Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets(SVD) 논문 리뷰
논문 : https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
github : https://github.com/stability-ai/generative-models
Introduction

Stable Video Diffusion(SVD)는 고해상도 텍스트-비디오(text-to-video) 및 이미지-비디오(image-to-video) 생성을 위한 최첨단 잠재 비디오 확산 모델(latent video diffusion model)입니다. 이 논문은 기존 2D 이미지 합성을 위한 잠재 확산 모델(Latent Diffusion Model, LDM)을 비디오 생성으로 확장한 연구를 다루고 있습니다. 이를 위해 시간적 레이어(temporal layers)를 추가하고, 소규모 고품질 비디오 데이터셋에서 파인튜닝(finetuning)을 수행하는 방식이 사용됩니다.
기존 연구에서는 비디오 생성 모델의 학습 방법과 데이터 큐레이션(data curation)에 대해 통일된 전략이 부재했습니다. 이에 따라 본 논문은 성공적인 비디오 LDM 학습을 위해 세 가지 주요 단계를 제안합니다:
1. text-to-image pretraining
2. 대규모 video pretraining(대규모 비디오 사전학습)
3. high-quality video finetuning
논문은 특히 데이터 큐레이션의 중요성을 강조하며, 잘 큐레이션된 데이터셋이 고품질 비디오 생성을 가능하게 한다는 점을 실험적으로 입증했습니다
2. Background
Stable Video Diffusion은 여러 선행 연구를 기반으로 하고 있습니다. 주요 관련 연구는 다음과 같습니다:
- Latent Diffusion Models (LDMs): LDM은 이미지 데이터를 잠재 공간(latent space)으로 압축하여 계산 효율성을 높이는 방식으로 작동합니다. Stable Diffusion과 같은 이미지 생성 모델에서 널리 사용되었습니다.
- 시간적 확장(Temporal Extension): 기존 2D 이미지 LDM에 시간적 레이어를 추가하여 비디오 생성을 가능하게 하는 연구들이 진행되었습니다.
- 데이터 큐레이션(Data Curation): 학습 데이터의 품질과 다양성이 생성 모델의 성능에 미치는 영향을 다룬 연구들이 있으며, 특히 대규모 데이터셋에서 효과적인 필터링 및 캡셔닝(captioning) 전략이 중요합니다.
논문은 이러한 선행 연구들을 기반으로, 텍스트-비디오 및 이미지-비디오 생성 작업에서 SVD의 성능을 극대화하기 위한 새로운 접근법을 제안합니다.
3. Curating Data for HQ Video Synthesis
Data Processing and Annotation
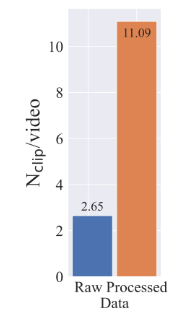
Cut detection pipeline을 통해 메타데이터의 3가지 다른 FPS 수준에서 훨씬 더 많은 클립을 얻습니다.
Coca로 클립의 중간 프레임에 대한 이미지 캡션을 얻고, V-BLIP로 비디오에 대한 캡션을 얻은 후 LLM을 통해 클립에 대한 3번째 설명을 생성합니다..
Coca: Contrastive Captioners are Image-Text Foundation Models
