Kafka에 대한 정리
현재 실무에서 실제로 사용하게 될 Kafka(이하 카프카)에 대해 어떤 역할을 하는지는 대략적으로 알고 있지만, 현재 너무 수박 겉핥기 식으로 알고 있다보니 업무에서 사용 시
제대로된 개념 없이 사용하고 있다는 느낌을 종종 받고있다. 그래서 개념 정리 겸 실무 사용에서도 버벅이지 않고 잘 사용하기 위해 카프카에 대한 전반적인 내용을
정리해보려 한다.
Kafka(카프카)란?
Apache Kafka®는 이벤트 스트리밍 플랫폼입니다. - 아파치 카프카 공식 사이트
- 대용량, 대규모의 데이터를 빠르게 분산 처리할 수 있는 메세지 스트리밍 플랫폼.
- 데이터 파이프라인 구성 시 사용되는 오픈소스이며, APP간 메세지 교환을 관리.
- 기존 DB 하나에 붙어 의존하던 시스템 -> MSA 형태로 변함에 따라 모듈간의 메세지 전달을 원할하게 하기 위해 사용.
카프카 구조
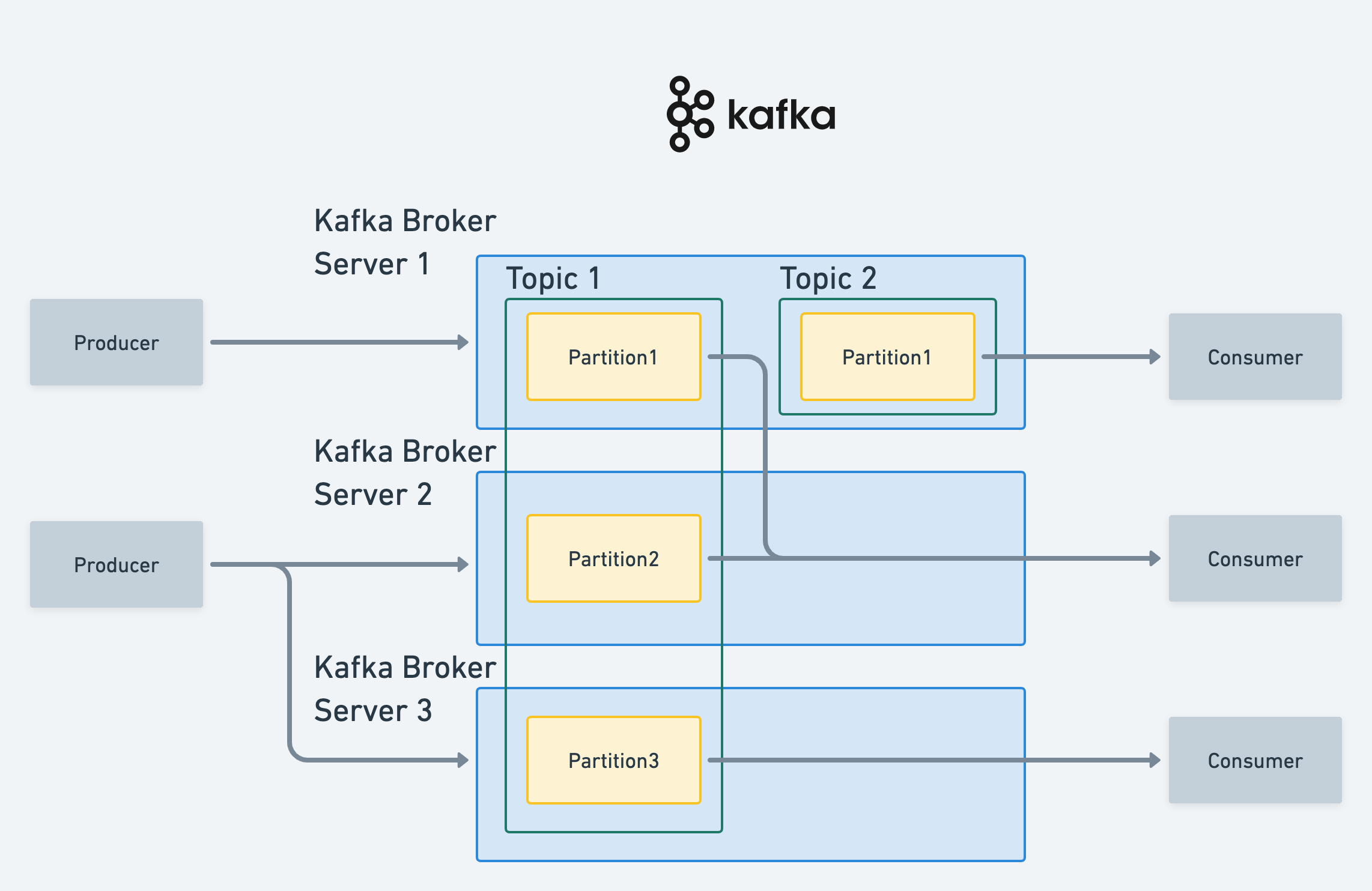
기본적으로 Producer에서 메세지를 전달하면 Kafka를 통해 Consumer가 메세지를 처리하는 구조.
