쿠버네티스에는 파드가 정상인지를 판단하기 위한 헬스체크 기능이 있다.
파드 내부 컨테이너에서 실행 중인 프로세스가 동작하고 있는지에 대한 헬스 체크는 쿠버네티스가 표준으로 하고 있으며, 이상 종료된 경우 파드에 설정된 spec.restartPolicy에 따라 파드를 재시작한다.
이외에도 상세한 조건으로 헬스체크를 할 수 있다.
헬스체크는 컨테이너별로 이루어지며, 어느 하나의 컨테이너라도 실패하면 전체 파드가 실패한 것으로 간주한다.
1. Liveness Probe
- 파드 내부의 컨테이너가 정상적으로 동작 중인지 확인하기 위한 헬스체크.
- 실패 시 컨테이너 재기동 (Restart)
- Readiness Probe와는 달리 헬스 체크에 한번 실패하면 재시작 없이는 복구가 어려운 컨테이너에 사용한다.
- ex) 프로세스에 버그 등이 있을 경우 장기간 실행하고 있으면 memory leak 등에 의해 응답하지 않게 되는 경우
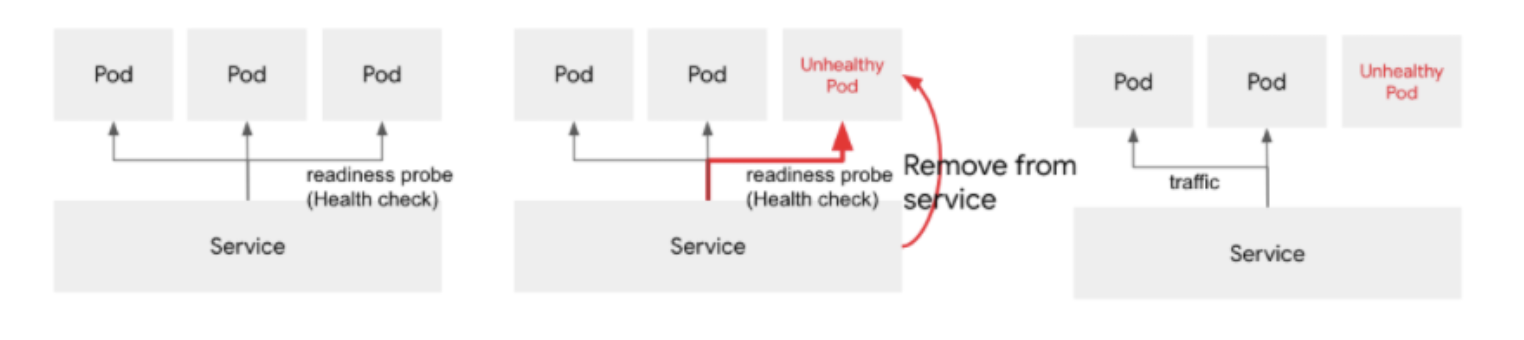
2. Readiness Probe
- 파드가 요청을 받아들일 수 있는지 확인하기 위한 헬스체크.
- 실패 시 트래픽 차단 (파드를 재기동하지 않음)
- ex) 백엔드 DB에 정상적으로 접속 되는지, 캐시에 로드가 끝났는지, 기동 시간이 오래 걸리는 프로세스가 기동을 완료했는지 등을 체크
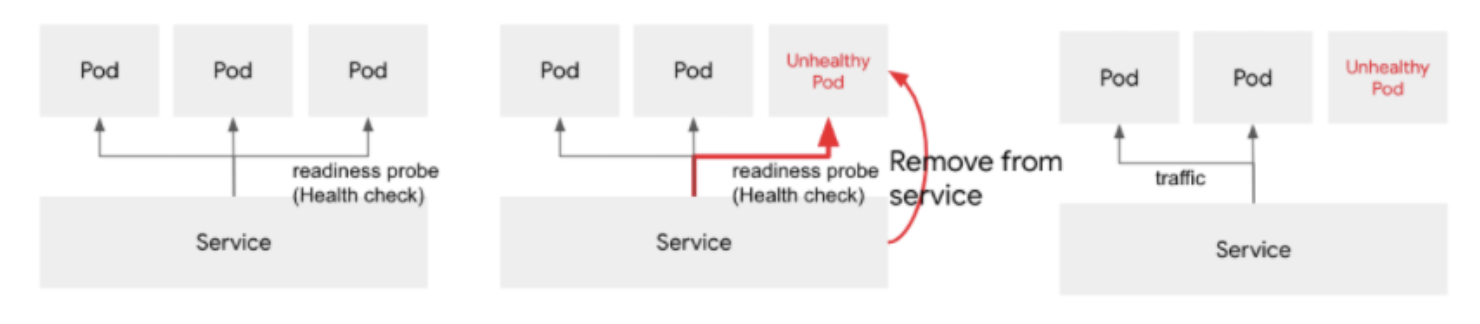
3. Startup Probe
- 파드의 첫 번째 기동이 완료되었는지 확인한다.
