최단 경로(shortest path) 문제
그래프에서 정점끼리의 최단 경로를 구하는 문제는 여러가지 방법이있다.
- 하나의 정점에서 다른 하나의 정점까지의 최단 경로를 구하는 문제 (single source and single destination shortest path problem)
- 하나의 정점에서 다른 모든 정점까지의 최단 경로를 구하는 문제 (single source shortest path problem)
- 하나의 목적지로 가는 모든 최단 경로를 구하는 문제 (single destination shortest path problem)
- 모든 최단 경로를 구하는 문제 (all pairs shortest path problem)
다익스트라 알고리즘
다익스트라 알고리즘은 여기서 두번째 방법으로, 하나의 정점에서 다른 모든 정점들의 최단 경로를 구한다. 간선들은 모두 양의 간선을 가져야한다.
다익스트라 알고리즘의 기본 로직은, 첫 정점을 기준으로 연결되어 있는 정점들을 추가해가며, 최단 거리를 갱신하는 것이다.
정점을 잇기 전 까지는 시작점을 제외한 정점들은 모두 무한대 값을 가진다.
정점A에서 정점B로 이어지면, 정점 B가 가지는 최단거리는 시작점부터 정점 A까지의 최단거리 + 정점 A와 정점B 간선의 가중치와, 기존에 가지고 있던 정점 B의 최단거리 중 작은 값이 B의 최단거리가 된다.
1. 다익스트라 알고리즘 기본 로직
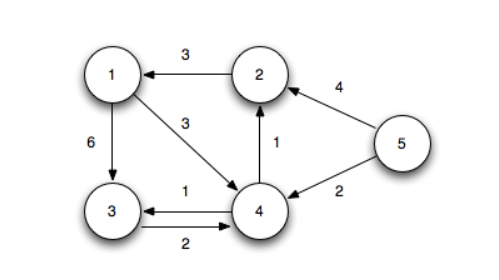
다음과 같은 그래프가 있다. 여기서 시작점은 5번 정점이라고 해보자.
여기서 5번 노드를 제외한 나머지 정점들이 가지는 최단 경로는 아직 연결되지 않았으므로 무한대이다.
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | INF | INF | INF | INF |
여기서 경로가 가장 짧은 정점을 고른다. 여기선 5번 노드이다. 5번 노드와 연결되어 있는 노드는 2,4 번 노드이다. 먼저 2번 노드부터 보자. 2번 노드의 최단 거리를 가지고 있는 현재 최단거리(INF)와, 5번 노드의 최단거리(0) + 2번-5번의 가중치(4) 값 중 가장 작은 값으로 갱신한다. 즉, dist[2] = min(dist[2], dist[5] + adj[5][2]) 을 구한다. 이는 min(INF,4)이므로 4가 된다.
4번 노드 또한 4번 노드의 최단거리를 가지고 있는 현재 최단거리(INF)와, 5번 노드의 최단거리(0) + 4번-5번의 가중치(2) 값 중 가장 작은 값으로 갱신한다.
즉, dist[4]= min(dist[4], dist[5] + adj[5][4])을 구한다. min(INF,2)이므로 2가 된다.
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | INF | INF | INF | INF |
| 2 | 4 |
이제 나머지 정점 중에서 경로가 가장 짧은 정점을 고른다. 가장 짧은 거리를 가지고 있는 노드는 2의 길이를 가지고 있는 4번 노드이다.
이제 4번 노드의 인접 노드는 2,3 번 노드이다.
2번 정점의 최단거리를 가지고 있는 현재 최단거리(4)와, 4번 정점의 최단거리(2)+2번-4-번의 가중치(1) 값 중 가장 작은 값으로 갱신한다.
즉, dist[2] = min(dist[2], dist[4]+adj[4][2])을 구한다.
2번 정점의 기존 최단 거리 dist[2]는 4고, dist[4]+adj[4][2]는 3이므로 3으로 갱신된다.
또한 3번 정점의 최단경로 dist[3]은 INF이므로, dist[4] + dist[4][3] = 3으로 갱신된다.
