
언어 모델(Language Model)
언어모델이란 단어 시퀀스(문장)에 확률을 할당하는 모델을 말합니다. 어떤 문장들이 있을 때, 기계가 이 문장은 적절해! 이 문장은 말이 안돼! 라고 사람처럼 정확히 판단할 수 있다면, 기계이 자연어 처리의 성능이 뛰어나다고 말할 수 있습니다.
이번 챕터에서는 통계에 기반한 전통적인 언어모델(Statistical Languagel Model,SLM)에 대해서 학습합니다. 통계에 기반한 언어 모델은 우리가 실제 사용하는 자연어를 근사하기에는 많은 한계가 있었고, 요즘 들어 인공 신경망이 그러한 한계를 많이 해결해주면서 통계 기반 언어 모델은 많이 사용 용도가 줄었습니다. 하지만 그럼에도 통계 기반 방법론에 대한 이해는 언어 모델에 전체적인 시야를 갖는 일에 도움이 됩니다.
언어모델이란?
언어 모델(Language Model,LM)은 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당(assign)하는 모델입니다.
언어 모델을 만드는 방법은 크게 통계를 이용한 방법과 인공 신경망을 이용한 방법으로 구분할 수 있습니다. 최근에는 통계를 이용한 방법보다는 인공 신경망을 이용한 방법이 더 좋은 성능을 보여주고 있습니다. 최근 핫한 자연어 처리의 기술인 GPT나 BERT또한 인공 신경망 언어 모델의 개념을 사용하여 만들어졌습니다. 이번 챕터에서는 언어 모델의 개념과 언어 모델의 전통적 접근 방식인 통계적 언어 모델에 대해서 배웁니다.
1. 언어모델
언어 모델은 단어 시퀀스에 확률을 할당 하는 일을 하는 모델입니다. 이를 조금 풀어서 쓰면, 언어 모델은 가장 자연스러운 단어 시퀀스를 찾아내는 모델입니다. 단어 시퀀스에 확률을 할당하게 하기 위해서 가장 보편적으로 사용되는 방법은 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것 입니다.
다른 유형의 언어 모델로는 주어진 양쪽의 단어들로 부터 가운데 비어있는 단어를 예측하는 언어 모델이 있습니다. 이는 문장의 가운데에 단어를 비워 놓고 양쪽의 문맥을 통해서 빈 칸의 단어인지 맞추는 고등학교 수험 시간의 빈칸 추론 문제와 비슷합니다. 이 유형의 언어 모델은 맨 마지막 BERT 챕터에서 다루게 될 예정이고, 그때까지 이전의 단어들로 부터 다음 단어를 예측하는 방식에만 집중합니다.
언어 모델에 -ing를 붙인 언어 모델링(Language Modeling)은 주어진 단어들로 부터 아직 모르는 단어를 예측하는 작업을 말합니다. 즉, 언어 모델이 이전 단어들로 부터 다음 단어를 예측하는 일은 언어 모델링입니다.
2.단어 시퀀스의 확률 할당
자연어 처리에서 단어 시퀀스에 확률을 할당하는 일이 왜 필요할까요? 예를 들어 보겠습니다. 여기서 대문자 p는 확률을 의미합니다
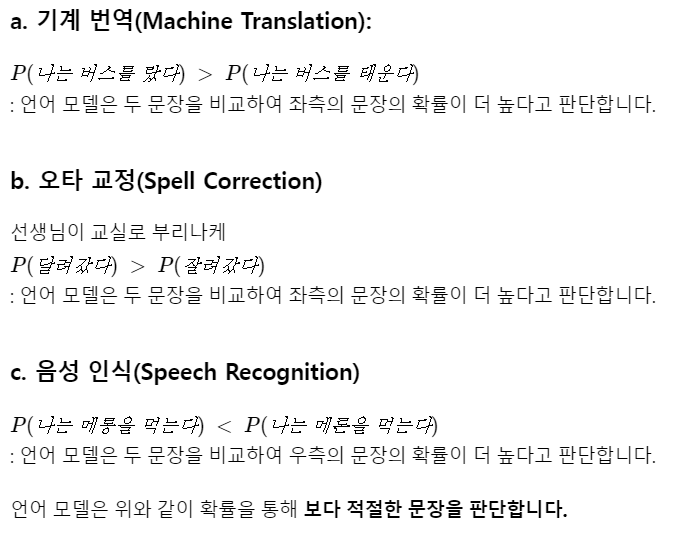
3.주어진 이전 단어들로부터 다음 단어 예측하기
언어 모델은 단어 시퀀스에 확률을 할당하는 모델입니다. 그리고 단어 시퀀스에 확률을 할당하기 위해서 가장 보편적으로 사용하는 방법은
이전 단어들이 주어졌을때, 다음 단어를 예측하도록 하는 것입니다. 이를 조건부 확률로 표현해보겠습니다.

4. 언어 모델의 간단한 직관
비행기를 타려고 공항에 갔는데 지각을 하는 바람에 비행기를[?] 라는 문장이 있습니다. '비행기를' 다음에 어떤 단어가 오게 될지 사람은 쉽게 '놓쳤다'라고 예상할 수 있습니다. 우리가 지식에 기반하여 나올 수 있는 여러 단어들을 후보에 놓고 놓쳤다는 단어가 나올 확률이 가장 높다고 판단하였기 때문입니다.
그렇다면 기계에게 위 문장을 주고, '비행기를' 다음에 나올 단어를 예측해보라고 한다면 과연 어떻게 최대한 정확히 예측할 수 있을까요? 기계도 비슷합니다. 앞에 어떤 단어들이 나왔는지 고려하여 후보가 될 수 있는 여러 단어들에 대해서 확률을 예측해보고 가장 높은 확률을 가진 단어를 선택합니다. 앞에 어떤 단어듫이 나왔는지 고려하여 후보가 될 수 있는 여러 단어들에 대해서 등장확률을 추정하고 가장 높은 확률을 가진 단어를 선택합니다.
5. 검색 엔진에서의 언어 모델의 예
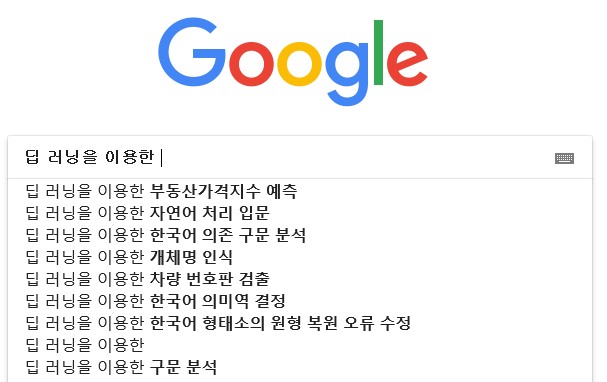
검색 엔진이 입력된 단어들의 나열에 대해서 다음 단어를 예측하는 언어 모델을 사용하고 있습니다.
추천하는 언어 모델 참고 자료 :
https://www.cs.bgu.ac.il/~elhadad/nlp18/nlp02.html
http://www.marekrei.com/pub/Machine_Learning_for_Language_Modelling_-_lecture3.pdf
