
미리 3줄 요약
select_related()는 DB에서 JOIN을 함. 오직 정참조 관계 (일대일, 일대다)에서만 쓰일 수 있음prefetch_related()은 Python이 JOIN을 해줌. 정참조 관계뿐만 아니고 다대다, 역참조도 가능.- 두 메소드가 하는 역할: 미리 관계가 있는 데이터까지 다 불러와서 cache에 남기면서 DB에 접근하는 수를 줄임 -> performace 향상
QuerySets are lazy
쿼리는 게으르다. 이 말이 무엇이냐 하면,
1. 쿼리셋에 어떤 액션을 취하기 전까지 그 액션에 상응하는 DB 쿼리문은 실행되지 않는다.
2. 똑같은 쿼리셋을 쓴다고 할지언정 여러개의 DB 쿼리문이 실행되지는 않는다.
이 점을 염두해두고 아래의 N+1 문제에 대해서 다뤄보겠다.
N+1 Query Problem
select_related, prefetch_related의 필요성을 피력하기전에, N+1 쿼리 문제에 대한 얘기를 하지 않을 수가 없다.
Django가 제공하는 ORM (Object-relational mapping)은 개발자들이 관계형 데이터베이스에 대한 깊은 지식이 없더라도 개발을 효율적이고 생산적으로 할 수 있도록 도와주는 중요한 도구이다. 하지만 ORM에는 치명적인 단점이 있다.
그것이 바로 N+1문제이다.
N+1 문제란, 한 쿼리문으로 데이터의 리스트를 loop를 돌고, 리스트 안의 하나에 데이터마다 쿼리문을 하나씩 실행하는 문제이다. Django는 필요한 데이터를 미리 끌어다쓰지 않기 때문에, foreign key로 참조하는 데이터를 찾기 위해서는 그 테이블에 가서 row 하나씩 확인해가면서 반복적인 쿼리문을 실행한다. 이러한 반복적인 과정에서 자원이 낭비된다.
In a nutshell: code that loops over a list of results from one query, and then performs another query per result.
N+1 문제는 코드의 효율과 성능을 치명적으로 저하시킨다.
이해가 잘 되지 않았다면 N+1 문제가 무엇인지 아래의 예시에서 자세히 살펴보도록 하자.
다음과 같은 테이블이 있다고 가정해보자:
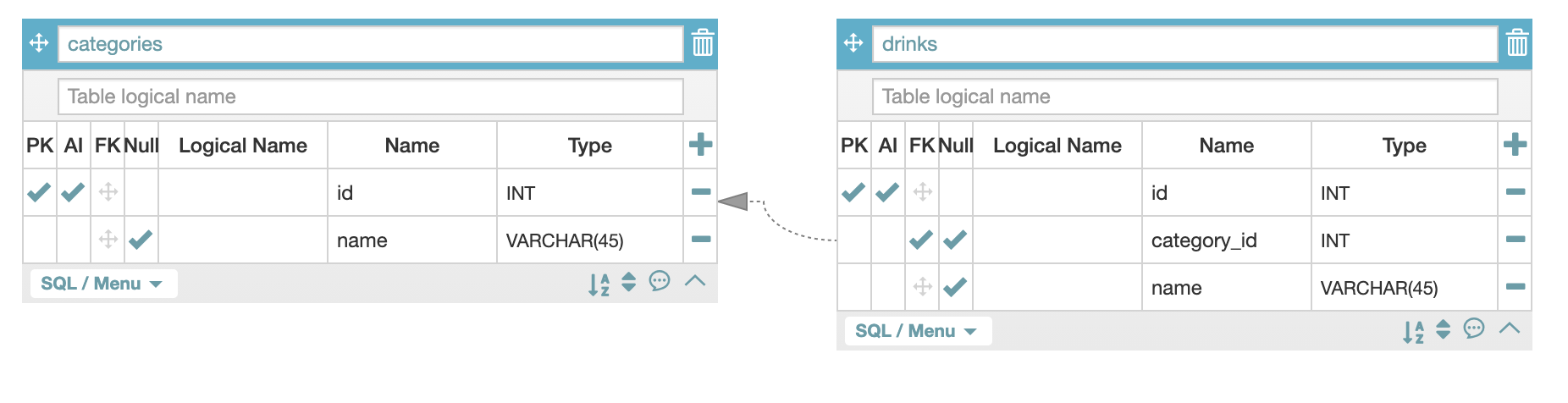
drink는 category를 참조하는 상황이다.
drinks 테이블의 전체 데이터를 불러오고, 각 drink에 해당하는 category를 프린트하고싶다.
>>> drinks = Drink.objects.all()
>>> for drink in drinks:
... print(drink.category)
...그렇다면 Django는 실제로 어떤 SQL 쿼리문을 보내고 있는 것일까?
-- 1st query
SELECT * FROM Category ...