- 실패 시, 다른 Probe 실행을 시작하지 않는다.
- 처음 기동하는데 시간이 걸리는 경우, Liveness Probe를 사용하려면, 첫 번째 체크 시작 시간을 연장하거나 실패라고 판단할 때까지 시간을 연장하여 사용해왔다.
예를 들어, 첫 번째 체크 시작 시간을 60초 후 등으로 설정하면, 최초 기동이 바로 끝나는 경우 60초칸 체크가 없는 상태가 되거나 처음 기동에 60초 이상이 걸리는 경우에는 체크에 실패하게 된다. 후자의 경우에는 몇 번이든 재기동을 반복하므로, 결국 Liveness Probe 때문에 파드가 전혀 기동하지 않는 경우가 있다.
또 실패라고 판단할 때까지 시간을 연장하여 위의 문제는 발생하지 않지만, 그 결과 장애 발생 시 헬스체크가 바로 실패라고 판단해주지 않는 문제도 발생하게 된다. 따라서 등장한 것이 Startup Probe 이다.
세가지 헬스체크 방식
1. 명령어 기반의 체크 (exec)
- 명령어를 실행하고 종료 코드가 0이 아니면 실패
- 세 가지 방식 중 가장 유연성이 높은 체크 가능
- 명령어는 컨테이너별로 실행되어, 명령어에서 사용하는 파일 등도 컨테이너별로 필요하다.
- ex)
livenessProbe:
exec:
command: ["test", "-e", "/ok.txt"]2. HTTP 기반의 체크 (httpGet)
- HTTP GET 요청을 실행하고 Status Code가 200~399가 아니면 실패
- path, scheme(http, https), host, httpHeaders 등과 같은 세부 설정이 가능
- HTTP GET 요청은 kubelet에서 이루어지므로, 컨테이너에는 kubelet이 가진 파드용 네트워크 인터페이스 IP 주소로 HTTP GET 요청이 오게 된다. 컨테이너 내부의 애플리케이션 측에서 소스 IP 주소를 제한하는 경우에는 주의해야 한다.
- ex)
livenessProbe:
httpGet:
path: /health
port: 80
scheme: HTTP
host: web.example.com
httpHeaders:
- name: Authorization
value: Bearer TOKEN3. TPC 기반의 체크 (tcpSocket)
- TCP 세션이 연결되지 않으면 실패한다.
- ex)
livenessProbe:
tcpSocket:
port: 80
- gRPC 헬스체크
gRPC를 사용한 애플리케이션에서 헬스 체크를 하는 경우 httpGet으로 체크하기 위해 별도 HTTP 엔드포인트를 준비하거나 tcpSocket으로 포트 활성화만 체크할 수도 있는데, 이러한 방법은 헬스 체크의 정확도가 낮다.
해결 방법은 다음과 같다.
gRPC에는 원래 gRPC Health Checking Protocol 을 사용한 헬스 체크 기능이 있으며, grpc_health_probe를 사용하면 엔드포인트에 대한 헬스 체크를 할 수 있다.
exec.command 에서 실행하기 위해 사전에 컨테이너 이미지에 grpc_health_probe 바이너리를 추가해 두어야 한다.
