
문제
Duplicate이 없는 유일한 element 하나를 찾아서 return 하는 것이다.
사실 그렇게 어려운 문제는 아닌데, 시간 복잡도, 공간 복잡도를 제대로 고려하고 풀어야하는 문제라서 넣어보았다. 그리고 이 단순한 문제에 다양한 접근 방식이 있는 것이 흥미로워서 글을 써보려고 한다.
솔루션
Approach 1. Count
Time Complexity: O(n^2), Space Complexity: O(n)
단순하게 생각하면 사실 풀기는 쉽다. Time complexity를 고려하지 않는다면 말이다.
# Approach 1. count
class Solution:
def singleNumber(self, nums: List[int]) -> int:
for i in nums:
if nums.count(i) == 1:
return inums의 각각의 element인 i가 nums에 몇번씩 있는지 확인하고, 만약 1개만 있다면 그 숫자인 i를 리턴하는 방식이다.
for loop으로 돌릴때 O(n), count() 함수를 쓸 때 O(n)이므로 time complexity는 O(n^2)이다.
space complexity는 nums라는 list가 있으므로 O(n)이다.
하지만 O(n^2) time complexity는 optimal과 거리가 멀다.
Leetcode submission 결과
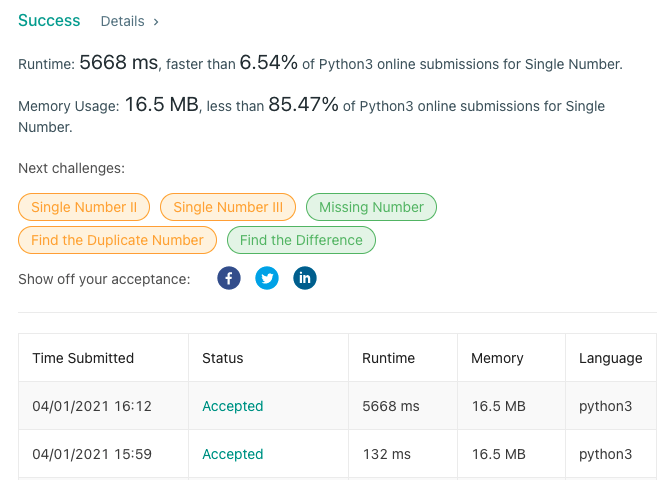
O(n^2)으로 푼 솔루션의 runtime은 5668ms인 반면, O(n)으로 푼 솔루션의 runtime은 132ms이다.
이 엄청난 차이를 생각하면 시간 복잡도의 중요성을 알 수 있다.
Follow up: time complexity O(n)으로 풀어봐
Approach 2. Sum
Time complexity: O(n), Space complexity: O(n)
class Solution:
def singleNumber(self, nums: List[int]) -> int:
return 2 * sum(set(nums)) - sum(nums)set으로 duplicate들을 일단 다 없앨 수 있다.
sum(nums) - sum(set(nums)) 는 sum of duplicates 일 것이다.
duplicate들은 오리지널 nums list에 두번씩 나타나므로, 2* (sum of duplicates) 를 sum(nums)에서 뺀다면 우리가 원하는 딱 한개만 존재하는 숫자가 나올 것이다.
sum(nums) - 2*(sum(nums) - sum(set(nums)))
= 2*sum(set(nums)) - sum(nums)Approach 3. Hash Table
Time complexity: O(n), Space complexity: O(n)
from collections import defaultdict
class Solution:
def singleNumber(self, nums: List[int]) -> int:
hash_table = defaultdict(int)
for i in nums:
hash_table[i] += 1
for i in hash_table:
if hash_table[i] == 1:
return i왜 hash table을 쓸 생각을 안했지??싶다.
Approach 4. Bit manipulation
Time complexity: O(n), Space complexity: O(n)
class Solution(object):
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
a = 0
for i in nums:
a ^= i
return a프린트를 해보았다.
input: nums = [2, 2, 1]
========================
i: 2
a before: 0
a after: 2
========================
i: 2
a before: 2
a after: 0
========================
i: 1
a before: 0
a after: 1i가 한번 나오면 a가 i가 되고, 두번 나오면 0이 되는 것을 알 수 있다.
Wrap-up
- hash table 써보는 버릇좀 들이자.
- Bit manipulation 저거 뭔지 공부 좀 한 후에 블로그 글을 쓰도록 하자
