🌚 Connection Pool
- 현재 Connection Pool, HikariCP 에 대해 아무것도 모르는 상태이다
- 첫 인상: Connection pool - 연결 풀? HiKariCP 이름 부터가 어렵게 느껴진다.
검색해보자.
🎁 Connection Pool
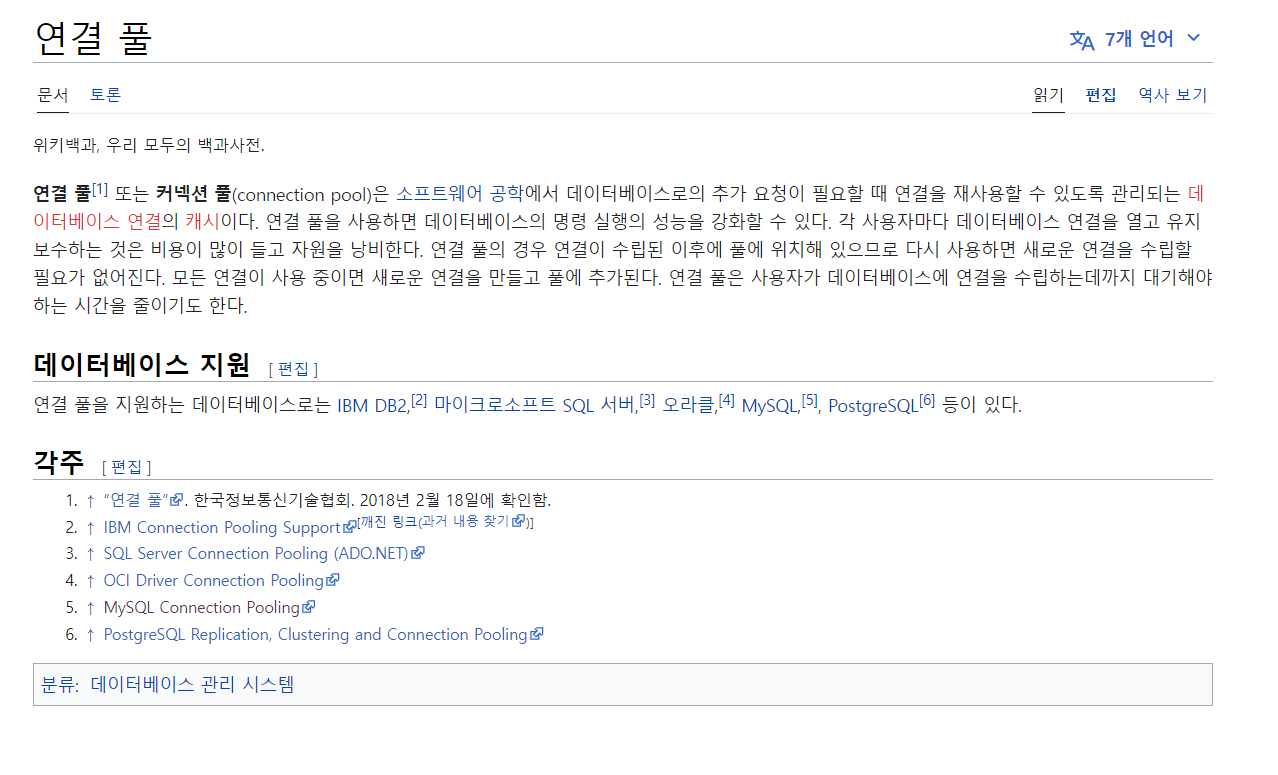
Connection Pool 정의
위키백과에 검색을 해보았다.
- 연결 툴 또는 커넥션 풀은 데이터베이스로 추가 요청이 필요할 때 연결을 재사용할 수 있도록 관리하는 데이터베이스 연결의 캐시이다.
여기서 모르는 단어인 캐시가 나왔다. 검색해보자.
