Django Admin-7 : Django Admin에 <table> 폼필드 추가하기 (Pandas 끼얹기)
Django Admin을 여행하는 히치하이커를 위한 안내서
어떤 항목은 표로 보여주는 것이 더 알아보기 쉽다.
이번에는 테이블 태그를 쉽게 추가하기 위해 판다스를 쓰는 방법을 알아볼 것이다.
1. 기본 구성
예시를 위해 먼저 테이블을 구성한다.
1) 설문조사 테이블 추가
예시를 위해 설문조사 테이블을 만든다.
설문조사 테이블, 설문조사 질문 테이블, 설문조사 응답 테이블 세가지를 만든다.
# adminpage\models.py
...
class Survey(models.Model):
id = models.AutoField(primary_key=True)
surv_name = models.CharField(verbose_name="설문조사명",max_length=200)
updated_at = models.DateTimeField(auto_now=True, verbose_name="수정일", )
created_at = models.DateTimeField(auto_now_add=True, verbose_name="생성일", )
def __str__(self):
return f"{self.surv_name}"
class Meta:
managed = True
db_table = 'survey'
verbose_name_plural = '설문조사'
class SurveyQ(models.Model):
id = models.AutoField(primary_key=True)
surv_id= models.ForeignKey(Survey, on_delete=models.CASCADE, db_column="surv_id", related_name="surv_survQ")
surv_q_content= models.CharField(verbose_name="설문조사 질문",max_length=200)
updated_at = models.DateTimeField(auto_now=True, verbose_name="수정일", )
created_at = models.DateTimeField(auto_now_add=True, verbose_name="생성일", )
def __str__(self):
return f"[{self.surv_id}]{self.surv_q_content}"
class Meta:
managed = True
db_table = 'survey_q'
verbose_name_plural = '설문조사 질문'
class SurveyA(models.Model):
id = models.AutoField(primary_key=True)
surv_q_id= models.ForeignKey(SurveyQ, on_delete=models.CASCADE, db_column="surv_q_id", related_name="survQ_survA")
user_id= models.ForeignKey(User, on_delete=models.CASCADE, db_column="user_id", related_name="user_survA")
surv_a_content= models.CharField(verbose_name="설문조사 응답",max_length=200)
created_at = models.DateTimeField(auto_now_add=True, verbose_name="생성일", )
def __str__(self):
return f"[{self.surv_q_id}]{self.surv_a_content}"
class Meta:
managed = True
db_table = 'survey_a'
verbose_name_plural = '설문조사 응답'
python manage.py makemigrations 과 python manage.py migrate을 해 데이터베이스에 적용한다.
2) 설문조사 어드민 추가
설문조사 관련 어드민을 추가한다. 응답은 table로 직접 추가할 것이다.
# adminpage\admin.py
class SurveyQInline(admin.TabularInline):
model = SurveyQ
readonly_fields = ('created_at', 'updated_at')
extra = 0
class SurveyAdmin(BaseAdmin):
list_display = ('id',
'surv_name',)
list_display_links = ('surv_name',)
fields = ( 'surv_name', 'updated_at', 'created_at')
readonly_fields = ('updated_at', 'created_at')
inlines=[SurveyQInline]
...
admin_site.register(Survey, SurveyAdmin)이렇게 하면 다음처럼 설문조사 어드민이 구성된다.
