JS의 데이터타입
JS의 데이터타입 종류
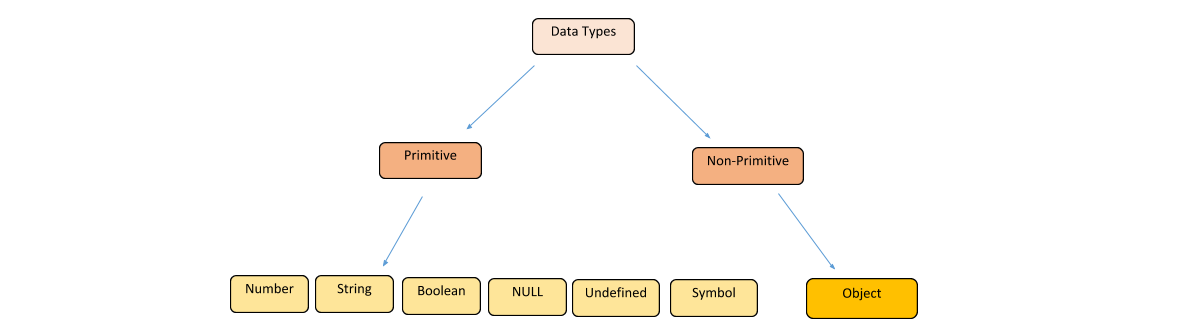
JS의 데이터 타입은 크게 두 종류가 있다.
- 기본형(Primivitive type) aka 원시형
- 참조형(Reference type)
기본형은 숫자(number), 문자열(string), 불린(boolean), null, undefined, Symbol(ES6에서 추가)이 있고, 참조형은 객체(Object)가 있는데 배열, 함수, 날짜, 정규표현식과 ES6에서 추가된 Map, Set 같은 것들은 객체의 하위 분류에 속한다.
기본형 vs 참조형
우리는 일반적으로 기본형과 참조형의 차이는 연산이나, 할당시 복제가 되고, 참조형은 참조가 된다.
/* 원시타입 */
let a = 100 // a라는 변수에 원시형 데이터 할당
let b = a // 그 값을 b라는 변수에 복제
a = 1 // a값 변경
console.log(b) // 100이 나온다(b가 변경되지 않음)
/* 참조타입 */
let a = {count: 100} // a라는 변수에 참조형 데이터 할당
let b = a // 그 값을 b에 복제
a.count = 1 //참조타입 데이터 변경
console.log(b.count) // 1이 나옴(a,b는 동일한 참조를 담고있고, 따라서 동일한 객체를 가르킨다)메모리란?
컴퓨터는 모든 데이터를 0 또는 1로 바꿔서 기억한다. 이때 0 혹은 1로 표현되는 메모리 조각을 비트(bit 혹은 Filpflop) 라고 부른다.
각각의 비트들은 고유한 식별자(unique identifier) 를 가지게 되는데, 이 식별자를 통해 비트의 위치를 확인할 수 있다. 이를 메모리 주솟값(memory address) 이라고 부른다.
그런데, 비트 하나하나 단위로 위치를 확인하고 연산을 수행하면 몇백 몇천번, 그 이상을 확인해야 할 수도 있고, 굉장히 비효율적이고 검색 시간도 오래 걸린다.
그래서 비트를 한 단위로 묶어야 할 필요성이 생겼는데, 그렇다고 엄청나게 많은 비트를 한번에 묶으면 속도는 빠르겠지만 사용하지 않는 비트들까지 한번에 묶여있기 때문에 낭비되는 비트가 생긴다.
그래서 나온 단위가 바로 바이트! (Byte) 8개의 비트를 하나의 바이트로 묶었으며, 가장 앞에 존재하는 비트의 식별자... 즉, 메모리 주솟값을 통해 바이트의 위치를 파악하여 더 빠르고 효율적으로 계산할 수 있다
JS의 메모리
JS는 비교적 최근에 만들어진 언어여서 과거 부족했던 메모리에서 최적의 효율을 낼 수 있게 데이터 타입을 쪼개놓은 것보다 여유로운 메모리 할당을 갖는다. 따라서 다른 언어(C, 자바)와는 다르게 정수형, 실수형이 따로 나뉘지 않고, 문자형도 string타입 하나만 있는등 형변환을 걱정해야하는 상황이 덜하다. 메모리를 비트가 모인 바이트의 집합인데, 각 비트와 바이트는 자기만의 메모리 주솟값을 갖고 있고, 이 것을 통해서 구분하고 연결을 할 수 있다.
