페이지 폴트가 발생하면 운영체제는 새로 진입할 페이지를 위한 공간을 만들기 위해 이미 존재하고 있는 페이지 중에 하나를 내보내야(메모리에서 제거해야)한다.
만일 내보낼 페이지가 변경되어 있다면(dirty 상태 라면) 그 페이지의 내용은 디스크로 보내져 기록되어야 한다. 그래야면 디스크에 있는 쉐도우(shadow)페이지가 가장 최근의 데이터를 유지할 수 있기 때문이다.
반면, 페이지가 변경되지 않았다면(clean 하다면), 디스크에 기록 할 필요는 없다.
새로 읽혀진 페이지는 쫓겨난 페이지가 차지하고 있던 공간을 차지한다.
내보낼 페이지는 임의적(random)으로 선택할 수 있다. 하지만 임의적으로 선택하는 것 보다 자주 사용되지 않을 페이지를 선택하는 것이 시스템 성능에 도움이 된다.
페이지 교체 알고리즘의 목표
- 제거할 최적의 희생 페이지를 고르는데 있어서 fault rate 줄이기
- 제거할 최고의 페이지는 다시는 접근되지 않을것이다.
- '다시는'는 매우 오랜 시간이다.
어떤 페이지를 교체할까에 대한 문제가 페이지 교체 알고리즘이며, 이에 대해서 이론적으로 그리고 실험적으로 많은 연구가 진행되었다. 이제부터 몇 가지 중요한 알고리즘을 살펴보자.
이후 살펴볼 모든 페이지 교체 알고리즘에서 공통적으로 발생하는 문제가 하나 있다.
교체될 페이지를 선택할 때, 그 페이지가 폴트를 야기한 프로세스의 것이어야 하는가, 아니면 다른 프로세스의 것도 가능한가?
전자의 경우, 각 프로세스들마다 고정된 개수의 페이지를 유지하게 되며, 후자에는 그렇지 않다. 두가지 모두 가능하다.
1. 최적 페이지 교체 알고리즘(Optimal Algorithm, Belady's Algorithm)
이 알고리즘의 동작 원리는 다음과 같다.
페이지 폴트가 발생했을 때, 이미 메모리에 몇 개의 페이지들이 존재한다고 가정하자. 이 페이지들 중에 하나는 바로 다음 명령어에 의해 참조될 것이다. (그 명령어를 가지고 있는 페이지)
다른 페이지는 10,100 또는 1000 명령어 뒤에 참조될 것이다.각 페이지들 마다 몇개의 명령어 뒤에 처음으로 참조되는지 레이블을 달 수 있다.
최적의 페이지 교체 알고리즘은 가장 큰 레이블을 갖는 페이지를 교체한다.
만일 8백만 명령어 뒤에 참조되는 페이지와 6백만 명령어 뒤에 참조되는 페이지가 있다면, 앞에 있는 페이지를 교체하게 되며, 결국 교체에 따른 페이지 폴트의 발생을 가능한 많이 뒤로 미룰 수 있게 된다.
컴퓨터도 사람과 마찬가지로 반갑지 않은 이벤트의 발생은 가능한 뒤로 미루려고 노력한다.
즉, 미래에 가장 오랜 기간동안 사용되지 않을 페이지를 교체한다.
하지만 구현이 불가능하다.
페이지 폴트가 발생했을 때, 운영체제는 각 페이지들이 미래의 어느 시점에 참조될 지 알 수 없다.
이 알고리즘은 프로그램을 시뮬레이터에서 수행하고, 모든 페이지 참조를 수집한 이후에 구현 가능하다. 구체적으로 첫 번째 수행에서는 메모리 참조 정보를 모으고, 두 번째 수행에서는 수집한 정보를 기반으로 최적의 페이지 교체 알고리즘을 구현하는 것이다.
이러한 방법으로 최적의 알고리즘과 실제 구현 가능한 알고리즘과 성능 비교가 가능하다.
이 알고리즘은 다른 페이지 교체 알고리즘의 성능을 평가하는데 의미가 있으며, 실용적인 효과는 없다.
2. NRU(Not Recently Used) 페이지 교체 알고리즘
가상 메모리를 지원하는 대부분의 컴퓨터는 각 페이지마다 운영체제가 페이지 사용 정보를 수집할 수 있도록 하기 위한 2개의 상태 비트를 유지한다.
