.jpg)
Photo by Quinten de Graaf on Unsplash
Pipe function ?
미니 프로젝트를 진행하면서 파이프 함수를 사용할 기회가 있어서 이에 대해서 제가 알아봤던 내용과 실제 적용기를 공유하고자 하는 마음에 이 글을 작성합니다.
Software와 Pipe의 의미
- Javascript에 국한되지 않는, Software의 관점에서 Pipe의 이해
In software engineering, a pipeline consists of a chain of processing elements (processes, threads, coroutines, functions, etc.), arranged so that the output of each element is the input of the next; the name is by analogy to a physical pipeline.
소프트웨어 엔지니어링에서 파이프 라인은 일련의 처리 요소 (processes, threads, coroutines, functions, etc.)로 구성되며 각 요소의 출력이 다음 요소의 입력이되도록 배열되며 , 이름은 물리적 파이프 라인과 유사합니다.
https://en.wikipedia.org/wiki/Pipeline_(software)
이 글을 읽고 이해한 바로는 어떤 작업에 대한 일련의 처리 과정들이 있고 각각의 처리 과정의 결과는 다음 처리의 입력으로 활용된다? 정도로 이해할 수 있을 거 같습니다.
Pipe function 그리고 pure function
Pipe function에서 일련의 과정은 작은 단위의 function들로 표현할 수 있습니다.
그렇다면 그 일련의 과정은 Pure function(순수 함수)으로 구성되어 있어야 하는데, 잠시 순수 함수를 이해하고 넘어가 보도록 하겠습니다.
순수 함수란 ?
- 동일한 인자가 전달되면 그 함수의 실행 결과는 항상 동일한 결과를 return 해야 합니다.
- 순수 함수는 그 어떠한 상태나 데이터에 의존하지 않습니다.
- side-effect를 갖지 않습니다.
순수 함수는 위와 같은 특성을 지닌 함수라는 걸 알아볼 수 있습니다.
위와 같은 특성을 따라서 함수를 구성하게 된다면 함수의 크기는 자연스럽게 줄어들 것입니다.
만약에 하나의 함수에 너무 많은 일을 시킨다면 자칫 잘못해서 다른 상태에 의존해 버리는 순간이 생길 수 있기 때문입니다.
순수 함수에 대해서 간단한 예시를 들어보도록 하겠습니다.
- For example
// 1.case
let behavior = "Play game";
const doingBehavior = (personName) => {
return personName + behavior;
};
doingBehavior("hoi");
doingBehavior("mino");
// 2.case
const doingBehavior_2 = (personName) => {
return personName + "Play game"
}-
첫 번째 case의 경우에는 doingBehavior라는 함수가 전역에 정의되어 있는 behavior 변수를 의존하고 있습니다. 그 결과 doingBehavior에 입력된 personName의 행동은 behavior라는 확신을 가질 수 없습니다. behavior의 상태가 변하면 자연스럽게 doingBehavior 함수의 결과도 변동이 있기 때문입니다.
-
두 번째 case의 함수 doingBehavior_2는 사용자의 행동을 함수 내부에서 자체적으로 정의하고 있으며 그 어떤 전역의 상태도 참조하고 있지 않습니다. doingBehavior_2와 같은 함수를 사용할 때 우리는 어떤 personName을 전달해도 항상 Play game이라는 행동을 하고 있을 것이라는 확신을 가질 수 있습니다.
Pipe function에서 순수 함수가 사용되는 이유는 어려 함수를 합성하여 하나의 결괏값을 내놓게 되니 Pipe에 사용되는 함수들은 우리가 결과에 대해서 확신을 가지고 예측할 수 있는 함수여야 합니다.
또한 Pipe function과 같이 함수를 합성하고, 순수 함수를 만드는 일은 각각 다른 범주에 있는 개념들이 아니라 Functional Programming이라는 큰 범주 안에 속해있는 개념들입니다.