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | INF | INF | INF | INF |
| 2 | 4 | |||
| 3 | 3 |
위와 같은 방법을 반복한다. 3,2 번 정점의 최단 경로가 똑같으므로 숫자적으로 앞에 있는 2번 경로를 꺼내고, 인접 정점을 비교한다.
인접 정점은 1로 간선 가중치는 3이다. 따라서 dist[1] = min(dist[1], dist[2]+adj[2][1])을 구한다. dist[1]은 INF이므로, dist[2]+adj[2][1]인 6으로 갱신된다.
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | INF | INF | INF | INF |
| 2 | 4 | |||
| 3 | 3 | |||
| 6 |
최단 경로가 3인 정점 3을 꺼내고 인접 정점을 비교한다. 인접 정점은 4다. dist = min(dist[4], dist[3]+adj[3][4])를 계산한다.
dist[4]는 2이고, dist[3]+adj[3][4]는 5다. dist[4]가 더 작으므로 그대로 유지된다.
마지막으로 남은 정점은 1이다. 1을 꺼내고 인접 정점을 비교한다. 인접 정점은 3과 4다.
dist[4] = min(dist[4], dist[1]+adj[1][4])를 계산한다.
dist[4] 는 2이고, dist[1]+adj[1][4]는 9이다. dist[4]가 더 작으므로 그대로 유지된다.
dist[3] = min(dist[3], dist[1]+adj[1][3])을 계산한다.
dist[3]은 3이고, dist[1]+adj[1][3] 은 9이다. dist[4]가 더 작으므로 그대로 유지된다.
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | INF | INF | INF | INF |
| 2 | ||||
| 3 | 3 | |||
| 6 |
모든 정점을 방문했다. 완성한 테이블이 5번 정점부터 나머지 정점까지의 최단경로이다.
2. 우선순위 큐(힙구조)를 이용한 다익스트라 알고리즘
위 방법은 배열을 매번 탐색해서 가장 짧은 거리를 찾는 방법이다.
하지만 힙 구조를 이용하면 더욱 빠른 시간 내에 구현이 가능하다.
최소 힙을 사용하여 가장 작은 경로를 가진 정점지 나오도록 구현하면 되기 때문이다.
그래프를 한번 그려보자.
모든 정점들을 힙(우선순위 큐)에 넣는다.
Priority Queue
| i | d | p |
|---|---|---|
| 5 | 0 | / |
| 1 | INF | / |
| 2 | INF | / |
| 3 | INF | / |
| 4 | INF | / |
dist 배열
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | INF | INF | INF | INF |
위 표에서 i는 정점 인덱스, d는 최단거리이고 p는 이전 정점이다.
d를 기준으로 최소 힙을 구성한다.
힙에서 가장 위에 있는 값을 꺼낸다. 인덱스가 5이고 최소 거리가 0인 값이다.
기존에 있던 dist[5]와 d를 비교한다 dist[5]가 더 작으면 연산하지 않고, 같거나 크면 연산한다.
둘다 0으로 같으므로, 5 주변 인접 정점을 계산하고 기존의 dist[i]보다 더 작아지는 정점들을 큐에 넣는다. (dist[2] = min(dist[2], dist[5]+adj[5][2], dist[4] = min(dist[4], dist[5]+adj[5][4])
Priority Queue
| i | d | p |
|---|---|---|
| 4 | 2 | 5 |
| 2 | 4 | 5 |
| 1 | INF | / |
| 2 | INF | / |
| 3 | INF | / |
| 4 | INF | / |
dist 배열
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | 2 | INF | 4 | INF |
힙에서 가장 위에있는 값을 꺼낸다. 인덱스가 4이고 최소거리가 2인 값이다.
기존에 있던 dist[4]와 d를 비교한다. dist[4]가 더 작으면 연산하지 않고, 같거나 크면 연산한다. dist[4]는 2이고, d는 2로 같으므로, 4 주변의 인접 정점을 계산해서 기존의 dist[i]보다 더 작아지는 정점들을 큐에 넣는다.