- R bit(referenced bit) : 페이지가 참조될 때마다 설정 (reae/written)
- M bit(modified bit) : 페이지가 수정될 때 마다 설정(written)
이 비트들은 모든 메모리 참조 때 마다 Update 되어야 하기 때문에, 설정은 하드웨어가 담당한다. 일단 1로 설정되면, 운영체제가 0으로 reset하기 전 까지는 1값을 유지한다.
만일 하드웨어가 이러한 비트들을 지원하지 않는다면, 이들은 다음과 같은 방법으로 시뮬레이션 될 수 있다. 프로세스가 실행을 시작하면 페이지 테이블의 모든 엔트리는 대응되는 페이지가 메모리에 없는 것으로 표시한다.
이에 따라 프로세스가 실행하면서 페이지를 참조하면 폴트가 발생한다.
그러면 운영체제는 자신이 관리하는 내부 자료구조에서 그 페이지에 해당하는 R비트를 설정하고, 페이지 테이블 엔트리가 해당 페이지를 READ ONLY 모드로 가리키도록 갱신한 후 명령 실행을 재개한다. 만일 이 페이지에 쓰기 요청이 발생하면 또 다른 페이지 폴트가 발생하며, 이때 운영체제가 m비트를 설정하게 된다. 그리고 페이지 접근 모드를 READ/WRITE로 변경한다.
R과 M비트는 간단한 페이지 교체 알고리즘을 만드는데 효과적으로 이용될 수 있다.
- 프로세스가 시작할 때 운영체제는 그 프로세스의 모든 페이지의 R과 M비트를 0으로 클리어 한다.
- 주기적으로(ex.클록 인터럽트가 발생할 때 마다), R비트를 클리어 한다.
- 최근에 참조된 페이지와 그렇지 않은 페이지를 구분하기 위하여 - 페이지 구분 (R,M 비트의 현재 값에 따라)
- Class 0 : not referenced, not modified- Class 1 : not referenced, modified
- Class 2 : reference, not modified
- Class 3 : referenced, modified
처음보면 클래스 1은 불가능해 보인다. 하지만 클래스 3 상태의 페이지가 클록 인터럽트에 의해 R 비트가 클리어 되면 그 페이지는 클래스 1 상태가 된다.
클록 인터럽트는 M비트를 클리어 시키지는 않는다. M비트는 페이지가 디스크에 재 기록되어야 하는지 여부를 나타내기 때문이다.
NRU알고리즘은 클래스 0,1,2,3 순서로 페이지를 교체한다.
만일 클래스 0 상태의 페이지가 여러 개 있다면, 그 중에 임의로 한 페이지를 선택하여 교체한다. 반면 만일 클래스 0 상태의 페이지가 없다면, 클래스 1 상태의 페이지 중에서 교체할 페이지를 선택하게 된다. 만일 클래스 1 상태의 페이지도 없다면, 클래스 2 그리고 클래스 3 순서로 교체할 페이지를 선택한다.
(NRU removes page at random from lowest numbered nonempty class)
이 알고리즘의 기본 아이디어는 가장 최근의 클록 틱 간격(보통 20ms)동안 참조되지 않은 변경된 페이지를 교체하는 것이, 집중적으로 참조되는 변경되지 않은 페이지를 교체하는 것 보다 좋다는 것이다.
이해하기 쉬우며, 비교적 효율적으로 구현할 수 있다. 또 좋은 성능을 제공한다는 장점이 있다.
3. FIFO(First-In First-Out) 알고리즘
FIFO는 명백하고 구현하기 간단하다.
운영체제는 현재 메모리에 존재하는 모든 페이지들을 리스트로 관리한다.
가장 최근에 메모리에 적재된 페이지는 리스트의 뒤(tail)로 가고, 가장 과거에 적재된 페이지는 리스트의 앞(head)에 존재하게 된다.
페이지 폴트가 발생하면 리스트 앞에 있는 페이지가 교체되고 새로운 페이지는 리스트의 가장 뒤에 적재된다.
