길 수 있고 현재는 더 이상 쓰이지 않는다. 현재는 8비트 문자 인코딩에서는 그냥 맨 앞 비트에 0을 붙이고 이어서 7비트가 이어지는 식의 인코딩이 일반적이다.
대박사건
짝수 패리티를 사용한다하면, 현재 전송되는 데이터의 비트 1의 개수가 홀수면, 1을 맨 뒤에 붙여서 짝수로, 짝수라면 0을 맨 뒤에 붙여서 짝수로 1의 개수를 맞춰주는 것이다.
지금 컴파일 해볼려고 하는 데
에러 해결