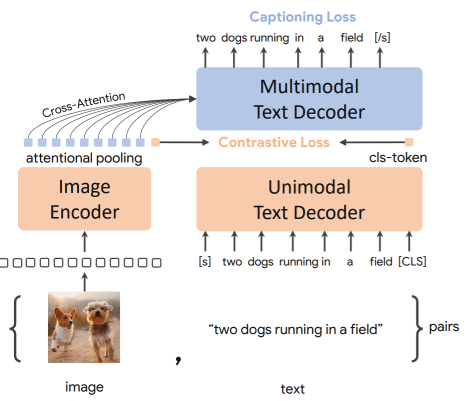
CoCa(Contrastive Captioners)는 이미지-텍스트 기반의 기초 모델로, CLIP의 대조 학습(Contrastive Loss)과 SimVLM의 생성적 캡셔닝(Captioning Loss)을 결합한 사전 학습 방식을 사용합니다. 이 모델은 이미지와 텍스트를 인코더-디코더 구조로 처리하며, 디코더의 전반부는 단일 모달 텍스트 표현을 인코딩하고 후반부는 이미지와 텍스트 간 멀티모달 표현을 생성합니다. 대조 학습과 캡셔닝 손실을 효율적으로 통합하여 다양한 비전 및 비전-언어 태스크에서 최첨단 성능을 달성했다고 합니다.
V-BLIP**
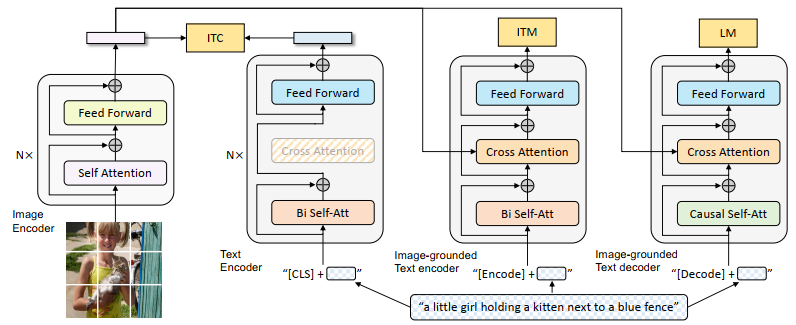
V-BLIP은 BLIP(언어-이미지 사전학습 모델)를 비디오 생성 및 이해 작업으로 확장한 모델입니다. 기존 BLIP의 이미지-텍스트 대조 학습과 캡셔닝 기법을 활용하며, 시간적 정보를 처리하기 위해 비디오 데이터를 추가로 학습합니다. 이를 통해 텍스트-비디오 검색, 비디오 캡셔닝, 비디오 질문 응답 등 다양한 비디오-언어 태스크에서 강력한 성능을 발휘하며, 제로샷 전이 능력 또한 우수하다고 합니다.
Large Video Dataset (LVD)이라고 부르는 초기 데이터셋은 580M의 video-clip pair로 구성됩니다. 이 후 OpenCV를 통해 dense optical flow를 계산하고 움직임이 적은 정적인 클립을 제거합니다.
여기서 dense optical flow는 연속된 두 프레임 간 모든 픽셀의 움직임을 계산하여, 이미지 내 모든 점에 대한 변위 벡터 필드를 생성하고, 프레임의 모든 포인트에 대해 광학 흐름을 계산하며, Gunner Farneback의 알고리즘이라고 합니다.
- 모든 픽셀에 대해 움직임 벡터 계산
- 연속된 두 프레임 간의 변화 분석
- 움직임의 방향과 크기 정보 제공
- 계산 비용이 높지만 상세한 움직임 정보 제공
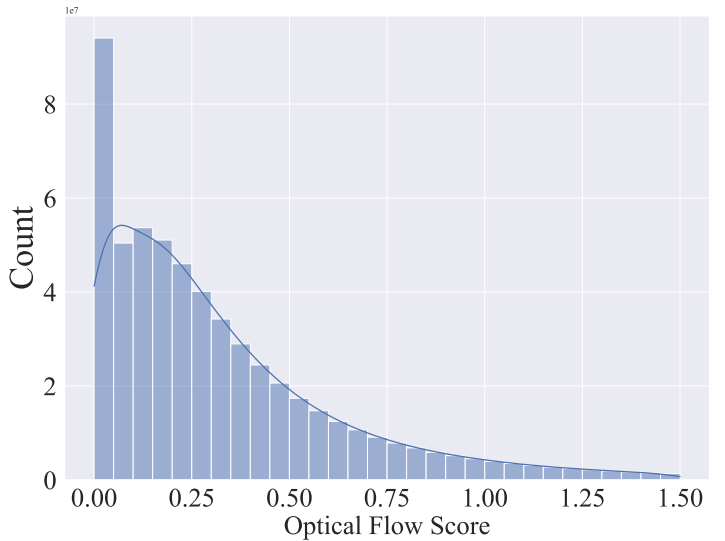
OCR detection을 통해 텍스트가 포함된 클립 제거. 각 클립의 처음, 중간, 마지막 프레임에 CLIP 임베딩을 부여하여 aesthetics score, text-image 유사성 계산합니다.
OCR detection은 OCR(광학 문자 인식)에서 Text Detection은 이미지 속 문자가 있는 영역을 찾아내는 과정입니다. 이는 객체 탐지(Object Detection) 문제를 문자 탐지로 확장한 것으로, CNN 기반의 모델이 주로 사용됩니다. 검출된 영역은 문자를 인식하여 디지털 텍스트로 변환됩니다.
Stage I: Image Pretaining
첫 번째 단계는 텍스트-이미지 생성 작업을 위한 사전학습입니다. 이는 기존 Stable Diffusion 모델(예: Stable Diffusion v2.1)을 기반으로 하며, 다음과 같은 수식을 따릅니다:
여기서 는 시간 t에서의 잠재 벡터(latent vector),c는 조건(condition), 와 는 신경망으로 파라미터화된 평균(mean)과 분산(variance)을 나타냅니다.
이 단계는 텍스트 프롬프트와 이미지 간의 관계를 학습하며, 이후 비디오 생성 작업에 필요한 기초를 제공합니다.
Stage II: Curating a Video Pretraining Dataset