식별자와 변수
1. 변수 선언
let a = 10;위의 코드를 풀어 쓰면, 변할 수 있는 데이터를 만든다. 그 데이터의 식별자는 a라고 한다. 라고 얘기 할 수 있다. 즉 변수란 변경 가능한 데이터가 담을 수 있는 공간 이라고 생각하면 된다.
이 변수가 선언이 되면, 컴퓨터는 메모리에서 비어있는 공간을 하나 확보를 하고, 이 공간의 이름을 식별자(여기선 a)라고 지정한다. 그리고 유저가 a에 접근하고 싶다면, a라는 식별자를 찾아 그 곳에 담긴 값을 반환한다.
2. 데이터 할당
let a; // a라는 식별자 생성
a = 10; //그 식별자에 10이라는 데이터를 할당
let a = 10 // 위에것을 한 줄로 표현하면..위의 코드도 앞에서 본 것과 같이, '변할 수 있는 데이터를 만들고, 그 데이터에게 a라는 식별자를 선언을 한 다음, a라는 식별자가 있는 메모리를 찾은 후, 그 곳에 10이라는 값을 할당한다'라고 볼 수 있겠지만 사실은 그게 아니다. 할당되는 데이터가 있다면 그 데이터를 바로 직접 저장하는 것이 아니라, 데이터를 저장하기 위한 메모리를 확보를 하고 그 곳에 10을 저장한 다음 그 곳의 주소값을 변수영역에 저장하는 절차로 이루어진다.
왜 이렇게 번거로울까?
그 이유는 메모리효율성을 높이기 위해 그런것이다. 예를들어 문자열같은 데이터타입은 그 문자가 영어인지(1바이트), 한글(2바이트)인지 또는 문자열의 길이에 따라 메모리를 가변적으로 사용해야하기 때문.
중간에 있는 데이터를 수정해야한다면?
새로 데이터 공간을 만든다.예를들어 'abc'라는 글자뒤에 'def'라는 문자를 더 붙인다고 하면, 'abc'가 있는 데이터 영역에서 그 곳을 늘리는게 아니라, 'abcdef'의 데이터 공간을 새로 만드는 것이다.
변수영역과 데이터영역을 나눠놓으면 중복 데이터에 대한 처리가 좋아진다. 예를들어 500개의 식별자에 5라는 데이터를 할당하고 싶은데, 만일 그 식별자들이 있는 공간에 직접 5가 들어간다고하면, 숫자형은 기본 8바이트 이기때문에, 500 8 4000바이트가 필요하지만, 이것을 분리하고 주소값을 넣고 있으면, (5002(식별자 이름, 데이터 주소)+8) 이런게 1008바이트만 쓸 수 있어서 큰 효율을 취할 수 있당
불변값
앞에서 얘기했던 변수영역과 데이터 영역을 다시 한 번 생각해보자.
let a = 'abc'
a = a + 'def'
let b = 5 //데이터 영역에 5라는 데이터가 없으므로 새로운 데이터 영역이 생성이 되고, b변수에 갖는 그 데이터 5할당
let c = 5 // 데이터 영역에 5라는 곳이 있기 때문에 그 주소를 c에 할당.
c = 7 // 새로운 데이터 영역이 생기고 c는 그걸 가르킴(5는 없어지지 않음)데이터의 변화가 있을때, 해당 데이터에 수정이 일어나는게 아니라, 새로운 수정된 데이터 영역을 새로 만든다.
따라서 기존 데이터가 사라지지 않기 때문에 불변성이 유지가 되는 것이다. 모든 원시형 데이터는 가비지 컬렉팅이 일어나지 않는 이상 불변성을 이런식으로 유지한다.
가변값
let obj = {
a:1,
b:'bbb'
}obj변수생성 -> 데이터 영역에 값을 넣으려고 했으나, 값이 여러개 있는 데이터임을 확인후 별도의 변수 영역을 마련하고 그 영역의 주소(여러개)를 obj변수에 저장 -> 각 프로퍼티의 이름을 별도로 만든 변수 영역에 지정 -> 값을 저장하는데 현재 데이터 영역에 1이라는 값이 없으므로 임의의 공간에 저장을 하고 그 공간의 주소를 별도 변수영역에 있는 이름이 a라는 공간에 그 주소 저장. 반복..