- Producer: 메세지를 보내는 쪽. 메세지는 보내는 행위를 Publish(Pub) 이라고 함.
- Consumer: 메세지는 받는 쪽. 메세지를 받는 행위를 Subscribe(Sub) 이라고 함.
- Topic: 이벤트(메세지)를 저장하는 일종의 저장소. 단순화된 토픽은 컴퓨터의 폴더와 유사하며, 이벤트(메세지)는 그 폴더의 파일이라고 볼 수 있음.
- Kafka Broker: 실질적인 메세지를 처리해주는 카프카 서버. 단일 및 클러스터 구성 가능. 토픽별로 파티션을 가짐.
- Partition: 토픽을 통해 들어오는 데이터를 분산 저장할 수 있는 저장소. 쉽게 말해 바구니라고 생각할 수 있다.
위의 프로듀서와 컨슈머에서 작성한 메세지를 보내는/받는 형태를 pub/sub 모델이라고 함.
- pub/sub 모델은 비동기로 동작함.
- 메세지의 수신자가 따로 정해져있지 않음.
- 발행된 메세지는 구독을 신청한 수신자에게 전달 됨.
- 수신자는 발행자에 대한 정보가 없어도 메세지 수신이 가능함. 이는 높은 확장성을 제공한다.
(참고: 위키백과)
파티션
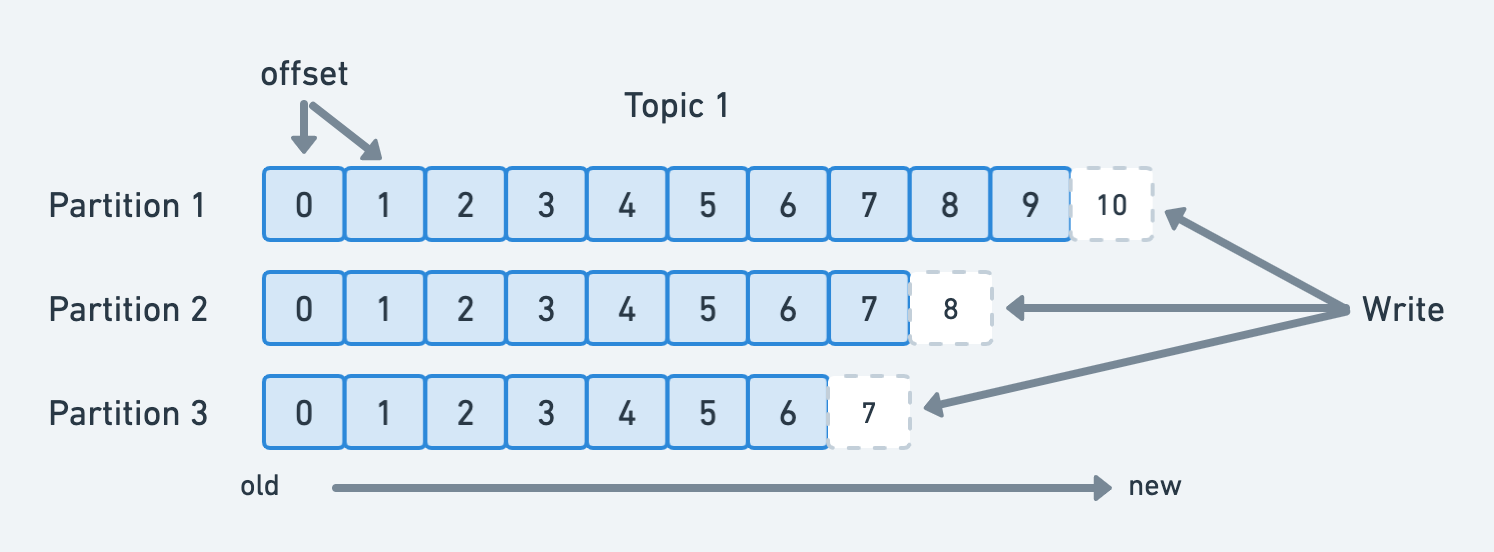
- 토픽을 통해 들어오는 데이터를 저장하는 저장소.