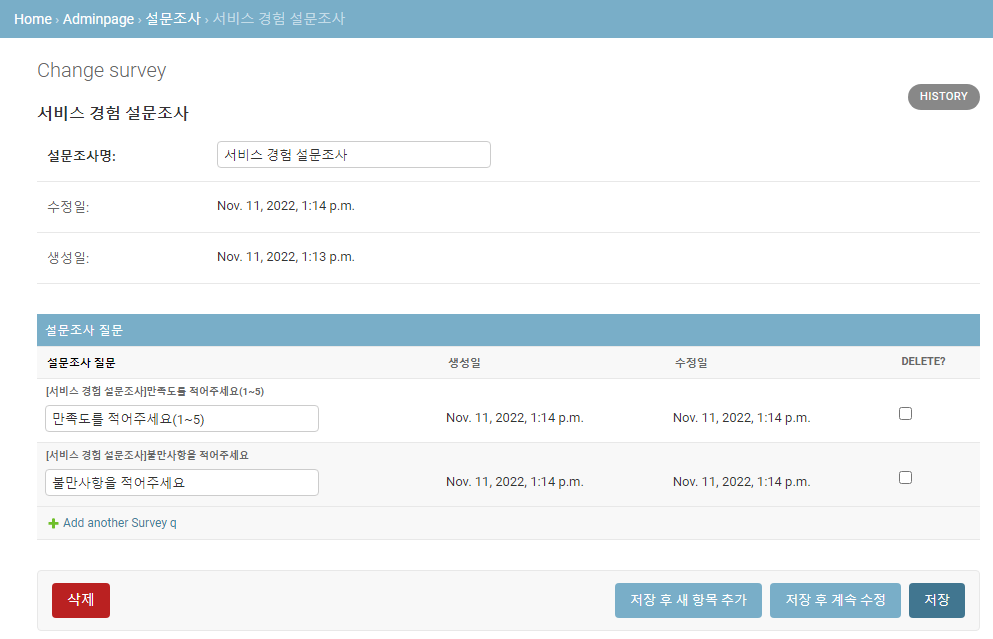
2. 판다스 쓰지 않고 <table> 추가하기
Django Admin-3 : 내용 커스텀하기(HTML/JS/CSS)와 동일하게 어드민에서 항목을 추가한다.
설문조사 질문 로우 하나에 모든 응답을 <table>로 만들되, 동일한 응답은 묶어서 응답 개수의 합을 보여주고 총 응답 개수 또한 보여줄 것이다.
1번 질문에 2명이 4점을, 1명이 3점을 주었을 경우 <table>은 다음과 같이 나타날 것이다.
| 응답 | 응답 수 |
|---|---|
| 4 | 2 |
| 3 | 1 |
| 모든 응답 | 3 |
# adminpage\admin.py
...
from django.db.models import Count
class SurveyQInline(admin.TabularInline):
model = SurveyQ
fields = ( 'surv_q_content', 'updated_at', 'created_at', 'tableRow')
readonly_fields = ('created_at', 'updated_at', 'tableRow')
extra = 0
@admin.display(description="전체 응답")
def tableRow(self, obj):
try:
result = """<table style='width: 100%;'>
<thead>
<tr>
<th>응답</th>
<th>응답 수</th>
</tr>
</thead>
<tbody>
"""
string = []
queryset = obj.survQ_survA.all()\
.values('surv_a_content')\
.annotate(total=Count('surv_a_content'))\
.order_by('-total')
for query in queryset:
string.append("""
<tr>
<td>%s</td>
<td>%s</th>
</tr>
"""% ( query['surv_a_content'], query['total']))
string.append(f"""
<tr>
<td>모든 응답</td>
<td>{obj.survQ_survA.all().count()}</th>
</tr>
""")
string = result + ' '.join(string) + "</tbody></table>"
return mark_safe(string)
except Exception as e:
print(e)먼저 <table> 기본 정보를 result에 저장해 두고, 쿼리셋을 돌면서 <tbody> 내용을 추가한다. 쿼리셋을 모두 돈 뒤에는 <tbody>와 <table> 태그를 닫는 문자열을 추가했다.
쿼리셋을 어떻게 만들었는지 살펴보자.
from django.db.models import Count ... # 현재 오브젝트(survQ 인스턴스)와 연결된 모든 survA를 불러온다 obj.survQ_survA.all() # survA쿼리셋에서 'surv_a_content'만 뽑는다. .values('surv_a_content') # 뽑아낸 결과에 집계 주석을 추가한다. # 'total'이라는 이름으로 # 'surv_a_content'개수를 세서 주석을 단다. .annotate(total=Count('surv_a_content')) # 최종 결과를 'total' 기준 desc로 정렬한다. .order_by('-total')django의 group_by는
values와annotate를 통해 이뤄진다.
공식문서에 다음과 같은 내용이 있다.values()절을 사용하여 결과 집합에 반환되는 열을 제한하는 경우 주석을 평가하는 방법이 약간 다릅니다. 원본의 각 결과에 대해 주석이 달린 결과를 반환하는 대신 원본 결과는 절 QuerySet에 지정된 필드의 고유한 조합에 따라 그룹화됩니다.