기본형과의 차이는 객체의 프로퍼티 영역이 존재를 한다는 것.그러나 앞에서도 얘기했지만 데이터 영역에 저장된 값은 전부 불변성을 띈다. 그러나 변수영역은 그러지 않기때문에 여기서 변하지 않다고 하는 것이다.
let obj = {
a:1,
b:'bbb'
}
obj.a = 10참조형의 재 할당은 객체를 위한 변수 영역에서 해당 이름(현재는 a)을 찾고, 그 곳이 가르키는 데이터의 주소를 확인 한 다음 다르다면 새로운 데이터 영역을 확보 후 그 값을 채워놓고 바뀐 데이터영역의 주소로 업데이트를 한다. 따라서 새로운 객체가 생성된 것이 아닌 기존 객체의 주소가 바뀐것이다.(기본형 재할당이랑 비교하기)
let obj = {
a:1,
b:[1,2,3]
}
obj.a = 10데이터 영역에 데이터를 추가할 때 먼저 그 데이터가 있는지 검사를 한다!!
참조형이 두 번 나올때..!!
마찬가지로 obj라는 이름으로 변수 영역에 공간을 만들고, 프로퍼티가 여러개 있는 값이니 그 객체를 저장하는 변수 영역을 다시 확보를 한다. 그 변수 영역의 이름은 데이터 영역에 저장이 된다.
참조 vs 기본의 차이는
주소를 참조하는냐가 아니라 주소를 복사하는 과정이 한 번 더 거치는지의 차이다
다시 말하자면
기본형의 값 복사는 본래 갖고 있던 데이터의 주솟값만 복제를 하기 때문에 불변성이 유지가 되는 것이고,
참조형의 값 복사는 본래 갖고 있던 데이터의 주솟값을 동일하게 갖고 있기 때문에, 복사를 한 값에서 변화를 주면 원래 갖고 있는 값도 영향을 받기 때문이다!!
불변성
불변성은 최근 React, Vue, Agnular등의 라이브러리뿐만 아니라, 디자인 패턴, 함수형 프로그래밍등에서 아주 주요한 개념으로 여긴다.
불변성은 한 객체의 내부 프로퍼티가 바뀔때 원본 객체는 바뀌지 않고 새로운 객체를 만들거나, 만들기로 해서 확보가 가능하다. 그럼 어떻게 해야할까??
let user = {
name: '감자',
gender: 'male'
}
let changeName = function(user, newName){
let newUser = user
newUser.name = newName
};
let user2 = changeName(user, '배추')
if(user !==user2){
console.log('유저정보가 변경되었습니다!')} //안나옴
console.log(user.name, user2.name) //배추 배추
console.log(user === user2) //true위의 코드는 앞에서 본 것과 같이 user2와 user1에 할당된 객체의 주소값이 같으므로 user2.name이 업데이트 되니까 user.name을 찍었을때 바뀐 값이 출력이 된다.
따라서,
let user = {
name: '감자',
gender: 'male'
}
let changeName = function(user, newName){
return{
name: newName,
gender: user.gender
};
let user2 = changeName(user, '배추')
if(user !==user2){
console.log('유저정보가 변경되었습니다!')} //유저정보가 변경되었습니다!
console.log(user.name, user2.name) //감자 배추
console.log(user === user2) //false이렇게 바로 chageName함수에서 새로운 객체를 반환을 하게되면 해결을 할 수 있다. 그러나 이것도 문제가 있는것이 gender를 하드코딩 했기 때문이다. 현재 예시에선 하나만 있어서 그렇지 여러개 있으면 그것들을 다 하나하나 하드코딩을 해야하므로 비효율적이다. 그때 for in문법을 사용하면 된다!
let copyObj = function(target){
let result = {}
for(let prop in target){
result[prop] = target[prop]
}
return result
}
let user = {
name: '감자',
gender: 'male'
}
let user2 = copyObj(user)
user.name = '배추'
if(user !==user2){
console.log('유저정보가 변경되었습니다!')} //유저정보가 변경되었습니다!