- 한 개의 토픽은 한 개 이상의 파티션으로 구성.
- 메시지 추가만 가능한 append-only 방식의 파일.
- 실제 데이터들이 파일로 남기 때문에 장애 발생 시 복구에 용이.
파티션을 나누는 이유
- 수천건씩 들어오는 메세지들을 병렬 분산하여 빠르게 데이터처리를 하기 위해.
- 파티션이 1개일 경우, 하나의 파티션에 순차적으로 데이터들이 append 됨. 그럴 경우 속도 저하 및 서버 부하가 발생.
카프카 컨슈머 그룹
- 카프카 컨슈머는 컨슈머 그룹으로 묶어 사용이 가능함.
- 여러개의 컨슈머를 하나의 그룹으로 묶어, 하나의 토픽에 붙여서 메세지 컨슈밍이 가능함.
- 그룹으로 묶어서 사용할 경우 컨슈머 그룹의 offset 관리에 용이하다.
컨슈머 그룹없이 하나의 토픽을 여러 컨슈머가 컨슈밍할 경우 offset이 뒤죽박죽되게 된다.
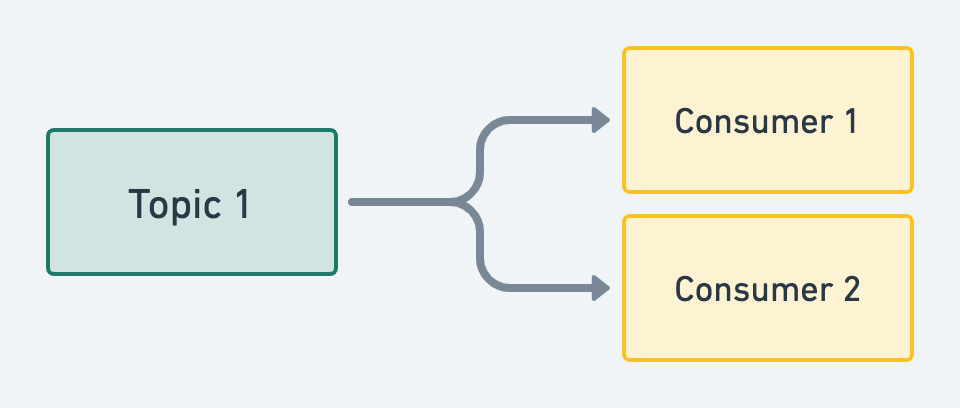
하나의 토픽을 두개의 컨슈머에서 데이터를 가져가는 경우 아래 그림과 같이 데이터를 가져가게 됨.

Consumer 1 이 3번까지 데이터를 가져간다. 이 때 offset은 4번을 읽을 위치로 감.