함수형 프로그래밍에 대한 좋은 글
https://medium.com/javascript-scene/master-the-javascript-interview-what-is-functional-programming-7f218c68b3a0
Pipe function의 간단한 예시
위 글과 함께 순수 함수에 대해서 짧게나마 이해를 했다면 실제로 Pipe function를 어떤식으로 사용하는지에 대한 간단한 예시를 들어보겠습니다.
- Pipe function
const pipe = (...functions) => (parameter) => functions.reduce((parameter, nextFn) => nextFn(arg), args),위의 pipe function은 spread operator를 사용하여 여러 함수들(...functions)을 Array의 형태로 받을 수 있으며 처음 시작이 되는 함수의 parameter을 받을 수 있고,
이후 Array method의 reduce를 사용하여 순차적으로 함수의 실행 결과가 다음 함수의 인자로 들어갈 수 있습니다.
- For example
const selectPizza = (pizzaType) => {
return pizzaType + " pizza";
};
const cookingPizza = (pizza) => {
return "Cooked" + pizza;
};
const serveGuest = (cookedPizza) => {
return "Serve to Guest" + cookedPizza;
};
pipe(selectPizza , cookingPizza , serveGuest)(Pepperoni)
// Serve to Guest Cooked Pepperoni pizza위의 예시는 손님이 Pizza를 선택하면 요리를 한 후 실제로 서빙되는 과정을 Pipe 함수에 적용하는 예제를 구현해 봤으며 Pipe의 인자로 전달된 함수들은 어떠한 상태도 참조하고 있지 않는 순수 함수 입니다.
어떤식으로 적용했나 ?
현재 미니 프로젝트로 github Clone을 진행하고 있었고 아래 구현한 화면에서 의도적으로 일부 기능에 Pipe function을 적용해 봤습니다.