console.log(user.name, user2.name) //감자 배추
console.log(user === user2) //false이렇게 copyObj함수를 만들어서 간단하게 객체를 복사하고, 수정 할 수 있다. 그러나 immer.js, baobab.js같은 휼륭한 라이브러리가 있으니 그것을 사용하자
얕은 복사 vs 깊은 복사
얕은 복사는 바로 아래단계의 값만 복사하는 값이고, 깊은 복사는 내부의 모든 값들을 하나하나 찾아 전부 복사하는 방법니다. 즉 얕은복사는 참조데이터의 참조변수들의 메모리 주소까지만 복사를 하기때문에 복사한 데이터의 참조값을 바꿔도 원본 데이터가 바뀐다(기존 데이터를 그대로 참조하니까).
let deepCopyObj = function (target) {
let result = {};
if (typeof target === "object" && target !== null) {
//target !== null를 넣어준 이유는, typeof 명령어가 null에 대해서도 object를 반환하는 버그가 있기 때문이다.
for (let prop in target) {
result[prop] = deepCopyObj(target[prop]);
}
} else {
result = target;
}
return result;
};
let obj = {
a:1,
b:{
c:null,
d:[1,2]
}
}
let obj2 = deepCopyObj(obj)
obj2.a = 3;
obj.b.c = 4;
obj.b.d[1] = 3
console.log(obj)
/*{
a:1,
b:{
c:null,
d:[1,3]
}
}*/
console.log(obj2)
/*
{
a:3,
b:{
c:4,
d:[1,2]
}
}
*/깊은복사는 이렇게 재귀적인 로직을 통해 내부 프로퍼티들을 순회하여 target을 그대로 지정하게끔 했다.
obj와 obj2는 아예 다른 주소값을 갖는 객체들이다.따라서 저 둘은 서로 영향을 주지 않는다.
다른 방식으로는 JSON.stringfy()로 문자열로 바꾼 다음 다시 JSON화를시켜주어도 된다. 다만 prototype나 getter/setter와 같은 경우 적용이 되질 않는다.
null vs undefined
JS에선 없음을 의미하는 값이 두가지가 있는데 그게 바로 null과 undifiend이다. 저 둘은 어떤 차이가 있을까
undefined
undefined은 유저가 명시적으로 지정할 수도 있으나, 값이 존재하지 않을때 JS엔진이 자동을 부여하는 경우가 있다.
- 값을 대입하지 않은 변수, 즉 데이터 영역의 메모리 주소를 지정하지 않는 식별자에 접근할 때
let a;
console.log(a) //undefined- 객체 내부의 존재하지 않는 프로퍼티에 접근하려고 할 때
let obj={a:'1'}
console.log(obj.b) //undefined- return문이 없거나 호출되지 않는 함수의 실행결과
let func = function(){}
console.log(func()) //undefined return값이 없으면 undefined를 반환한 것으로 간주함그러나 첫번째 경우 데이터가 배열일 때 조금 독특한 동작이 있다.
let arr1 = [];
arr1.length = 3
console.log(arr1) //[empty x 3]
let arr2 = new Array(3)
console.log(arr2) //[empty x 3]
let arr3 = [undefined, undefined, undefined]
console.log(arr3) //[undefined, undefined, undefined]첫번째, 두번째 예를 보면,3개의 빈 요소를 확보했지만 문자 그대로 어떤 값도, undefined값 조차도 할당되어 있지 않다. 이는 비어있는 요소와 undefined를 할당한 요소가 다르다는 것을 의미한다. 그래서 출력 결과도 당연히다르다.
let arr1 = [undefined, 1]
let arr2 = []
arr2[1] = 1;
arr1.forEach((v,i) => console.log(v,i))
//undefined 0 / 1 1
arr2.forEach((v,i) => console.log(v,i))
//1 1
arr1.map((v,i) => v+i)
//[Nan, 2]
arr2.map((v,i) => v+i)
//[empty, 2]
arr1.filter((v)=> !v)
//[undefined]
arr2.filter((v)=> !v)
//[]
arr1.reduce((p,c,i)=>p+c+i,'')
//undefined011
arr2.reduce((p,c,i)=>p+c+i,'')
//11
보다시피 arr2에서 각 메소드들이 비어있는 요소에서는 어떠한 처리도 하지 않았음을 알 수 있다.
이 이유는 배열도 객체라는 것을 생각해보면 당연한 것이다.
null
null은 비어있음을 명시적으로 나타내고 싶을때 사용하는 것이다. 그러나 typeof null이 object라고 나오는 버그가 있으니null여부는 다른식으로 접근해야하는데
let isNull = null
console.log(isNull === null) //true바로 일치 연산자를 확인해보면 된다!!!