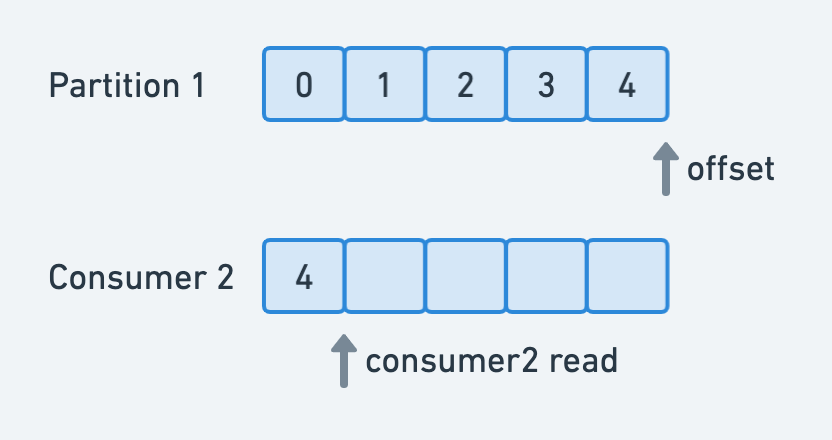
- 이 상태에서 Consumer 2 가 컨슈밍을 하면 offset 위치에 의해 4번 데이터만을 가져가게 되고 offset은 그 다음 메세지 읽을 위치로 감.
- 앞의 1, 2, 3 데이터에 대해서 Consumer 2 는 알 방법이 없음.
- 이때 Consumer 1 이 컨슈밍을 시도 하면 offset이 이동했으므로 4번을 넘기고 그 다음에 들어올 데이터를 읽어옴.
- 결국 offset 관리가 안되며, 데이터를 서로 뒤죽박죽 가져가게 됨.
이를 컨슈머 그룹으로 묶을 경우 동일한 토픽을 여러 컨슈머 그룹이 컨슘하더라도 서로 각기 다른 offset을 가지고 데이터의 손실 없이 가져가기가 가능함.
컨슈머와 파티션간 관계
컨슈머 구성은 보통 파티션당 컨슈머 한 개 또는 파티션 개수의 절반만큼의 컨슈머 구성이 가장 이상적임.
카프카에서는 하나의 파티션에 대해 컨슈머 그룹내 하나의 컨슈머 인스턴스만 접근이 가능함.
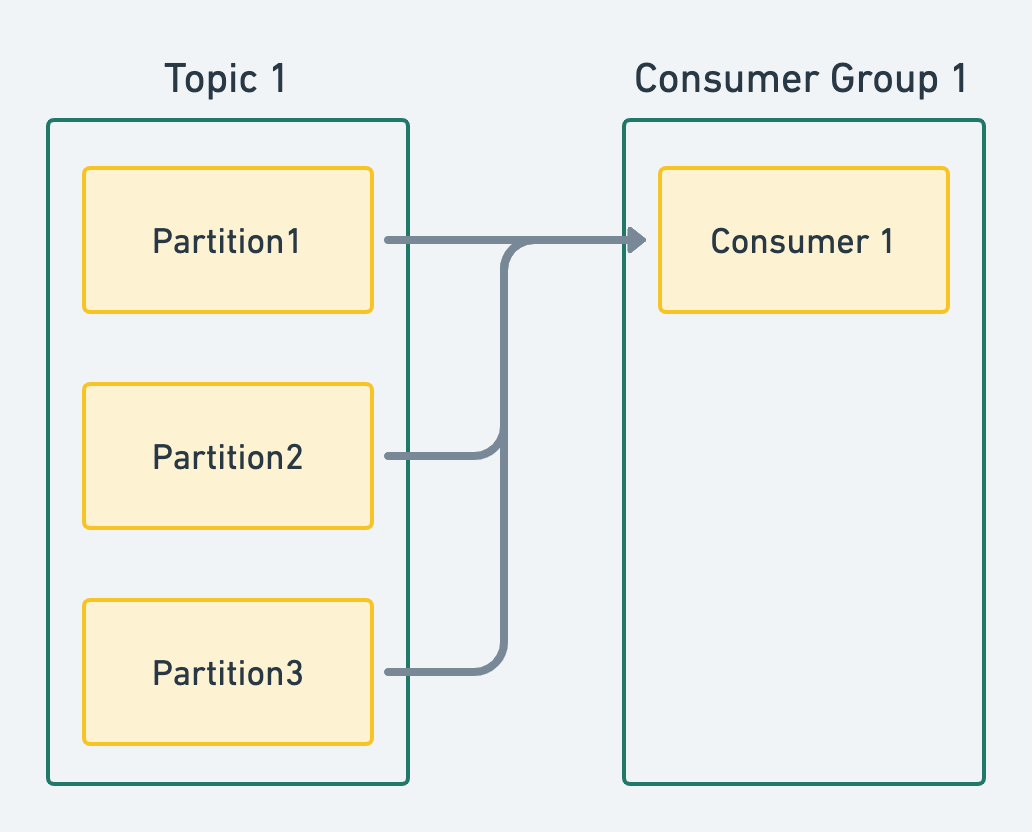
- 그룹에 컨슈머가 하나만 있을 경우 하나의 컨슈머가 모두 처리 하므로 메세지가 대량으로 올 경우 부하 발생 가능
- 해당 컨슈머에 장애가 발생할 시 메세지를 가져 오지 못하고 컨슈머가 복구될 때 까지 메세징 처리가 되지 않음.