위와 같이 코드를 변경하면 성공적으로 <table>이 로우에 추가된 것을 확인할 수 있다.
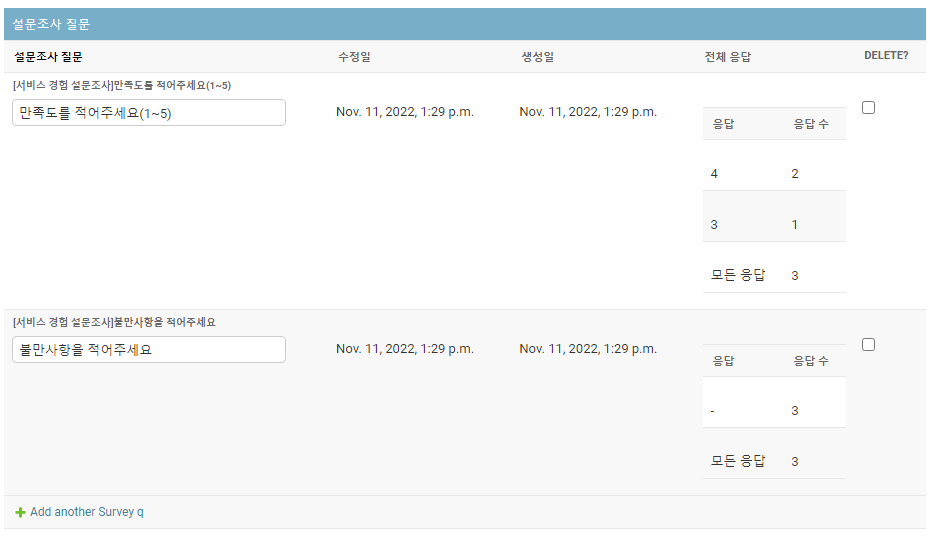
3. 판다스로 <table> 추가하기
판다스를 사용하면 동일한 과정을 더 쉽게 수행할 수 있다.
import pandas as pd
class SurveyQInline(admin.TabularInline):
model = SurveyQ
fields = ( 'surv_q_content', 'updated_at', 'created_at', 'tableRow','tablePandasRow')
readonly_fields = ('created_at', 'updated_at', 'tableRow','tablePandasRow')
extra = 0
...
@admin.display(description="전체 응답2")
def tablePandasRow(self, obj):
if(obj.id is None):
return '-'
try:
targetColumns = ["응답", "응답 수"]
conn = sqlite3.connect('db.sqlite3')
SQL_Query = pd.read_sql_query(f"""
SELECT surv_a_content as "{targetColumns[0]}", count(surv_a_content) as "{targetColumns[1]}"
FROM survey_a
where surv_q_id={obj.id}
group by surv_a_content
order by "{targetColumns[1]}" DESC;
""", conn )
df = pd.DataFrame(SQL_Query)
df.loc[-1] = ['모든 응답', obj.survQ_survA.count()]
return mark_safe("<div style='max-width:300px; max-height: 300px; overflow: auto;'> " +
df.style.bar(
subset=[targetColumns[1]], color='#79aec8').hide(axis="index").to_html()
+ "</div>"
)
except Exception as e:
print(e)
대충봐도 코드가 더 간결해진 모습을 확인할 수 있다.
pandas는 데이터베이스에서 바로 값을 읽어서 df 로 만들어 줄 수 있는데, orm 쓰는것보다 sql치는게 더 편한 입장에서는 이쪽이 훨씬 쉽다.
위부터 순서대로 어떻게 진행된 것인지 살펴보자.
conn = sqlite3.connect('db.sqlite3')
먼저 데이터베이스와 커넥션을 만들어 준다.
SQL_Query = pd.read_sql_query(..., conn)
그리고pd.read_sql_query의 첫번째 인자로는 쿼리문을, 두번째 인자로는 바로 위에서 만든 커넥션을 준다.
