[SmoothRide] 프로젝트에 대한 고민
오늘 이력서 컨설팅을 받았다. 당연히 탈탈 털리면서 배웠고, 내가 모르는게 엄청 많다는 것을 알게 되었다. 한시간동안 열심히 들었는데, 그래서 까먹기 전에 오늘 우선 해놨다.
깃헙도 꾸미고, 이력서도 고치고.. 해보니 뭔가 한 거 같아서 뿌듯하긴 하다. 그래도 더 고쳐야지.
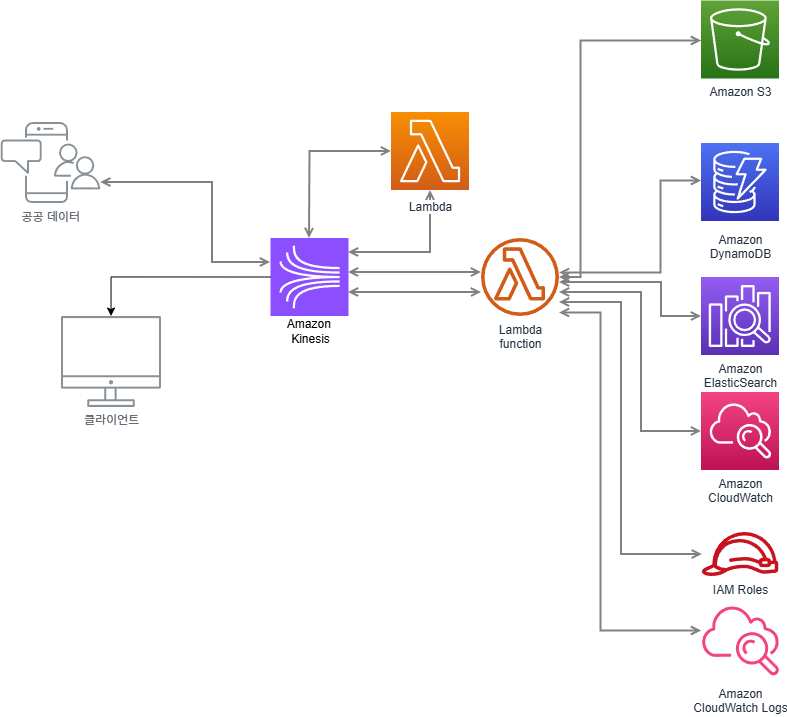
SmoothRide 프로젝트가 기획만 한것이고, 내가 aws 쪽에 대한 지식이 많은 것이 아니기 때문에 지피티랑 다 짰는데, 이게 맞나 여쭤보고 싶어서 여쭤봤다.
우선 가장 중요한 것 중 하나는 본인이 설계한 아키텍처에 이유가 있어야 한다 였다.
코치님께서 "왜 아마존 키네시스를 사용했냐?" 라고 하셨을 때는
다른 AWS 서비스들과 호환이 잘 되고, AWS 서비스를 많이 써보는 경험을 해보고 싶다 라고 답했었다. 하지만 그 다음에 "그럼 AWS에는 키네시스 말고도 SQS도 있고, 분산형 메시지 큐 시스템이 여러개 있는데 왜 키네시스를 쓰냐?" 라고 하셨을 때는 할말이 없었다. 쩝.
이 프로젝트의 메인은 AWS 키네시스라고 생각했는데, 키네시스를 왜 사용해야 하지? 라는 의문이 생기니 같이 돌아가는 람다도 존재 의의가 부실해졌다.
그리고 AWS 서비스를 많이 사용하고 싶었다라고 했는데, 다른 곳 취업할때는 별로 좋지 않을 것 같다고 말씀하셨다.
또한 나는 이정도면 대규모 데이터라고 생각을 했는데, 본질적인 질문으로 "이 프로젝트는 대규모 처리에 대한 요청사항을 가지고 있는가?"라는 말씀을 하셨다. 나는 대규모 데이터라는 기준은 운영하는 서버에 따라 상대적이라고 생각을 했었는데, 코치님께서는 이것도 맞지만 제너럴하게
1. 단일 호스팅 메모리에서는 도저히 전부를 계산할 수 없다.
2. 단일 호스트만으로는 원하는 레이턴시를 끌어낼 수 없다.
이를 해결하기 위해 병렬 처리/배치를 사용하는 것인데, 과연 이 프로젝트는 그정도의 감당하지 못할 데이터를 가져오는가? 라고 하셨다.
그래서 네이밍 바꾸기 -> 어느 정도의 트래픽을 견딜 수 있게 아키텍처 구현 (분산 시스템)
대규모 처리 및 부하 테스트에는 명확한 기준(3000명 접속자 기준, 프로세스 수는 얼마..)
감안할 수 있는 커버리지
라는 걸 얘기해주셨는데, 솔직히 근본부터 흔들리는 것 같아서 현타가 좀 왔다. 나름대로 아키텍처에 대한 질문을 대답하고 싶었는데, 아는게 없어서 그런가. 그래서 며칠동안 아키텍처를 생각을 다시 해볼까 한다.