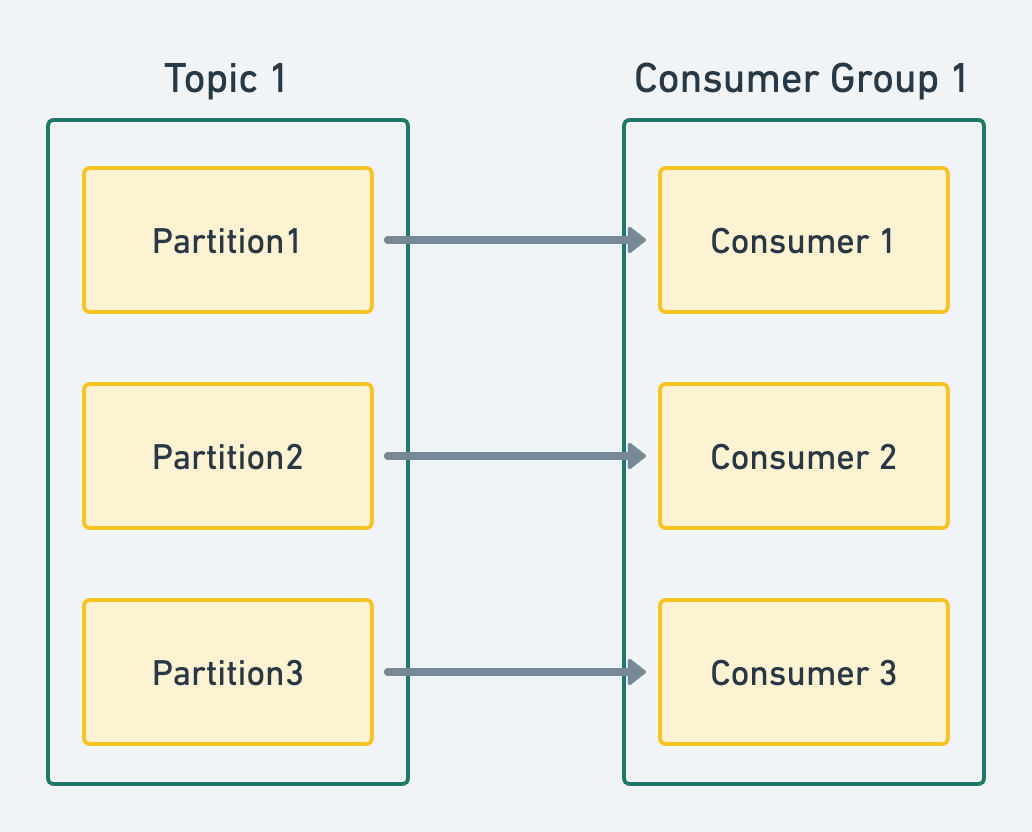
- 가장 이상적인 모습. 파티션 하나당 컨슈머 하나가 데이터를 컨슘함.
- 이때 컨슈머 인스턴스중 하나가 장애가 나도 나머지 2개의 컨슈머에서 데이터 처리가 가능.