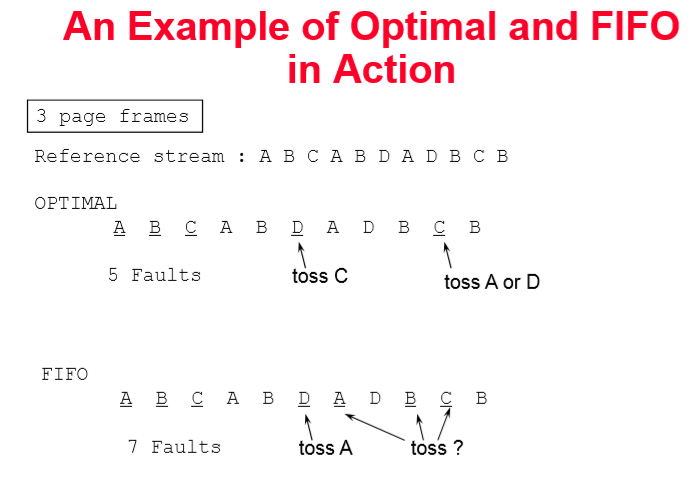
위의 사진처럼, fifo는 자주 참조되는 페이지를 교체할 가능성이 있다는 문제가 있다.

위와 같은 문제도 있다. 더 많은 프레임이, 페이지 폴트를 적게 발생시킬까?
이것은 Belady's anomaly 라고 부른다. (벨레이디의 모순)
원래 페이지 프레임이 늘어나면, 페이지 폴트의 개수가 감소해야 하는데 오히려 늘어나는 경우를 말한다.
4. Second-Chance 페이지 교체 알고리즘
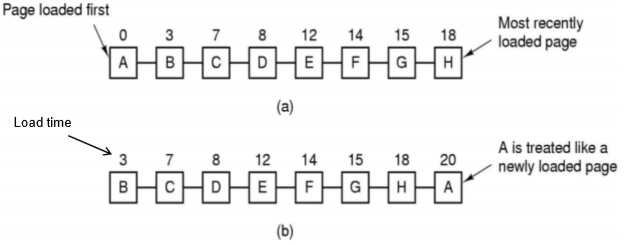
FIFO는 자주 참조되는 페이지를 교체할 가능성이 있다는 문제가 있다.
이 문제를 피하는 방법 중 하나는 가장 오래된 페이지의 R비트 를 이용하는 것이다.
만일 R이 0이면 이 페이지는 가장 오래된 페이지이며 동시에 최근에 사용되지 않는 페이지이다. 따라서 교체해도 된다. (M이 1이면 디스크에 쓰고 0이면 귿로 버리면 된다)
반면 R이 1이면 이 페이지를 리스트의 뒤로 옮기고, R비트를 0으로 클리어하며 적재 시간도 현재 시간으로 갱신한다.
마치 이 페이지가 방금 적재된 것처럼 한번 더 기회를 주는 것 이다.
그리고 이제 리스트 가장 앞에 있는 페이지의 R을 검사한다.
결국 second-chance 알고리즘이 교체하려는 페이지는 오래 되었으며, 동시에 가장 최근 클록 간격에 참조가 되지 않은 페이지이다.
만일 모든 페이지가 참조되었다면, second chance 알고리즘은 FIFO 알고리즘과 동일하게 동작한다.
예를 들어, 위 그림의 모든 페이지들의 R비트가 1이라고 가정해 보자. 운영체제는 페이지를 하나씩 리스트의 뒤로 이동시키며, R비트를 0으로 클리어 시킨다. 결국 A 페이지로 다시 돌아오게 되고 이때에는 R비트가 0으로 되어있다. 따라서 A가 교체되고 이 알고리즘은 종료된다.
5. Clock 페이지 교체 알고리즘
비록 second chance 알고리즘이 교체할 페이지를 적절하게 선택하지는 하지만 페이지를 리스트에서 이동시켜야 하기 때문에 동작의 효율성이 저하될 가능성이 있다.
더 효과적인 방법은 모든 페이지들을 밑의 그림처럼 클록 형태의 원형 리스트로 관리하는 것이다. 화살표는 가장 오래된 페이지를 가리킨다.
(second chance와 원리는 같은데 사용하는 구조체가 다름)
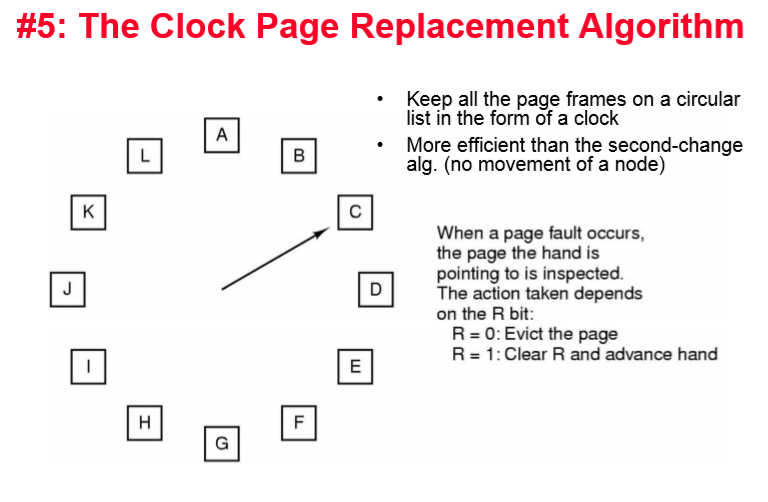
페이지 폴트가 발생하면 화살표가 가리키는 페이지를 조사한다.