-- 2nd query, N times
SELECT * FROM Drink WHERE category_id = 1
SELECT * FROM Drink WHERE category_id = 2
SELECT * FROM Drink WHERE category_id = 3
...
1st query에서 Category 테이블을 확인하는 것이 1번의 쿼리이고,
2st query에서 Drink 테이블에서 특정 category_id를 가진 drink를 찾기 위해 category 테이블의 row 개수만큼 N번의 쿼리문을 사용한다.
그래서 불필요하게 N+1 개만큼의 쿼리문을 사용하는 문제가 N+1 문제인것이다. 만약 row가 3-4개라면 큰 문제가 되지 않을지도 모른다.
하지만 row가 1000개라면? 우리는 캐시에 저장되어 있지 않는 단 하나의 foreign key에 접근하기 위해서 다른 쿼리문을 또 날려서 값을 찾아야한다. 결국에는 1001번의 쿼리문을 사용하는 것이다.
N+1 문제는 즉, 필요한 정보만 쓰는 것이 아니고 참조하는 테이블에서 row 하나하나를 쿼리문을 실행해가면서 확인한다는 불필요함에서 시작된다.
데이터베이스에 접근하는 빈도수가 증가하여 자원이 낭비될 수 있기 때문이다.
그리고 위에서 언급했듯, 쿼리는 게으르다. 그렇기 때문에 여러개의 작은 쿼리문을 실행하는 것보다 하나의 무거운 쿼리문을 실행시키는 것이 더 효율적이고 빠르다.
그러므로 적은 수의 쿼리문을 실행시킬 있는 방법을 찾아야한다.
이 방법들이 바로 select_related(), prefetch_related()이다.
Solutions
select_related()
select_related()
- ForeignKey와 OneToOneField에서만 쓸 수 있다. (ManyToManyField 안됨)
- query문 하나를 날려서 테이블을 JOIN한다
- 정참고 관계에서만 쓸 수 있다:
자식.select_related(부모)
아래의 예제들을 통해 실제로 날리는 쿼리문이 얼마나 줄어드는지 살펴보자.
📌는 데이터베이스를 확인한다는 뜻이다. (DB HIT)
select_related()를 사용하지 않은 경우
>>> drinks=Drink.objects.all() [1]📌 DB HIT!
>>> for drink in drinks:
... print(drink.category) [2]📌 N개의 drink만큼 DB HIT!
...
>>> len(connection.queries)
10그렇다면 select_related()를 사용하지 않은 일반적인 경우에는 어떤 쿼리문이 실행되는걸까? N+1 문제를 야기하는 반복적인 쿼리문이 실행된다.
-- 1st query
SELECT * FROM Drink
-- 2nd query, N times
SELECT * FROM Category WHERE drink_id = 1
SELECT * FROM Category WHERE drink_id = 2
SELECT * FROM Category WHERE drink_id = 3
...
select_related()를 사용한 경우
>>> drinks=Drink.objects.select_related('category').all() 📌DB HIT!
>>> for drink in drinks:
... print(drink.category)
>>> len(connection.queries)
3
select_related()를 쓰지 않을 때는 쿼리문 10개,
select_related()를 쓸 때는 쿼리문 3개를 실행하고 있음을 알 수 있다.
딱 7개만큼의 차이가 나는데, 이것은 drinks 테이블의 row 수가 7개이기 때문이다. 딱 N개만큼의 차이가 나는 것이다.
select_related()의 작동 원리: INNER JOIN
select_related()을 쓰지 않는 경우에는 두개의 다른 테이블을 확인하면서 첫번째 테이블의 데이터 하나하나를 통해 두번째 테이블을 계속 확인하는 과정을 진행한다.
그럼 select_related()을 사용하는 경우에는 Django는 실제로 어떤 SQL 쿼리문을 보내고 있는 것일까?
>>> drinks = Drink.objects.select_related('category').all()
>>> print(drinks.query)
SELECT `drinks`.`id`, `drinks`.`name`, `drinks`.`category_id`,
`categories`.`id`, `categories`.`name`, `categories`.`menu_id`
FROM `drinks`
INNER JOIN `categories`
ON (`drinks`.`category_id` = `categories`.`id`) select_related()를 쓰면 SQL에서는 INNER JOIN을 실행한다.
INNER JOIN을 실행하면 모든 합쳐진 테이블의 column을 포함할 수 있으므로 한 테이블 안에서 원하는 데이터를 찾을 수 있는 범위를 넓혀준다.
그러므로 데이터를 찾기 위해 참조하는 테이블에 가서 row 하나하나씩을 확인하는 수고를 하지 않아도 되는 것이다.
prefetch_related()
지금까지 select_related()에 대해서 알아보았다. 하지만 이는 정참조 관계에서만 쓸 수 있었다. 이제부터 다대다 관계 (manytomany relationship)에서 쓸 수 있는 prefetch_related()를 알아보자.
prefetch_related():
select_related()가 쓰일 수 있는 모든 경우 + ManyToManyField에 사용가능
아래에서 예제를 살펴보자.
drink와 allergy는 ManyToMany 관계이다.