- 이렇게 구성할 경우 각각의 파티션에 컨슈머가 붙어 데이터 처리가 이루어지므로 데이터 처리 속도가 빨라지게 됨.
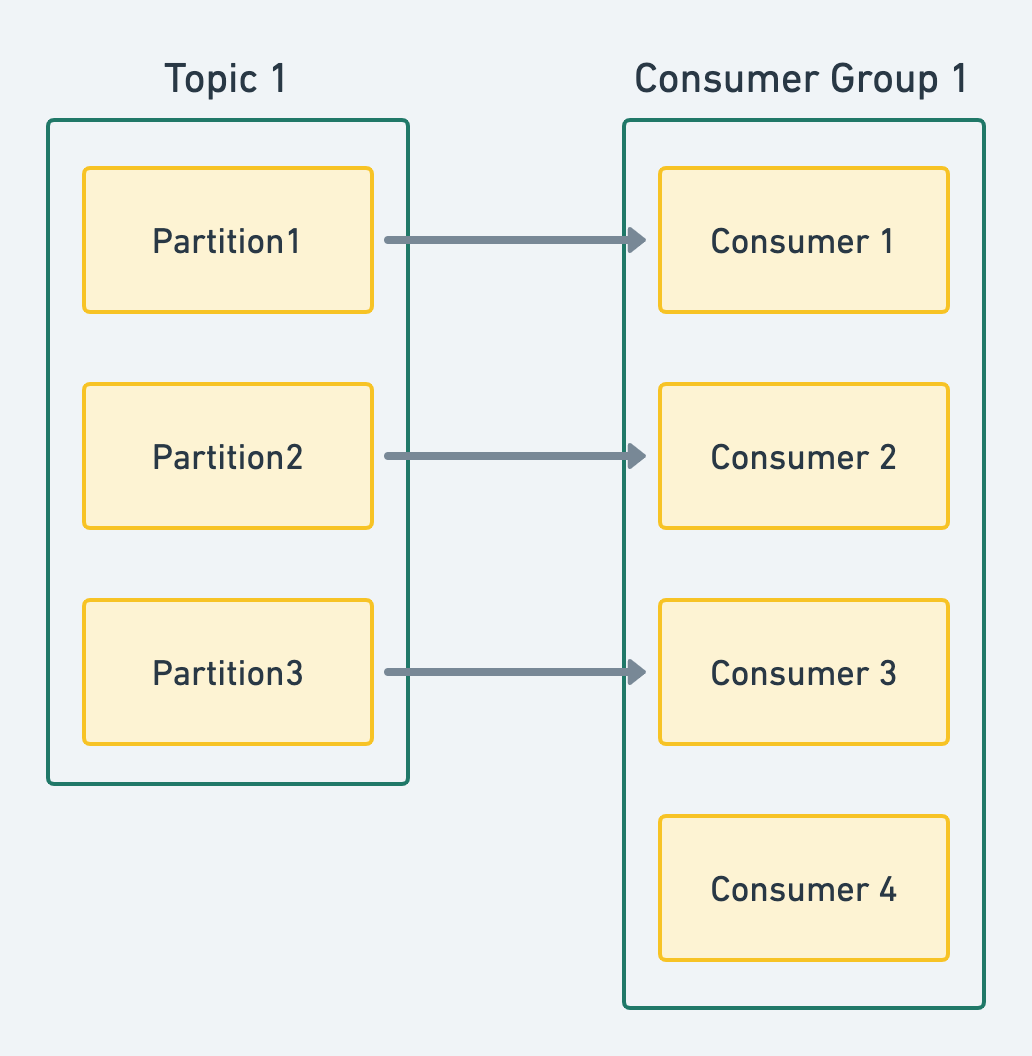
- 컨슈머가 파티션 수보다 많을 경우 위 그림 처럼 어떤 파티션에도 붙지 못하고 잉여자원으로 남게 됨. (하나의 파티션에 대해 하나의 컨슈머만 붙음)
- 위와 같은 구성은 좋은 구성이라 볼 수 없음.

개발 잘하고 싶다...!