- 주황색 영역
사용자가 버튼을 누르면 Random한 색상을 정해준다.
- Random한 RGB Color를 생성한다.
- RGB Color를 인자로 받으면 해당 색상을 기준으로 font의 색상을 검은색과 하얀색 둘 중 결정한다.
- 최종적으로 나온 RGB Color와 Font Color의 상태를 update 해준다.
const createRandomRGBColor = () => {
var r = Math.floor(Math.random() * 256);
var g = Math.floor(Math.random() * 256);
var b = Math.floor(Math.random() * 256);
return { r, g, b };
},
const isDarkColor = (RGBColors) => {
const { r, g, b } = RGBColors;
const yiq = (r * 299 + g * 587 + b * 114) / 1000;
const textColor = yiq < 150 ? "#fff" : "#000";
return { r, g, b, textColor };
};
const updateLabelColors = (labelColors) => {
const { r, g, b, textColor } = labelColors;
const bgColor = "rgb(" + r + "," + g + "," + b + ")";
setFormat({ ...format, textColor: textColor, backgroundColor: bgColor });
};
pipe(createRandomRGBColor , isDarkColor , updateLabelColors)()
2.빨간색 영역
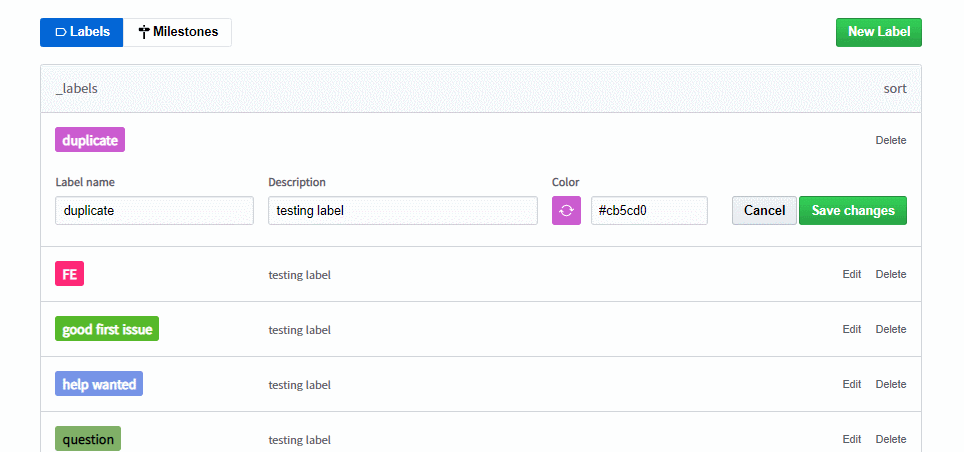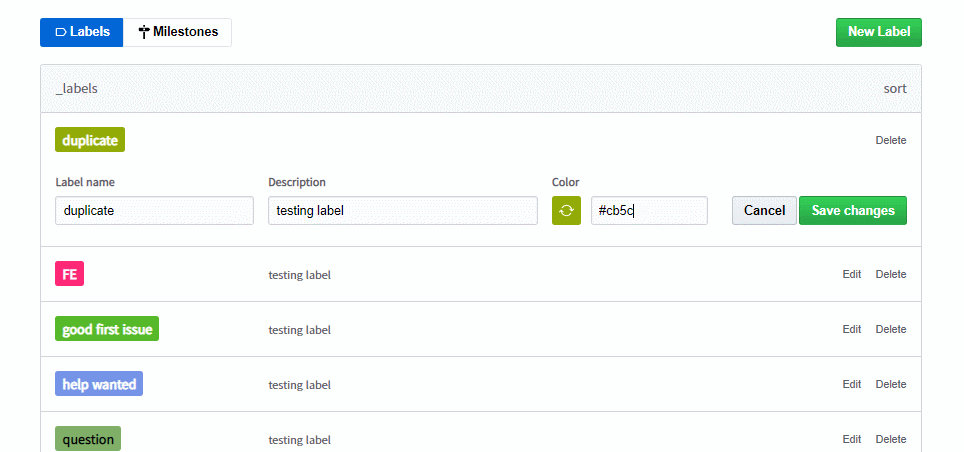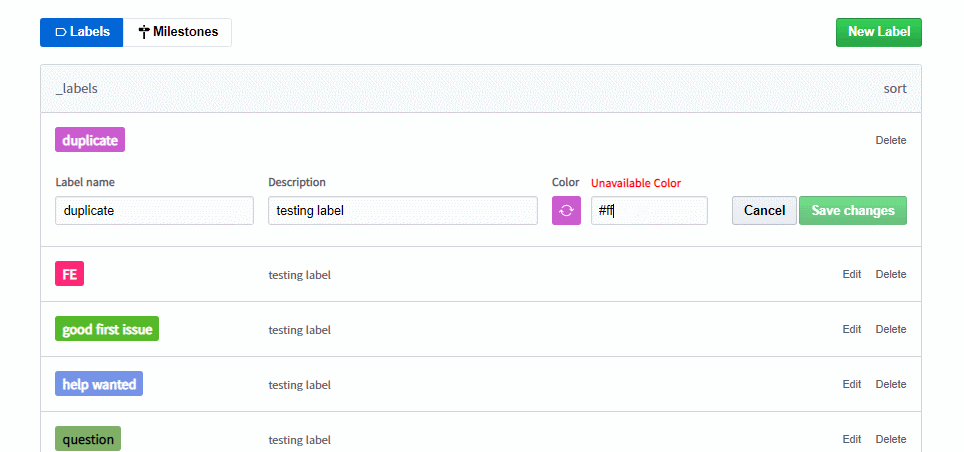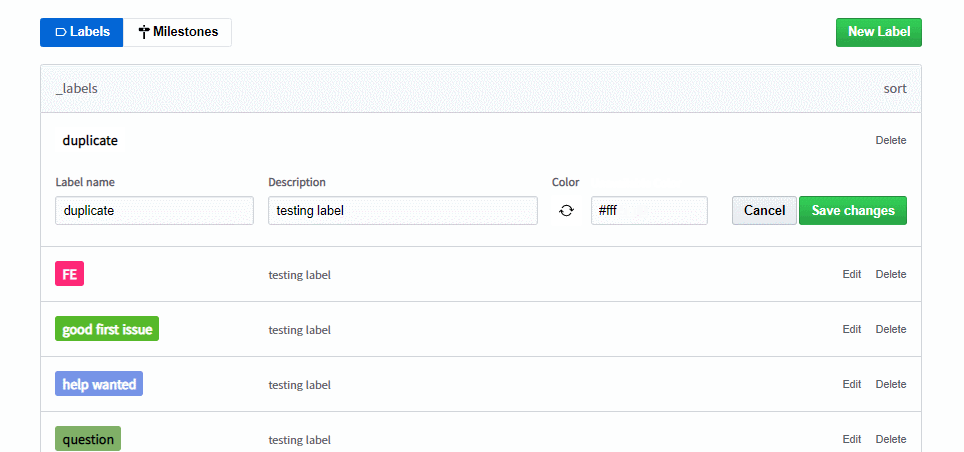
사용자는 원하는 Color를 16진수로 입력할 수 있으며 입력된 value가 유효한 16진수 값인지 판단한 후 상태를 update해준다.