- 만일 이 페이지의 R비트가 0이면?
- 이 페이지를 교체하고, 이 위치에 새로운 페이지를 삽입하고,- 화살표를 다음 페이지를 가리키도록 전진한다.
- 만일 이 페이지의 R비트가 1이면?
- 이 비트는 클리어되고,- 다음 페이지로 전진하여 그 다음 페이지를 조사한다.
- 이 과정을 R이 0인 페이지를 찾을 때 까지 반복한다.
이 알고리즘은 시계에서 시계바늘의 움직임을 연상시키기 때문에 클록(clock)알고리즘 이라고 불린다.
6. LRU(Least Recently Used) 페이지 교체 알고리즘
최적의 페이지 교체 알고리즘과 유사하게 동작하는 알고리즘은 다음과 같은 관찰을 기반으로 한다.
가장 최근의 명령어들에 의해 자주 접근된 페이지들은 가까운 미래에도 자주 접근될 확률이 높다.
역으로 오랫동안 참조되지 않은 페이지는 이후로도 사용되지 않을 확률이 높다.
이 관찰은, "페이지 폴트가 발생하면 가장 오랫동안 사용되지 않은 페이지를 교체하자"라는 알고리즘을 가능하게 한다. 이 알고리즘이 LRU이다.
LRU 알고리즘은 완벽하지만, 모든 메모리 참조를 기록하기 위한 timestamp가 필요하고 PTE안에 그것을 두어야 하는데 이것은 비용이 많이 든다.
- Possible Implementation
- 메모리 내에 있는 모든 페이지들이 리스트로 연결되어 있어야 함
- 가장 최근에 참조된 페이지는 리스트의 앞에
- 가장 과거에 참조된 페이지는 리스트의 뒤에 위치- 이때 어려운 것은 모든 메모리 참조마다 리스트를 갱신해야 함
- 리스트에서 페이지를 찾고, 삭제하고, 가장 앞으로 이동하는 작업은 시간이 많이 걸림
- 하드웨어 적으로 동작해도 부하가 크다
- 리스트에서 페이지를 찾고, 삭제하고, 가장 앞으로 이동하는 작업은 시간이 많이 걸림
- C라는 64비트 카운터(counter)를 이용해 구현 (하드웨어 지원)
- 카운터가 명령 실행 때 마다 1씩 증가
- 각 페이지 테이블 엔트리는 카운터 값을 저장할 수 있는 공간을 가짐
- 메모리가 참조될 때 마다 참조된 메모리를 담고 있는 페이지를 가리키는 페이지 테이블 엔트리에 C의 값이 저장됨
- 페이지 폴트 발생 시, 운영체제는 모든 페이지 테이블 엔트리의 카운터 값 조사하여 가장 적은 값을 갖는 페이지를 교체 (이 페이지가 LRU 페이지 이다)
- 카운터가 명령 실행 때 마다 1씩 증가
- n * n 비트로 구성된 행렬을 갖는 LRU 하드웨어 이용
- N개의 페이지 프레임 -> N*N 비트로 구성된 행렬
- 초기엔 행렬 모든 값 0
- 페이지 프레임 k가 참조되면 하드웨어는 행렬에서 k번째 행의 모든 비트를 1로 설정, 그리고 k번째 열의 모든 비트를0으로 설정
- 이 행렬에서, 행의 이진 값이 가장 작은 행에 대응되는 페이지 프레임이 가장 과거에 참조된 것이다. 그 다음 작은 값을 갖는 행에 대응되는 페이지 프레임이 두번째로 오래전에 참조된 것이다.