(dist[2] = min(dist[2], d+adj[4][2], dist[3] = min(dist[3], d+adj[4][3]))
Priority Queue
| i | d | p |
|---|---|---|
| 2 | 3 | 4 |
| 3 | 3 | 4 |
| 2 | 4 | 5 |
| 1 | INF | / |
| 2 | INF | / |
| 3 | INF | / |
| 4 | INF | / |
dist 배열
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | 2 | 3 | 3 | INF |
힙에서 가장 위에있는 값을 꺼낸다. 인덱스가 2이고 최소거리 3인 값이다.
기존에 있던 dist[2]와 d를 비교한다. dist[2]가 더 작으면 연산하지 않고, 같거나 크면 연산한다. dist[2]는 3이고 d는 3으로 같으므로,
2 주변 인접 정점을 계산해서 기존의 dist[i]보다 더 작아지는 정점들을 큐에 넣는다.
(dist[1] = min(dist[1], dist[2] + adj[2][1]))
Priority Queue
| i | d | p |
|---|---|---|
| 3 | 3 | 4 |
| 2 | 4 | 5 |
| 1 | 6 | 2 |
| 1 | INF | / |
| 2 | INF | / |
| 3 | INF | / |
| 4 | INF | / |
dist 배열
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | 2 | 3 | 3 | 6 |
힙에서 가장 위에 있는 값을 꺼낸다. 인덱스가 3이고 최소거리가 3인 값이다.
기존에 있던 dist[3]과 d를 비교한다. dist[3]가 더 작으면 연산하지 않고, 같거나 크면 연산한다. dist[3]은 3이고 d는 3으로 같으므로, 연산한다.
2 주변의 인접 정점을 계산해서 기존의 dist[i] 보다 더 작아지는 정점들을 큐에 넣는다.
(dist[4] = min(dist[4], dist[4] + adj[4][2]))
여기서 dist[4]는 2로 계산값보다 더 작으므로 큐에 넣지 않는다.
Priority Queue
| i | d | p |
|---|---|---|
| 2 | 4 | 5 |
| 1 | 6 | 2 |
| 1 | INF | / |
| 2 | INF | / |
| 3 | INF | / |
| 4 | INF | / |
dist 배열
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | 2 | 3 | 3 | 6 |
힙에서 가장 위에 있는 값을 꺼낸다. 인덱스가 2이고 최소거리가 4인 값이다.
dist[2]=3 보다 d=4가 더 크므로 계산하지 않는다.
Priority Queue
| i | d | p |
|---|---|---|
| 1 | 6 | 2 |
| 1 | INF | / |
| 2 | INF | / |
| 3 | INF | / |
| 4 | INF | / |
dist 배열
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | 2 | 3 | 3 | 6 |
힙에서 가장 위에있는 값을 꺼낸다. 인덱스가 1이고 최소거리가 6인 값이다.
기존에 있던 dist[1]과 d를 비교한다. dist[1] 은 6이고, d는 6으로 같으므로 연산한다.
1 주변의 인접 정점을 계산해서 기존의 dist[i]보다 더 작아지는 정점들을 큐에 넣는다.
(dist[4] = min(dist[4], dist[1] + adj[1][4], dist[3] = min(dist[3], dist[1] + adj[1][3]))
둘다 dist[i] 보다 크므로 큐에 넣지 않는다.
Priority Queue
| i | d | p |
|---|---|---|
| 1 | INF | / |
| 2 | INF | / |
| 3 | INF | / |
| 4 | INF | / |
dist 배열
| 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| 0 | 2 | 3 | 3 | 6 |
큐에 남아있는 정점들은 전부 d가 INF로 dist[i]보다 크므로 계산되지 않는다.
이를 구현한 코드는 밑과 같다.
위에선 작성되어있지 않지만, 갱신 시마다 위의 정보들을 map에 넣어주면 경로를 쉽게 구할 수 있다. 이 또한 코드에서 구현해보았다.
C++ 구현
시간 복잡도
1) 배열을 이용하는 경우
- 시간 복잡도 : O(V^2)
2) 힙(우선순위 큐)를 이용하는 경우
- 시간 복잡도 : O(ElogV)