(SQLAlchemyconnectable,str(?),sqlite3 connection이 지원된다. 상세 내역은 공식문서를 확인)
df = pd.DataFrame(SQL_Query)
그 후에pd.DataFrame에 인자로pd.read_sql_query의 결과를 넘겨주면 SQL문 실행 결과로 dataframe을 만들어준다.
df.loc[-1] = ['모든 응답', obj.survQ_survA.count()]
이렇게 생성된 항목은surv_a_content로 group_by 한 count 만 가지고 있으므로 '모든 응답' 부분을 위해 전체 합을 별도로 추가한다.mysql에서는 `GROUPING SETS` 가 있어서 sqlite에서도 비슷한 기능이 있나 찾아봤는데 없는 것 같다...
df.style.bar(subset=[targetColumns[1]], color='#79aec8').hide(axis="index").to_html()
시각화를 추가한다. dataframe에 style을 지정해 데이터 시각화를 할 수 있는데, 이번에는 개수에 따라 바 길이를 다르게 보여줄 것이다.
df.style.bar()에 subset 옵션으로 바 형식을 나타낼 컬럼을 지정하고, color 옵션으로 바의 색상을 지정한다.
그리고hide(axis="index")로 기본으로 나타나는 맨 앞쪽 index 컬럼을 보여주지 않겠다고 설정 한다.
to_html()으로 결과를 html로 변경한다.
(자세한 내용은 공식문서 참조)
여기에 답변이 지정되지 않으면 스크롤이 엄청나게 길어질 수 있으므로to_html()결과를<div style='max-width:300px; max-height: 300px; overflow: auto;'>로 감싼다. 이렇게하면 세로 길이가 제한되고 세로 길이를 넘어설 경우 스크롤바가 나타난다.
이렇게 하면 더 간단한 코드로 데이터 시각화까지 완료된 <table>을 얻을 수 있다.
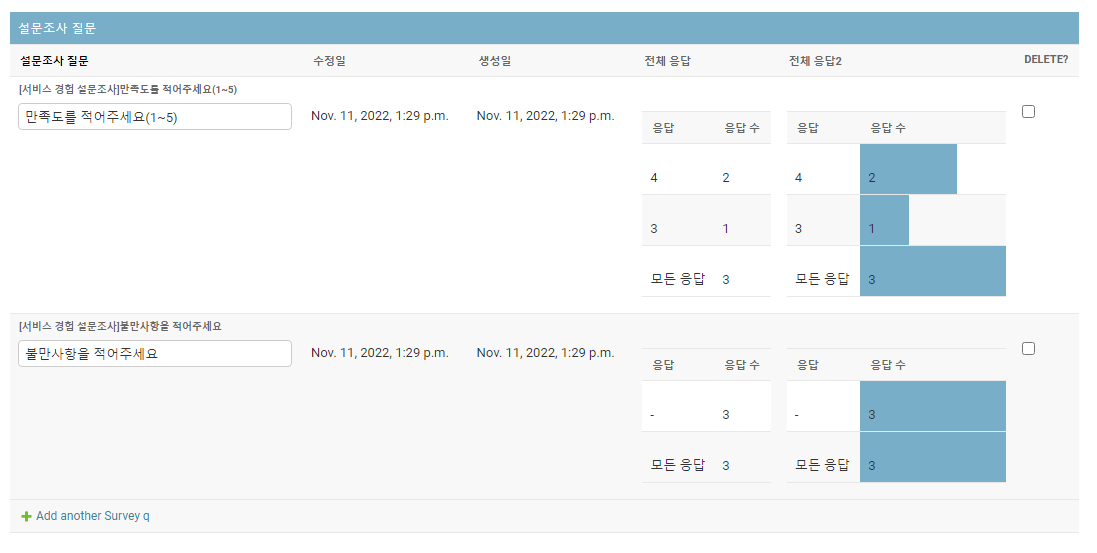
상세 코드는 다음을 참고:
https://github.com/hokim2407/django-admin_study/tree/5e6365b0e87eb5c0be77a63153bd8afb061b0007
파이콘 2022에 갔을때 알쓸파잡에 붙였는데, 어떤분께서 친절하게 DataTable이 속도가 더 빠르다는것을 알려주셨다...! 이번에 django admin을 정리하면서 DataTable도 써보려고 했는데, DataTable은 아쉽게도 html 변환에 대한 설명이 없었다... .
당장 적용하기는 어려워서 쓰지 못했지만 나중에 언젠가 꼭 써보고 싶다.