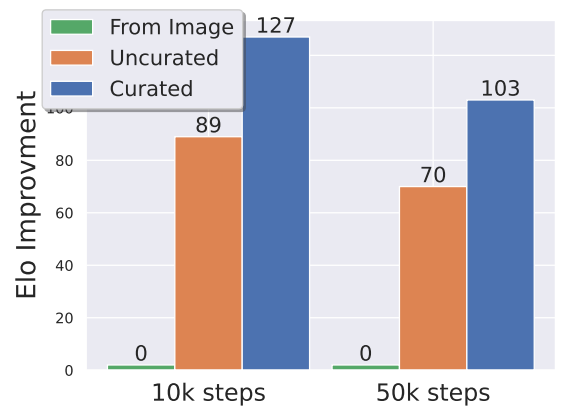
각 유형의 annotation(CLIP score, aesthetic score, OCR detection rate, synthetic caption, optical flow score)에서 하위 12.5%, 25%, 50%를 제거한 각 하위 집합에 대해 동일한 모델을 훈련하고, 인간 선호도 투표에 대한 Elo ranking을 평가합니다. 이를 통해 각 annotation에 대한 최적의 필터링 임계값을 찾습니다.
Stage III: High-Quality Finetuning
세 번째 단계는 고해상도 비디오 생성을 위한 파인튜닝입니다. 이 단계에서는 소규모 고품질 데이터셋(예: 250K 개의 고해상도 캡셔닝된 비디오 클립)을 사용하여 모델을 미세 조정합니다.
참고로 파인튜닝 과정에서 사용되는 손실 함수는 다음과 같습니다:
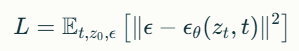
여기서 ϵ은 가우시안 노이즈이며, 는 노이즈 예측 네트워크입니다.
4. Training Video Models at Scale
Pretrained Base Model
고해상도일수록 더 많은 노이즈가 필요하며, 이산 시간 노이즈의 최대 timestep에서도 원본 이미지의 long-wavelength를 완전히 지우지 못합니다. 논문에서는 Stable Diffusion 2.1을 기반으로, noise scheduling을 조정하여 해상도를 높였습니다:
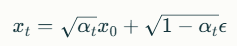
여기서 는 t-번째 단계의 샘플, 는 원본 데이터, ϵ는 가우시안 노이즈입니다.
그다음 시간 계층을 삽입한 후 임베딩을 제외한 모든 계층을 EDM 노이즈 스케줄을 사용하여 256x384의 해상도로 14개 프레임에 대해 훈련한 뒤, 노이즈 분포를 더 많은 노이즈로 이동시킨 후 320x576 해상도에서 추가 훈련합니다.
여기까지 다양한 작업의 fine-tuning에 사용될 '기본 모델'입니다.
High-Resolution Text-to-Video Model
fine-tuning을 통해 다양한 응용 분야에 적합한 모델을 개발했습니다
-
High Resolution Text-to-Video Model: 고해상도 영상 생성.

-
High Resolution Image-to-Video Model: 입력 이미지를 기반으로 일관된 프레임 시퀀스 생성.

-
Multi-View Generation(다중 뷰 생성): 객체의 여러 뷰를 동시에 생성하며, Zero123XL 및 SyncDreamer와 같은 최신 방법보다 우수한 성능을 보였습니다.

5. Conclusion
Stable Video Diffusion(SVD)은 대규모 데이터 큐레이션과 체계적인 훈련 단계를 통해 고해상도 비디오 생성을 위한 강력한 기반을 제공합니다:
- 데이터 큐레이션의 중요성을 실증하며, 이를 통해 최첨단 성능을 달성.
- 다중 뷰 생성 및 동작 제어와 같은 응용 분야에서 뛰어난 결과를 보여줌.
마지막으로
Stable Diffusion에 이어 Stable Video Diffusion 논문을 리뷰해보았다. Stable Diffusion을 계승한 모델이다 보니 비슷한 개념이 있지만, LoRA, CLIP 임베딩 등의 새로운 개념에 대해서도 알게되었고, 이 개념들에 대해서도 리뷰를 해보고 싶다.