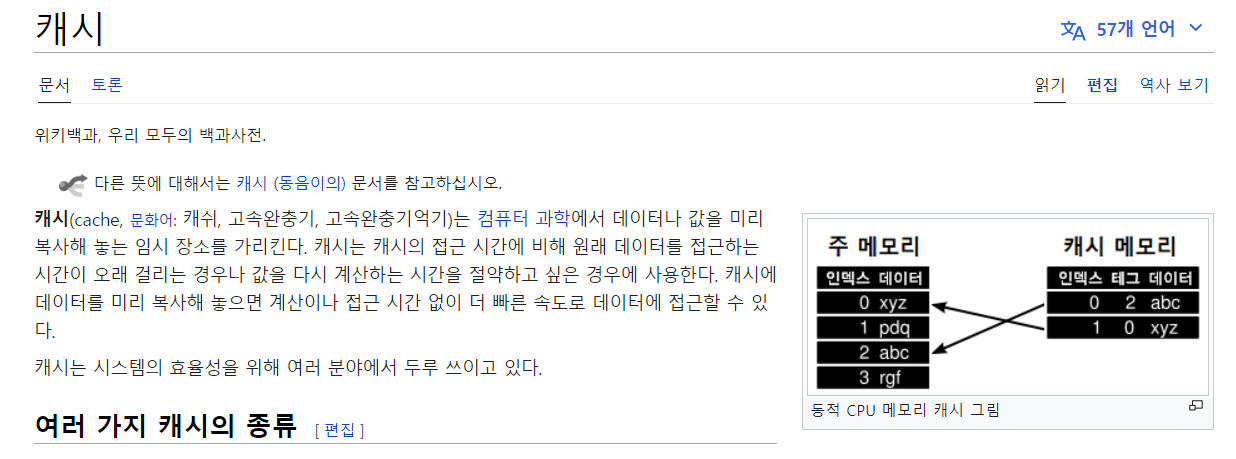
- 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다고 한다.
- 캐시를 이용하면 값을 다시 계산하는 시간을 절약할 수 있다.
- 메모리에 관한 내용은 와닿지 않는다.
다시 커넥션풀로 돌아와 보자.
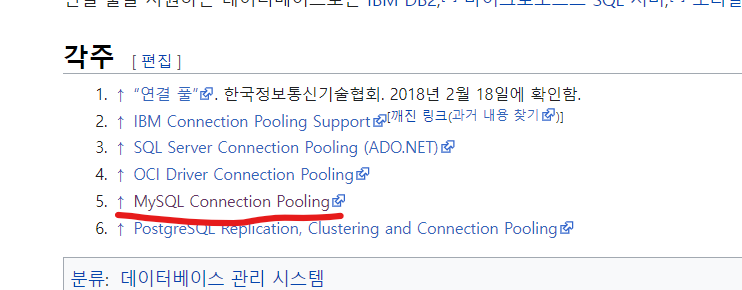
커넥션 풀을 지원하는 DBMS로는 위와 같이 있다고 한다.
한달 정도 MySQL을 사용했으니 나름 익숙해 졌다고 생각한다. MySQL의 Connection Pooling을 들어가보자.
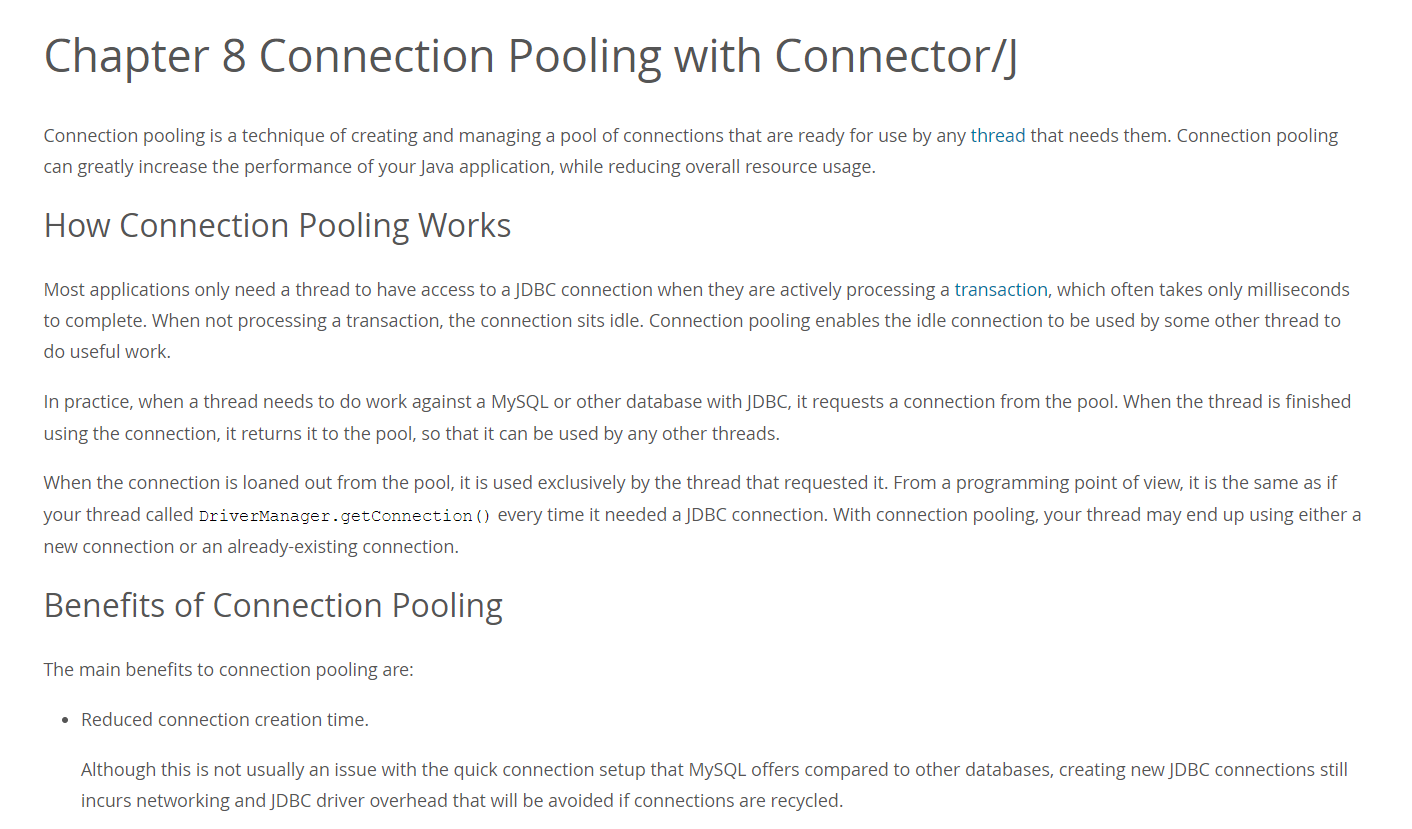
😵😵😵😵 울렁 거리지만, 참고 읽어보자.
내 해석 : 커넥션 풀링은 기술이다. 풀을 생성하고 관리하는 // 사용하기로 준비되어 있는 // 어떤 쓰레드로 인해 // 그들을 필요로하는.
커넥션풀링은 매-우 향상시킨다. 자바 어플리케이션 퍼포먼스를, 전체 리소스 사용량을 줄이면서
번역기를 돌려보자.