- N개의 페이지 프레임 -> N*N 비트로 구성된 행렬
- 이때 어려운 것은 모든 메모리 참조마다 리스트를 갱신해야 함

소프트웨어로 LRU 시뮬레이션
1) NFU(Not Frequently Used)
비록 지금까지 살펴본 두가지 하드웨어 지원(counter, matrix) LRU 구현은 가능하기는 하지만 실제로 이러한 하드웨어를 제공하는 시스템은 거의 없다.
그 대신 소프트웨어적인 방법들이 많이 연구되었다.
한가지 방법은 NFU(Not Frequently Used) 알고리즘이다.
- 각 페이지 마다 소프트웨어 카운터를 유지한다
- 이 카운터는 초기값을 0으로 갖는다
- 클록 인터럽트가 발생할 때 마다 운영체제는 메모리의 모든 페이지를 검사하여 R비트의 값을 소프트웨어 카운터에 더한다.
- 이 카운터는 각 페이지들이 얼마나 자주 참조되었는지 알려준다.
- 페이지 폴트가 발생하면 가장 적은 카운터 값을 갖는 페이지가 교체된다.
- 단점은 잊어버리는 기능이 없다
예를 들어, 다중 패스 컴파일러의 경우, 첫 번째 패스에서 자주 참조된 페이지들은 높은 카운터 값을 가지게 되고, 이 값은 두 번째 이후 패스에서도 유지 된다.
실제로, 만일 첫 번째 패스가 그 이후 다른 패스들보다 더 긴 실행 시간을 가진다면, 패스 1에서 실행된 페이지들은 그 이후 패스에서 사용되는 페이지들에 비해 더 큰 카운터 값을 갖게 된다.
그 결과 운영체제는 패스 1에서 사용되던 더 이상 사용되지 않는 페이지가 아닌, 현재 패스에서 사용하는 유용한 페이지들을 교체하게 된다.
2) Aging(에이징)
다행히도 NFU를 약간 변경하면 LRU와 비슷한 성능을 얻을 수 있다.
변경은 두 부분으로 구성된다.
- R비트를 더하기 전에 오른쪽으로 1비트 시프트한다.
- R비트는 오른쪽 비트가 아닌 왼쪽 최상위 비트에 추가된다.
- 페이지 폴트가 발생하면 카운터 값이 가장 적은 페이지가 교체된다.
4번의 클록 틱이 발생할 동안 참조되지 않은 페이지는 카운터 값의 상위 4비트가 0이 되며, 반면 세번의 클록 틱이 발생할 동안 참조되지 않은 페이지는 카운터 값의 상위 3 비트가 0이 된다. 따라서 전자의 페이지가 후자의 페이지 보다 더 적은 카운터 값을 갖게되며 결국 우선적으로 교체된다.

에이징 알고리즘은 LRU에 비해 두가지 차이가 있다.
위 그림(e) 에서 페이지 3,5를 고려해보자.
두 페이지 모두 최근 두 번의 클록 틱 간격에서 참조되지 않았다.
하지만 바로 그 이전 클록 틱 간격에서는 두 페이지 모두 참조되었다.
LRU 원칙에 따르면, 두 페이지 중에서 더 과거에 참조된 페이지가 먼저 교체되어야 한다.
문제는 이 두 페이지 중에서 어떤 페이지가 더 먼저 참조되었는지 모른다는 것이다.
이것은 클록 틱 간격 동안 오직 하나의 비트로 참조 여부만 기록하였기 때문에 발생하며, 결국 시간 순서를 구별할 수 있는 정보를 기록하지 않았기 때문에 발생한 것이다.
에이징 알고리즘은 페이지 3을 교체한다. 이는 페이지 5가 두 번의 클록 틱 전에 한번 더 참조되었고 페이지 3은 그렇지 않았기 때문이다. (반면, LRU는 페이지 3과 5의 마지막 참조 시간에 따라 페이지 5를 교체할 수도 있다)
두번째 차이는, 카운트 값이 제한된 비트로 구성 된다는 것이다.
이것은 과거에 대한 정보 기억을 제한한다.
예를 들어, 두 페이지의 카운터 값이 모두 0이라고 해보자.
에이징은 두 페이지 중 임의의 한 페이지를 교체한다.
이때 교체된 페이지가 9번째 클록 틱 전에 참조된 것이고 남겨둔 페이지가 1000번째 클록 틱 전에 참조된 것일 수도 있다.
하지만 실질적으로는, 만일 클록 틱이 20ms 간격으로 발생한다면 8개의 비트면 비교적 충분하다.
