
펄플렉서티
두 개의 모델 A,B가 있을 때 이 모델의 성능은 어떻게 비교할 수 있을까요? 두 개의 모델을 오타 교정, 기계 번역 등의 평가에 투입 해 볼수 있겠습니다. 그리고 두 모델이 해당 업무의 성능을 누가 더 잘했는지를 비교하면 되겠습니다. 그런데 두 모델의 성능을 비교하고자, 일일히 모델들에 대해서 실제 작업을 시켜보고 정확도를 비교하는 작업은 공수가 너무 많이 드는 작업입니다. 만약 비교해야하는 모델이 두개가 아니라 그 이상의 수라면 시간은 비교해야하는 모델의 수만큼 배로 늘어날 수도 있습니다.
이러한 평가보다는 어쩌면 조금은 부정확할 수는 있어도 테스트 데이터에 대해서 빠르게 식으로 게산되는 더 간단한 평가방법이 있습니다.
바로 모델 내에서 자신의 성능을 수치화하여 결과를 내놓는 펄플렉서티 입니다.
1. 언어 모델의 평가방법
펄플렉서티는 언어 모델을 평가하기 위한 지표입니다. 보통 줄여서 PPL이 라고 표현합니다. 왜 perplexity라는 용어를 사용했을까요? 영어에서 'perplexed'는 헷갈리는과 유사한 의미를 가집니다. 그러니까 여기서 PPL은 헷갈리는 정도로 이해합시다. PPL를 처음 배울때 다소 낯설게 느껴질수 있다는 점이 있따면, PPL은 수치가 높으면 좋은 성능을 의미하는 것이 아니라, '낮을수록' 언어 모델의 성능이 좋다는 것을 의미하다는 점입니다.

2. 분기계수(Branching factor)
PPL은 선택할 수 있는 가능한 경우의 수를 의미하는 분기계수 입니다. PPL은 이 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미합니다. 가령, 언어 모델에 어떤 테스트 데이터를 주고 측정했더니 PPL이 10이 나왔다고 해봅시다. 그렇다면 해당 언어 모델은 테스트데이터에 대해서 다음 단어를 예측하는 모든 시점마다 평균 10개의 단어를 가지고 어떤것이 정답인지 고민하고 있다고 볼 수 있습니다. 같은 테스트 데이터에 대해서 두 언어 모델의 PPL을 각각 계산 후에 PPL의 값을 비교하면, 두 언어 모델 중 PPL이 더 낮은 언어 모델의 성능이 더 좋다고 볼 수있습니다.
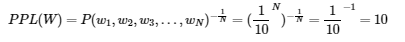
단, 평가 방법에 있어서 주의할 점은 PPL의 값이 낮다는 것은 테스트 데이터 상에서 높은 정확도를 보인다는 것이지, 사람이 직접 느끼기에 좋은 언어 모델이라는 것을 반드시 의미하진 않는다는 점입니다.
또한 언어 모델의 PPL은 테스트 데이터에 의존하므로 두 개 이상의 언어 모델을 비교할 때는 정량적으로 양이 많고, 또한 도메인에 알맞는 동일한 테스트 데이터를 사용해야 신뢰도가 높다는 것입니다.
3. 기존 언어 모델 Vs. 인공 신경망을 이용한 언어 모델.
페이스북 AI 연구팀은 앞서 배운 n-gram 언어 모델과 이후 배우게 될 딥 러닝을 이용한 언어 모델에 대해서 PPL로 성능 테스트를 한 표를 공개한 바 있습니다.

표에서 맨 위의 줄의 언어 모델이 n-gram을 이용한 언어 모델이며 PPL이 67.6으로 측정되었습니다. 5-gram을 사용하였으며, 5-gram 앞에 Interpolated Kneser-Ney라는 이름이 붙었는데 이 책에서는 별도 설명을 생략하겠다고 했던 일반화(generalization) 방법이 사용된 모델입니다. 반면, 그 아래의 모델들은 인공 신경망을 이용한 언어 모델들로 페이스북 AI 연구팀이 자신들의 언어 모델을 다른 언어 모델과 비교하고자 하는 목적으로 기록하였습니다. 아직 RNN과 LSTM 등이 무엇인지 배우지는 않았지만, 인공 신경망을 이용한 언어 모델들은 대부분 n-gram을 이용한 언어 모델보다 더 좋은 성능 평가를 받았음을 확인할 수 있습니다.
추천하는 참고 링크 :
https://towardsdatascience.com/perplexity-intuition-and-derivation-105dd481c8f3
https://www.slideshare.net/shkulathilake/nlpkashkevaluating-language-model
http://www.statmt.org/book/slides/07-language-models.pdf
https://github.com/kobikun/wiki/wiki/Language-Models
https://courses.engr.illinois.edu/cs447/fa2018/Slides/Lecture03.pdf