연결 풀링은 연결 풀을 필요로 하는 스레드에서 사용할 수 있는 연결 풀을 만들고 관리하는 기술입니다. 연결 풀링은 전체 리소스 사용을 줄이면서 Java 응용프로그램의 성능을 크게 향상시킬 수 있습니다.
크게 다르지 않은 것 같다.
Connection Pool은 어떻게 작동하는가?
위의 내용을 해석했지만 내용이 많기도하고, 잘 와닿지 않아서 번역기를 돌렸다.
- 트랜잭션을 처리하지 않으면, 커넥션이 죽는다.
- 커넥션 풀링을 이용하면 작동하지 않는 커넥션을 사용할 수 있게 해준다.
- 스레드는 JDBC를 사용해 MySQL 또는 데이터베이스에 대해 작업을 수행할 때 풀에서 연결 요청을 한다.
- 스레드의 연결이 완료되면 다른 스레드에서 사용할 수 있도록 다른 스레드풀로 반환한다.
Benefits of Connection Pooling
커넥션풀의 장점은 무엇일까?
- 커넥션 생성 시간의 단축
- 프로그래밍 모델의 간단화
- 리소스 사용을 제어
연결 풀링을 사용하지 않고 스레드에 필요할 때마다 새 연결을 만들면 응용프로그램의 리소스 사용량이 낭비될 수 있으며, 부하가 높을 때 응용프로그램이 예기치 않은 동작을 할 수 있다.