하나의 drink는 여러개의 allergy를 가질 수 있고, 하나의 allergy도 여러개의 drink를 가질 수 있다.
prefetch_related()를 사용하지 않은 경우
>>> drinks = Drink.objects.all()
>>> for drink in drinks:
... drink.allergy.all()
...
>>> len(connection.queries)
11prefetch_related()를 사용한 경우
>>> drinks = Drink.objects.prefetch_related('allergy').all()
>>> for drink in drinks:
... drink.allergy.all()
...
>>> len(connection.queries)
4
prefetch_related()를 사용하지 않은 경우에는 11개의 쿼리문을,
prefetch_related()를 사용한 경우에는 4개의 쿼리문만을 실행한 것을 확인할 수 있다.
딱 7개만큼의 차이가 나는데, 이것은 drinks 테이블의 row 수가 7개이기 때문이다. 딱 N개만큼의 차이가 나는 것이다.
prefetch_related()의 작동 원리: Python에서의 JOIN
Beginning Django: Web Application Development and Deployment with Python. p369
... the
select_related()method fetches related model data in a single query by means of a database JOIN; however, theprefetch_related()method executes its join logic once the data is in Python.
이 말은 즉슨, select_related()는 한개의 쿼리문을 실행하여 DB의 JOIN을 써서 관계가 있는 (즉, 참조하고 있는) 데이터를 가져온다는뜻이고, prefetch_related()는 데이터가 파이썬에 들어오면 그 JOIN을 실행한다는 뜻이다.
prefetch_related()가 실행하는 쿼리문은 실제로 어떤 식으로 돌아가는 것일까? 위에서 썼던 예제에서 쓰이는 쿼리문이 무엇인지 프린트해보았다.
>>> drinks = Drink.objects.prefetch_related('allergy').all()
>>> print(drinks.query)
SELECT `drinks`.`id`, `drinks`.`name`, `drinks`.`category_id`
FROM `drinks`
책에 적힌 실행 과정 (길면 넘기고 마지막 요약만 읽으세요)
실제로 Django가 실행하는 raw SQL 쿼리문을 보면 JOIN이 없는 단순한 쿼리문처럼 보인다.
select_related()가 쓰일때와는 다르게prefetch_related()를 사용하는 경우에는 첫번째 쿼리문이 실행되고 난 후prefetch_related()안에서 선언된 모든 관계가 있는 모델의 QuerySet instances를 만들어낸다. 이는 한번에 일어난다.그래서 우리가
prefetch_related()를 써서 관계 있는 모델을 참조하려고 할때, Django는 이미 관련된 결과들을 다 cache에 미리 저장해둔 상태이다. 이때 Python의 자료 구조로서 JOIN이 실행이 되면서 결과가 나온다.
실행 과정 한줄 요약:
Django와 Python이 알아서 관계가 있는 데이터를 효율적으로 읽기 위해 새로운 쿼리셋 자료 구조를 관리하고 만들어주는 역할을 한다.
select_related() vs prefetch_related()
그렇다면 select_related()를 쓰는 것보다 더 포괄적인 prefetch_related()를 쓰면 되지 않을까? 왜 두가지가 따로 있는 것일까?
위에서 설명했듯, select_related()는 SQL에서 JOIN을 하는 반면, prefetch_related() 는 첫번째 쿼리문이 실행되면 Python에서 알아서 JOIN 로직을 실행하여 관계가 있는 데이터를 모두 끌어와서 정리한다.
만약 같은 foreign key로 엮여있는 3-5개의 모델이 있다면 select_related()가 나을 것이다. 반면에, 같은 foreign key를 쓰는 100개, 1000개의 모델들이 있다면 prefetch_related() 가 나을 것이다. 둘 중에서 무엇이 더 효율적인지는 실제로 코드를 실행해보고 어떤 쿼리문이 얼마나 실행되는지 확인해야한다.
References
- https://scoutapm.com/blog/django-and-the-n1-queries-problem
- https://www.codementor.io/@pritishc/django-optimization-or-how-we-avoided-memory-mishaps-yh6fwfxet
- https://medium.com/codeptivesolutions/prefetch-related-and-select-related-in-django-90f07a2379c0
- https://medium.com/chrisjune-13837/%EB%8B%B9%EC%8B%A0%EC%9D%B4-%EB%AA%B0%EB%9E%90%EB%8D%98-django-prefetch-5d7dd0bd7e15
- https://docs.djangoproject.com/en/3.1/ref/models/querysets/
- https://stackoverflow.com/questions/31237042/whats-the-difference-between-select-related-and-prefetch-related-in-django-orm#:~:text=The%20difference%20is%20that%20select_related,ModelA%20in%20the%20above%20example).
- Daniel Rubio, 'Beginning Django: Web Application Development and Deployment with Python', p367-369