예)
livenessProbe:
exec:
command: ["/bin/grpc_health_probe", "-addr=:5000"]
헬스 체크 간격
| 설정 항목 | 내용 | 기본 값 |
|---|---|---|
| initialDelaySeconds | 첫 번째 헬스 체크 시작까지의 지연(최대 failureThreshold 만큼 연장) | 0 |
| periodSeconds | 헬스 체크 간격 시간(초) | 10 |
| timeoutSeconds | 타임아웃까지의 시간(초) | 1 |
| successThreshold | 성공이라고 판단하기까지의 체크 횟수 | 1 |
| failureThreshold | 실패라고 판단하기까지의 체크 횟수 | 3 |
livenessProbe:
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 1Liveness Probe, Readiness Probe, Startup Probe 모두 위 나타난 다섯가지 헬스 체크 간격에 대해 파라미터 설정이 가능하다.
- Liveness Porbe 에서는 실패했을 때 파드가 재시작하기 때문에, 실패라고 판단하기까지의 체크 횟수(failureThreshold)를 환경에 맞게 설정하도록 한다.
- successThreshold는 1 이상이어야 하며, Liveness Probe와 Startup Probe의 경우 반드시 1이어야 한다.
- 첫 번째 체크까지 지연 (initialDelaySeconds)은 가급적 사용하지 말고 대신 Startup Probe를 병용해서 사용하자.
헬스 체크 생성
헬스 체크 방법 3가지와, 헬스 체크 방식 3가지로 총 9가지 패턴의 헬스 체크를 생성할 수 있다.
아래 예제에서는 Liveness Probe로 http://localhost:80/index.html 에 HTTP GET 요청을 체크하고, Readiness Probe로 /usr/share/nginx/html/50x.html 파일이 있는지 확인한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-healthcheck
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
# command: ["/bin/bash", "-c", "--"]
# args: ["while true; do sleep 30; done;"]
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /index.html
port: 80
scheme: HTTP
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 2
initialDelaySeconds: 5
periodSeconds: 3
readinessProbe:
exec:
command: ["ls", "/usr/share/nginx/html/50x.html"]
timeoutSeconds: 1
successThreshold: 2
failureThreshold: 1
initialDelaySeconds: 5
periodSeconds: 3설정은 kubectl describe 등에서 확인할 수 있디.
# pod 에 설정된 probe 확인
$ k describe pod nginx-healthcheck | egrep -E "Liveness|Readiness"
Liveness: http-get http://:80/index.html delay=5s timeout=1s period=3s #success=1 #failure=2
Readiness: exec [ls /usr/share/nginx/html/50x.html] delay=5s timeout=1s period=3s #success=2 #failure=1Liveness Probe 실패
- 실제로 Liveness Probe 체크를 실패시켜 보자.
- 다음 예제에서는 index.html 을 삭제하고 hTTP Status Code가 404르 ㄹ반환하도록 하여 동작을 확인한다.
# index.html 삭제
$ k exec -it nginx-healthcheck -- rm -f /usr/share/nginx/html/index.html
# --watch 옵션을 사용하여 파드 상태 변화를 확인
$ k get pods nginx-healthcheck --watch
NAME READY STATUS RESTARTS AGE
nginx-healthcheck 1/1 Running 0 37s
nginx-healthcheck 0/1 Running 1 71s
nginx-healthcheck 1/1 Running 1 77sLiveness Probe가 실패한 경우 파드의 restartPolicy(기본값 Always)에 따라 컨테이너를 재시작한다.
그래서 Restart 카운트가 증가하는 것을 확인할 수 있다.
Readiness Probe 실패
이번에는 Readiness Probe를 실패시켜 보자. 다음 예제에서는 /usr/share/nginx/html/50x.html 파일이 있는지 명령어 기반으로 체크하고 있다.
체크가 실패하도록 해당 파일을 삭제하고 다시 생성하여 동작을 확인한다.
# 50x.html 삭제
$ k exec -it nginx-healthcheck -- rm -f /usr/share/nginx/html/50x.html
# 확인
$ k get pods nginx-healthcheck--watch
NAME READY STATUS RESTARTS AGE
nginx-healthcheck 1/1 Running 0 21s
nginx-healthcheck 0/1 Running 0 42sReadiness Probe가 실패한 경우 READY 상태가 아니므로, 서비스에서 트래픽 전송을 차단한다.
또한, Liveness Probe와는 달리 컨테이너가 재시작되지 않는다.

안녕하세요 : )
정리해 주신 글 잘 읽었습니다.
1. Liveness Probe랑 2. Readiness Probe 동작 설명하는 사진이 둘 다 Readiness네요
수고하세요~!