Using Connection Pooling with Connector/J
커넥터/J와 연결 풀링 사용
아래와 같은 소스코드를 사용한다고 한다.
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import javax.naming.InitialContext;
import javax.sql.DataSource;
public class MyServletJspOrEjb {
public void doSomething() throws Exception {
/*
* Create a JNDI Initial context to be able to
* lookup the DataSource
*
* In production-level code, this should be cached as
* an instance or static variable, as it can
* be quite expensive to create a JNDI context.
*
* Note: This code only works when you are using servlets
* or EJBs in a J2EE application server. If you are
* using connection pooling in standalone Java code, you
* will have to create/configure datasources using whatever
* mechanisms your particular connection pooling library
* provides.
*/
InitialContext ctx = new InitialContext();
/*
* Lookup the DataSource, which will be backed by a pool
* that the application server provides. DataSource instances
* are also a good candidate for caching as an instance
* variable, as JNDI lookups can be expensive as well.
*/
DataSource ds =
(DataSource)ctx.lookup("java:comp/env/jdbc/MySQLDB");
/*
* The following code is what would actually be in your
* Servlet, JSP or EJB 'service' method...where you need
* to work with a JDBC connection.
*/
Connection conn = null;
Statement stmt = null;
try {
conn = ds.getConnection();
/*
* Now, use normal JDBC programming to work with
* MySQL, making sure to close each resource when you're
* finished with it, which permits the connection pool
* resources to be recovered as quickly as possible
*/
stmt = conn.createStatement();
stmt.execute("SOME SQL QUERY");
stmt.close();
stmt = null;
conn.close();
conn = null;
} finally {
/*
* close any jdbc instances here that weren't
* explicitly closed during normal code path, so
* that we don't 'leak' resources...
*/
if (stmt != null) {
try {
stmt.close();
} catch (sqlexception sqlex) {
// ignore, as we can't do anything about it here
}
stmt = null;
}
if (conn != null) {
try {
conn.close();
} catch (sqlexception sqlex) {
// ignore, as we can't do anything about it here
}
conn = null;
}
}
}
}정리를 해보면, 데이터베이스 커넥션풀이란 애플리케이션에서 필요로 하는 시점에 커넥션을 만드는 것이 아니라 미리 일정한 수의 커넥션을 만들어 놓고 필요한 시점에 애플리케이션에 제공하는 서비스 및 관리 체계를 말한다.
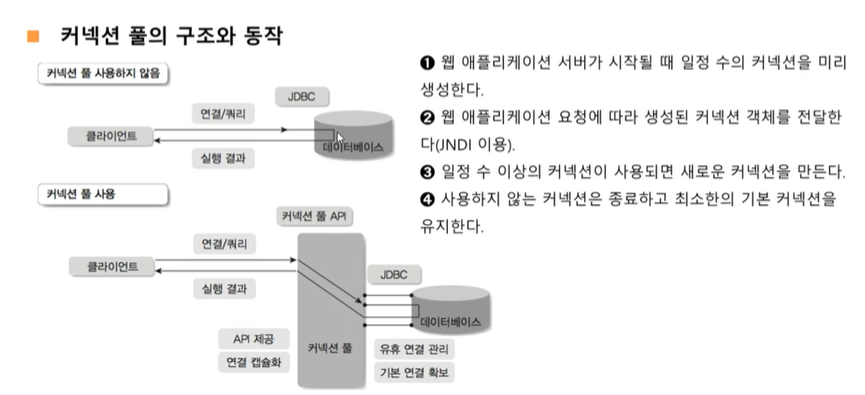
- 웹 애플리케이션 서버가 시작될 때 일정 수의 커넥션을 미리 생성한다.
- 웹 애플리케이션 요청에 따라 생성된 커넥션 객체를 전달한다(JNDI 이용)
- 일정 수 이상의 커넥션이 사용되면 새로운 커넥션을 만든다.
- 사용하지 않는 커넥션은 종료하고 최소한의 기본 커넥션을 유지한다.
더 알아볼 것: 어떻게 커넥션풀이 사용되는지..
참고 및 본글

그래야만 한다