1.사용자의 입력을 받는다.
2.input의 value를 update 해준다.
2.입력받은 색상의 값이 16진수를 기준으로 유효한 값인지 판단한다
(유효하지 않다면 null을 return 함)
3.null이 아닌 유효한 입력값을 받았다면 16진수를 Rgb로 변환한다.
(null을 입력받거나 16진수로 변환되지 않는다면 null을 return함)
4.text의 색상이 검은색인지 하얀색인지 판단한다.
((null을 입력받거나 RGB Type이 아니라면 null을 return함)
5.상태를 update 해준다.
((null을 입력받으면 Default Color(Gray)가 update되면서 error 문구의 상태를 true로 변환 )
const onChangeLabelColors = (e) => _.pipe(updateColorPickerInputValue, _.changeHexToRgb, _.isDarkColor, debounceLabelColors)(e.target.value);- 최종 화면
Pipe function 사용 후기
주황색 영역의 경우에는 각 함수들을 순수하게 분류하는 걸 생각보다 큰 고민 없이 구현했던 거 같다.
하지만 빨간색의 영역에 경우에는 실제로 구현하는데 꽤나 많은 고민을 했고 각 함수들이 순수한가? 그 부분에 대해서도 큰 의문이 든다...
저 두 개의 기능에 큰 차이점이 뭘까?라는 생각을 했을 때 예측할 수 있는 사용자의 행동이 아닐까 싶다. 첫 번째의 경우에는 사용자가 버튼을 클릭을 하는 경우만 생각하고, 또한 잘못된 색상 값의 경우를 고민하지 않아도 된다. 하지만 두 번째 기능은 실제로 사용자가 입력을 하고 그 입력된 값이 유효한지를 검증하는 과정을 거쳐야 한다. 클릭과 검증을 해야 하는 입력 이 두 가지의 고민의 크기는 생각보다 많이 차이가 났다. 그럼에도 Pipe function을 사용하면서 느낀 좋은 점은 하나의 함수에 많은 일을 시키지 않는다는 것이다. Pipe에 들어가는 함수들은 내가 값을 예측할 수 있는 순수 함수여야 하고, 그 과정에서 함수의 크기가 크다면 예외 상황에서의 처리도 복잡해질 뿐만 아니라 외부의 상태에 의존하는 상황에 노출되기 싶다는 생각이 들었다. 또한 나열된 작은 단위의 함수들로 인해 기능이 어떻게 작동되는지 좀 더 쉽게 이해할 수 있었다.
아직 깊게 알지 못하는 단계지만 functional programming(FP)과 친화적이라는 lodash 같은 라이브러리와 함수형 프로그래밍에 도움을 주는 라이브러리들의 구성을 살펴보면서 좀 더 깊게 공부하면 필요한 상황에서 멋지게 사용할 수 있을 거 같다.
